非线性回归模型参数估计的轮回选择算法
2019-11-28陈庭木方兆伟王宝祥刘艳邢运高徐波徐大勇
陈庭木 方兆伟 王宝祥 刘艳 邢运高 徐波 徐大勇

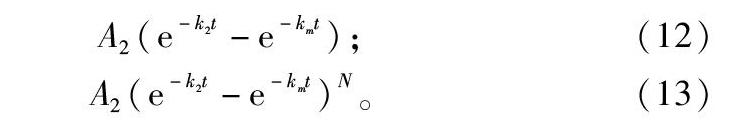
摘要:生物学领域规律更多呈现不可线性化的纯非线性方程关系,对此类方程的参数准确估计能促进生物学领域的应用数学研究。但纯非线性方程最优拟合一直是应用数学没有完全解决的课题;受水稻轮回选择育种启发,以育种进化方法构建新的进化算法,求解复杂非线性方程的拟合问题。结果表明,通过Richard方程、房室模型中的二室模型试算,前者与NIST结果相同,后者明显优于原文结果;通过奶牛泌乳曲线中的Dijkstra、Wood方程各14组数据最优拟合计算,表明本算法准确有效,且计算结果优于统计软件SAS。本算法为生物学研究中更复杂的非线性方程拟合及其应用提供了可能,为生物数学的深入发展提供了有力计算工具。
关键词:最优拟合;轮回选择;非线性回归
中图分类号: S11+5文献标志码: A
文章编号:1002-1302(2019)18-0253-07
收稿日期:2018-05-04
基金项目:现代农业技术体系建设专项(编号:CARS-01-61);江苏省科技计划重点项目(编号:SBE2017310472)。
作者简介:陈庭木(1977—),男,安徽芜湖人,副研究员,主要从事水稻品质遗传育种与生物统计研究。E-mail:chentingmu@139.com。
通信作者:徐大勇,博士,研究员,主要从事水稻遗传育种研究。E-mail:xudayong3030@sina.com。
一般线性回归关系有成熟算法,能应用最小二乘法准确无偏估计回归参数及其标准差,在农业科学研究领域,变量间更多呈现非线性关系,非线性关系只有经线性代换化为线性方程后才能应用成熟的线性算法,且参数估计只是在线性化条件下最优,以原非线性方程考量不是最优[1-2]。对于不能化为线性方程的非线性方程,称为纯非线性方程。纯非线性方程在生物学研究中更为普遍,如生物生长衰老方程、病害发展动态模型[3-7]、混合正态分布方程、复杂房室模型[8-11]、植物光合光响应方程[12-14]、奶牛泌乳曲线机理方程[15]、土壤水分模型[16-18]、农药残留降解模型[19-21]等。对于纯非线性方程最优拟合难度极大,传统方法有最速下降法、牛顿法、共轭梯度法,近代的有麦夸法、模拟退火法、遗传算法、缩张算法、人工神经网络、蚁群算法等。传统最优拟合方法存在对初值依赖性强、易陷于局优陷阱[1-2]的缺点,麦夸法对简单非线性模型初值要求较低[22],但对于复杂非线性方程(如Richard方程)极难拟合,对于房室模型中一室模型相对容易,对二室模型则会得出不恰当的解[23]。其他算法多是模拟生物自然演化过程的进化类算法。进化算法属于计算智能,现有进化算法以遺传算法为代表,但遗传算法存在早熟收敛的问题,至今未能很好克服[24]。缩张算法是一种优秀的最优拟合算法,不依赖导数支持,在已报道实例中均能达到全局最优,但对于参数过多,如参数20个以上,则按最少试算点计算,每次试算量达320个试算点,计算难以实现。故应当进一步研究开发新的算法,以克服遗传算法与缩张算法的固有缺陷。
1 材料与方法
1.1 数据来源
1.1.1 Richard方程拟合
美国国家标准网站(NIST)提供了Richard方程的最优拟合计算案例,残差平方和(http://www.itl.nist.gov/div898/strd/nls/data/ratkowsky3.shtml)由15对数据组成,最小离回归平方和Qe=8 786.404 908 0。
yi=A(1+Be-kti)1/N。(1)
式中:yi为第i个观察值;A为生长极限值;B为初始生长量参数;k为生长速度参数;ti为第i个时刻;N为曲线形状参数。
Qe=∑n-1i=0(yi-yei)2。(2)
式中:Qe为残差平方和;yi为第i个观察值;yei为第i个预测值。
1.1.2 二室模型
二室模型共5个参数,且满足Km>K2>K4。摘自袁志发《多元统计分析》中二室模型拟合实例演算[22],文献[25-26]以麦夸法求解,初值以退层法求得。
二室模型:A2(e-k2t-e-kmt)+A4(e-k4t-e-kmt)。(3)
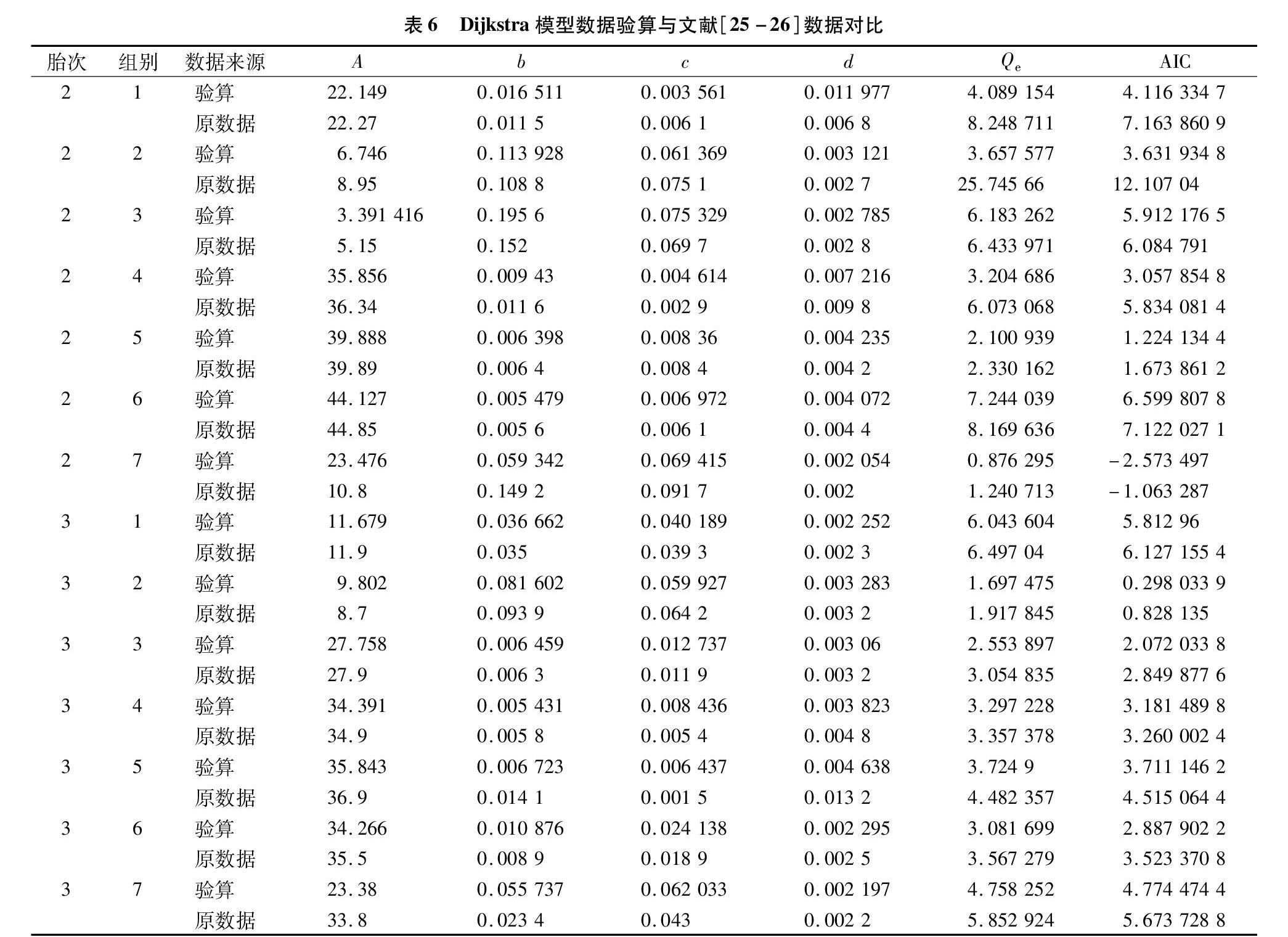
1.1.3 奶牛泌乳方程Dijkstra与Wood方程[25-26]
分别用下面2个公式表示。
y=Aeb(1-e-ct)/c-dt;(4)
y=Atbe-ct。(5)
式中:各字母含义见文献[25-26]。
以2种数学模型分别对罗清尧、能本海等《中国荷斯坦奶牛第二泌乳期泌乳曲线模型的研究》《中国荷斯坦奶牛第三泌乳期泌乳曲线模型的研究》文中第2、第3胎的各7组数据重算。
1.2 轮回选择算法
轮回选择是经典的育种方法,工作重点是选种、鉴定与自由互交。轮回选择在有限的遗传背景中,能最大程度地淘汰不良基因,聚合优良基因,以产生更高产量、抗性与品质的新种质。在轮回选择时,每轮选择大量选种材料,鉴定出10%的优良选种材料,作为自由互交亲本,亲本间自由杂交产生下轮选种材料。如此周而复始,不断提高亲本遗传表现水平,多代选择后必会获得一群高水平的个体。
笔者受轮回选择育种程序启发,将残差平方和作为目标函数值,看作遗传表现值,约束条件不满足看作致死基因(只选择存活个体),各自变量看作染色体,染色体以实数编码,先按各参数给定区间随机生成染色体组,构成若干亲本,亲本间进行自由杂交、自由突变产生一定量存活选种群体,对存活选种群体依目标函数值排序,选择若干优良选种材料作下轮亲本,亲本间再自由杂交、自由突变产生下代选种群体,如此周而复始,直到亲本间没有遗传变异与或目标函数值收敛到迭代精度要求为止。经历多个连续世代进化,收敛达到精度要求,称为1轮轮回选择进化,此进化算法称为轮回选择算法。
当对参数取值区间完全不知情,可以设定1个很宽的区间,首轮(第1轮)进化结束,以最优个体自变量(染色体)取值为中心,以其绝对值为邻域半径,进行第2轮轮回选择进化计算,之后每轮轮回选择进化计算,均以最优个体自变量(染色体值)取值为中心,将区间缩小到0.618倍,重新生成随机亲本,并加入上轮最优个体,重新作轮回选择进化计算,一般进行10轮计算方能达到全局最优解。如上组织多轮轮回选择进化计算,放宽初始区间要求及提高计算精度的算法称为多重轮回選择算法。
1.2.1 基本轮回选择算法
轮回选择算法基于亲本自由杂交及自由突变产生选种群体,再从选种群体中优选存活个体组成新一轮亲本群体,每一个由初始亲本群体形成下轮亲本群体的进化过程称为1个进化世代。不同进化世代间,只要上代亲本选种群体存在差异且有优劣区别,进化就会发生,反之进化则会停止。每轮进化由下列算子构成:初始亲本生成算子、杂交算子、突变算子、选择算子、迭代终止算子。
不断地应用杂交算子、突变算子、选择算子、迭代终止算子进行世代更替,当世代间进化达到收敛要求,则完成了一轮轮回选择计算。计算实践表明,1轮轮回选择计算结果一般不差于遗传算法,一般表现更优。
针对本算法,以C++编程语言,以面向对象的编程方法设计RSBase类,将常用参数设计成类的属性,各算子设计成类的私有方法,参数输入与输出方法设计为公有方法,以利于使用者改写与调用。类中将Fx(目标函数定义)、Gx(约束函数定义)设定为纯虚函数,每次调用必须根据使用者特有的统计模型改写,同样,参数输出方法Para也设计成了虚函数,方便改写。另外设计了函数求极值及积分的公有方法,利于对使用者定义的复杂数学模型求函数极值点、极值及区间积分。软件著作权《连农最优生长拟合类库软件V1.0》(登记号:2147408)包含了本算法全部C++代码。算法流程详见图1。
1.2.2 多重轮回选择算法
一轮轮回选择计算多由于区间不恰当或区间过大,一般不能达到全局最优解,如要求更高计算精度,可在上轮计算结果基础上精算。每轮初始亲本生成边界值由空间收敛算子给出,算子算法描述如下:
tmp=0.618repeat
repeatrepeat+1
if(tmp<0.001)tmp0.001
xa=optX-tmp×|optX|
xb=optX+tmp×|optX|。
对每个参数独立计算取值区间,由xa、xb计算产生初始亲本群体及表征突变程度上限。收敛倍率0.618是笔者经过数百次试算由经验给出,一般取值区间(0.5,1)。repeat初始值为0,optX为参数上轮最优估计值,tmp最小值暂定为0.001,最佳值有待深入研究确定。
每轮最优亲本由上轮最优选种个体遗传,能保障轮次间收敛与持续进化,参数取值区间的缩小,能更大程度地减少早熟收敛的可能性。多重轮回选择算法流程见图2。
1.2.3 轮回选择算法属性构造与各算子设计
1.2.3.1 属性构造
本算法以C++语言设计,程序执行前,要求定义一些基本的参数,以利程序安排必要的内存空间用于计算。重要参数如下:
Nx为参数变量个数;Repeat为多重轮回选择计算轮数计数器;nP、nS为亲本与选种群体规模;iG、iS、maxG为进化世代计数、选种个体计数及最大进化代数;isint为整型变量标志指针,规定变量取实数还是整数;xa、xb参数取值区间指针,初始群体由之计算产生,突变程度也由之表征;optX、optValue最优个体染色体取值指针及其目标函数值,作为算法输出;Parent、valueP亲本群体染色体取值及对应目标函数值指针;Select、valueS选种群体染色体取值及对应目标函数值指针。
1.2.3.2 初始群体构造算子
第i个变量依据(xa,i,xb,i)区间随机生成亲本参数,如整型标志变量isinti=0将相应变量取整,每个变量的区间、整型约束独立处理。初始群体由存活个体构成。初始群体的构造,不像其他算法那样过度依赖初始值,给研究者一个宽松的条件,之后在第1轮最优结果获得后,再据其修正取值区间,区间长为最优个体相应自变量取值绝对值的2倍,以防初始区间不恰当造成的随机生成样本分布不均匀,之后每轮区间长度缩小到上轮0.618倍,当区间长达到原区间长的0.001倍时不再缩小。每轮区间收敛能保证最优解区间的收敛,减少进化难度,区间愈小,进化愈快。
1.2.3.3 杂交算子
每条染色体独立杂交,每次杂交随机选择2个不同的亲本,以[0,1]间随机数α为因子一次杂交形成2个选种个体。有整型约束的变量变换为整型。杂交如同轮回选择中的自由互交,个体都由自由交配形成,保障了遗传多样性。杂交采用实数形式表示,由式(6)、式(7)计算:
x1=αPi+(1-α)Pj;(6)
x2=(1-α)Pi+αPj。(7)
1.2.3.4 诱变算子 因为诱变产生变异及杂交产生变异是本算法的2种变异方式,诱变概率过低会导致杂交变异产生的变异个体显著多于诱变产生的变异个体,为相对均衡起见,不能将诱变概率定太低。αi∈[0,1]间随机数,用于计算第i个变量突变程度,βi∈[0,1]间随机数,表示第i个自变量是否突变,表征诱变发生的概率。当βi<0.1时进行突变处理,否则不作突变处理,整体突变概率很高。计算实践表明,突变在进化过程中起重要作用。如果αi<0.5,采用式(8)。
x=P-αi[(xi)max-xai]。(8)
式中:(xi)max为当前世代亲本群体第i个自变量的最大值。如果αi≥0.5,采用式(9)。
x=P+αi[xbi-(xi)max]。(9)
式中:a、b表示属性值的左、右边界值。
1.2.3.5 选择算子
选择分为2个部分。一部分选择是致死选择,即约束函数Gx=0,为致死个体,不能参与进化计算;另一部分选择对存活个体选优汰劣,由选种群体的排序功能完成,优选nP个个体加入下轮亲本群体。选择算子优选出的解总是可行解,这与运筹学中的外点法不同,同时又避免了内点法初始可行点难以选择的矛盾。迭代过程中不会因为函数性态差而产生大幅度偏差。
1.2.3.6 空间收敛算子
当解空间过大时,会造成进化计算获取的采样点不一定能覆盖最优解空间,容易造成早熟收敛,如对不包含解空间的空间进行割舍,能集中计算能力寻找最优解。具体方法见“1.1.2”节。
1.2.3.7 迭代终止算子
迭代终止算子是判断计算能否终止的方法,当进化代数达到上限时,终止计算;或亲本没有遗传变异时,终止计算;或亲本群体目标函数值变异标准差小于指定精度值,提前结束本轮计算。当群体变异存在,但目标函数值已经基本没有变化时,应提前终止;如有整数约束时,常存在多个最优解。
1.3 经典算法介绍
高斯-牛顿法应用各一阶导数构造一个正交矩阵,建立一个最优搜索方向,当目标函数全局性态单一、有类似正定二次型的曲面形態且初始搜索点处对应正交矩阵可逆,则计算过程很快,速度优于所有现代算法。
麦夸法是在高斯-牛顿法基础上发展起来的一种近代算法。当初始搜索点处对应正交矩阵不可逆,通过将正交矩阵主对角线元素加上一足够小正数,可以改变矩阵性态,可以适当放宽高斯-牛顿法的初始值条件,计算量相对其成倍提高。
牛顿法以初始点处黑塞矩阵计算优化点,当黑塞矩阵可逆时,迭代计算非常快,如目标函数为正定二次型可一次迭代成功,当黑塞矩阵不可逆时,类似于麦夸法,将黑塞矩阵主对角线元素加上一足够小正数,此法称为修正牛顿法。牛顿法与修正牛顿法要计算各种二阶导数,计算复杂,不利于编程计算。二者与前述两法相比,存在同样的问题,当目标函数性态很差时,存在相当多的局部最优,则计算很难达到全局最优,有的甚至没有可行解。
缩张算法是由扬州大学顾世梁等提出的最优化算法,通过扩张步与收缩步组成一轮循环,初始值由随机数生成,经过多轮的缩张循环,可以较快地计算得到全局最优解,在低维问题处理上本算法目前是最优方法,但面对高维问题时,其试算点数过多,计算时间相当长,计算难以实现。
1.4 各算法间比较指标
1.4.1 误差方差
各算法比较最关键指标为残差平方和,好的算法获得估计参数更加适合所研究模型,应变量变异平方和中误差平方和占比最小化。均方误差(mean squared error,MSE)是衡量“平均误差”的一种较方便的方法,表征实际值与预测值的差异程度,可由残差平方和计算得到。均方根误差(root mean squared error,RMSE)是均方误差的算术平方根,也称作标准误差(standard error)。
1.4.2 AIC指标
AIC是赤池弘次提出的衡量统计模型拟合优良性的一种标准,可以权衡所估计模型的复杂度和此模型拟合数据的优良性。
AIC=2k+nln(Qe/n)。(10)
式中:k是参数的数量;n为观察数;Qe为残差平方和。
1.4.3 计算时间
计算时间是衡量算法效率的重要指标,但算法有效性往往比算法效率更重要,如牛顿法是非线性最优化问题的最快算法,但计算往往不能得到正确结果,现代遗传算法计算时间远多于牛顿法,但获得了广泛的应用。缩张算法计算时间也远多于牛顿法,但它是处理低维非线性问题的最佳算法。可见,计算时间在算法间比较意义相对较小,更重要的是比较计算可行性、准确性与鲁棒性。
1.4.4 对初值的依赖性 好的算法不仅要有精确的计算结果,还不能依赖初值的精确性,如牛顿法对初值要求较高,只有好的初值才会收敛到精确结果,麦夸法相对于牛顿法则对初值依赖性有所下降,但不当的初值还会造成不收敛[22-23]。缩张算法对初值基本没有要求,本研究算法对初值也没有要求,对初值没有依赖的算法称为没有初值依赖性。
2 结果与分析
2.1 Richard方程最优拟合结果
应用轮回选择算法经历11轮计算,第0轮经历10代进化,第1轮经历17代进化,…,第10轮经历7代进化(表1),残差平方和Qe达到本算法最优值8 786.404 913 187 29,与NIST网站公布的全球最优结果8 786.404 908 0前8位有效数字完全相同,AIC分别为49.515 799 32、49.515 799 31。经多次计算均达到相近计算结果(前9位有效数字一直相同),本次计算第6轮已达到计算精度要求,之后RMSE变化很小,且参数估计值变化也相当小,有的轮次间不能产生进化。本次尝试随机生成初值再作麦夸法求解,当随机点数达5 000个时,其最优结果仍不及本算法。本算法属性值构造:亲本群体规模100,每代杂交规模10 000,诱变规模10 000,迭代收敛精度要求1.0×10-10。A初始区间[0,1 000],B初始区间[0,1 000],K初始区间[0,10],N初始区间[0,10]。建议10轮为佳,如提前进入全局最优值,之后轮次的进化世代数很少,进化很快。平均每个数据集单个模型计算用时不超过120 s。
拟合残差总体为可接受水平,拟合决定系数0.991 8,相关系数0.995 9。残差分析见表2。
2.2 房室模型中二室模型拟合
二室模型共5个参数,且满足要求Km>K2>K4。对于有约束的拟合,传统非线性拟合难度极大。给定初值不当,不能产生符合约束的解,而初值选择难度又很大。轮回选择算法可将约束作为致死因子,在存活个体中优选亲本杂交、突变,产生新的选种群体,遴选最优个体,求解最优拟合参数。以式(3)模型与数据试算(表3)。本算法属性值构造:亲本群体规模100,每代杂交规模10 000,诱变规模10 000,迭代收敛精度要求1.0×10-10。初始区间A2∈[0,5 000]、K2∈[0,10]、Km∈[0,50]、A4∈[0,50]、K4∈[0,50],经11轮计算,得 Qe=6 731.829 722 431 19(AIC=47.548 071 21),明显低于文献[22]中的最优结果6 761.911 38(AIC=47.575 180 15),且完全符合约束条件。
以上拟合数据说明,K4=0,不适合二室模型拟合,更适合一室模型拟合,但原文中K4明显不为0,不能说明一室模型不合适;A4与原文差异较大,其他3个参数差异较小。本算法计算更准确。同Richard模型计算相似,第6轮基本不再有大的进化。最优拟合残差见表4,决定系数0.996 4,相关系数0.998 2。
2.3 最优数学模型选择
奶牛泌乳方程,国内外已报道有100多种,以“1.1.3”节模型与数据计算。
第2胎泌乳数据拟合残差平方和(表5)作模型、組别两因素无重复方差分析,表明模型间差异显著(F值9.083 321 499,无差别显著概率0.023 583 05),Dijkstra显著优于Wood模型。第3胎泌乳数据拟合残差平方和(表5)作模型、组别两因素无重复方差分析,也表明模型间差异显著(F值11.093 4,无差别显著概率0.015 793),Dijkstra也显著优于Wood模型。这与文献[25-26]结论完全相反,对比表7数据发现,Wood模型参数文献[25-26]SAS计算结果与本研究轮回选择计算结果相似,但本算法所有残差平方和均小于SAS结果,方差分析表明,2种方法间差异F值4.282 694 075,无差别概率0.058 986 506,接近显著水平,2种算法残差平方和差异越大,则参数估计值差异越大,表明轮回选择算法在处理简单非线性模型方面优于SAS。表6显示,Dijkstra模型数据差异较大,少数组别相近,多数组别差异大,且拟合残差14组数据均小于SAS结果,表明轮回选择算法在处理复杂非线性模型方面也优于SAS软件系统的非线性分析模块(一般采用高斯-牛顿法)。文献[25-26]14组试验数据分别用2种模型计算,形成28组拟合数据,拟合残差平方和Qe均表明本算法较SAS非线性拟合优秀,但AIC结果2个模型间差别不明显,可能AIC指标结合了参数个数信息,实质上泌乳数据需要更精确的预测结果,以Qe比较更为恰当。
3 讨论与结论
3.1 轮回选择算法的优点
3.1.1 鲁棒性
轮回选择算法采用亲本自由杂交、自由突变产生选种群体,从选种群体中优选个体组成新的亲本群体,不断地选优汰劣,实现全局寻优计算。本算法不采用导数计算,不要求目标函数及约束函数连续可导,另可以针对整数约束求解,不受一般最优化问题的实数连续约束的制约。当模型添加了区间限制(如非负),不等式约束限制(如房室模型中的二室、三室模型)等时,有特别大的灵活性。
3.1.2 适合解混合非线性模型与高难度生物学模型
如非线性模型中部分自变量存在整数约束,则称为混合非线性模型,解此类问题,传统优化算法无能为力。运筹学中采用罚函数法中的外点法求解,初始值易找,但所得常为不可行解,内点法初始点不易寻找,所得解均为可行解,但可行域不一定唯一,不能保证解为所有可行域中的最优解,实践应用不便,如采用轮回选择算法,易于实现,如将Richard方程中N要求取整数,求解中仅加整数标志即可。
由于非线性模型拟合一般采用导数支持的传统算法,当模型复杂时,会在最优解附近存在很多局部优化陷阱,拟合难度极大,如Richard方程,在美国NIST网站中将其归为高难度数组。植物生长过程不是一个单调生长过程,还包括衰老过程,仅用生长方程来拟合,不能解析衰老过程,衰老过程还干扰生长过程的参数拟合。如设计生长衰老方程,如式(11),将生长与衰老过程相叠加,则可以解析生长过程与衰老过程,还能找到二者平衡点,扬州大学孙成明在博士论文中提及此想法[27],但一直未有应用报道,主要原因是参数拟合难度远高于Richard方程,笔者研究发现,轮回选择算法可以高效准确拟合此类方程,将另文报道。
W=A11+B1e-kt-A21+e-k(t-t0);(11)
A2(e-k2t-e-kmt);(12)
A2(e-k2t-e-kmt)N。(13)
式(12)方程用于描述生物对药物的吸收清除过程,称为一室模型,在应用中一室模型拟合精度一般不高,但给方程括号项加一指数成分后变为四参数方程,形如式(13),拟合精度显著提高,也极大地提高了拟合难度,用轮回选择算法也能准确拟合,将另文报道。此类复杂的生物学方程还有很多,意义很大,难度很高,限制了在生物学科研中的应用,轮回选择算法的成功将拓展对复杂生物学模型的开发与应用,促进生物学理论研究的深入。
3.1.3 每轮重新初始化,防止了解样本分布不均匀、早熟收敛问题
遗传算法与模拟退火算法在本算法提出前早有应用,但其早熟收敛缺陷不易克服,主要是进化计算过程中对最优参数空间的不自觉舍弃[22]。轮回选择算法因采用了类似轮回选择育种中自由互交的变异方式,单轮计算出现早熟收敛的概率较低,采用多轮优化技术,每轮优化均对最优解空间作分割,区间长缩小到0.618倍,当早期轮次未计算出全局最优解时,可在以后的轮次出现全局最优解,在足够的计算轮后总能找到全局最优解。如提高计算精度(高精度计算支持)还可以突破现有最优记录。从表1和表3结果可知,随着计算轮次的增加,进化增益很小,一般没必要超过10轮,完全可以处理一般科研应用问题的求解。
3.1.4 隐并行性
如同遗传算法,本算法避开了最优方向及最优步长的搜索,也有计算的隐并行性,可实现多线程的并行计算,大幅提高计算时间效率。
3.2 算法优化
轮回选择算法计算,对不同的模型,最优算法参数不同,采用相同的参数也完全可以计算出各种类型模型的全局最优解,但计算效率有区别,针对不同的模型可以探讨最优参数配置问题,如以全局最优解解出计算时间为目标函数值进行复杂的非线性规划,可以计算最优参数配置问题,此问题有待深入研究。本算法有待改进,促进算法的完善与推广。
参考文献:
[1]顾世梁,惠大丰,莫惠栋. 非线性方程最优拟合的缩张算法[J]. 作物学报,1998,24(5):513-519.
[2]顾世梁,徐辰武,蒯建敏. 用缩张算法最优拟合非线性方程的检验[J]. 扬州大学学报(自然科学版),2001,1(3):16-19.
[3]刘维红,林茂松,李红梅,等. 人工接种测定水稻干尖线虫在水稻上的病害发展动态[J]. 中国农业科学,2007,40(12):2734-2740.
[4]刘维红. 水稻干尖线虫在“小穗头”上的危害及人工接种测定病害发展动态[D]. 南京:南京农业大学,2007.
[5]彭怀俊,顾 钢,纪成灿,等. 烤烟根系土壤中青枯病菌动态与田间病害发生发展的关系[J]. 湖南农业大学学报(自然科学版),2005,31(4):384-387.
[6]曹 静. 设施条件下马铃薯晚疫病流行主导因素及病害防治的初步研究[D]. 保定:河北农业大学,2002.
[7]柏自琴. 中国柑橘黄龙病发生动态及其病原菌亚洲种群分化研究[D]. 重庆:西南大学,2012.
[8]曾文艺,孙晓颖. 药物动力学房室模型的改进[J]. 北京师范大学学报(自然科学版),2012,48(1):6-10.
[9]王晓丽,赵 晶. 传染病房室模型的建立及求解方法[J]. 山东轻工业学院学报(自然科学版),2006,20(3):88-90.
[10]何绍雄,曹鉴萍,黄团华. 非线性房室模型参数计算法[J]. 数值计算与计算机应用,1986(3):147-152.
[11]杨博文,刘 萍. 药物动力学二房室模型[J]. 哈尔滨师范大学(自然科学学报),2016,32(1):13-15,66.
[12]韩 刚,赵 忠. 不同土壤水分下4种沙生灌木的光合光响应特性[J]. 生态学报,2010,30(15):4019-4026.
[13]闫小红,尹建华,段世华,等. 四种水稻品种的光合光响应曲线及其模型拟合[J]. 生态学杂志,2013,32(3):604-610.
[14]王荣荣,夏江宝,杨吉华,等. 贝壳砂生境干旱胁迫下杠柳叶片光合光响应模型比较[J]. 植物生态学报,2013,37(2):111-121.
[15]贾先波,陈仕毅,王 杰,等. 中国荷斯坦牛泌乳曲线数学模型拟合及应用[J]. 南京农业大学学报,2016,39(1):133-138.
[16]李洪文,高焕文. 保护性耕作土壤水分模型[J]. 中国农业大学学报,1996,1(2):25-30.
[17]于 浕. 土壤水分特征曲线Gardner模型参数的预报模型研究[D]. 太原:太原理工大学,2017.
[18]张 岩,朱 岩,张建军, 等. 林地土壤水分模型SWUF在晋西黄土高原的适用性[J]. 林业科学,2012,48(5):8-14.
[19]吴 鹏,秦智伟,周秀艳,等. 蔬菜农药残留研究进展[J]. 东北农业大学学报,2011,42(1):138-144.
[20]陈振德,陈雪辉,冯明祥,等. 毒死蜱在菠菜中的残留动态研究[J]. 农业环境科学学报,2005,24(4):728-731.
[21]张韩杰,闫艳春. 农药残留及微生物在农药降解中的应用与展望[J]. 湖北植保,2004(1):31-35.
[22]袁志发,周静芋. 多元统计分析[M]. 北京:科学出版社,2002:247-248.
[23]周静芋,宋世德,袁志发,等. 用麦夸法进行室分析曲线拟合[J]. 西北农业大学学报,1996,24(1):75-78.
[24]范青武. 遗传算法动态演化过程的研究[D]. 北京:北京工業大学,2007.
[25]罗清尧,熊本海,马 毅,等. 中国荷斯坦奶牛第二泌乳期泌乳曲线模型的研究[J]. 中国农业科学,2010,43(23):4910-4916.
[26]熊本海,马 毅,罗清尧,等. 中国荷斯坦奶牛第三泌乳期泌乳曲线模型的研究[J]. 中国农业科学,2011,44(2):402-408.
[27]孙成明. FACE水稻生长发育模拟模型研究[D]. 扬州:扬州大学,2006.
