一种嵌入式GPU上的实时图像语义分割方法
2019-12-04董建升袁景凌
董建升,袁景凌,2,钟 忺
1(武汉理工大学 计算机科学与技术学院,武汉 430070)2(武汉理工大学 交通物联网湖北省重点实验室,武汉 430070)
1 引 言
图像语义分割是为图像中的每一个像素分配一个预先定义好的表示其语义类别的标签[1],是计算机视觉、图像处理等领域的基础性问题之一,可应用于自动驾驶、智能安防、智能机器人、医学影像分析等诸多领域之中,具有重要的研究意义和应用价值.近年来深度学习的迅猛发展给各个科研领域带来了巨大的影响,基于深度学习的语义分割方法也日新月异,在性能上取得了极大的飞跃.
Long等人[2]于2014年提出了FCN(fully convolutional network),设计了一种针对任意大小的输入图像,训练端到端的全卷积网络的框架,实现逐像素分类,奠定了使用深度网络解决图像语义分割问题的基础框架[3].Chen等人[4]在FCN的末端添加全连接CRF[5],提出了Deeplab模型,显著的提高了分割性能.Zheng等人[6]在Deeplab的工作基础上,将CRF建模为循环神经网络(recurrent neural network,简称RNN),解决了Deeplab无法进行端到端训练的问题.2016年,Chen等人[7]进一步提出Deeplab-V2网络,对特征图分辨率变小、定位精度过低等问题进行改进.2017年,Chen等人[8]对Deeplab-V2中的ASPP模块进行改进,提出了Deeplab-V3网络.
在使用CNN进行图像语义分割过程中,池化操作能够增大特征图的感受野,但也带来了部分像素的空间信息丢失的问题[9].Olaf等人[10]提出了U-Net解决这一问题,该网络利用编码器-解码器结构在编码器中逐步减少特征图的分辨率,在解码器中则逐步还原图像细节.Vijay等人[11]提出的SegNet是一个类似编码器-解码器结构的对称结构网络,该网络的左边是一个由全卷积网络构成的编码器,右边是一个由反卷积网络构成的解码器.Adam等人[12]在2016年提出的ENet中的编码部分比解码部分更加复杂,是一种不对称的编码器-解码器结构,该网络由较少的卷积层构成,并且利用低阶近似对卷积操作进行简化,显著的提高了网络的计算效率.
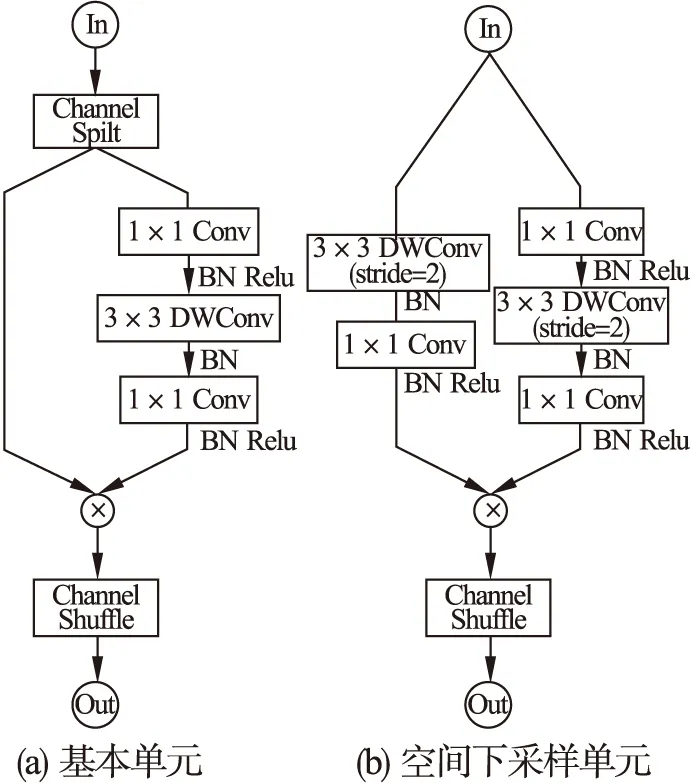
图1 ShuffleNet V2构造单元Fig.1 Building blocks of ShuffleNet V2
随着半导体工艺以及记忆芯片设计水平的不断提升,嵌入式GPU的性能得到了空前的发展,其计算能力不断提升,应用的领域也更为广泛.尽管如此,受限于复杂深度学习网络的算力要求,大部分高准确度的深度学习网络在低功耗的嵌入式GPU上运行速度缓慢,很难在实际场景中应用,于是一些学者开始尝试提高深度学习网络的计算效率.Wu等人[13]和Zhao等人[14]通过裁剪、调整大小等操作来固定网络的输入尺寸,从而降低计算复杂度,这是一种简单有效的方法,但会牺牲较大的性能.Hinton等人[15]和Han[16]等人分别使用知识蒸馏和剪枝来压缩已有的复杂网络,其目标在于尽可能地减小模型大小,因而会对原网络结构造成极大程度的改造甚至是破坏.Zhang等人[17]和Ma等人[18]分别提出了ShuffleNet V1和ShuffleNet V2网络,ShuffleNet V2构造单元如图1所示.这两个网络主要利用深度可分离卷积(Depthwise Separable Convolution)来简化网络,在牺牲少量精度的条件下显著地提高了计算效率,可以很好地作为我们研究轻量级图像语义分割模型的基础.
因此,针对自动驾驶、智能机器人等实时性应用背景,本文提出了一个轻量级的图像语义分割模型,该模型在保留较高准确度的前提下,实现了嵌入式平台上的实时图像语义分割,为深度学习模型在嵌入式平台上的实时性应用提供了支持.本文的主要工作如下:
1)提出了一个轻量级的图像语义分割模型,该模型在嵌入式平台上实现了实时图像语义分割,并在Cityscapes数据集上达到了72.17%的mIoU.
2)使用基于深度可分离卷积的特征金字塔结构替换轻量级网络ShuffleNet V2中单个的3×3卷积核,来捕获多尺度空间信息,提高模型的性能.
3)利用NVIDIA的推理加速器TensorRT进行合并层、降低计算精度、并行优化等操作,提高模型的计算效率.
2 网络结构
在图像语义分割任务中,对小目标如交通信号灯、杆状物的分割极具挑战性,这是因为小目标的空间信息很容易在不断地卷积池化过程中丢失,或者与大目标的空间信息重叠从而被忽略,在一定程度上降低了分割精度.为了解决这一问题,本文使用特征金字塔结构替换ShuffleNet V2中单个的3×3卷积核来捕获多尺度空间信息,再进行信息融合,提高模型的性能.但特征金字塔结构是计算密集型的,为了避免对模型的计算效率产生较大影响,本文使用计算高效的深度可分离卷积结构代替标准的卷积核.
2.1 深度可分离卷积
深度可分离卷积是许多轻量级神经网络模型[17-20]的关键结构,它通过分解标准卷积操作来降低计算量.卷积层的主要作用是特征提取,标准的卷积将三维的卷积核作用.
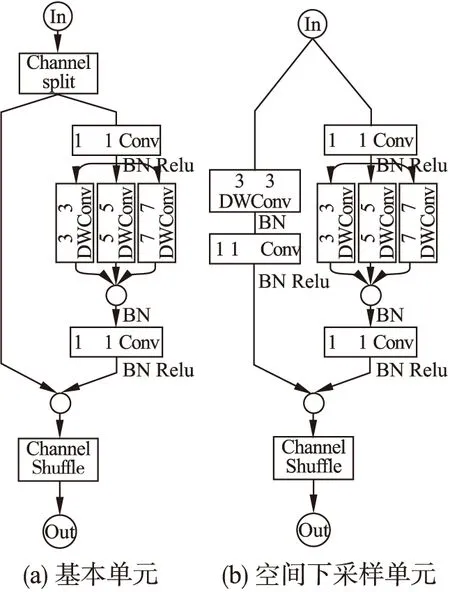
图2 网络构造单元Fig.2 Building blocks of network
在一组特征图上,需要同时学习空间上的相关性和通道间的相关性.深度可分离卷积的基本思想是将标准的卷积操作分解为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两步操作.它首先分别对输入的每个通道使用一个逐通道卷积来捕获通道中的空间信息,然后使用实质为1×1卷积核的逐点卷积来捕获跨通道信息.
假设有一个卷积层,其输入特征图Li大小为h×w×di,输出特征图Lj大小为h×w×dj.对于标准卷积层,其卷积核K∈Rk×k×di×dj,其中k是卷积核的大小,其卷积操作的计算量为h·w·di·dj·k·k.对于深度可分离卷积层,其逐通道卷积操作的计算量为h·w·di·k·k,逐点卷积操作的计算量为h·w·di·dj,因此深度可分离卷积操作的总计算量为h·w·di·(k2+dj).那么,标准卷积操作与深度可分离卷积操作的计算量之比应为:
(1)
由此可见,深度可分离卷积操作极大地降低了标准卷积操作的计算量,当输出通道数量dj越大时,减少的计算量也就越大.
表1 网络结构
Table 1 Network structure
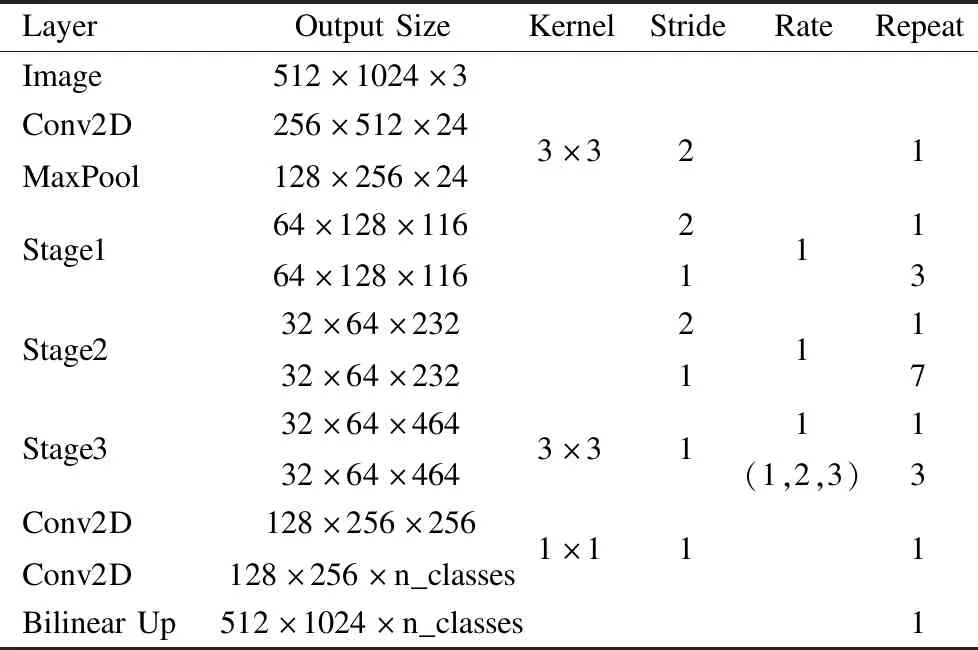
LayerOutputSizeKernelStrideRateRepeatImage512×1024×3Conv2DMaxPool256×512×24128×256×243×321Stage164×128×11664×128×11621113Stage232×64×23232×64×23221117Stage332×64×46432×64×4643×311(1,2,3)13Conv2DConv2D128×256×256128×256×n_classes1×111BilinearUp512×1024×n_classes1
2.2 网络构造单元
如图2所示,本文使用基于深度可分离卷积的特征金字塔结构替换ShuffleNet V2中单个的3×3卷积核,来捕获多尺度空间信息.其中DWConv表示Depthwise Convolution,⊗表示连接操作.
对于图2(a)所示的基本单元,首先通过Channel Split操作将通道数为c的输入划分成通道数分别为c-c′和c′的两组特征图,两组特征图分别通过下面的两个分支.为简单起见,本文令c′=c/2.右分支由一个特征金字塔结构和两个1×1卷积组成,特征金字塔结构中的DWConv的步长均为1,通过该分支的输入特征图和输出特征图具有相同的通道数.通过左分支的特征图作同等映射直接与右分支的输出进行拼接.最后通过Channel Shuffle操作重新分配特征图通道顺序,保证两个分支间的信息交流
对于图2(b)所示的空间下采样单元,该单元移除了Channel Split操作,输入将被复制到两个分支同时进行计算,因此最后整个空间下采样单元的输出通道数会翻倍.与基本单元不同的是,空间下采样单元中右分支的特征金字塔结构中的DWConv的步长均设置2,以实现空间下采样.左分支添加了一个步长为2的DWConv和一个1×1卷积.接着连接两个分支的输出并进行Channel Shuffle操作.
2.3 网络结构
本文提出的网络结构如表1所示,可以划分将其为初始化模块,中间模块和上采样模块.
初始化模块由一个标准卷积层和一个最大池化层组成,该模块能够将输入快速地下采样到原图的1/4大小.中间模块由3个Stage组成,这个模块与ShuffleNet V2的网络结构类似,但本文进行了一些修改.Chen等人[8]发现连续的下采样操作会降低特征图的分辨率,丢失大量的细节信息,这对语义分割是有害的.因此对于Stage3中的空间下采样单元,本文将其特征金字塔结构中的卷积步长均设置为1,同时将Stage3中基本单元中特征金字塔结构的卷积核大小均设置为3×3,扩张率分别设置为(1,2,3).本文通过上述设计将Stage3的output_stride由ShuffleNet V2中的32倍调整到为16倍,更有利于提取细节信息[8].上采样模块由两个1×1的卷积层和双线性插值操作组成,该模块将提取到的特征图进行分类并上采样到原图大小.
3 TensorRT推理加速
TensorRT是NVIDIA公司推出的深度学习网络推理加速引擎.如图3所示,它可以对训练好的网络进行合并层、精度校准、动态存储、内核自动调整、并行优化等操作,从而提升模型的推理速度.加速后的网络无需深度学习架构支持,对平台的依赖性极小,无论在高性能GPU还是嵌入式GPU上都有可观的加速能力.
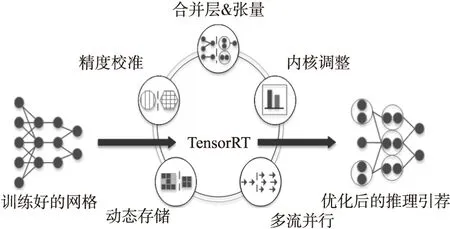
图3 TensorRT推理加速Fig.3 TensorRT inference acceleration
表2 Cityscapes测试集上实验结果对比
Table 2 Comparison of experimental results on cityscapes test set

MethodmIoUBuildingSkyCarSignRoadPersonFencePoleSidewalkBicycleEnet[12]58.385.090.690.644.096.365.533.243.574.255.4ShuffleNetv2+DPC[22]70.390.793.994.066.998.178.550.951.582.567.5Fast-SCNN[21]68.089.794.393.060.597.974.048.648.381.661.2Ours72.191.293.686.172.697.281.951.058.181.269.9
算法1.使用TensorRT构建推理加速引擎
输入:训练好的神经网络
输出:推理加速引擎
1.model←load_model()
2.weights←get_weights()
3.model←populate_model(model,weights)
4.engine←build_engine(model)
5.engine←serialize_engine(engine)
6.return engine
推理加速引擎的构建如算法1所示.首先加载模型和训练好的模型参数,并将模型参数填充到模型中,然后利用加载参数后的模型构建推理引擎,最后将推理引擎序列化.接下来就可以用推理引擎进行推理.
4 实验分析
4.1 数据集
本文主要在Cityscapes数据集上对提出的网络模型进行训练和评估.Cityscapes是一个图像语义分割领域的大型城市街景数据集.它包含5000个精细标注的样本,其中用于训练、验证和测试的数据集分别包含2975、500和1525个样本.分割的目标包含道路、人行道、建筑、围墙、围栏、杆状物、交通信号灯、交通标志、植被、地形、天空、人、骑手、汽车、卡车、公交车、火车、摩托车、自行车共19个类别.
4.2 训练细节
本文基于Pytorch深度学习网络框架采用并行GPU进行训练.网络每次训练的样本数(batch-size)为16,采用动量(momentum)为0.9的随机梯度下降(Stochastic Gradient Descent)优化算法.与文献[19,21,22]类似,学习率采用初始值为2.5e-2,幂值(power)为0.9的多项式衰减策略,使用交叉熵损失函数进行损失计算.为了强化数据,我们对训练数据集进行了随机尺寸调整,随机裁剪,水平翻转等操作.
4.3 实验结果
表2和表3为Cityscapes测试集上的实验结果对比.表2展示了mIoU以及部分类别的IoU结果对比,本文提出的网络无论是单个类别的IoU还是mIoU都优于目前大部分的轻量级图像语义分割网络.表3展示了19个细分类别(class)和7个粗分类别(category)的IoU结果以及网络参数数量的对比,特别注意的是,尽管网络的参数数量略大于部分其他网络,但是仍然是一个轻量级网络,能够达到较快的推理速度.
表3 Cityscapes测试集的Class IoU和Cat.IoU结果
Table 3 Class and category IoU on cityscapes test set
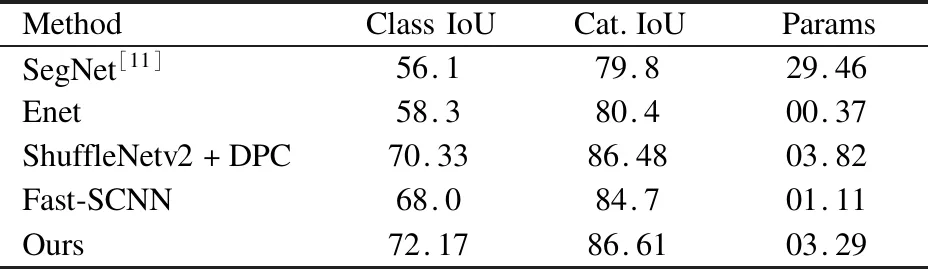
MethodClassIoUCat.IoUParamsSegNet[11]56.179.829.46Enet58.380.400.37ShuffleNetv2+DPC70.3386.4803.82Fast-SCNN68.084.701.11Ours72.1786.6103.29
表4 Cityscapes测试集上的消融实验结果
Table 4 Ablation results on the cityscapes test set

MethodClassParamsShuffleNetv267.702.27Ours72.1703.29
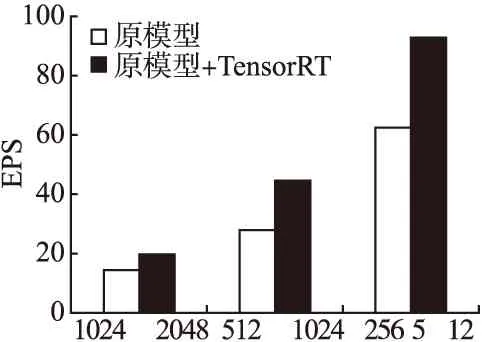
表5 Xavier上的推理速度
Table 5 Inference speed on xavier
本文进行了一个简单的消融实验来验证特征金字塔结构对网络的性能和参数的影响,实验结果如表4所示.在Cityscapes测试集上,ShuffleNet V2的mIoU是67.7%,在使用特种金字塔结构对ShuffleNet V2的构造单元进行优化之后,mIoU达到了72.17%,网络的性能得到了显著的提升.但相应的参数数量也增加了约1.45倍.
为了验证网络在嵌入式平台的推理速度以及TensorRT的推理加速效果,本文在NVIDIA Jetson Xavier上进行了推理实验.Xavier的CPU采用8核ARM64架构,GPU采用512颗CUDA的Volta,支持FP32/FP16/INT8,20W功耗下单精度浮点性能1.3TFLOPS,Tensor核心性能20TOPs,解锁到30W后可达30TOPs.Cityscapes数据集上的图片像素尺寸为1024×2048,我们分别进行了以1倍,1/2倍,1/4倍尺寸为输入的网络在嵌入式平台Xavier推理速度测试实验,实验结果如表5所示.对于512×1024的输入图像,原网络在Xavier上的推理速度约为25 FPS,经过TensorRT加速后,推理速度达到了45 FPS,加速比约为1.8,加速后的网络实现了嵌入式平台上的实时图像语义分割.

图4 Cityscapes验证集上的部分分割结果(标签中的黑色区域被忽略)Fig.4 Example results on Cityscapes validation set(Black colored regions on ground truth are ignored)
最后,图4展示了网络在Cityscapes验证集上的部分实验结果对比.第1列是原图,第2列是精细标注的标签,第3列是ShuffleNetV2+DPC的分割结果,第4列是本文的分割结果.可以看到,在一些细节方面,本文提出的网络更接近于实际标签.例如第2幅图中的围栏,第4幅图中远处的行人以及第5幅图中的三轮车等.而且我们的分割结果有较少的噪声点.
5 总 结
深度学习已经广泛应用于图像语义分割,并取得了比传统方法更高的准确度.本文针对复杂深度学习网络在嵌入式平台上推理速度慢,性能较低的问题,提出了一个轻量级图像语义分割网络.该网络通过特征金字塔结构提取多尺度空间信息,提升网络的细节分割能力从而提升网络的性能.随后利用NVIDIA的推理加速器TensorRT对网络进行优化,提升网络在嵌入式平台上的推理速度.实验结果表明本文的网络在保留较高准确率的条件下,实现了嵌入式平台上的实时图像语义分割.
从分割结果来看,边界的精确分割是网络需要改进的方向.在未来的工作中,打算将一些边缘分割算法与本文的网络有效地结合起来,以进一步提高模型的性能.
