基于特征词典构建和BIRCH算法的中文百科文本聚类研究
2019-11-28杨秀璋夏换于小民武帅赵紫如窦悦琪
杨秀璋 夏换 于小民 武帅 赵紫如 窦悦琪

摘 要: 针对传统文本聚类存在数据维度过高,无法深层次理解语义等问题,提出一种基于特征词典构建和BIRCH算法的文本聚类方法。该方法通过LDA主题模型和语义特征构建特征词典,利用BIRCH算法进行文本聚类,并对维基百科、百度百科和互动百科中的景点、动物、人物和国家四个主题的网页文档进行实验分析。实验结果表明,特征词典结合了主题关键词和语义相似度,其准确率、召回率和F特征值较传统方法有所提高,该方法可以广泛应用于文本挖掘、知识图谱和自然语言处理等领域。
关键词: 文本聚类; 特征词典; BIRCH; 特征提取; LDA
中图分类号:TP391 文献标志码:A 文章编号:1006-8228(2019)11-23-05
Abstract: Aiming at the problem that traditional text clustering has too high data dimension and deep understanding of semantics, a text clustering method based on feature dictionary construction and BIRCH algorithm is proposed. This method builds a feature dictionary through LDA topic model and semantic features, uses BIRCH algorithm to perform text clustering. an experimental analysis on Wikipedia, Baidu Encyclopedia and Interactive Encyclopedia WebPages is conducted on attractions, animals, characters and countries four topics, the results show that combined with the topic keywords and semantic similarity, the accuracy, recall and F eigenvalues of the feature dictionary are improved compared with traditional methods. This method can be widely used in text mining, knowledge mapping and natural language processing.
Key words: text clustering; feature dictionary; BIRCH; feature extraction; LDA
0 引言
在大数据研究中,文本挖掘是对文本信息进行数据挖掘的过程,文本聚类是文本挖掘的重要知识,它根据文档的相似性将文档集合进行自动归类,尽可能地使内容相似性较大的文档划分为同类。
由于文本数据复杂,通常为半结构化数据或非结构化数据,并且中文文本具有深层次语义等特点,这使得传统的聚类算法不适用于文本聚类。近年来,国内外学者对文本聚类的研究取得了一定进展,在方法和实践上都有不少的成果。但由于这些方法都是直接对高维空间向量进行聚类,没有提取具有代表性的特征词,一方面降低了运算效率,另一方面忽略了特征词的权重及相关性,从而效果不是很理想。
针对此问题,本文提出了基于特征词典构建和BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)层次聚类算法的文本聚类方法。该方法利用向量空间模型将中文分词后的文档转换为高维空间向量,再基于LDA主题模型和语义特征构建自定义特征词典,通过该特征词典提取具有代表性的特征词,然后用BIRCH层次聚类算法对新构建的特征词典向量进行文本聚类。
1 相关研究
聚類(Clustering)是将本身没有类别的数据集聚集成不同类别的组,每一组数据对象的集合都称为簇。它根据数据的不同特征,将其划分为不同的类簇,使得处于同一类别的数据成员之间的距离尽可能小,而处于不同类别的数据成员彼此分离[1]。常用聚类方法包括K-Means聚类、层次聚类、基于密度的聚类(DBSCAN)、Affinity Propagatio、模糊聚类等[2]。
文本聚类(Text Clustering)属于聚类一种,它是针对文本数据的聚类分析,根据文档内容的相似性将文档集合进行自动归类的过程,其目标是促使同类文档的内容相似性较大,而不同类文档的内容相似性较小[3-4]。常见的方法有基于层次的、基于划分的、基于密度和基于网格的文本聚类方法。
随着互联网的飞速发展,文本数据呈爆炸式增长,国内外学者对文本聚类做了大量的研究和实践。在传统文本聚类研究方面,吴夙慧等[5]将文本聚类定义为文本表示和相似度计算两个基本问题,并概述了基于向量空间模型的相似度计算、基于短语的相似度计算和基于本体的相似度计算方法;马帅等[6]提出了一种基于参考点和密度的快速聚类算法;彭京等[7]提出了一种基于语义內积空间模型的文本聚类算法;赵世奇等[8]提出了一种基于主题的文本聚类方法;Chen C L等[9]提出了挖掘模糊频繁项集的层次文档聚类算法;Jing L等[10]提出了一种基于特征权重的K-Means文本子空间聚类方法。
本体(Ontology)[11]是被用来描述某个特定领域或某些语义结构的概念以及概念之间的关系。越来越多的学者将语义网和本体引入到文本聚类中。罗娜等[12]将WordNet的概念置于文档集合中,特征提取后用TF-IDF表示文档,从而提升文本聚类效果;王晓东等[13]实现了文档语义层面上的矢量描述,通过WordNet对向量空间模型存储的特征词进行概念映射和消歧处理,完成合成聚类;林丽[14]通过知网语义距离计算相似度,根据权重淘汰特征词进行最近邻聚类算法的文本聚类;叶宇飞[15]通过知网语义改进最近邻聚类算法,实现Web中文文本聚类。如今,统计学、机器学习、深度学习等领域知识也引入到了文本挖掘中。
2 特征词典构建和BIRCH文本聚类方法
本节介绍基于特征词典构建和BIRCH算法的文本聚类方法,重点阐述了该方法的流程。
2.1 基本思路
对维基百科、百度百科和互动百科的景区、国家、动物和人物四个主题的信息进行文本聚类,其算法核心思想是引入了特征词筛选步骤,通过LDA主题模型、语义相似度和贡献程度构建专有特征向量,再进行BIRCH算法的文本聚类[16]。其框架如图1所示。方法优势是引入了特征词典,通过特征词的贡献程度和语义相似度构建特征向量;所采用的BIRCH层次聚类算法处理的数据规模更大,算法效率更高,更容易计算类簇直径和类簇间的距离,提升文本聚类效果。
2.2 文本抓取及数据预处理
通过Python、Selenium和XPath构建自定义爬虫分别抓取维基百科、百度百科和互动百科的中文网页信息,将抽取的文本保存到本地作为语料。接着对所爬取的文本内容进行预处理操作,包括中文分词、特色字符过滤、停用词清洗等。
① 分词旨在将汉语句子切分成单独的词序列。所选用的工具是基于Python语言的结巴(Jieba)分词工具。同时,由于分词中会涉及到固定词组或专有名词,如地点专有名词“沙特阿拉伯”,它可能在分词之后会变成 “沙特”和“阿拉伯”两个名词,这会严重影响实验的效果。因此在使用结巴分词过程中,通过导入自定义词典实现专有名词和固定词组的分词。
② 在文本挖掘过程中,为了避免冗余数据对实验结果造成影响并提高分析效率,会过滤掉标点符号、特殊字符和停用词(Stop Words),防止这些词对文本中所包含的有价值信息造成干扰。
2.3 特征提取及特征词典构建
(1) 特征表示
采用向量空间模型(Vector Space Model)来表示百科文本语料,它将一篇网页语料(Web Dataset)转换为一系列的特征项(Term)向量[17]。
(3) 特征词典构建
LDA(Latent Dirichlet Allocation)是由Blei等[18]在2003年提出的一种文档主题生成模型,它能将一篇文档的每个词按照一定概率分布到某个主题上,并从这个主题中选择相关的词语集。本文选用LDA模型结合语义相似度来构建特征词典,图2表示构建的百度百科重要程度排名靠前的特征词。
该方法将分别针对维基百科、百度百科、互动百科进行特征词典构建,通过LDA主题模型分别提取景区、动物、人物、国家四个主题的特征词,然后根据文档的重要程度各自获取前1000个特征词,再构成新的4000个特征词,最后利用这4000个特征词典所构建的向量矩阵进行文本聚类。
2.4 BIRCH文本聚类算法
BIRCH算法是一种常用的层次聚类算法。该算法使用聚类特征树(Clustering Feature Tree)和聚类特征(Clustering Feature)进行聚类。BIRCH聚类算法具有算法效率更高,聚类速度更快,并且适用于处理大规模数据集等优点,也更容易计算类簇的直径和类簇之间的距离。
3 实验结果分析
3.1 数据集
为了验证本文所提出的基于特征词典构建和BIRCH算法的文本聚类方法,本文实验所选取的数据集来源于三大中文百科,包括维基百科、百度百科和互动百科的景区、国家、动物、人物四个主题。实验数据集共包含1200篇网页文本,每类百科的每类主题各100篇网页语料,具体情况如表1所示。
3.2 评估指标
本实验采用数据挖掘和自然语言处理领域普遍使用的性能评估指标(准确率、召回率和F值)对所得到的网页文本数据进行评估。准确率(Precision)如公式(7)所示,召回率(Recall)如公式(8)所示,F值(F-score)如公式(9)所示。
公式中,N表示实验结果中文本聚类正确的数量,S表示实验结果中实际识别出的文本聚类数,T表示真实存在的文本类标数。F值平衡了准确率和召回率在特定环境下的制约问题,本文用它来评估整个实验的最终结果。
3.3 实验对比及结果分析
首先对维基百科、百度百科和互动百科三类数据集进行了文本聚类实验,分别对景点、动物、人物和国家四个主题进行了对比。所有实验采用的方法都是计算十次取平均值作为最终的结果,实验所采用的BIRCH算法的类簇数是4,相当于对4个不同的主题进行聚类分析。
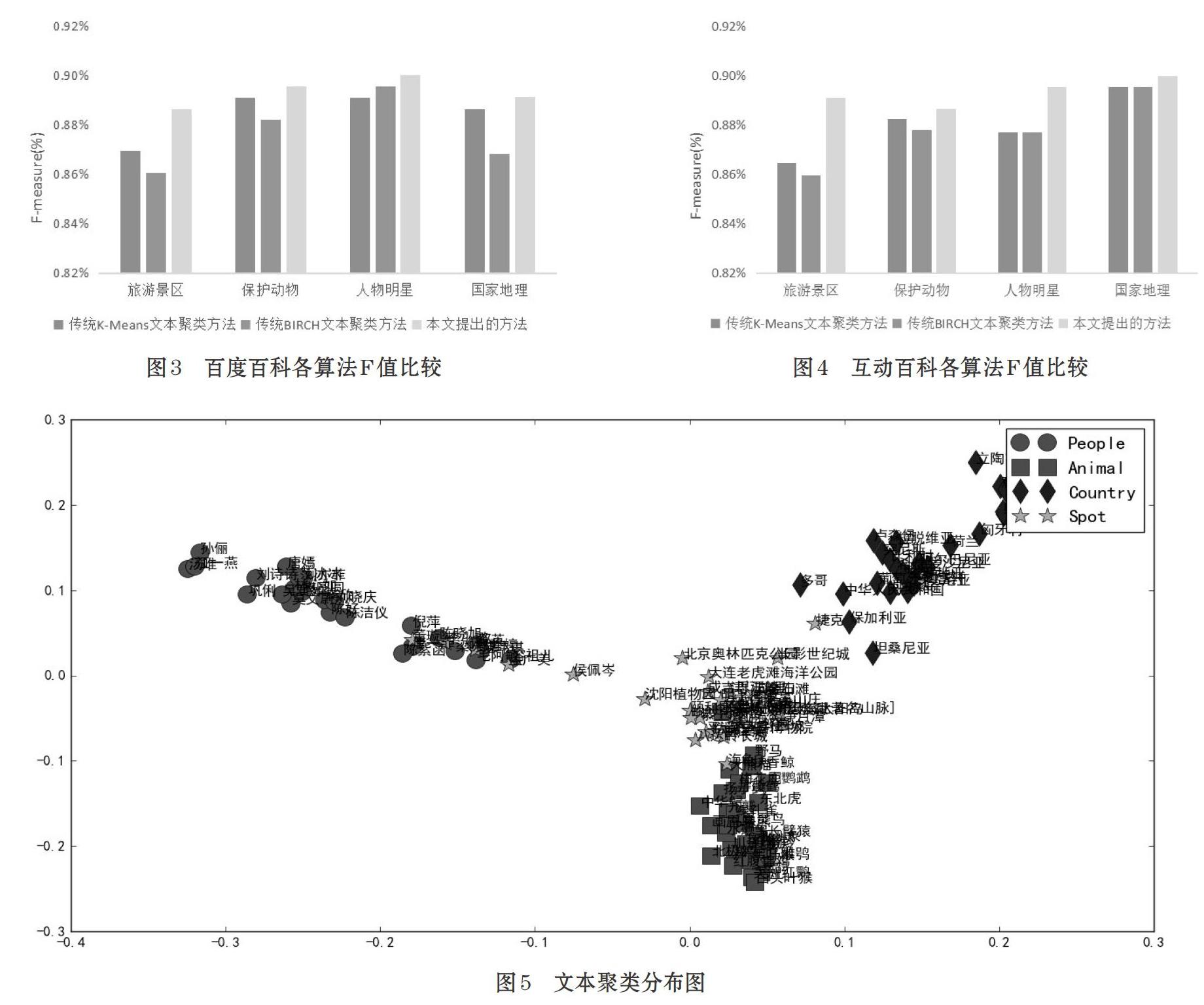
表2是维基百科基于特征词典构建和BIRCH算法的文本聚类方法的对比实验结果。从表中可以发现,本文所提出算法在準确率、召回率和F值较之以前的方法都有一定提高。其中旅游景区F值为0.8863,保护动物F值为0.8955,人物明星F值为0.9000,国家地理F值为0.8911,比对应的其他两种传统文本聚类方法都高,表明了本文提出的基于特征词典构建和BIRCH算法的文本聚类方法聚类效果更好。
图3是百度百科比较不同方法的F值的实验结果,图4是互动百科比较不同方法的F值的实验结果。图中X轴表示旅游景区、保护动物、人物明星和国家地理四个主题,Y轴对应为F值。由此可见,本文方法的F值都有所提升,其中在百度百科旅游景区主题,相对于传统的K-Means文本聚类方法和BIRCH文本聚类方法,本文方法的F值分别提升了0.0170和0.0258。
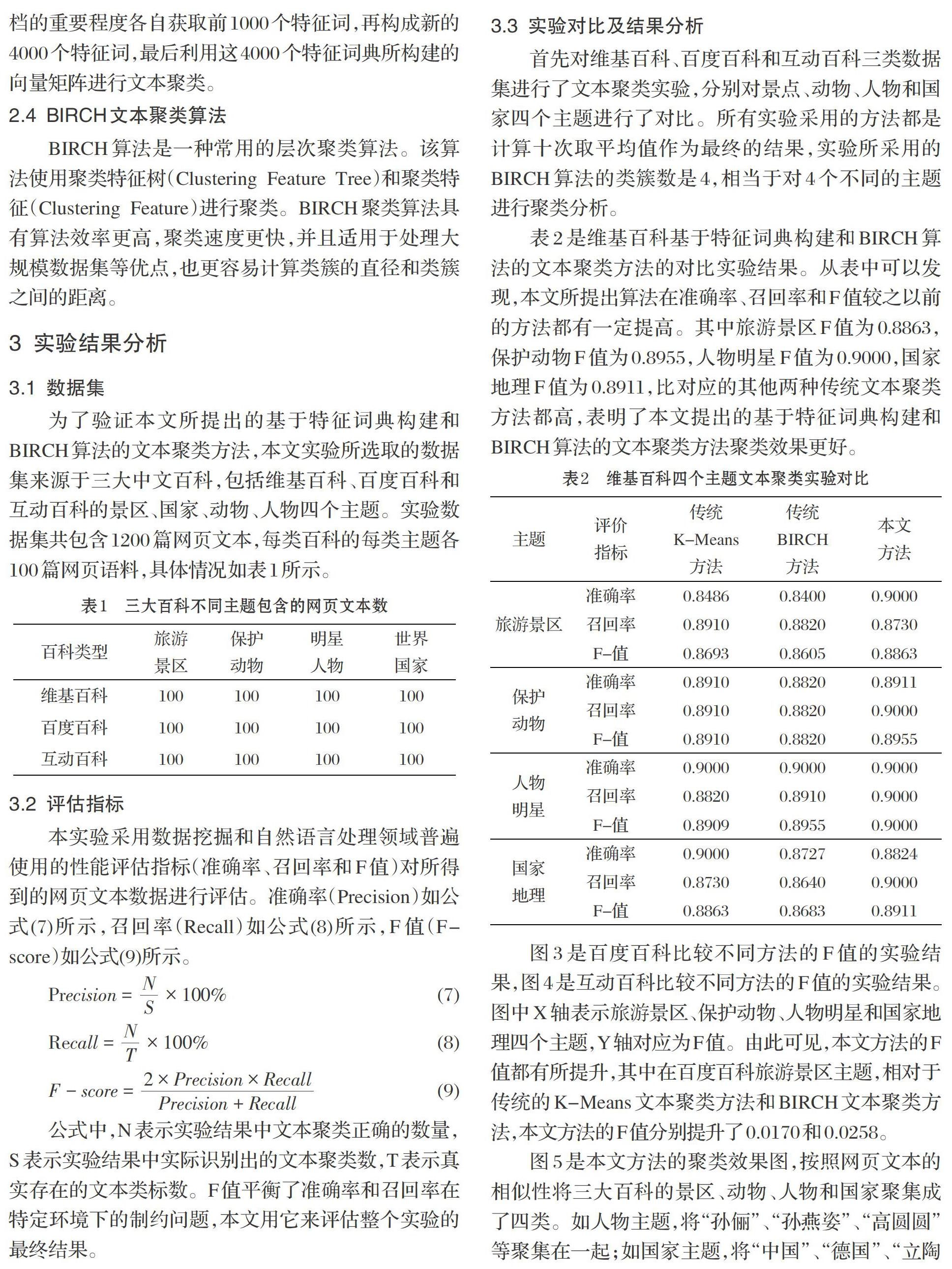
图5是本文方法的聚类效果图,按照网页文本的相似性将三大百科的景区、动物、人物和国家聚集成了四类。如人物主题,将“孙俪”、“孙燕姿”、“高圆圆”等聚集在一起;如国家主题,将“中国”、“德国”、“立陶宛”等聚集在一起;如景区主题,将“故宫”、“海洋公园”、“黄果树瀑布”等聚集在一起;如动物主题,包括“中华鲟”、“鹦鹉”、“海豚”等。
上述实验表明,基于特征词典构建和BIRCH算法的文本聚类方法优于传统的文本聚类方法,它结合了LDA主题模型和语义相似度,通过构建特征词典来提升聚类结果,BIRCH算法也加快了聚类的效率。
6 结语
针对传统文本聚类算法数据维度过高,识别特征词不精准,没有提取具有代表性的特征词,缺乏深层次语义理解等问题,本文提出了基于特征词典构建和BIRCH层次聚类算法的文本聚类方法。该方法利用LDA主题模型和语义特征构建自定义特征词典,再用BIRCH层次聚类算法对新构建的特征词典向量进行文本聚类。
本文的实验数据集为百度百科、互动百科和维基百科的旅游景区、保护动物、人物明星和国家地理四类主题的网页信息,并通过详细的实验对比了传统的K-Means和BIRCH文本聚类算法。實验结果表明,本文提出的方法的准确率、召回率和F值都有所提升,基于特征词典构建和BIRCH算法的文本聚类方法有效地提高了百科的文本聚类效果,它是优于传统文本聚类方法的。本研究成果具有重要的理论研究意义和实际应用价值,该算法可以广泛应用于文本挖掘、舆情检测、知识图谱和聚类分析等领域。
参考文献(References):
[1] 伍育红.聚类算法综述[J].计算机科学,2015.42(6A):491-524
[2] 金建国.聚类方法综述[J].计算机科学,2014.41(11A):288-293
[3] 吴启明,易云飞.文本聚类综述[J].河池学院学报,2008,28(2):86-91
[4] 曹晓.文本聚类研究综述[J].情报探索,2016.1:131-134
[5] 吴夙慧,成颖,郑彦宁,等.文本聚类中文本表示和相似度计算研究综述[J].情报科学,2012.30(4):622-627
[6] 马帅,王腾蛟,唐世渭,等.一种基于参考点和密度的快速聚类算法[J]. 软件学报,2003,14(6):1089-1095
[7] 彭京,杨冬青,唐世渭,等.一种基于语义內积空间模型的文本聚类算法[J].计算机学报,2007.30(8):1354-1363
[8] 赵世奇,刘挺,李生,等.一种基于主题的文本聚类方法[J].中文信息学报,2007.21(2):58-62.
[9] CHEN C L,TSENG F S C,LIANG T. Mining fuzzy frequent itemsets for hierarchical document clustering[J]. Information Processing and Management,2010.46(2):193-211
[10] JING L,NG M K,XU J,et al.Subspace Clustering of Text Document with Feature Weighting K-Means Algorithm[M]//Advances in Knowledge Discovery and Data Mining.Springer Berlin Heidelberg,2005:802-812
[11] SHVAIKO P,EUZENTAT J.Ten Challenges for Ontology Matching[C].Berlin:Springer,2008:1164-1182
[12] 罗娜,左万利,袁福宇,等.使用本体语义提高文本聚类[J].东南大学学报(英文版),2006.22(3):370-374
[13] 王晓东,郭雷,方俊,等.一种基于本体的抽象可调文档聚类[J].计算机工程与应用,2007.43(29):172-175
[14] 林丽.基于语义距离的文本聚类算法研究[D].厦门:厦门大学,2007.
[15] 叶宇飞.基于知网语义的Web中文文本聚类方法研究[D].重庆:重庆邮电大学,2013.
[16] 仰孝富.基于BIRCH改进算法的文本聚类研究[D].北京:北京林业大学,2013.
[17] SALTON G,WONG A,YANG C S. A Vector Space Model for Automatic Indexing[J].Communication of the ACM,1975.18(11):613-620
[18] BLEI D M, NG A Y,JORDAN M I. Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003.3:993-1022
