人工智能助力医疗大数据行业腾飞
2019-11-29张玉满
张玉满
医学领域其实非常需要强人工智能技术:可解释的人工智能技术,可以智能推理的人工智能技术。
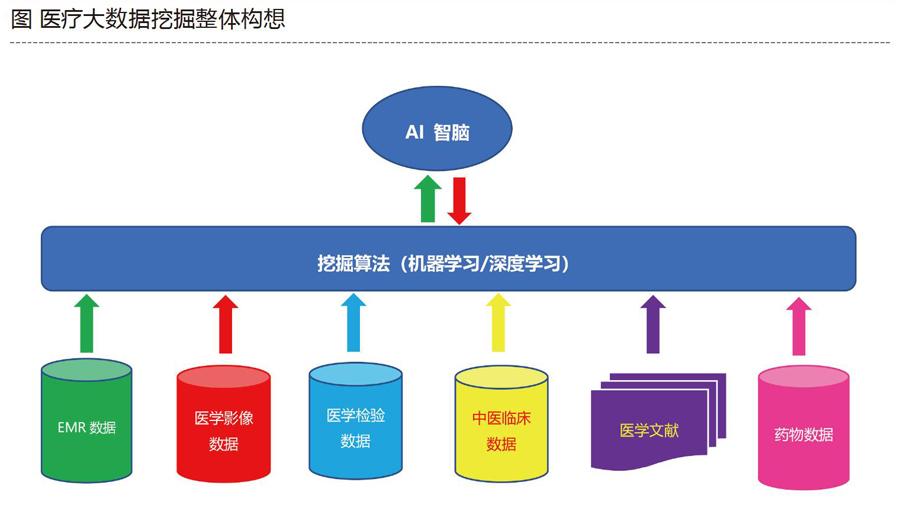
医疗大数据通常包括临床电子病历(EMR -Electronic Medical Record)、医疗影像(包括超声/CT/MRI/DR等影像)、医学检验数据(包括临床检验(如血常规)、病理数据、生化检验、微生物检验、寄生虫检验、免疫检验、分子检测数据(包括DNA/RNA等数据)、中医临床数据、医学文献、药物大数据、健康(体检)大数据、医疗保险大数据、公共卫生(事务)大数据等。这些数据的挖掘,将会极大地促进医疗领域的发展。比如,对临床大数据的挖掘,将大大缓解临床医生的工作强度,减少漏诊和误诊,进而提高诊疗服务水平,提高人民生活质量。
同时,由于医疗行业本身的属性,医疗大数据具有一定的敏感性,如隐私性、安全性等。特别是分子检测方面的数据,涉及特定人群(民族)的遗传信息,不应当大规模地流出国门,以免泄露民族特有(遗传)信息。国务院在2019年6月,国务院发布《中华人民共和国人类遗传资源管理条例》,并于2019年7月1日起正式施行。这是我国在医疗大数据保护方面的一个重要节点。
一、医疗大数据(挖掘)的价值
数据挖掘的出现是一个逐渐演变的过程,最早可以追溯到上世纪60年代。随着科技的发展,到上世纪80年代提出了KDD(Knowledge Discovery in Database)概念,泛指所有从源数据中发掘模式或联系的方法。KDD描述了整个数据发掘的过程,包括最开始的制定业务目标到最终的结果分析,而数据挖掘(data mining)描述使用挖掘算法进行数据挖掘的子过程。现在人们逐渐习惯于使用数据挖掘来涵盖整个过程。
随着计算能力的快速发展和人工智能(AI-Artificial Intelligence)技术的兴起,数据挖掘行业也进入高速发展时期。很多人工智能算法已经被应用在医疗大数据挖掘中,例如常见的机器学习/深度学习算法KNN(K-NearestNeighbor)、K-Means、SVM(Supported Vector Machine)、CNN(Convolutional Neural Network)、RNN(Recurrent Neural Network)、NLP(Natural Language Processing) 等已经得到很好的运用,请见后面章节的更多具体介绍。
医疗大数据挖掘能够发现一些复杂疾病的发病机理、(潜在)治疗靶点,同时也有助于显著缩短新药物研发周期,甚至发现用于治疗某些恶症的新药物(分子)。而且,对医疗影像数据的(机器)学习和挖掘,可以快速发现影像数据中的潜在病灶,并判断良恶性。
在医学文献方面,人工智能技术可以快速阅读大量的医学文献,从而帮助医学工作者及时更新自己的知识,并且在临床工作中做出更加全面的诊断。同时人工智能技术也大大简化了医学文献的编撰,进而大大节省临床医学研究者的时间,從而提高效率。
体检行业的医疗大数据也是很有价值的。它可以提供民众的健康指标、疾病分布图谱等。体检服务大都会提供基因检测、脑部MRI 检测、CT/超声扫描、常规血液检测等。这些服务产生的数据基本构成了完整的人类健康数据。
对于慢病研究而言,体检行业的数据可能比医疗机构(如医院)在某些情况下更有价值,因为体检机构有受检客户的逐年数据,可以更好地理解慢病发生的机理(时间/疾病状况/各种健康数据的演变过程)。
体检行业某头部知名公司,有分布全国各地的体检门店,并且可以构建不同区域、不同民族、不同遗传背景条件下各种慢病发生的机理和过程。医药行业应该很需要这样的数据。对政府来说,这些数据是了解全国人民健康状况的窗口,也是规划医疗保险基金的重要依据之一。
另外,体检行业提供了大部分医疗场景(疾病诊断和治疗相关场景除外),所以体检行业也是各种医疗AI产品的理想“试刀石”, 因为体检行业主要是筛查和防治,基本上不涉及治疗场景。如果医疗AI产品决策不那么准确,造成的影响比在医院(使用它)造成的影响小很多。
关于医疗大数据挖掘的整体架构,有一种设想:AI智脑+挖掘算法+医疗大数据。
现在医学界已经有学者在讨论“电脑医生”,包括一些国外知名企业正在大力推广的AI医生,其实是以上医疗大数据挖掘的具体应用之一。
下面我们举几个典型的利用人工智能技术来挖掘医疗大数据的例子。
二、医疗大数据挖掘和应用的实例
生成式对抗自编码器(AAE-Adversarial Auto-Encoders)在生成新型(化学药物)分子指纹图谱中具有广泛的应用前景。
生成对抗网络(Generative Adversarial Networks,GANs)这个概念,最早是在2014年由Ian Goodfellow提出的。GANs的基本原理和实现方式是让两个网络相互竞争。其中一个叫做生成器网络(Generator Network),它不断捕捉训练库中的数据,从而产生新的样本。另一个叫做判别器网络(Discriminator Network),它也是根据相关数据去判别生成器提供的数据到底是不是足够真实。
到现在为止,基于GANs的算法和应用层出不穷,其中比较常见的有DCGANs(Deep Convolutional GANs,卷积版本的GANs)、ImprovedDCGANs(高级深度卷积生成式对抗网络)、ConditionalGANs(条件生成式对抗网络)、InfoGANs(信息最大化生成对抗性网络)、WassersteinGANs(Wasserstein GANs)、ImprovedWGANs,BEGANs(Boundary Equilibrium Generative Adversarial Networks,边界生成式对抗神经网络)、 ProGANs(Progressive growing of GANs, 渐进式发展生成对抗网络)、CycleGANs(循环生成对抗网络) 等。
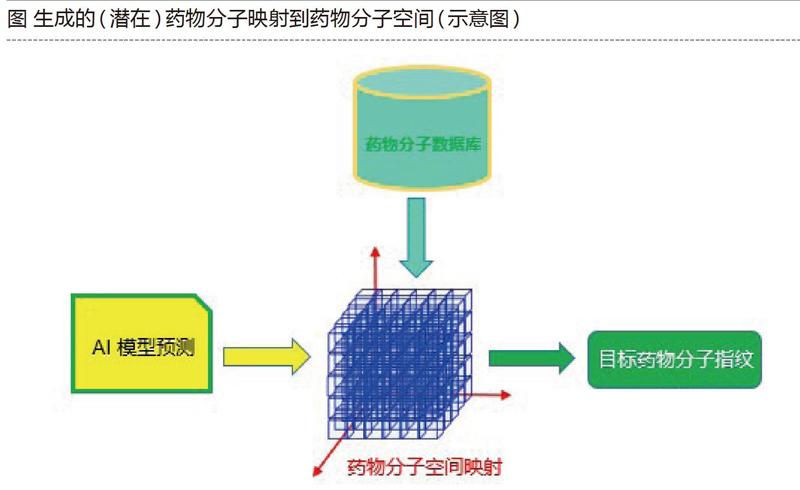
2017年某研究机构发表了一篇关于利用AAE模型(基于GANs原理)来预测(抑制)癌症的药物分子结构的论文:利用一个7层AAE架构,中间的隐藏层作为鉴别器。作为输入和输出,AAE使用二进制分子指纹和浓度的向量。在隐藏层还引入了一个负责生长抑制率的神经元,当其为负时,表示治疗后肿瘤细胞数量减少。
在训练AAE模型时,输入了NCI-60细胞系分析数据(6000多种化合物在MCF-7细胞系中的检测数据)。AAE模型的输出可以用来筛选PubChem中的7000多万种化合物,并选择具有潜在抗癌特性的候选(药物)分子。这种方法是人工智能药物研发引擎的概念原型,其AAEs模型可以用于生成具有(抑制癌症药物)分子特性的新(药物)分子指纹。
论文中还提到利用AAE模型还预测了六十几种化合物。它们中大部分化合物的抗癌活性已经在临床上被确定,甚至在某些情况下,这些化合物分子已经被用作治疗一些癌症的抗癌剂,包括白血病和乳腺癌。
其实,这里我们不妨做个大胆的延伸:如果用大量的临床癌症患者个性化数据(患者的基因数据,用药数据等)来训练AAE模型,当模型训练好了之后,输入特定癌症患者的临床数据,模型就应该可以生成相应的个性化(抑癌)药物分子。这样就可以在一定程度上实现复杂疾病/恶症的个性化治疗,从而提高患者的生命值。
这个模型在医药行业应该会得到大力发展。在互联网时代,大家常说的“网上半天,实验半年”,说的是做医学科研工作者应该充分利用互联网的力量来缩短研发时间。在当今的 AI时代,笔者认为应该改为“AI(模型跑)几天,实验几年”。可以说在AI时代医药研发的速度应该会得到极大地提升。
胰腺癌临床数据挖掘
笔者曾经参与过几个胰腺癌临床数据挖掘的项目。通常临床数据的挖掘是通过统计学、机器学习算法(及深度神经网络学习算法)来找到新的生物标志物、药物作用靶点、发病机制和预后康复是否良好的关键因子,甚至还可以预测患者的生存时间等。
常用的机器学习算法有逻辑回归、随机森林、支持向量机(SVM -Support Vector Machine)、集成算法(如XGBoost算法)。生物医学方面可能会用到基因图谱、信号通路分析(pathway analysis)、生物互作用网络等。笔者参与的挖掘项目成功找到预测胰腺癌晚期患者生存时间的基因位点。在另一批胰腺癌临床数据中也成功挖掘到一些新的基因位点(可以帮助医生明确患者胰腺癌发生的机理、新的用药靶点等)。
医学文献阅读/编撰“神器”
人身上的秘密太多了,即使科技发展到今天的程度,人类在医学方面还有很多未知的领域。所以,每年都会有大量的医学论文发表。医学科研工作者基本上没有办法及时阅读相关论文内容。
比如,在生物医学领域,平均每年有超过40万篇论文被发表,在2016年就有120多萬篇新论文发表,总论文数超过2500万篇。但人类的阅读能力几乎是不变的。据国外科学家估计,他们平均每年只能阅读不到300篇的论文。所以会有大量的论文没有机会阅读和跟进。这可能会极大地阻碍医学行业的高速发展。
最近,有美国AI学者发表了一篇关于医学文献智能编撰的论文,引起一阵轰动。笔者曾阅读过那篇论文及相关代码并且测试过模型,还试着生成一些医学文献的摘要和题目,应该说效果还是不错的。笔者设想如果把原论文用到的RNN(Recurrent Neural Network)模型替换成BERT(Bidirectional Encoder Representations from Transformers)模型,可能效果会更好。有兴趣的读者,可以自行改编相关代码。
笔者这里要指出的是论文编撰“神器”固然重要,但医学文献阅读“神器”其实对行业来说更为迫切—大量的医学文献没有被及时阅读,也就意味着好多前辈的努力没有被很好地传承。
要知道,和动物相比,人类文明能高速向前发展,离不开后辈科研工作者在前辈们取得的基础上继续推进。如果一切都要重新开始,那今天的人类社会文明可能要倒退不少年。
所以,大量的医学文献没有被很好地阅读和继承,可能也是阻碍医学行业以更高速度向前发展的因素之一。当然,虽然NLP(Nature Language Processing)技术目前还有不少难点,但应该可以用来开发医学文献阅读“神器”了。希望有志进军医疗AI的企业和读者,可以尝试。
医疗影像数据的挖掘和智能学习
医疗影像数据的应用和挖掘目前在国内如火如荼地开展着—不仅有众多的AI创业公司在研发医疗影像相关的智能识别和辅助诊断类应用,还有知名互联网企业也大举涉足医疗影像的智能辅助诊断领域。这应该既得益于国家的良好政策支持,也和影像类AI算法发展相对成熟有关。
目前常见的医疗影像类AI开发,主要还是集中在医院的影像科数据的AI应用,如肺部疾病智能辅助诊断(包括常见的肺部结节智能辅助诊断)、肝脏疾病智能辅助诊断、甲状腺/乳腺等脏器的智能辅助诊断等。影像数据通常包括CT片、核磁共振片、超声片、DR片(数字平板X射线片)等。
其实医院的病理科也有大量的临床数据,更需要AI来智能辅助识别和诊断,因为同影像科医生相比,病理科医生通常需要借助显微镜来审阅样本,比较容易漏诊,而且还比较辛苦。笔者呼吁相关企业可以多关注这个领域的人工智能应用研发,因为病理科的临床数据通常是确诊的“金标准”:意味着在训练AI模型时就可以拿到确诊的临床数据,因此训练好了的AI 模型,其智能诊断的准确度应该会比较高。
超声AI
同CT/MRI扫描的高度自动化相比,超声扫描过程基本上还是手动的,容易受多方面因素的影响,比如超声医生的经验等。所以对超声来说,人工智能技术的应用应该包括超声扫描过程的智能化质量控制和超声影像智能辅助诊断。
医学无人实验室
在医学检验环节,也有很好的医疗大数据挖掘的机会,比如通过挖掘和人工智能学习历史以往的检验数据,AI模型可以判读检验结果,并(把判读结果)推送到相关负责人做最后的审核。如果配合机械臂等自动化设备,完全可以实现智能化医学无人实验室。
三、医疗大数据行业对人工智能技术提出更高的要求
目前的人工智能技术还是处于弱人工智能时代—数据驱动,“暴力”迭代。也有人说现在的人工智能就是“数学模型”+“计算机的傻劲”,有点像“结硬寨,打呆战”。
笔者深以为然。“结硬寨”可以认为是一种模式(模型),“打呆战”就好比是无尽的迭代(计算机的傻劲)。现在很多场合可以采用这种弱人工智能技术,在医学领域也有不少的适合场景,比如肺部结节智能识别和辅助诊断。
但是,医学领域其实非常需要强人工智能技术:可解释的人工智能技术,可以智能推理的人工智能技术。因为数学上有解,不代表医学上可行。医生(和患者)对AI提供的治疗方案需要合理和权威的解释。弱人工智能在这方面没有办法做到。而且,由于人类(器官)的多样性,在AI模型训练时,没有办法输入相关疾病/器官的所有场景临床数据。
所以,基于现阶段的人工智能技术(弱人工智能技术),基本上是“看到了(类似的影像/数据)才会”,没有“举一反三”的能力。这对临床决策影響比较大。
和NLP(Nature Language Processing, 自然语言处理)领域一样,无监督学习和弱监督学习对医疗大数据行业来说也很重要,因为医疗行业的数据是极其庞大的,尤其是生物医学领域的数据,如人体基因层面的数据,每个个人的数据量都可以达到GB(Giga Byte)级别。
举一个例子,一个人的全基因组测序数据大小为30亿(碱基对)×2(双链)×30(30层的测序深度)=180GB。一般的公司经营几年下来就积累了PB(Petabyte, 千万亿字节)级的数据。医疗影像数据、电子病历数据和医学文献数据也是很大的。如果这些数据都需要专家精确标注的话,那是一个巨大的工程。
对于研发智能推理技术,笔者的建议是:构建医学常识库(包括医学图谱)。
寻找有多个领域经验的技术专家牵头。这些领域最好包括医学影像(CT/MRI/DR/超声影像等)技术专家,也最好熟悉医院信息化系统(HIS/RIS/PACS系统)、精准医疗、临床医学、人工智能、大数据挖掘。
为什么需要跨领域经验的专家牵头呢? 因为智能推理涉及多个学科知识,需要一个多方面都很有经验的“老兵”掌舵,这样可事半功倍。
比如说肺部结节智能识别和辅助诊断,现阶段大部分的解决方案都是基于图理解技术来学习/训练:基本上是“看图说话”,仅限于图中信息做出决策。但医疗影像的内容是有内在的医学逻辑的。所以,如果构建了“人体肺部医学模型”,再加上以上技术,相信AI诊断正确率会提高很多。
四、几点倡议
目前无论是政府,还是投资机构,抑或是广大高校、学生、学者、知名公司、技术人员等都满怀激情地投入到人工智能行业和(医疗)大数据挖掘行业中,使得它们高速蓬勃发展。但我们也应该看到人工智能的成熟算法绝大部分都是由国外知名大学/公司发明并开源的。国内的相关论文和产品大都是在国外的算法/模型基础上做些改动和优化,基本上没有突破性的算法被提出。
这是很显著的区别。希望读者和国内知名互联网公司在这些方面多投入,多鼓励并创建一些原创性的AI算法和框架。
另外国内的开源/分享氛围不强,导致国内的AI工作者基本上都是从学习国外知名大学、公司的开源算法和代码成长起来的。
其实开源自己公司的(部分)项目,可以在行业内获得很高的声誉,也培养一大批拥趸,相当于是做了免费的广告,其收益应该远远大于不分享带来的暂时优势的好处。看看国外的知名公司,他们由于开源自己的一部分项目而获得很多良好反馈,进而推高他们的股价,宣传了他们的产品,统领了未来技术标准等。
希望国内的知名公司在有能力的情况下多为行业做贡献,同时也是给自己的企业在行业内树立标杆。当然,最近有些知名的互联网公司也意识到这一点,开始慢慢开源一些项目。这是好的开端!
