全景绿视率自动识别和计算研究
2019-11-30张炜周昱杏杨梦琪
张炜 周昱杏 杨梦琪
近年来,为促进城市绿色基础设施建设,评估绿色空间感知效果,绿视率(visible green index)评估已成为评定城市绿化空间的标准指标之一,用以指导城市公园、街道等绿色空间的规划设计。绿视率的概念首先由日本学者青木阳二提出,其定义为“在人的视野中绿色所占的比例”[1]。绿视率同人的视觉和心理感受密切相关,是一项可以让人们直观了解城市绿化水平的指标。绿化率作为城市绿色景观评价体系的常规标准之一,相关研究包括绿视率的影响因素及其对街道景观、环境舒适度、人的心理感受方面的影响等[2-3]。
在绿视率的实践应用中,也逐渐反映出一些问题。由于绿视率基于视野平面范围进行测量,其植被占比不能反映人视环绕空间中可视绿量的真实水平。同时,统计绿视率所依赖照片的拍摄角度、镜头焦距等指标具有主观性和不确定性,会对评估结果产生一定的影响。
近年来开始出现的全景影像摄影技术(panoramic photography),是一项使用特定设备或软件获取全景视野图像的摄影技术,可以捕捉记录相机环绕360°的全景影像,让观看者产生身临其境的效果。全景影像的获取通常使用多镜头相机拍摄直接获取,或普通相机拍照经后期拼合处理生成全景影像,目前全景摄影在Web街景服务、全景VR及摄影展示等领域已获得广泛应用。全景图像已成为绿视率研究中新的数据来源,如郝新华等[4]通过网络爬虫获取腾讯地图的街景图像,对每个点获取前后左右4个方向的平面图像,进行绿视率评估得出平均值。崔喆等[5]通过Python脚本调用地图API批量下载图片,下载取样点前后左右4个方向的街景图像,并将街景图转换成HSV色彩空间,提取其中的绿色部分进行绿视率计算。
但目前相关研究中,使用街景图分析城市街道绿量等指标时,主要通过截取街景全景图的沿街视角范围实现。此类方法本质上依然是基于二维视平面的研究,而并非完整的全景球面范围。因此,本研究拟从完整全景影像入手分析,通过等积投影转换,实现对全景图直接的识别和测量。
绿视率的计算通常采用网格法,即人为辨识图像中的植被区域并计算其所占网格面积的比率。通过计算绿色植物所占方格数量与总方格数量的百分比获得相应的全景绿视率。此方法对于少量数据的操作简便易行,但由于人工的介入,存在一定的主观性,面对大量数据难以快速处理。近年来一些研究者对绿视率的计算提出新的思路。如彭锐等[6]在传统绿视率计算方法上探索出一种新的自动化计算方法,利用HSL色彩空间模型对获取图像进行色彩解析。徐磊青等[7]基于公共空间布局效能和关键指标研究建筑界面与绿视率对街道环境迷人性的不同程度的影响,通过构建空间变量的虚拟场景以及虚拟现实技术(virtual reality,简称VR)沉浸式体验的方法,调查了体验者在不同绿视率环境下的主观感受。
深度学习(deep learning,简称DL)是指学习样本数据的内在规律和表示层次,使机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。目前,深度学习在人工智能技术领域中已经获得愈加广泛的应用[8]。近年来随着深度学习技术的发展,出现了一系列用于图像语义分割(sematic segmentation)的开源卷积神经网络模型。本研究分析和比较现有常用街景识别的卷积神经网络模型(convolutional neural networks,简称CNN)识别全景影像中的植被部分,以实现绿视率计算的自动化。
1 全景绿视率的特点和优势
本研究基于全景影像,在传统绿视率基础上,提出全景绿视率概念,并将其定义为:站在固定位置的人环视四周即360°球面视野中可视绿量占球面视野面积的百分比(图1)。计算公式为:

全景绿视率使用全景球面影像替代传统绿视率所使用的二维图像。与传统绿视率指标相比,全景绿视率具有两点优势:
1)全景绿视率综合反映指定场地环视360°的绿视率,与人的主观视觉感受一致,切实可靠反映该场地周边环境绿量的可视情况。
2)全景图的拍摄过程不会因相机镜头方向、焦距大小、可视范围等因素产生影响,可以使得评估结果更为客观和准确。
2 全景绿视率的测量和计算方法
本研究基于全景影像,提出计算全景绿视率的方法步骤,包括全景影像获取、全景影像投影变换、可视植被面积计算。
2.1 全景影像获取
全景图影像的获取可通过2种方式:传统相机拍摄和多镜头全景相机拍摄。
1)用传统相机拍摄各取样点,沿水平方向每隔相同角度照相1次,以取样点多个视觉角度后期拼合而初步成像。即依据视觉特征对照片进行拼合处理。但此方法步骤复杂,须后期拼合处理。
2)利用全景拍摄设备,如多镜头全景相机等进行拍摄,直接获取全景影像,此方法便捷,能够获取同时空下不同视角的全景图。随着VR和影像业发展,全景设备应用愈加广泛,直接使用全景相机拍摄将是未来趋势。
2.2 全景影像投影变换
全景相机或相关设备所获得的全景影像一般为等距圆柱投影(equirectangular projection)。投影展开图为一张2 : 1的长方形图像。在等距圆柱投影图中,投影面积相等的区域其真实面积并不相等。为使全景图像的面积可量测,需要将其转换为等积圆柱投影(cylindrical equal-area projection)进行计算。具体计算过程为首先将原始等距圆柱投影转换为球面坐标,然后将球面坐标转换为等积圆柱投影。
2.2.1 等距圆柱投影转球面坐标
等距圆柱投影是圆柱投影面与地轴平行,按经线长度不变的条件将经纬线网投影到圆柱面上,再沿某一母线剖开展平的一种投影。此类投影纬线间隔与实地等长,经线与纬线表现为相互垂直的等距平行直线[9](图2)。
等距圆柱投影转为球面经纬坐标公式:
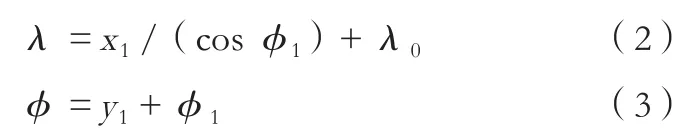
式中,λ是球面坐标定点所在位置的经度,φ是球面坐标定点所在位置的纬度,φ1是球面坐标标准纬线,λ0是球面坐标中央经线,x1是等距圆柱投影位置的水平坐标,y1是等距圆柱投影位置的垂直坐标。
等距圆柱投影转换后生成全景球面(图3)。
2.2.2 球面坐标转等积圆柱投影
等积圆柱投影是在与全景球面赤道相切的圆柱上按等面积条件进行投影,其中经线为等距平行直线,纬线为垂直于经线且间隔随纬度增加而间距逐渐缩小的平行直线(图4)。
全景球面转换为等积圆柱投影计算公式:

式中,λ是全景球面所在位置的经度,φ是全景球面所在位置的纬度,λ0是全景球面的中央经线,x2是等积圆柱投影位置的水平坐标,y2是等积圆柱投影位置的垂直坐标。
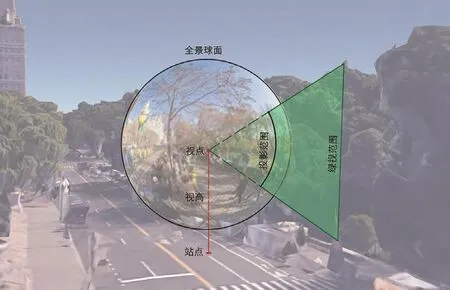
1 全景绿视率原理示意Schematic diagram of panoramic visible green index

2 等距圆柱投影Equirectangular projection

3 全景球面Spherical panorama

4 等积圆柱投影Cylindrical equal-area projection

5 神经网络模型图像语义分割过程 [14]Neural-network based semantic segmentation process[14]
2.3 可视植被面积计算
将全景图像转换为等积圆柱投影后,就可以直接测量其各部分投影面积获得其相对面积。通过等积投影图像中植被面积所占的比率计算全景绿视率,其计算公式为:

投影图像中植被面积通常用网格法进行计算,但面对大量数据时耗时较长。为了实现绿视率的自动识别,部分研究中使用GNU Image Manipulation Program、Adobe Photoshop等图像处理软件,基于RGB或HSL通道设置阈值,筛选提取其绿色像素信息,作为植被部分进行计算。但是,由于光照条件差异,植物茎干等非绿色区域的存在,以及其他绿色物品干扰等原因,单纯依赖于颜色信息,往往并不能准确代表植物范围。
本研究尝试使用基于语义分割的神经网络模型,对全景图像中的植被区域进行自动识别,以实现客观准确批量化地计算绿视率。并将其结果同传统人工判别计算绿视率的方法进行对比分析。
3 基于语义分割神经网络的全景绿视率自动识别
3.1 语义分割神经网络特点
神经网络(neural network)模型是通过模拟人类大脑神经元对信息处理的方式,建立数学模型,来分析、学习和解析数据。卷积神经网络是前馈神经网络的一种,在图像识别中具有广泛的应用,其通常由顶端的全连接层、一个或多个卷积层以及池化层构成[10]。神经网络进行图像处理需经过图像预处理、图像压缩、图像特征提取、图像分割和图像识别五大步骤[11-12],且具有以下特点:处理速度快;自适应能力强;可以建立数学模型来分析图像信息;可处理图像中的非线性问题;可预处理图像中的噪声或杂质数据等[13]。
语义分割是图像分析的一项常用操作,描述了将图像的每一个像素同一个类型标签(如花朵、人物、道路等)建立联系的过程(图5),其通常应用于自动驾驶、工业监测、遥感影像分类以及医学影像分析等领域。
3.2 模型选择和数据集来源
本研究选择基于MXNet进行封装的Wolfram Neural Net Repository所提供的5项卷积神经网络模型[15](表1),对全景图像中的不同物体进行识别和分类,并针对植被比较各模型的识别效果。
各模型训练数据集均来自Cityscapes数据集。Cityscapes数据集来源于基于语义理解进行手动标注的25 000张街景图像,其中包括精细注释5 000张和粗略注释20 000张街景图像。图像源自德国50个城市的街景图像[19]。每张街景图像经人工识别将图像基于内容进行分割,标注共划分为8组30种类型(表2)[20]。
各模型语义分割识别的准确性可使用交并比(Intersection over Union,简称IoU)进行衡量。IoU是一项衡量目标识别结果和模型预测结果之间重叠百分比的指标。IoU指数的计算公式为:
IoU=(目标结果∩预测结果)/(目标结果∪预测结果) (7)
平均交并比即mIoU,通过计算不同类别的IoU指标的平均值,用来衡量图像语义分割结果的准确性[21]。
3.3 不同模型处理结果比较
2019年3月6日,使用Garmin VIRB 360全景相机在华中农业大学校园拍摄全景图像,通过上述各卷积神经网络进行识别分析,所获得全影像分辨率为5 640×2 820像素。为提高识别速度和效率,将其压缩至分辨率1 600×800像素,并转换为等积圆柱投影图片进行识别。
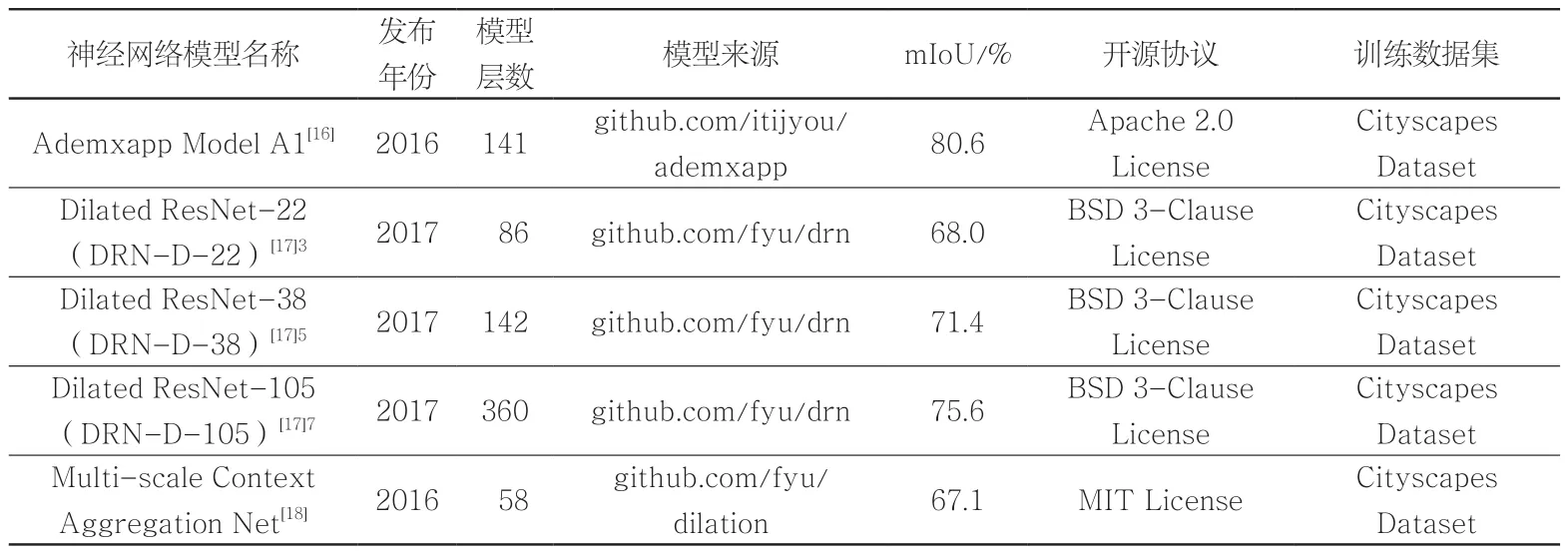
表1 不同卷积神经网络模型相关信息Tab. 1 The information of different CNNs
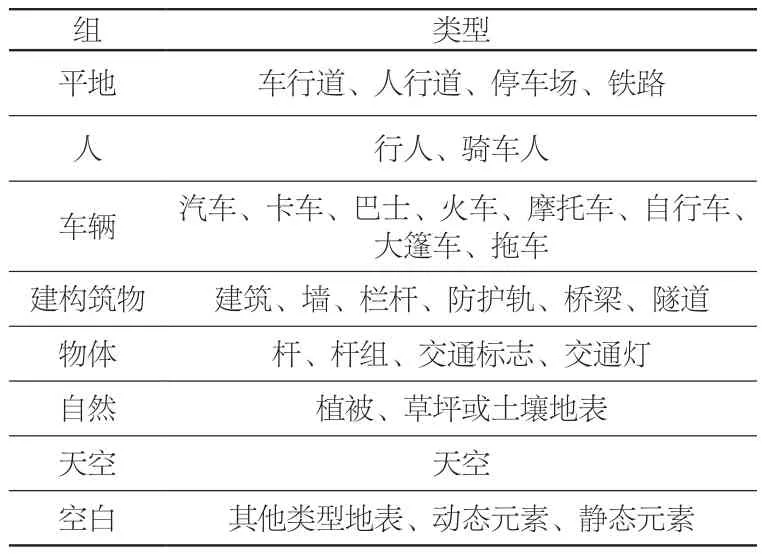
表2 Cityscapes数据集的类型划分Tab. 2 Type classification of Cityscape database labeling
为定量评估各模型识别的准确性,本研究使用图像编辑软件,对等积全景图的植被范围进行人工识别,并转换为二值图像进行分析(图6)。
总体而言,对于树木部分的识别,相关神经网络会将树木枝干所占据的范围均识别为植被部分,而并不会划分枝叶之间的孔隙,这导致了对于存在大量枝干孔隙的全景图,各模型识别结果绿视率比依照传统绿视面积判别方法人工标定数据要高出5%~15%。但也由于神经网络并不识别植被间的较小孔隙这项特点,可以降低植被在不同季节因叶片数量、颜色、形态变化而产生的影响,从而保持在不同季相下识别和评估结果的一致性。
从不同模型之间的识别差异来看,各模型识别效果差异主要表现在对近景草坪和顶层覆盖空间的识别效果。Ademxapp Model A1对远景植被识别不够准确;Dilated ResNet-22对于覆盖空间中的植被识别误差较大,并将部分地表铺装错误识别为植被,Multi-scale Context Aggregation Net模型对远景和覆盖空间中的植被识别效果不够准确。为定量评估各神经网络计算结果的准确性,本研究将人工识别的植被范围作为标准数据(ground truth),计算各神经网络识别出的绿地范围的IoU。
依据mIoU计算结果(表3),各项模型识别准确度从高至低依次为:Dilated ResNet-105>Dilated ResNet-38 >Multi-scale Context Aggregation Net> Ademxapp Model A1>Dilated ResNet-22。因此,本研究使用Dilated ResNet-105进行绿视率测量的实证研究。
4 全景绿视率测量实证
基于前述全景绿视率的评估方法,选取武汉市紫阳公园,对公园内各级园路和活动广场的全景绿视率进行测量评估。紫阳公园是位于武汉市武昌区的综合公园,因紫阳湖得名。公园面积约28.0 hm2,其中水体面积约11.7 hm2,陆地面积约16.3 hm2。
4.1 样点选择
全景影像拍摄时间为2019年3月12日(周二)09:30—15:30,此期间游客较少,可以降低拍摄过程中游人对测量的干扰。拍摄当天平均气温16℃,光照条件良好,园内落叶树尚处于萌芽期,枝叶尚不十分茂密,郁闭度较低。
基于紫阳公园游人可进入游览的区域进行等距选点。沿各级园路中心线、道路交叉口、广场区域每间隔30 m进行一次拍摄,获得不同活动区域的全景绿视率情况。场地内水域和种植区内部等游人不可进入区域则未进行拍摄。拍摄期间由于紫阳湖湖心岛和中心路段因施工封闭,因此未能进入拍摄。最终总计获得126个拍摄点(图7)。
4.2 全景影像获取
全景图拍摄设备为Garmin VIRB 360 全景相机,合成全景影像照片分辨率为5 640×2 820像素。相机自带GPS+GLONASS卫星定位系统,可自动记录拍摄影像的地理坐标。相机的拍摄高度根据国家卫健委于2015年发布的中国成年男女的平均身高设定视点高度,为1.6 m。
4.3 影像数据识别与计算
在获得影像数据之后,将原始影像的等距圆柱投影转换为等积圆柱投影,使用Dilated ResNet-105卷积神经网络对全景影像中绿色植被部分进行识别分析和计算(表4)。
基于Dilated ResNet-105卷积神经网络识别和计算后,得出紫阳公园出入口、各级园路及活动广场的全景绿视率(图8)。综合全园样点计算得出公园可游览区域的平均全景绿视率为51.18%。从全景绿视率的空间分布来看,各路段绿视率差异不大。其中三级路的平均全景绿视率最高,活动广场最低,公园主路北段和南段绿视率最高,东南和西北路段绿视率略低。区域内平均绿视率从高到低依次为三级路>二级路>公园入口>一级路>活动广场。从全园来看,绿视率最高点为85.42%,最低点21.19%,绿视率最高点位于三级路,是铺设于大面积草坪上的汀步,上层植被为高大的乔木,顶层植被覆盖率高。绿视率最低点位于二级路,四周是大面积水域,植被距离摄像机镜头较远。因此在图像的识别过程中,绿色植被所占比例较低。
4.4 绿视率识别结果比较
为衡量卷积神经网络绿视率识别的准确性,本研究同时对126张全景图像绿视率进行人工识别计算。通过图像编辑软件,对等积圆柱投影的全景图植被范围进行人工标记,并转换为二值图像,依据面积百分比计算相应的绿视率。并将人工标记数据作为标定数据,计算神经网络识别植被区域的IoU。并以各张图像的IoU为横坐标,神经网络识别绿视率及人工识别绿视率分别作为纵坐标,绘制得出散点图(图9)。

6 不同卷积神经网络模型对全景图像的识别效果Result comparison of different CNNs
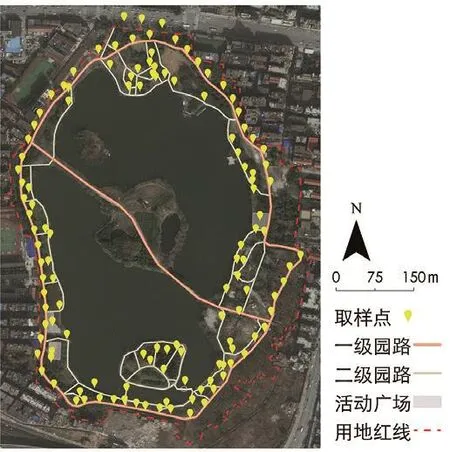
7 武汉市紫阳公园全景影像样点位置Locations of panoramic images at Ziyang Park in Wuhan
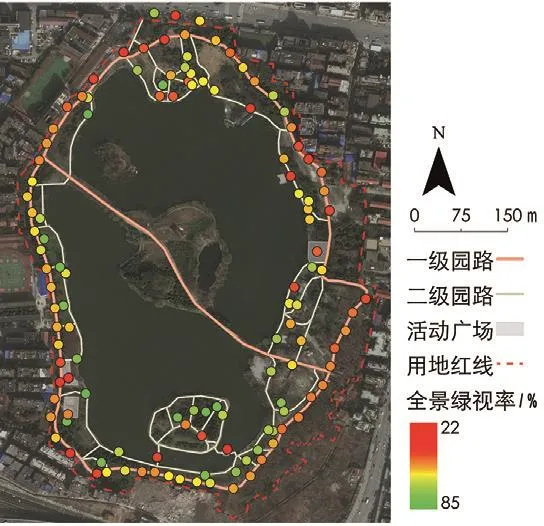
8 武汉市紫阳公园全景绿视率分析Distribution of panoramic visible green indices in Ziyang Park in Wuhan
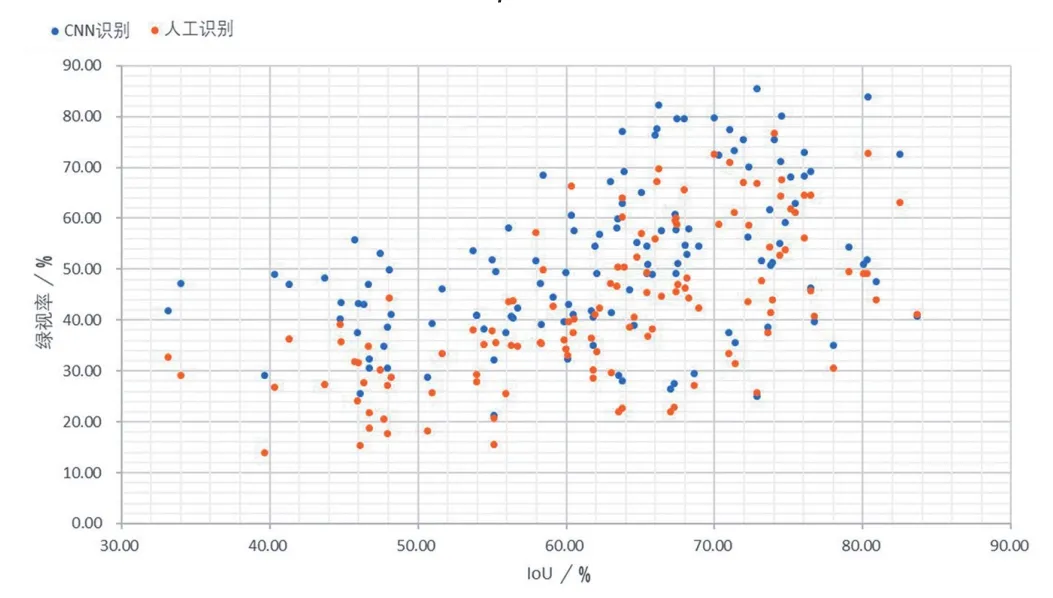
9 不同IoU下卷积神经网络识别和人工识别的绿视率分布The distribution of visible green indices recognized by both CNNs and human under different IoU
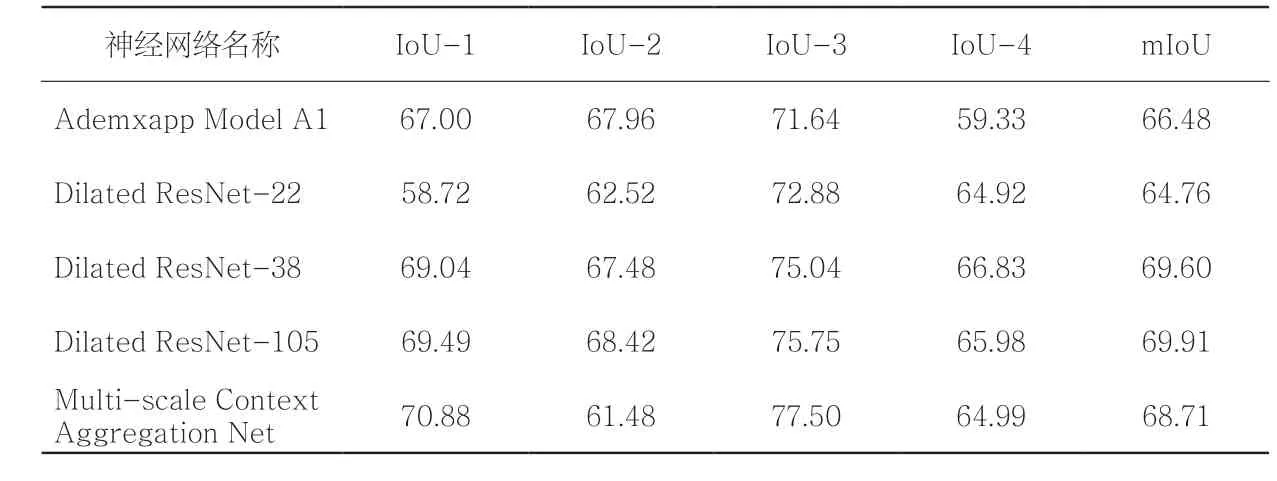
表3 神经网络模型对绿地部分识别结果的IoU比较Tab. 3 IoU comparison by different CNNs for green area identification单位:%

表4 基于卷积神经网络的全景绿视率识别结果Tab. 4 Panoramic visible green index identification by CNNs
经分析可知,使用Dilated ResNet-105卷积神经网络绿地范围识别的IoU在33.13%~83.68%之间,mIoU为62.53%。从绿视率识别结果来看,神经网络识别绿视率同人工识别的绿视率差异在0.40%~23.86%之间,平均差异为9.17%。图像识别的IoU越高,相应绿视率的平均偏差也就越低(表5)。
为分析卷积神经网络识别结果和人工识别结果间存在差异的原因,将二者植被区域的二值图像进行对比分析(表6)。
由于语义分割标记操作的惯例,卷积神经网络会将乔木枝干间的孔隙部分作为植被进行识别。而传统人工识别方法,由于植物孔隙颜色与植被存在显著区别,因此往往不会包含植物的孔隙部分。这导致了对于枝叶稀疏的乔木(表6中①~③所示),二者的识别结果存在显著差异。而对于枝叶茂密的植被范围,二者识别结果较为接近(表6中⑤~⑥所示)。
另外,由于本研究所选取的神经网络模型均采用Cityscapes街景数据进行训练,其数据集来源于德国城市街景,同中国公园环境存在一定差异。同时,对于圆柱投影下的全景图,由于相关要素存在一定的变形,影响了识别的准确性。在部分全景图的识别过程中,模型会误将树木枝干在地面上的投影、水中的倒影等识别为植被,或因地形变化而未识别出部分草坪。在拍摄过程中,相机底部三脚架不可避免会对全景图底部范围形成局部遮挡,对部分结果产生一定影响。
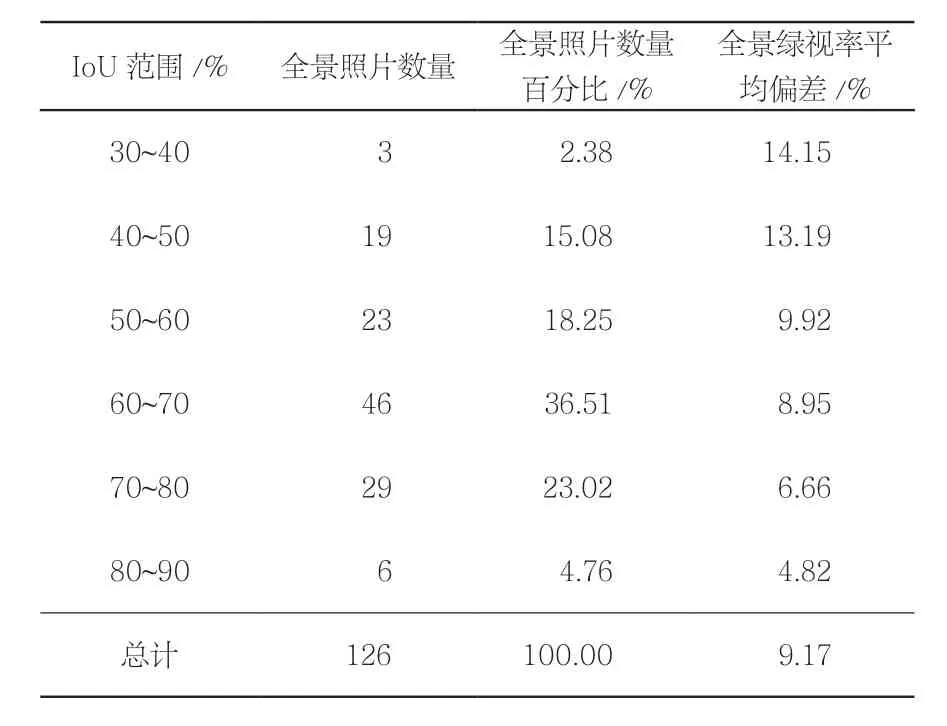
表5 卷积神经网络识别与人工识别效果比较Tab. 5 Comparison between CNN recognition and manual recognition

表6 部分图片的识别效果对比Tab. 6 Comparison of recognition results of some images
5 结论与讨论
本研究基于全景摄影技术,在传统绿视率的基础之上,提出了全景绿视率的概念。并将全景摄影所获得的等距圆柱投影通过坐标转换转为等积圆柱投影,用于测量植被所占区域的面积,并通过基于语义分割的卷积神经网络模型,实现全景绿视率的自动识别和计算。
目前普遍使用的全景图片通常使用等距圆柱投影,其图上面积并不代表真实面积,因此对全景影像进行等积投影变换,是实现准确测算其面积比率的先决条件。本研究通过将全景影像转换为等积圆柱投影,可以在实现图片面积可量测的同时,保持图片内容的易识别性,方便后续进行神经网络识别或人工判别。
通过对5项卷积神经网络模型的植被识别效果同人工判别结果比较发现,Dilated ResNet-105神经网络模型具有最高的识别准确性(mIoU为 69.91%)。
从实际案例应用来看,卷积神经网络识别计算的绿视率同人工判别结果之间存在一定差异,其主要原因在于卷积神经网络语义分割的识别特点,即前景物体中的孔隙并不会进行单独识别,造成绿地识别过程中乔灌木的孔隙统一作为植被范围,使其绿视率平均高于人工判别结果9.17%左右。但从另一角度来看,卷积神经网络语义分割的此项特点,可以显著降低不同物候期植物枝叶疏密程度对绿视率所造成的影响,使绿视率的评价结果在不同物候条件下保持一致性。
其他造成卷积神经网络绿视率识别存在差异的原因包括图像投影变形、地表阴影、水面投影等产生的影响。对于这些因素,后续研究中可以通过针对全景图的标定数据进行训练、调整神经网络参数、优化模型层级结构等方式,提升识别的准确性。
图表来源(Sources of Figures and Tables):
图1~4、6~9由作者绘制,图5引自参考文献[14];表1根据参考文献[15-17]相关神经网络模型的描述信息进行总结归纳;表2源自www.cityscapes-dataset.com/datasetoverview/#class-definitions;表3~6为作者绘制。
