BLAKE2b算法优化及OpenCL实现
2019-12-04杜飞飞张德学王佃涛郭晓超
杜飞飞,张德学,王佃涛,郭晓超
1(山东科技大学 电子信息工程学院,山东 青岛 266590)2(中国科学院 计算技术研究所,北京 100190)3(中国科学院大学,北京 100190)
1 引 言
Equihash算法是主流数字货币zcash采用的一种工作量证明算法[1,2],它由 Alex Biryukov 和 Dmitry Khovratovich 联合发明,其理论依据是一个著名的计算机科学及密码学问题—广义生日悖论.Equihash算法具有去中心化的优势,但同时存在运算量大的问题.Equihash算法计算过程中需要一种产生固定长度值的哈希算法—BLAKE2b算法[3],BLAKE2b算法相比同类的哈希算法,速度更快,具有可并行实现的设计结构.针对可并行实现的结构,现有两大主流硬件实现方法:G/2结构和1G结构[4,5].两种结构可根据硬件的特点进行调整.大多数学者采用Xilinx的Virtex实现BLAKE系列算法,文献[6-9]对各个版本实现BLAKE2b算法的频率与吞吐率进行分析.硬件实现BLAKE系列算法的研究已有很多年,2010年,文献[6,7]提出了BLAKE-256作为SHA-3候选算法在Aumasson 1G并行结构基础上增加寄存器,构成流水线结构,提升吞吐率,在Altera Stratix III FPGA芯片上运行频率为46.97MHz,但未将整体算法在硬件上实现;同年,Karri等人提出BLAKE-128利用G/2结构以及移位寄存器的ASIC实现[8],频率和吞吐率分别为67.5MHz,281.61Mbps,但与Xilinx Virtex-4 FPGA实现相比,性能并未提升;2014年,Nuray等人[9]在Virtex-6 FPGA上利用G/2并行结构的流水线实现BLAKE-512,其频率为329 MHz,吞吐率250Mbits/s,其频率虽然有较大提升,但吞吐率有所下降.
相比于传统的人工设计编写RTL代码实现BLAKE2b算法,本文采用Intel最新的FPGA SDK for OpenCL技术,针对此技术特点对BLAKE2b算法进行优化,省略SIGMA操作,减少CPU和与内存之间交互访问时间;利用loop展开技术以及pipeline,减少数据依赖.面向FPGA实现优化后的OpenCL代码,将OpenCL代码直接编译为硬件配置文件,并在Terasic DE5-Net FPGA开发板上实现.
2 BLAKE2b算法简介及应用于 Equihash算法中的优化
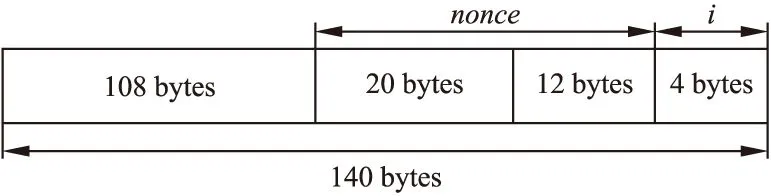
BLAKE2b应用于Equihash算法如图1所示,区块头数据和一个随机数nonce以及输入参数i作为BLAKE2b参数,计算生成220个200位的哈希数据,利用广义生日算法对哈希数据进行异或碰撞求解.若通过验证条件,则求解成功,否则重新开始计算.BLAKE2b单次计算可以生成512位哈希数据,可分为2组200位数据,Equihash共需219次BLAKE2b运算,运算量较大.
2.1 BLAKE2b算法简介
BLAKE2b可处理0~2128间任意字节长度的数据,按128 字节分组,不足128字节时补零填充,运算后可产生1~64 字节长度的哈希数据,具体参见BLAKE2b算法文献[3],本文仅对改进部分做必要说明.
1) G(a,b,c,d)函数定义如式(1),8个G函数操作,执行12轮,如式(3).
(1)
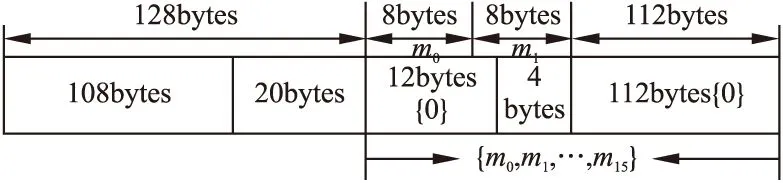
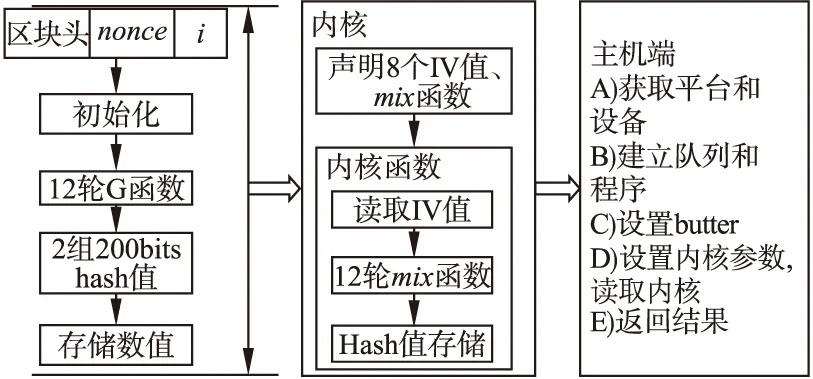
其中mσr为SIGMA表(10×16 个常量)中的值,r(1 p=σr mod10(2i)q=σr mod10(2i+1) (2) 其中σr mod10是SIGMA表中的第rmod10行,σr mod10(2i)为该行第2i个值. G0=(V0,V4,V8,V12);G1=(V1,V5,V9,V13);G2=(V2,V6,V10,V14);G3=(V3,V7,V11,V15);G4=(V0,V5,V10,V15);G5=(V1,V6,V11,V12);G6=(V2,V7,V8,V13);G7=(V3,V4,V9,V14); (3) 其中V0,…,V14,V15为存储G函数计算过程的存储变量,即将每次计算的结果都存储到这16个中间变量,用于每一轮的计算. 2) 最终输出值,可参考文献[3]中附录A.1 (4) Equihash算法中,用BLAKE2b处理长度为144 字节的数据块,并在服务器端给定的随机数基础上,按序列生成220组200位哈希数据.BLAKE2b处理的数据具体格式如图2所示,108字节的区块头数据,32字节的随机数nonce,4字节的用户输入值i. 图2 输入数据格式Fig.2 Format of input data 将32 字节的nonce值分成20+12字节两部分,先计算108+20=128字节输入数据,这部分只需计算一次;依次取i为0~220-1. nonce是任意32字节随机数,可进一步优化,限定其低12字节全为0,将12字节0值与4字节i组合,同时补齐112字节的0值,构成下一组128 字节的数据,以8字节为单位划分为16个信息块mσr,即是m0=0,m1=i,其余m2~m15均为0.如图3所示: 图3 优化后数据组合Fig.3 Optimized data combination 本文将mσr(2i)、mσr(2i+1)作为G函数的新增输入参数,分别赋值给x、y,G函数重新定义为mix(a,b,c,d,x,y)函数,公式如下: a=a+b+x;d=(d^a)>>32;c=c+d;b=(b^c)>>24;a=a+b+y;d=(d^a)>>16;c=c+d;b=(b^c)>>63; (5) 采用mix函数实现G运算后,每一轮中的8个G操作需要展开调用mσr,按调用顺序给定不同的mσ(2i)和mσ(2i+1)作为x、y参数值,此时可将mσr提前计算,并编码到源程序中.例如在第一轮、第二轮计算中8个mix函数定义如下: //round1 mix(V0,V4,V8,V12,0,m1);mix(V1,V5,V9,V13,0,0); mix(V2,V6,V10,V14,0,0);mix(V3,V7,V11,V15,0,0); mix(V0,V5,V10,V15,0,0);mix(V1,V6,V11,V12,0,0); mix(V2,V7,V8,V13,0,0);mix(V3,V4,V9,V14,0,0); //round2 mix(V0,V4,V8,V12,0,0);mix(V1,V5,V9,V13,0,0); mix(V2,V6,V10,V14,0,0);mix(V3,V7,V11,V15,0,0); mix(V0,V5,V10,V15,m1,0);mix(V1,V6,V11,V12,0,0); mix(V2,V7,V8,V13,0,0);mix(V3,V4,V9,V14,0,0); 相比于式(1)(2)(3)调用SIGMA置换操作,当采用上述nonce低12字节全取0优化时,m0、m2~m15均为0,可直接用0作为参数调用mix函数,编译器可以生成优化代码.采用本优化方法,可优化掉SIGMA置换操作,BLAKE2b计算一次减少12×2次CPU对内存的访问,减少运行时间. 在FPGA上实现OpenCL代码时,FPGA一般只含1个或少数几个计算单元,但可采用流水线技术提高吞吐率.当数据有依赖时,FPGA可利用流水线技术隐藏等待周期. 利用loop 展开及pipeline技术,结合算法特点,将循环部分无数据依赖部分展开为流水线结构或者并行计算结构,提升计算效率. 不同于直接利用RTL代码实现定制硬件结构,采用将OpenCL技术综合为硬件的技术,访存的频率高低会影响FPGA计算效率,均衡全局内存和局部内存的访问效率,才能达到更好的吞吐量.CPU对global memory 访问次数越少,则运行性能更好. 如图4所示,本文将BLAKE2b算法部分编写成内核代码,同时编写了主机端代码.主机端程序主要包括A、B、C、D、E五部分;内核部分主要包括常量定义和内核函数定义.内核函数外部声明8个IV常量,内核函数包括读取IV值、12轮mix函数、Hash值存储三部分,各部分作用如下: 图4 优化后BLAKE2b的OpenCL实现Fig.4 OpenCL implementation of optimized BLAKE2b 1) 读取IV值:由于IV定义为内核函数外部local memory常数,减少CPU的外部访存时间. 2) 12轮mix函数:Equihash算法中需要220组200位哈希值,各组数据是无依赖的,因而可以并行计算,根据开发板资源,本文将“#pragma unroll N”中N设置为16,Intel离线编译器会自动将无依赖数据进行展开实现. 3) Hash值存储:将hash定义为global memory动态指针数组,存储哈希值. 本文修改了BLAKE2b算法区块头及、nonce数据以及输入数据i的组合方式,略去SIGMA置换部分,减少了221次SIGMA置换,即减少了CPU对global memory访问时间.BLAKE2b算法每轮间有数据依赖,12轮需串行计算,同一轮中的8 个G运算,前后4个之间无数据依赖,可并行计算.明确BLAKE2b算法中的数据依赖关系后,可以通过在OpenCL代码中手工展开每轮前后4个G运算,指导离线编译器生成如图5所示的流水线结构.系统在每一轮构建2级流水线,分别并行计算前后4个G运算,12轮共24级,流水计算i~i+23组数据. 图5 流水线结构Fig.5 Structrue of pipeline 本文采用友晶公司的DE5-Net以及Intel 系列的CPU实现了优化前和优化后BLAKE2b算法,分别计算了220组哈希值,共输出1G bits哈希数据.Intel i5/i7 CPU有睿频技术,表1中时钟频率是测试时CPU-Z软件显示的实际频率.所测试代码没有利用多线程技术,测试结果是单核运行结果.最终测试结果如表1所示. 表1 测试结果 测试平台优化前优化后时钟频率(MHz)时间(s)吞吐率(Gbits/s)时钟频率(MHz)时间(s)吞吐率(Gbits/s)Inteli5-3210MCPU28931680.0060289613.160.0760Inteli7-8750HCPU3993114.920.006940927.0610.1416IntelXeonE5-2670C2CPU349055.3750.018126001.880.5319DE5-Net///226.30.03231.47 BLAKE2b算法优化前,进行一次BLAKE2b计算需要进行12×2轮的SIGMA表常量的置换,因Equihash算法需要219次BLAKE2b算法的计算,因此需要访问219×12×2次SIGMA常量表,优化前BLAKE2b算法在Intel系列CPU实现,其中Intel Xeon E5-2670 C2 CPU运行时间最短,为55.375秒;在Intel i5处理器上运行时间最长为168秒.优化BLAKE2b算法后,本文将SIGMA置换表略去,重组输入数据,略去SIGMA置换表中数据,预计算mσr值,写入mix函数参数中,减少了219×12×2次对常量内存的访问,优化后的算法在Intel系列CPU上运行,运行时间均有不同程度的减少.将优化后的BLAKE2b是我OpenCL代码面向硬件编译时,针对DE5-Net开发板以及BLAKE2b特点,每一轮8G函数展开为两级流水线结构,即由8个时间单位缩短为2个,提升了75%的计算效率.DE5-Net运行时间最短,为0.032秒,吞吐率为31.47 Gbits/s. 分析以上测试结果,采用略去SIGMA置换,减少了本地访存操作,利用流水线结构,缩短了运行时间;在优化掉SIGMA操作后,既不改变输出数据,又满足Equihash算法需求. Equihash算法中需要用BLAKE2b算法生成220组200 位哈希值,计算效率很重要.可以通过优化输入数据模式,利用构造出的大量零值数据和预编码,省略SIGMA计算操作.在面向FPGA实现时,利用循环展开以及流水线等技术,实现计算过程并行化,提高了吞吐率,实验结果表明,优化后BLAKE2b算法运行时间大大缩短,在DE5-Net FPGA板卡上吞吐率可达E5-2670 C2 CPU的59倍,可提高Equihash算法求解速度.2.2 BLAKE2b应用于Equihash算法中的优化
3 Intel FPGA SDK for OpenCL技术特点及BLAKE2b优化实现
3.1 Intel FPGA SDK for OpenCL技术特点
3.2 BLAKE2b优化实现

4 实验结果
Table 1 Results
5 结 语
