基于KECA-IGKDE的离心式冷水机组故障检测
2019-12-03
(杭州电子科技大学 自动化学院,浙江 杭州 310018)
随着现代化工业的快速发展,制冷系统日益复杂化,若系统发生故障,会导致系统运行异常,造成无法估计的损失。通过对系统过程性能监控来检测和诊断故障的发生,可提高过程的可靠性和系统的效率,有效减少能源的损失和节约运行成本[1]。其中基于数据驱动的多元统计方法被广泛应用于制冷系统[2],它无需精确的数学模型且相对简单。
在多元统计的故障检测算法中,最基本的方法是主元分析法[3](Principal Component Analysis,PCA)。胡云鹏[4]等人针对螺杆式冷水机组的复杂性,采用PCA故障检测,然而,PCA假定过程变量具有线性关系,制冷系统却是一个多变量、多工况、高耦合系统,过程数据具有非线性、非高斯的特点,PCA的检测效果不理想。针对非线性问题,Schölkopf[5]等人提出核主元分析法(Kernel Principal Component Analysis,KPCA)。杨亚伟[6]将KPCA应用于定风量空调系统检测,与PCA相比可更有效地检测故障,但KPCA未考虑特征向量对检测效果的影响。Jenssen[7]在KPCA的基础上,提出核熵成分分析法(Kernel Entropy Component Analysis,KECA),目的在于挖掘高维空间中能够保持低维空间数据Renyi二次熵的坐标轴作为最优投影方向。常鹏[8]等人将KECA应用于间歇过程故障监测,相比较KPCA检测率有明显优势,但仍然使用基于高斯假设的传统统计量与控制限,并不满足复杂系统的要求。
为此提出KECA-IGKDE故障检测方法。KECA以Renyi二次熵大小作为选取主元的指标,确保降维时信息损失最小。经投影后形成角度结构,故提出CS统计量,与基于高斯假设的SPE统计量相比,具有一定的优势。采用核密度估计(Kernel Density Estimation,KDE)获取CS统计量的控制限,但是KDE平滑因子选择对于检测的正确率和虚警率有严重的影响。采用改进的灰狼算法(Improved Gray Wolf Optimization,IGWO)对平滑因子寻优,与GWO相比,IGWO改进了局部搜索和全局搜索平衡性,并且避免陷入局部最优,提高了收敛速度。将本文方法应用于ASHRAE RP-1043离心式冷水机组[9]进行故障检测,验证了该方法的有效性。
1 基本原理
1.1 核熵成分分析
核熵成分分析是基于Renyi二次熵和Parzen窗提出的[7]。假设Renyi二次熵是连续的,其表达式为
(1)
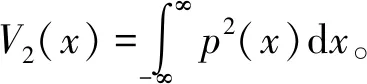
(2)
式中,K(x,xt|σ)为窗函数,即K(x,xt)=exp(-0.5‖x-xt‖2/σ2)。利用卷积定理对V2(x)估计得:
(3)
式中,I为N×1的向量且每一项值为1。
将核矩阵分解为
K=AAT=(ED0.5)(D0.5ET)
(4)
式中,D为特征值λ1,λ2,…,λN组成的对角矩阵;E为对应特征向量e1,e2…,eN所组成的矩阵。经计算,V2(x)表示为
(5)
式中,ψi为每一项的熵值,表明特征值与特征向量对熵值均做出贡献,即熵值的大小不能完全取决于特征值的大小。

1.2 CS统计量
CS统计量是两类概率密度函数pi(x)和p(x)之间“距离”的度量,衡量两类概率密度函数间的相似度程度的高低[10]。定义为
(6)
经过Parzen窗化简计算得:
VCS(pi,p)=cos∠(mi,m)
(7)
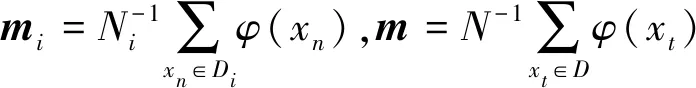
从式(7)可以看出,CS统计量只与主元有关。若正常工况模型与测试模型两者相似度较高,统计量较大,则系统处于正常运行;反之统计量偏小。
1.3 KDE确定控制限
CS统计量存在向量相乘的关系,难以确定分布规律,故引入核密度估计确定控制限。KDE是一种非参数估计,避免对数据分布作任何假设,从样本本身研究其分布[11],定义如下:
(8)
式中,N为样本的数量;K(x)为核函数;H为平滑因子;xi为样本数据中某一观测值。
实际应用中,核函数的形式并不重要,一般选择高斯核函数。然而,KDE的估计精度与H直接相关,如果H过小,产生一个交错估计,则整个函数波动较大;若H过大,产生平滑估计,则函数的微小波动将会被平滑掉[12]。因此,选择一个合适的平滑因子,可以有效提高检测率。
1.4 基于IGWO的KDE参数优化
GWO是一种新的元启发式算法,通过灰狼对猎物的包围、围捕、攻击进行模仿,寻找最优。该算法原理简单,需调整的参数少[13]。
在设计GWO时,定义最优解为α狼,第2个和第3个最优解为β狼和δ狼。其余的最优解为ω狼。在GWO算法中狩猎(优化)由α,β,δ狼指导,ω狼由这3只狼指挥。首先对猎物进行包围,该过程定义为
D=|C·Xp(t)-X(t)|
(9)
X(t+1)=Xp(t)-A·D
(10)
A=2a·r1-a
(11)
C=2·r2
(12)
式中,t为迭代次数;A、C为加权系数;Xp为猎物的位置向量;X为灰狼的位置向量;a为从2~0的线性递减常数,a=2-2t/T,T为最大迭代次数;r1、r2为[0,1]的随机向量。
模仿灰狼的围捕行为时,利用α,β,δ狼确认猎物可能出现的地点,该算法优化过程就是保留目前为止前3个最优解,同时迫使ω狼不断更新位置。该过程定义如下:
Dα=|C1·Xα-X|,Dβ=|C2·Xβ-X|,Dδ=|C3·Xδ-X|
(13)
X1=Xα-A1·(Dα),X2=Xβ-A2·(Dβ),X3=Xδ-A3·(Dδ)
(14)
(15)
式中,X(t+1)为当前迭代的最优解。
灰狼搜索猎物在数学模型上是通过减少a的值来接近猎物,同时A伴随着a线性减少。若|A|<1,则攻击猎物,进行局部搜索;若|A|>1,则发散去寻找新的最优解,进行全局搜索。由此可知,GWO一半迭代用于局部搜索,一半迭代用于全局搜索,忽略了两者之间的平衡性。为解决这个问题,提出改进的收敛因子公式,用指数函数代替线性函数,使全局搜索达到70%,局部搜索达到30%,具体表达式为
(16)
由于ω狼向α,β,δ狼逼近时,寻优逐渐趋近收敛,此时存在陷入局部最优的问题。考虑到最佳狼随机系数的影响,针对位置更新提出一种新的策略,表达式如下:
(17)
2 KECA-IGKDE故障检测方法
KECA-IGKDE算法应用于冷水机组的故障检测,分为离线训练和在线检测两个部分,如图1所示。
2.1 离线训练
离线训练步骤如下。
① 选取正常工况的数据,将数据进行预处理,以过滤掉瞬态数据,而后将数据进行标准化。
② 对样本数据建立核矩阵。按式(4)将核矩阵分解,得到相应的特征值与特征向量,从而由式(5)计算Renyi二次熵,根据熵值的贡献率选取相应的主元。本文选择累计贡献率高于99%的主元。
③ 按式(8)利用KDE计算CS统计量的99%分布值。使用IGWO算法优化KDE的平滑因子,适应度函数为故障检测率,从而获得最优控制限。
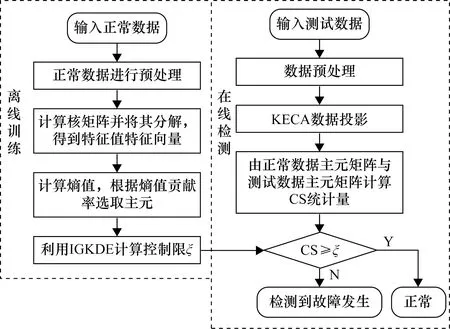
图1 KECA-IGKDE故障检测流程图
2.2 在线检测
在线检测步骤如下。
① 将系统实时运行的数据采用与离线训练相同的方法进行预处理和标准化。
③ 按式(7)分别利用离线数据投影均值m0与在线数据投影均值m1计算CS统计量,与监测控制限相比较,若高于控制限,则说明未检测到故障;若低于控制限,则说明发生故障。
3 实验验证
采用ASHRAE RP-1043冷水机组的实验数据进行该算法的仿真。该实验对象是一台90 t的离心式冷水机组,制冷量约为316 kW,制冷剂为R134a。机组运行在27个不同的工况,共采集64个参数,其中由传感器采集的参数有48个,剩余16个参数由VisSim软件计算得出[9]。该试验模拟7种典型的单一故障,每一种故障引入4种不同程度(SL1,SL2,SL3,SL4)的故障,如表1所示。

表1 离心式冷水机组故障
3.1 数据预处理
在进行实验仿真之前,需要将选取的数据进行稳态检测以过滤掉瞬时操作的数据,采用Glass[14]等人提出的几何加权平均数和方差的方法进行实现。选择蒸发器进水温度、蒸发器出水温度和冷凝器进水温度为稳态特征变量,阈值设定为0.2 ℃,两次测量之间的时间增量为10 s,时间窗口为80 s。经过稳态检测后,均匀选取27个不同工况下200个样本作为训练集,500个样本作为测试集,设定在第200个样本处引入故障,其中每一类故障的4种不同程度故障均有500个样本。
3.2 参数选择
该检测模型的参数对检测性能有重要的影响,共有两个参数需要进行优化:主元数S和KDE的平滑因子H。
首先确定主元数S,选取熵值累计贡献率超过99%的主元。结果表明,保留的主元个数为5。
对于KDE的平滑因子,采用IGWO进行优化。初始化狼群的数目为30,狼群迭代的次数是100。由于实验包括1种正常工况和7种故障(包含4种不同程度的故障),不同的模型具有不同的控制限,故需要确定29种不同的控制限,每种模型平滑因子如表2所示,其中正常工况平滑因子为2.938。

表2 不同模型最优平滑因子
正常工况、故障3程度SL1的适应度曲线如图2所示。由图2可知,IGWO迭代次数在31、35处达到收敛,收敛速度明显高于GWO和PSO,并且收敛精度更高,从而表明IGWO在KDE参数优化上更具优势。
3.3 检测结果与分析
检测性能基于两个指标:故障检测率(Fault Detection Rates,FDR)和虚警率(False Alarm Rates,FAR),具体计算公式可参照文献[15]。选取正常工况、故障3的两种程度为例,比较SPE统计量和CS统计量,并给出监测统计图。图中横坐标为采样数,纵坐标为统计量,虚线为99%的控制限。
对正常工况下故障检测结果如图3所示,从图3(a)可知,SPE进行故障检测时有一部分虚警的数据点,FAR为2%,而CS进行检测的FAR为0%,说明所提出的方法的FAR有明显的改善。分析可知,SPE的前提假设是满足高斯分布,而冷水机组的过程数据并不满足这一要求,故SPE检测导致频繁的误报。
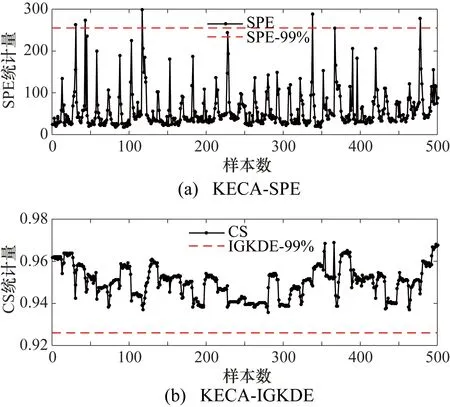
图3 正常工况下两种模型监控对比
故障3程度SL1、SL3的仿真结果如图4和图5所示。从图4(a)可以看出,SPE在样本的初始阶段仍有虚警点,在样本的第207个数据点检测到发生了故障;图4(b)CS在故障发生的第200个样本立即检测到,这是由于正常数据与故障数据的角度结构发生变化,相似度迅速减少,从而CS的值低于控制限。虽然所提出的方法相比KECA-SPE提高了检测性能,但是在较小的程度上仍不敏感。随着故障程度加深到SL3,如图5所示,故障检测率明显提高,此时SPE在样本第204检测到故障,这是由于冷水机组故障程度增加,对各个变量的影响也随之加深。
表3为KECA-SPE、KECA-CS两种不同统计量的FDR,每一种故障的FDR随着故障严重程度的增加而增加。对比这两种方法,所提出的方法能够获得更好的FDR。其中故障程度为SL1时,故障1、故障4、故障5、故障6和故障7的FDR均达到60%以上。针对故障6和故障7特别灵敏,在4种不同程度下均能达到100%,故障1和故障5在SL3和SL4的程度下也能达到100%的检测率。唯一例外的是故障2,FDR并没有随着严重程度的增加而明显增加,这是由于在检查冷冻水循环泵的健康状态和蒸发器上冷冻水压降这两种情况下,测量的变量较少。基于KECA-SPE故障检测性能不佳,主要原因有以下两点:首先基于SPE的过程监控对数据的概率分布和相依性做出高斯分布的假设,得到的控制限并不准确,导致FDR降低;其次是SPE在宽范围工况灵敏度低。

图4 故障rl在SL1下两种模型监控对比

图5 故障rl在SL3下两种模型监控对比

表3 两种不同方法的FDR对比
4 结束语
提出一种新的基于KECA-IGKDE的故障检测方法,有效地解决了冷水机组过程监控的非线性和不确定性导致的检测性能低下的问题。该方法是基于KECA投影后能够挖掘不同状态数据间的角度结构,构造新的CS统计量,并使用KDE确定控制限,而KDE平滑因子影响检测率,通过IGWO算法精确快速搜索最优值,以达到优化KDE平滑因子的作用。该方法不需要对数据的分布做出任何假设,适合非高斯分布的过程数据。将该方法应用于离心式冷水机组,并与传统的基于高斯假设统计量SPE进行比较,结果表明,对于同种程度下的故障,基于KECA-IGKDE的方法比基于KECA-SPE的方法在FAR和FDR方面表现更好。
