基于窗口样本相似因子分析的油井工况识别方法*
2019-11-22段泽文张文喜
王 通,段泽文,张文喜
(1.沈阳工业大学 电气工程学院,沈阳 110870;2.盘锦辽河油田辽南集团有限公司 辽南公司,辽宁 盘锦 124114)
随着油田生产信息化的快速发展,根据不同工况信息,进行油井生产故障诊断分析和动态调整采油方式,对于油井设备的安全运行和提高采油效率都有重要的现实意义[1-2].因此,油井工况的智能识别成为数字化油田建设的一个重要环节[3].
近年来,利用生产参数进行工况识别的方法在不同的生产行业领域取得了良好的发展[4-5].文献[6]采用模糊C-均值聚类算法和变量相关性分析的方法对火电机组重要参数运行的历史数据进行了分析,实现不同工况的划分.文献[7]采用加权的K均值算法对水泥生产线控制参数进行聚类分析,完成工况检索,使生产系统实时处于最优的运行状态.传统工况识别算法多采用单一时刻样本的空间距离度量进行相似性聚类,但在油田生产过程中,由于存在生产波动和异常等现象,单一时刻样本并不能对当前工况特性进行准确描述,现场生产人员采用一段时间生产数据特性作为当前工况的判断依据[8].文献[9]提出一种全自动的多模态过程离线模态识别方法.对窗口数据进行均值处理,虽简化了计算,但淹没了不同窗口的数据多样性.文献[10]提出一种基于多工况识别的过程监测方法,采用窗口切割技术和窗口平均值相似度计算来完成不同工况的分析.采用传统基于样本距离的计算方法并不适用于空间样本数据相似性的度量.因此,本文提出采用基于窗口样本相似因子分析方法,以一定宽度的窗口样本数据特征来表征当前的工况特性,减小由于单一时刻样本数据在描述工况特性时的不准确性以及异常数据对同一工况数据聚类效果的影响.利用窗口样本的相似因子计算来代替传统样本的距离计算,采用改进的K-means聚类算法根据不同工况样本数据的特性对生产参数进行聚类分析,完成多工况的识别过程.
1 特征参数选取
选取的特征参数应尽可能表征不同工况下的所有生产特征,准确反映相应的生产状况,是准确进行工况识别的关键.特征参数的选取应遵循以下原则:1)区分性,在不同工况类型下这些特征参数的差异很大;2)聚类性,在同一工况类型下这些特征参数的差异较小;3)独立性,各个特征参数是独立的,彼此之间没有关联性;4)方便易测.
对于生产特征参数的选取,结合现场生产资料,通过大量数据分析后选取日产液量Q,日产气量V,油压Fo,井口温度T,泵效η和电流I等6个生产工作参数作为特征参数,全面涵盖了油田生产中油井的抽油能力和油层供液能力的相关参数信息,具体描述如表1所示.
为减小传感器采样数据的误差影响,对油田生产参数的采样数据作相应的均值处理,以一个采样周期内所有采样数据点的均值作为该时刻的样本数据值,降低异常数据的干扰.

表1 选取的生产特征参数Tab.1 Selected production characteristic parameters
2 基于窗口样本相似因子分析的改进K-means聚类算法
油田生产是一个多工况运行的复杂生产过程,包括多个稳态工况以及不同稳态工况之间的过渡过程.通常在生产运行稳定时,各生产参数的数据变化不大,数据特性基本一致.当采油方式发生改变或出现生产波动时,传统工况聚类方法不能有效表征不同工况特性,应对异常数据对工况聚类的影响,最终导致聚类效果不理想,造成部分工况发生误判的情况.因此,本文首先对历史生产数据进行窗口切割,以窗口样本数据的整体特征来表征当前生产工况特性,减少波动数据和异常数据对工况特性的影响;然后采用窗口样本相似因子分析来合理表征不同工况的样本数据特性;最后采用改进的K-means聚类算法对不同窗口数据进行聚类分析,完成不同工况的识别过程.
2.1 窗口切割技术
采集油田生产参数的历史数据,将其记为数据集X∈Rn×m,n为样本数据个数,m为生产参数变量个数.选取长度为H的窗口,对生产参数的历史数据X∈Rn×m沿采样时间轴方向进行等距切割,将n个样本数据分割为K个窗口数据子集,即
n=HK+d (0≤d (1) 将K个窗口数据按连续采样的时间间隔进行排序,记为Xi∈RH×m(i=1,2,…,K),Xi为第i个时刻的窗口数据子集. 对于窗口长度H的选取,要根据实际过程选取恰当的切割宽度.H越大,对噪声、异常数据的冗余能力和抗干扰能力越强,但会使得工况数据点的划分准确性下降,造成部分样本分类错误;H越小,会使各工况数据点划分更准确,但噪声和奇异点等随机扰动的影响便会增大,数据特性容易被掩盖,使得数据聚类的复杂度升高. 设两个M维的线性空间向量u和v,定义空间欧式距离d2(u,v)为 (2) 传统基于样本空间距离的相似性计算,在样本复杂度上升时,空间距离不能有效对样本进行区分.本文采用PCA相关的相似因子分析来进行数据相似性判断,设采集的样本数据X为 X=[X1,X2,…,XK]T(Xi∈RH×m) 对Xi进行PCA分解可得 (3) 式中:t1,t2,…,tk为得分向量;p1,p2,…,pk为载荷向量;E为数据的残差空间.取前p个主元进行后续相似因子运算. 设数据集Xl、Xh∈RH×m均由H个样本m个变量组成,取每个数据集矩阵的PCA模型中前p个特征向量作为主元向量. (4) PCA相似因子分析可用于衡量两个多元数据集间的相似性,通过计算两个主元模型负载向量之间的角度大小以及引入不同主元向量对应的特征值λ,来反映各主元所含方差信息量的不同,区分不同数据集之间的相似性,并在许多数据分析应用场合取得了良好的效果. 采用窗口样本相似因子分析计算替代传统的距离计算方法,能更好地衡量样本数据之间的相似关系.改进聚类算法对于聚类中心和类别的选取,能够有效防止出现局部最优的情形,提升整体的聚类效果.算法的具体步骤流程如图1所示. 算法输入为切割后的K个窗口数据子集X1,X2,…,XK,以及不同聚类中心之间的最小相似性阈值θ.算法的输出为目标类数量C,代表不同的稳态工况.从K个聚类单元中均匀抽取C0个单元作为初始聚类中心Wi(i=1,2,…,C0),保证能够选取到合适的聚类中心,一般C0的取值为K/3~ K/2.当算法在两次迭代运算后对应聚类中心相似性因子的差值小于算法收敛条件阈值ε时,即算法终止.ε的取值是根据算法在多次迭代后以不同聚类中心间相似因子的差值范围作为参考,采用交叉验证的方式来进行选取. 图1 改进的K-means算法流程图Fig.1 Flow chart of improved K-means algorithm 实验采用辽河油田某采油平台在2017年3月20日至5月20日的实际生产监测记录进行研究,验证本文方法的有效性.选取抽油机井生产记录中的油压、日产液量、日产气量、井口温度、泵效和电流等6个生产参数作为过程监测变量,根据生产数据特性的变化来反映油井生产工况的改变. 图2 基于窗口分析的工况识别流程图Fig.2 Flow chart of condition recognition based on window analysis 根据采油平台生产监测记录显示T=60 d,以生产参数变量中最小的采样频率为基准进行参数数据的采样,每天采样次数为12次,采样数据为720个.根据生产记录显示,在日期T=1~16 d内地面一直发生渗水现象,油井运行记为稳态工况A;在T=17 d时,地面渗水停止,油井进入过渡过程AB;在T=20 d时,过渡过程结束,油井恢复正常生产运行,进入到下一个稳态工况B.在T=45 d时,抽油机井发生游漏现象,进入过渡过程BC;在T=49 d时,过渡过程结束,油井进入下一个稳态工况C.在T=60 d时,油井依然运行在游漏状态下.设置两个聚类中心的最小相似性阈值为θ=0.225,算法收敛条件阈值ε=0.15.实验研究包含了油井的3个工况变化过程,具体如表2所示. 表2 生产记录过程Tab.2 Production record procedure 实验过程中生产参数随工况的变化而改变,变化曲线如图3所示,横轴代表采样点,纵轴为各生产参数数值. 图3 特征参数变化曲线Fig.3 Changing curve of characteristic parameters 采用生产参数特征进行工况识别,当H=1时,即表示不考虑生产波动和过渡过程中异常数据对整体数据的影响,采用传统K-means聚类算法进行聚类分析.聚类单元为720个,初始聚类中心C0和聚类类别通过类簇指标下降最快原则进行选取,然后根据不同的聚类结果以生产时间为横轴进行工况类别的顺序划分,最终工况的识别结果如图4所示. 图4 传统K-means算法聚类结果(H=1)Fig.4 Clustering results by traditional K-means algorithm (H=1) 由图4可知,由于在聚类分析时未考虑生产波动干扰或过渡过程的异常数据对整个工况聚类结果的影响,使得即使在同一稳态工况内数据特性相近时,仍然出现了多次工况类型波动发生工况误判的情况,得出错误的结论. 由于油田生产是一个慢时变的过程,结合生产参数采样频率,通过对选取不同切割窗口长度H进行实验对比分析,结果表明,6 h内的生产数据能够及时准确地反映实际的生产工况变化情况.当H=6时,样本数据被分割为120个窗口,计算每个窗口的均值向量,利用改进的K-means算法进行聚类分析.聚类单元为120个,初始聚类中心C0为50个,然后根据不同的聚类结果进行工况划分,最终工况的识别结果如图5所示. 图5 基于窗口分析的K-means算法聚类结果(H=6)Fig.5 Clustering results by K-means algorithm based on window analysis (H=6) 通过对比图4、5可知,在同一稳态工况中,由于生产波动异常数据带来的工况误判情况明显得到了改善,不同稳态工况之间过渡过程的工况类型波动也变得清晰了,工况复杂性也被大大降低.实验结果表明,采用窗口样本相似因子分析能够有效去除由于生产波动数据和过渡过程数据对正常生产数据聚类造成的影响,提高油田生产工况的识别精度,为油田生产后续相关措施的制定提供了有效的前提保障. 针对传统工况识别方法容易受到生产波动和过渡过程中异常数据的影响,发生部分工况误判的情况,本文提出基于窗口样本相似因子分析的改进K-means聚类算法,以窗口样本数据的整体特性来表征当前生产工况特点,减小波动数据或干扰的异常数据对工况聚类效果的影响.采用窗口样本相似因子计算代替传统的距离计算,利用改进的K-means聚类算法对不同工况数据进行聚类分析,完成多工况的识别过程.实验采用辽河油田某油井的实际生产参数进行研究,结果表明,该方法能够有效地减小异常数据对聚类效果的影响,提高了工况识别的准确性,为油田的安全生产运行提供了保障.2.2 相似性因子分析

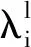
2.3 改进的K-means聚类算法

3 算法实现过程

4 实验分析





5 结 论
