基于改进随机森林算法的LBSN用户短期位置预测模型
2019-12-04袁健,蒋宇,孙悦
袁 健,蒋 宇,孙 悦
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
近年来,基于位置的社交网络(简称LBSN)得到了迅速发展.国外比较主流的LBSN有Foursquare、Gowalla和Brightkite等,国内有滴滴、街旁和大众点评等.LBSN中有大量的签到数据(包括用户,位置,相应的签到时间和好友关系等)现已被广泛应用于研究人员的移动性问题中,其中如何将历史签到数据进行用户位置预测是目前的研究热点.若有高效的用户位置预测方法将极大改善用户的体验.
当前与用户位置预测相关的研究主要有两种:对用户家庭住址的位置预测和对用户在未来的一段时间内可能签到的位置预测.对用户未来可能签到位置的预测又分为短期位置预测(数分钟后、数天或数周后)和长期位置预测(数月乃至数年).本文研究的是对用户在较短时间内可能的签到位置进行预测,该研究可以充分描述用户的活动区域,从而精准地为用户提供个性化推荐服务;商家也可以通过短期位置预测获得附近的人群用户画像,从而做出更精准的广告投放或商业活动决策.
2 相关工作
对人类移动行为分析以及预测一直备受国内外学者的关注.在移动设备还没有普及的时候,研究者们只能采用GPS设备针对用户移动的轨迹数据进行研究[1,2],其轨迹论证了用户的历史签到数据对预测用户将来所处位置的重要作用.Schönfelder[3],M.Ye[4]和 Li W[5]等人,通过对用户的历史签到数据的研究,发现用户将来所处的位置在固定的周期内呈现很强的相似性,可建立模型对用户将来出现的位置进行预测.
在早期,由于移动互联网没有普及,对位置预测的研究并未将社交关系这一因素考虑在内.故此类模型[2,5,6]存在预测结果精度低的问题.
随着移动设备的普及和LBSN的蓬勃发展,新兴的研究更多地从LBSN中的签到数据[7-9]切入.其签到数据可以有精确的签到时间、签到位置经纬度信息以及用户的社交关系,还可以对签到位置标注相应的功能标签,以便于从多个维度对用户的签到行为进行挖掘.
Chang等人[10]利用Facebook公开的数据集,考虑用户签到的历史位置,相似功能标签地点,人口分布以及好友等因素,研究影响用户在未来可能签到的位置的特征因子,通过这些组合的特征因子对用户未来可能的签到地点进行预测,并采用逻辑回归算法对多个维度进行组合,预测用户即将签到的位置,取得了不错的效果.但是对于非线性特征,需要进行转换,当特征空间很大时,逻辑回归的性能不是很好.Gao等人[8]提出将社交关系和用户历史记录综合考虑的模型,训练出一个数学统计模型来预测用户下一次的签到可能发生的地点,并分析用户签到的历史信息和好友签到历史信息两者之间的关联性作为社交影响因素加入统计模型.但是该模型需要依赖大量的训练数据,并且构造模型的时空消耗非常大.Ying等人[11]提出了一种UPOI-Mine模型,该模型融合了社交网络关系,用户个人偏好和人口等因素来预测用户在将来可能的签到位置,通过输出一个POI评分来对签到位置的可能性大小进行描述.最后通过建立决策树模型对Gowalla数据集[12]中数据进行实验.但是,该模型割裂了时间序列对位置预测的影响,而且由于数据集的原因对个人偏好特征挖掘不充分.Lv[13]等人提出了基于多维混合特征的位置预测算法,但是该模型的泛化性较差,对训练的数据集产生过拟合,并且模型的准确率和召回率不够高.Li 等人[14]分析了用户签到地点与时间变化之间的规律,考虑用户的长期和短期的偏好因素,提出一种基于时间的兴趣点预测算法,但是该模型依赖个体的偏好因素,没有考虑用户签到位置受社交群体因素的影响.
综上所述基于LBSN的用户短期位置预测的研究面临着如下问题.首先,签到数据维度高但呈现稀疏性,且现有的研究模型预测的位置结果对训练样本很敏感,泛化性较差;其次,数据特征的提取与应用往往存在局限,预测的准确度不高.为此,本文针对用户短期位置预测问题提出了基于改进随机森林算法的LBSN用户短期位置预测模型-short-termpositionpredictionmodelforLBSNusersbasedonimprovedrandomforestalgorithm(以下简称SPMLIRFA).该模型将位置预测问题看作是一个分类问题,首先对LBSN中的时间、空间、个人社交因素和社交群体的位置的热门程度等关键特征进行量化,然后应用提出的基于Fisher判别函数的过滤型特征选择方法进行特征分区,最后通过分类判断用户是否在给定时间在候选位置进行签到从而实现用户位置的预测.实验结果证实了该模型对于预测用户的短期签到位置具有更好的泛化性和准确率.
3 相关定义
定义1.G
定义2.Bootstrap(自助抽样法),是从给定训练集中抽取后又放回的均匀抽样的方法.
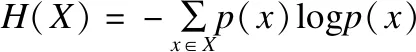
定义4.ri(t),i∈{d,w},表示不同模式下以小时为粒度切分的时间点集合.当i=d时表示日模式下的时间点集合,即rd(t)={1,2,…23}.当i=w时表示周模式,rw(t)={0,1,2,…,167}.
4 SPMLIRFA算法
4.1 随机森林算法
随机森林算法思路是利用Bootstrap采样生成n个训练样本;随机抽取样本数据中的k个相关属性,依据最小熵原则分裂属性构建一颗CART决策树[15];然后,不断地重复上述操作直至构建m棵CART树;将这m棵决策树看成一个整体,构建出一个随机森林.
随机森林具有结构简单,构建速度快的特点,能够有效克服过拟合的特点,因此完全适合对用户签到行为进行预测.虽然随机森林能够做到对所有属性无差别的随机抽取,但是一旦样本有着大量的属性并且存在着对分类结果影响较小的属性,随机抽取的特征的质量将低于有导向性抽取出的特征.
4.2 SPMLIRFA算法
随机森林算法是一种组合型分类算法,它采用分类回归树(CART)作为基分类器来构建分类模型,主要用在分类预测问题上.标准的随机森林算法选择特征是完全随机的,因此任何一个特征被抽取到的概率都是相同的,然而,在实际情况下,不同的特征对最终分类结果的影响程度是不同的.本文对随机森林算法进行了改进,将其应用于LBSN用户的短期位置预测,提出了SPMLIRFA模型.
SPMLIRFA将位置预测问题看作是一个分类问题,利用签到数据,在现有相关研究的基础上,先将时间因素,空间因素,个人社交因素和社交群体的签到地点热门因素进行量化,将Fisher判别函数值(简称Fisher比)来衡量特征的重要程度,训练样本则按照特征重要程度划分的比例来采样,训练生成多个决策树后分类预测位置,从而实现LBSN中用户位置的预测.
4.2.1 特征量化
1)周特征量化值Week_loc.
周模式下,给定用户u和时间tgiven∈ri(t),i∈{d,w},该用户的历史签到集合为Cu,其在历史签到集合中的t时刻表示为rw(c,t),c∈Cu.给定的候选位置Vcandidate的特征量化值Week_loc定义如公式(1):

(1)
2)日特征量化值Day_loc.
同周模式,给定的候选位置Vcandidate的日特征量化值的定义如公式(2),其中rd(tgiven)表示日模式下的一个给定时间,rd(c.t)表示给定用户u在历史签到集合中日模式下t时刻.
3)空间特征量化值Distance.

(2)
空间特征量化值Distance的定义如公式(3)所示.
Distance]dist(Vcandidtae,center)
(3)
其中dist(vi,vj)表示从位置vi到位置vj的距离,center表示该用户的签到中心,本文选取该用户所有签到位置集合的经纬度的均值作为其签到中心的位置.
4)个人社交因素特征量化值Friendship.
个人社交因素特征量化值Friendship的定义如式(4):
(4)
其中weightu′代表好友u′对用户u影响的权重,其取值正比于用户u′和u所在历史集合中共同的签到位置数量,取值范围为[0,1],P(Cu′=vcandidate)是好友u′在候选地点Vcandidate的签到频率,Fu代表用户u的好友集合.
5)签到地点热门程度特征量化值fpop(p).
利用Gowalla数据集(公开的LBSN签到数据集),本文对用户社交群体在连续签到的热门位置距离的概率密度进行了研究.图1为Gowalla数据集中所选的相邻连续签到位置的概率密度的情况.其中点表示Gowalla数据集中所有存在的连续签到位置的分布情况(共约5万个点).
若设定用户u其社交群体(所有好友)的签到位置的热门程度的概率密度p服从幂率分布[16],其幂律分布的概率密度fpop(p)如公式(5)所示.
fpop(p)=(β-1)(p+1)-β,p≥0,β>1
(5)
其中,β是从签到频率矩阵中使用极大似然法[17]计算得出的值.如公式(6)所示.
(6)
其中,L代表签到位置的集合,l,l′表示某用户群体在历史签到集合中任意两次连续签到的位置,Rl′,l表示两个签到地点的经纬度坐标计算出的空间距离的函数[18].
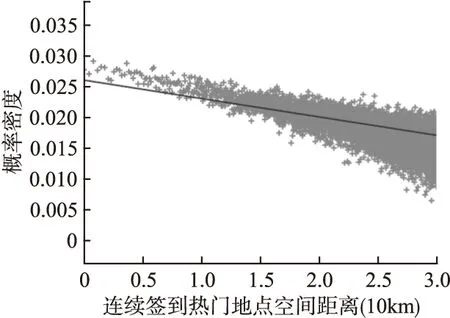
图1 连续签到热门地点空间距离与概率密度分布Fig.1 Continuous sign-in to popular location space distance probability density distribution
按公式(5)在图1中绘出图形得到一直线,从图中可看出数据集中的连续签到热门地点距离的概率密度和公式(5)的幂律分布较为近似,因此假设用户的社交群体的签到地点热门程度特征量化值符合幂律分布,用fpop(p)表示.
4.2.2 SPMLIRFA模型主要步骤
SPMLIRFA模型的核心思想是先从数据集中自助取样得到多个样本,计算出各个样本的特征重要程度的值(即Fisher比)并求得均值;再将样本的特征根据重要程度的均值分区:重要特征区和次要特征区.然后,根据特征重要程度的值按照比例分别抽取不同分区特征组合成该样本的特征子空间,再根据每个样本的特征子空间构造决策树.接着对决策树构成的森林采用随机森林算法进行投票分类,再根据分类结果进行用户位置预测.SPMLIRFA模型的总体流程如图2所示.
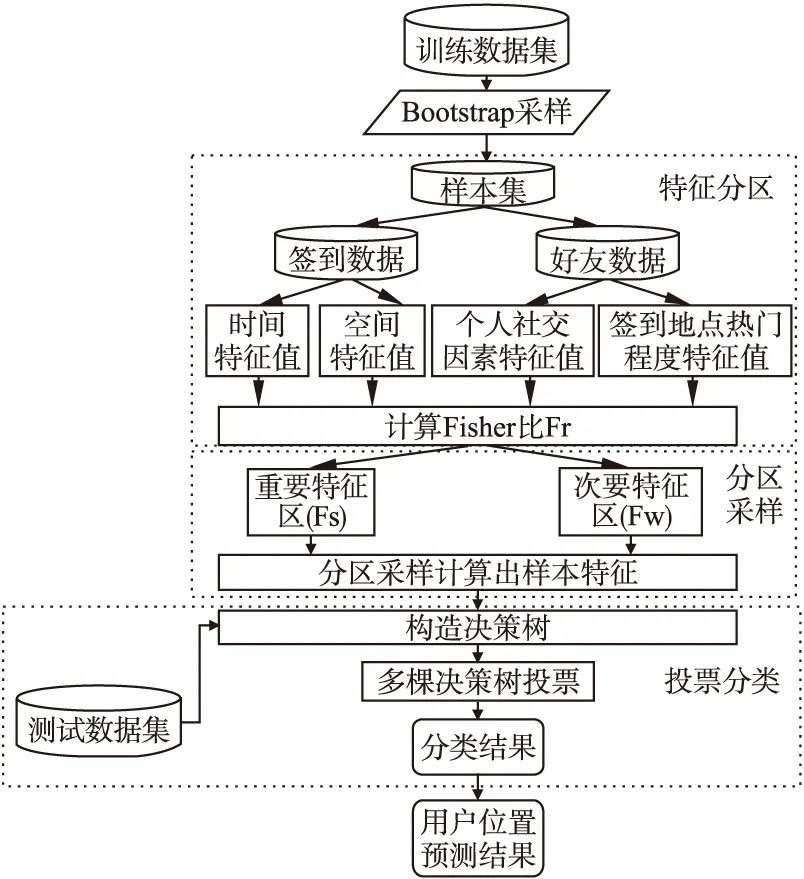
图2 SPMLIRFA模型的总体流程图Fig.2 SPMLIRFA model process
算法模型的主要步骤如下:
1)Bootstrap采样
通过Bootstrap采样从原始数据集抽取k个自助样本集.
2)特征分区
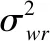
(7)
(8)
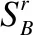
(9)
则属于第w个分类的所有样本中第r维特征的Fisher比Fr可表示为公式(10).
(10)
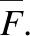
(11)
(12)
NS+NW=n
(13)
3)分区采样
如公式(14),公式(15),在抽取样本特征时,分别随机从FS区和FW区抽取出mS和mW个特征并将其组合,构造成mtry维的特征子空间.
(14)
(15)
4)构造样本的决策树
对于自助样本集和每个样本集对应的mtry维特征子空间,以当前节点的熵值最小为特征选择基准,选择相应的特征来分裂节点,若节点具有最小的熵值,即由该节点分类出的所有输入只有一种分类结果,则该节点为决策树的叶子节点.生成k个决策树,构成随机森林[19].
5)投票分类
将测试数据集输入至上面随机森林,统计每一棵CART分类树的分类结果,按照最大投票法[19]得出分类结果,作为模型的预测结果.
5 实验与分析
5.1 实验环境和数据集
实验所用的数据集是知名的LBSN签到数据集Gowalla[12].其中,选取数据的时间范围为2010年1月到2012年1月,总计抽取其中的约600万条签到记录作为训练集.筛选时间范围为2012年2月的部分数据作为实验的测试集(实验假设个人社交因素在训练集和测试集的时间维度上是不变的).其中筛选规则为:对于在训练集上的每个用户,若该用户存在2012年2月的签到记录且该次签到的地点属于训练集的地点集合,则该条记录满足筛选条件.实验前,先对数据集进行数据清洗与过滤,剔除了签到记录较少的不活跃用户(签到记录数少于15条),去除了原始签到记录中不必要的信息如签到商户信息等,只保留本文研究的特征信息:时间戳,地理经纬度,好友关系和地理位置总签到次数;然后清洗了一些缺失必要信息的签到记录,如签到时间戳缺失,签到经纬度缺失的记录;与此同时,剔除了一些明显不合理的数据,如经纬度超出范围的签到记录.最后经过预处理后的数据集大致信息如表1所示.
实验将原始数据集中的数据格式化至mysql数据库,分别将签到记录,好友关系和签到地点存至三张对应的表中,表的信息如表2,表3,表4所示.实验的机器CPU为intel(R)Core(TM)i5-3320M 2.6GHz,运存大小为6GB,操作系统为windows 7 sp1,代码基于matlab 10和python 2.7,其中,数据的预处理环节和Fisher比计算使用python完成,再将由python抽样得出的自助样本集和计算出的样本集对应的特征子空间作为参数传入基于matlab提供的随机森林工具包(Windows-Precompoiled-RF_MexStandalone)构建的代码中,训练生成随机森林.
表1 数据集信息
Table 1 Data set information

数据集签到记录数好友关系数地点数Gowalla5970244950523158345
表2 签到记录表
Table 2 Check-in record

属性含义UserId签到用户idCheck-intimestamp签到时间戳Latitude签到地点经度Longitude签到地点纬度LocateId签到点id
表3 好友关系表
Table 3 Friend relationship

属性含义User1用户1的idUser2用户2的id
表4 签到地点表
Table 4 Check-in location

属性含义LocateId签到点idcheckInNum总签到次数
5.2 评估指标
5.2.1 准确率
准确率[20]表明了用户真正签到位置在所有预测结果中所占的比例.其中对于用户u,R(u)表示算法的预测签到位置集合,T(u)表示测试数据集中用户u实际签到的位置,准确率的公式如公式(16).
(16)
5.2.2 召回率
召回率[20]表示的是用户实际签到的位置在预测候选位置中所占的比例,召回率的表示如公式(17).
(17)
5.3 结果分析
5.3.1 SPMLIRFA和随机森林(RFPA)算法比较
SPMLIRFA中的核心算法是本文提出的改进的随机森林算法.下面对SPMLIRFA与基于随机森林的用户位置预测模型(简称RFPA)在测试集上的预测准确度和召回率进行了对比实验,以下实验得到的准确率和召回率均为相同训练集和测试集条件的20次实验结果的平均取值.
1)准确率
从图3可以看出,选取200个样本生成200个决策树的情况下,随着原始数据集的规模越来越大,RFPA和SPMLIRFA的准确率呈现上升的趋势,这表明两者的分类的准确率都是随着训练数据的变大而变好.在相同的样本个数下,SPMLIRFA在准确率上基本优于RFPA,并且,由于随机森林算法的泛化性强,SPMLIRFA的实验结果也做到了较为稳定的准确率,而不会出现过分拟合的情况.
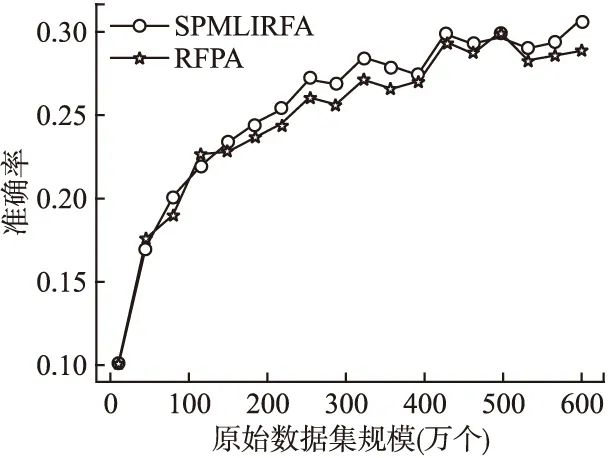
图3 模型预测准确率-原始数据集规模大小折线图Fig.3 Forecast accuracy-original dataset scale line chart
2)召回率
从图4可以看出,选取200个样本生成200个决策树的情况下,随着位置候选点的个数越来越大,RFPA和SPMLIRFA的召回率呈现上升的趋势,这表明两者的分类召回的效果都随着候选点的个数的增加而变好.其次,在候选点个数相同的情况下,SPMLIRFA的召回率高于RFPA.同样的,随机森林算法的强泛化性也在图4中得到了体现.
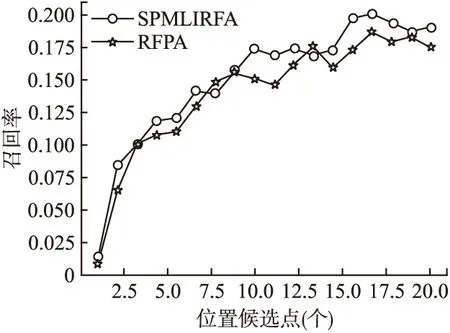
图4 模型预测召回率-位置候选点个数折线图Fig.4 Predicted recall rate-candidate point location line chart
5.3.2 SPMLIRFA和LPMMF等算法比较
选择对比LPMMF[13],UPOI-Mine[11],MFT-D[8]和MFT-W[8].其中LPMMF模型是一种融合了多个维度特征的位置预测模型,其使用逻辑回归模型融合时间和空间等特征来预测用户在给定的候选位置集合中出现.UPOI-Mine是一个融合了个人偏好因素,社交因素和兴趣点流行度因素的地点推荐模型,并且采用了决策树回归的方式预测结果.MFT-D和MFT-W是在文献[8]中提出的对比基准算法,这两个算法模型认为用户在相同的时间模式的情况下,用户在某候选位置签到的概率和该用户在历史签到记录中在该位置签到的频率强相关.SPMLIRFA的20次平均实验结果与这三个算法模型的实验对比原始训练集都为抽取的Gowalla数据集中5970244条签到数据.SPMLIRFA模型在200个决策树的条件下(即抽取200个样本),选取的位置候选点个数为17个,同时,在LPMMF中选取的备选位置的个数也为17个,UPOI-Mine中推荐列表的大小也是17.
1)准确率
由图5可以看出,MFT-D和MFT-W在准确率上都要低于基于多维的特征算法模型SPMLIRFA和LPMMF,这表明用户未来签到的位置取决于多个因素的影响,UPOI-Mine模型因未考虑时间这一重要因素,且没有对挖掘到的特征作出导向性的特征选择,实验得出的结果和只考虑单一的时空特征的模型MFT-D和MFT-W得出的结果相似,而融合了时间特征,空间特征,社交关系等多维特征的算法模型的效果明显好于单一特征的算法模型.同时,观察到SPMLIRFA算法模型在准确度上也优于LPMMF,这证明,SPMLIRFA算法在特征因素的选取考虑、量化以及重要性划分上的工作优于LPMMF.
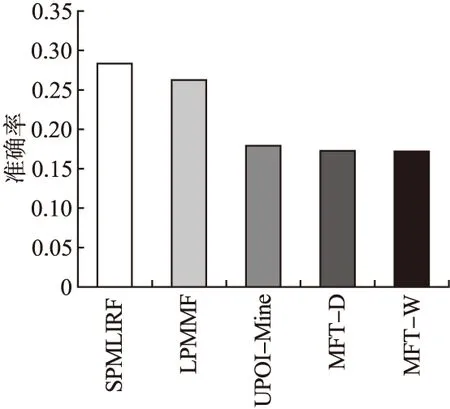
图5 模型准确率对比图Fig.5 Comparison of model accuracy ratio
2)召回率
由图6可以看出,在召回率的对比中,SPMLIRFA依然是几个算法中表现最好的,而LPMMF的召回率表现出一定的差距,这表明,LPMMF的在泛化性上也是不如SPMLIRFA的.

图6 模型召回率对比图Fig.6 Comparison of model recall rate
6 结束语
本文研究了LBSN中的用户短期位置预测问题.并将其看成是一个是否在候选位置签到的分类问题,模型以时间周期特征,空间距离特征,社交群体特征和签到位置的热门特征作为分类特征.然后以特征的量化值为依据,建立特征的重要性度量体系(Fisher比),将带有重要性度量的特征空间参与到随机森林的训练过程中去.实验结果表明,本文提出的SPMLIRFA算法模型具备随机森林算法的优秀的泛化能力,在位置预测方面有着稳定的准确率和召回率,并且由于特征的重要性度量的引入,相比较现有的一些算法模型,在准确率上也具备相应的提升.以后打算把用户的动态偏好纳入用户的位置预测模型进行研究.此外,未来将研究来源于多种异构网络的信息的融合,这将有助于提高位置预测的准确率和性能.
