高可靠免训练的广播节目识别方法浅论
2019-11-26孙鹏程
孙鹏程
国家广播电视总局203台 内蒙古 呼和浩特市 010070
前 言
覆盖全球各地的中波、短波和调频广播是新闻、娱乐和信息传播的重要载体,也是舆论宣传的重要工具。国际电信联盟(ITU)规定了广播频段用途划分。 中波广播频率范围526.5~1606.5kHz,短波广播频率范围1.8~26.5MHz,中国短波广播范围2.3~26.1MHz,调频广播频率范围87~108MHz。广播频率带宽中波9kHz,短波10kHz,立体声调频256kHz。广播频率间隔中波9kHz,短波5kHz,立体声调频100kHz。在没有同频的情况下,中波120个频率,短波825个频率,调频210个频率,同时还存不同地区使用相同频率广播的电台,仅呼和浩特地区每季实际达到保证收听的中、短波、调频广播电台可以多达1000个以上。
1 广播节目识别的目的
为研究、协调频率资源的更好利用,国际上ITU 成员国对无线电广播进行监测,并通过ITU 下设的国际频率登记委员会(IFRB)和“世界无线电行政大会”(WARC)协调电波秩序。中国《无线电管理条例》也规定了无线电频率资源使用和监测的法规,对无线电台站进行检查和监测,保障无线电台站的正常使用,维护正常的无线电波秩序。广播电台收测识别是这些研究协调管理的重要数据基础。
广播收测通过监听全部广播频点,全部时间的广播,确定一周内每天每个时间各个频点都有哪些电台在广播。按照国际电联无线电规则规定各种广播应该在整点前后5 分钟内播报识别信号,如果为避免节目中断而没有整点播报,则应该在开播、停播时播发识别信号。对于四千多个可能的频率点进行7 天×24 小时的监测,这意味着有六十多万条10 分钟的记录。这些记录全部听一遍要4600 多人天的工作量。所以自动广播节目识别的方法将大大节约人力,及时为广播监测监管、新闻舆论宣传、无线电台管理部门提供重要的基础信息。
2 传统匹配方法的困难
由于各个电台在固定时刻,大多是整点,会用典型的间奏曲和语音播报电台呼号和节目,自然人们希望通过不常变化的间奏曲和电台播报音频和广播节目音频匹配,从而自动识别广播节目。但是电波经过远距离传播后,产生较大信道效应,从而使得不同时间,不同频率广播的相同节目在音频波形上很大不同。
用同一台接收机在同一天不同时间段,录制不同频率的“中国之声”整点间奏曲开始0.5 秒的波形和时频图谱,如图1 所示。可以看到上面的音频波形相当不同,但是下面的时间-频率二维图谱非常接近。所以传统上,可以通过比对不同音频的时频图谱来做音频识别。大多数情况这种时频图谱是通过短时傅里叶变换,将时域波形分割成前后部分重叠的短片段,再对各个短片段做傅里叶功率谱,就得到了信号在时间—频率二维的分布图谱。通常将这种二维分布用伪彩色图片显示。伪彩色图谱里用不同颜色代表递减的功率分布。图中可以明显看到各个频率分量随时间的变化和节奏。
在图谱比对方法中,二维相关是一种传统方法。但是由于接收机频响不同,发射台设备和配置不同,接收到的音频在时频图谱上回带有响应频率分布畸变,而这些畸变会显著干扰相关计算的判决。

图1 不同时间和频率接收相同节目的音频波形和时频图谱
3 基于时频特征哈希编码的识别方法
基于时间频率二维分布图谱中包含大量音频特征的显示,本文作者设计了一种提取音频特征而较好忽略无线电信道传输畸变和接收机频谱响应的方法。简单来说,在时频图谱中寻找特征点,具体来说可以是时间、频率局部区域的功率峰值。时频图谱中可以看出条状的音频信息和零散分布的噪声。由于噪声在频域被图谱分隔,不会影响有用音频特征点的提取。
特征点提取后设计者提取特征信息并编码。由于音频主要信息在于频率和时间,而不在于功率,所以仅仅提取特征点的频率、时间,这样正好避免了传输信道衰落变化和接收机频响带来的功率波动。设计者对特征点采用了相对时频位置的编码,这样进一步去除了相对时间差异和整体频率偏差带来的干扰。这种特征编码是一种长序列哈希编码,事先采集足够的节目开始曲短音频,对每个模板生成哈希编码,对于任何一个待识别录音同样进行哈希编码,然后将待识别编码和所有模板编码匹配,得出各个模板的匹配分值,再通过最佳匹配得出识别结果。
如果最佳匹配分值高于置信门限,就软件输出识别结果。由于时频分析基本上是一种线性变换,如果电台串音,会表现为同时保留2 个节目的特征,所以软件可以在识别成功时,再对第二匹配判断,如果第二匹配分值合理,也会提出串音告知。
4 实践检测
设计者从实际监测录音文件中提取了中国国际广播电台蒙古语、汉语及多种外语的播报音短音频,制作了哈希码模板,然后试验用短波接收机录制了一些整点播报的音频。设计者编写了软件,对这些音频进行编码匹配。通过一段约2 分钟的波斯语播报录音及其和对应模板匹配的结果,如图2 所示。图中上部是待识别录音的时域曲线,中部是该录音的时频图谱,下部是该录音哈希码和波斯语播报模板哈希码的移动匹配分数过程。可以看出当模板时间移动到待识别哈希码对应时段时,出现匹配峰值。
在2019年春季换频之前,设计者录制了某天多个时间段多个频率的中国国际广播电台的整点播报录音。选取可听度较好的录音样本,时间为整点前30 秒到整点后90 秒。从互联网资源和人工收测中挑取多个语种播报,生成模板序列,对这些录音匹配识别。样本总数85 个,扣除没有合适模板匹配不上40 个,没有模板误报语种6 个,实际有效样本39 个,其中准确识别35 个约占90%,错误识别4 个,约占10%。而这4 个错误识别全是播报语种不在模板语种集合,预计各个语种播报模板完善后这种错报可以消除。所以试验结果证明基于哈希编码匹配方法可以准确的识别广播节目。如表1 所示。

图2 中国国际广播电台波斯语整点播报匹配
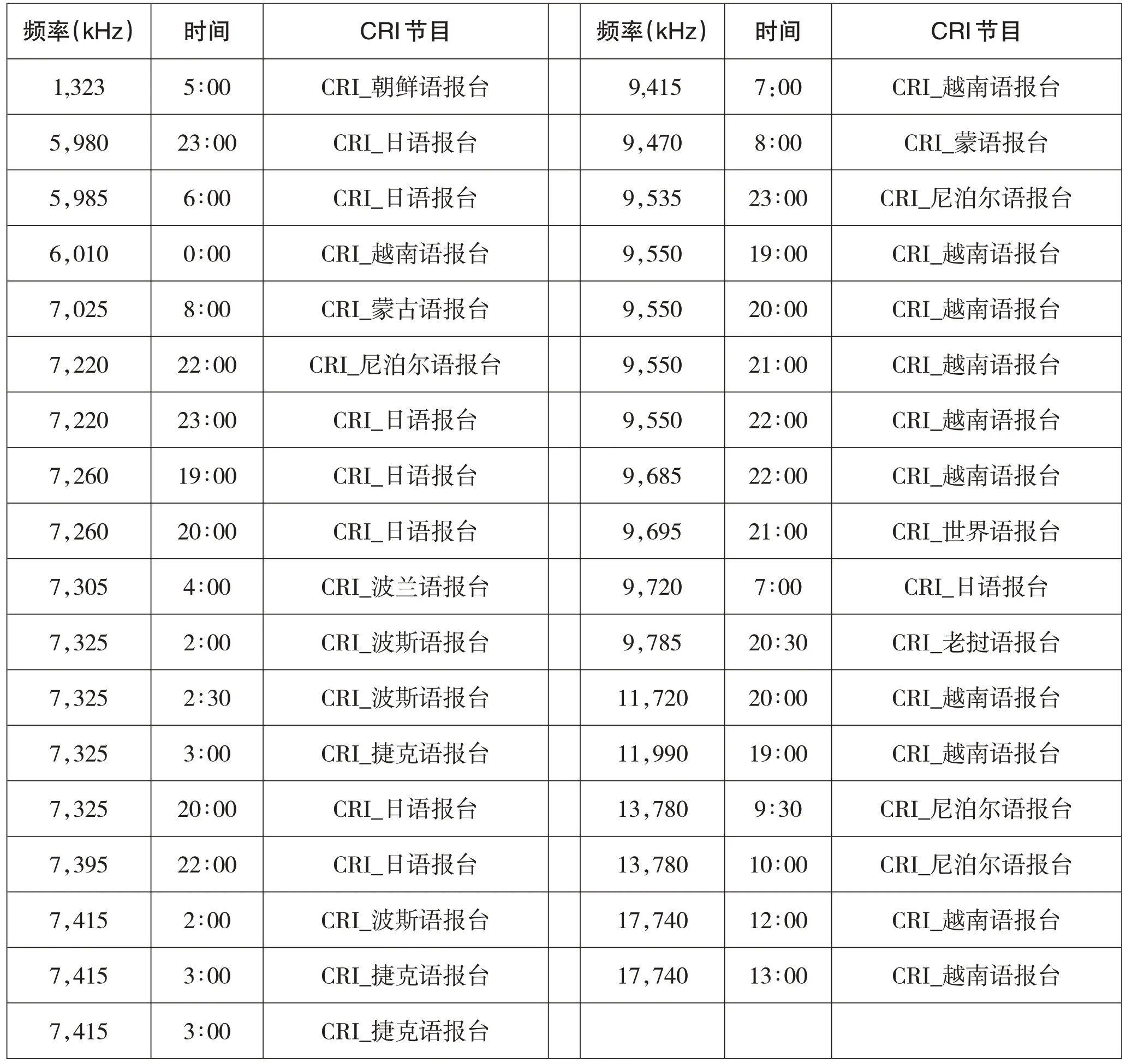
表1 样本录音识别结果表
结 论
本文提出的基于哈希编码匹配方法来识别广播节目的方法较好地克服了广播信道畸变、不同接收机频率响应的影响有四点成果。第一,达到了不需要训练,不挑接收机的效果。第二,这种基于时频特征编码的方法具有较好的抗噪声能力,对待识别的音频质量要求非常宽松。第三,这种方法适用于任何语言,并且同时提取语音和音乐特征,适用性较好。第四,基于时频图谱编码的识别算法是一种顺序处理算法,处理速度较快。
