普通话塞擦音声学界标研究*
2019-11-13曾晨刚
曾晨刚
中央民族大学国际教育学院 北京 100081
提要 语音量子理论认为,声学界标可反映区别特征的声学区分模式。本文以语音量子理论为理论基础,以1800个普通话塞擦音音节为分析对象,利用决策树模型,考察了VOT、GAP、谱重心、谱顶点、标准差、偏度、峰度、后接F2、振幅9项声学参数中,哪些参数可以作为表征塞擦音的声学界标。研究表明,VOT可以作为[送气嗓音]特征的声学界标,谱重心和偏度可以作为[后]特征的声学界标,后接F2和谱重心可以作为[面部]特征的声学界标。
1 引言
语音量子理论(Quantal Nature of Speech,简称QNS)认为:声学参数与发音参数存在一种非线性关系(见图1),Stevens (1989)将其称为量子关系。在I区与III区,发音参数(articulatory parameter)的变化不会引起声学参数(acoustic parameter)的剧烈变化,在II区,发音参数的细微变化会引起声学参数的剧烈变化(Stevens 1989)。从区别特征的角度来看,如果我们把I区定义为[-F]特征,把III区定义为[+F]特征,介于I区与III区之间的II区则为构成对立的关键,该区域集中体现了发音—声学关系的不连续性,对应到声学参数上便是该区存在一个声学界标(acoustic landmark),反映区别特征在不同赋值状态下声学参数的分布情况,因为II区的存在,才使得I区与III区在区别特征上的对立成为了可能(Stevens 1989,2000a,2000b,2003)。
QNS的目的是从发音参数(或声学参数)的角度研究区别特征在声学以及生理层面的物质基础。基于区别特征展开声学界标的清单研究有助于深刻认识语音产生过程中声学—生理的非线性关系,即量子关系。那么,在进行清单研究之前,以下两个问题必须明确(Stevens 1989; Stevens & Keyser 2010):1)选择何种区别特征来构建清单?2)哪些声学参数可以体现出发音与声学的非线性关系,并进而揭示区别特征的声学/生理基础?对于第一个问题,Stevens选择Chomsky & Halle(1968:113)提出的区别特征体系用来构建声学界标清单,他指出:QNS理论需要一种同时兼顾生理与声学因素的区别特征体系,而Chomsky & Halle提出的区别特征系统,则从发音部位与发音方法两个角度提出17对区别特征,这与QNS理论的初衷不谋而合(Stevens 1989)。对于第二个问题,哪些声学参数可以体现发音与声学的非线性关系,Stevens & Keyser(2010)指出区别特征由两类物理因素决定:
1)声道在共振时存在的耦合现象,此时区别特征的对立由声道函数“零点”位置差异所决定,如本文所讨论普通话塞擦音中的[面部]特征([coronal])、[后]特征([back])、[高]特征([high]),(1)Stevens在构建QNS理论时,选择Chomsky & Halle的区别特征体系,因而本文在描述塞擦音的区别特征时,均以Chomsky & Halle所提出的区别特征体系为准。皆由不同的零点位置形成对立,Halle(1992:98)认为这些特征与特定发音器官绑定,为器官绑定特征(articulator-bound),Stevens在此基础上提出声学界标的器官绑定(bounding articulator),即存在标记对立发音部位的声学界标(Stevens & Keyser 2010)。
2)不与特定器官绑定,反映语音声源特性的器官独立特征(articulator-free) (Halle 1992:98),如[粗糙]([strident])、[延续]([continuant])、[响音]([sonorant])等,Stevens将这类声学界标称为声学界标的声源绑定(bounding articulator-free),该类声学界标反映了不同声源的对立(Stevens & Keyser 2010)。Stevens & Keyser(2010)认为以上两类物理因素在语音实现的过程中,还存在“区别特征的发音增强”(enhancement of distinctive feature):区别特征与声学界标不是一一对应的关系,区别特征在实现的过程中,不仅仅依靠标准声学参数(standard parameter)反映声学、听感、生理基本格局,还有别的声学参数增强了该区别特征在声学上的显著性。
QNS理论一经提出便引起国际语音学界的广泛关注,围绕声学界标所做的声学清单研究成为国际语音学界的研究热点,如:Park & Cohen (1995)对英语中元音/i/、/u/、//、//的声学界标进行了研究;Tabain(2001)分析了四名澳大利亚成年女性擦音的频谱特征,并结合前人对擦音所得到的生理参数EPG,对擦音的声学界标进行了清单化研究;Chi & Sonderrgger(2006)讨论了英语中[-后]与[+后]的特征赋值机制,进而分析了英语中前元音与后元音的声学界标;Sonderrgger & Keshet(2012)讨论了英语中VOT对区分辅音发声态所起到的声学界标作用;Kozloff(2017)讨论了西班牙语中区分颤音(trilled)与拍音(tapped)的声学界标。与国外相比,国内目前围绕QNS理论的研究较少,仅有李智强(2013)和鲍怀翘(2015)从理论层面对QNS的介绍,围绕声学界标的清单研究尚属空白,本文参考Park & Cohen (1995)、Tabain(2001)、Veilleux & Shattuck-Hufnagel(2008)的研究范式,以普通话塞擦音为研究对象,拟对普通话塞擦音的声学界标进行探索性研究。

图1 发音参数和声学参数之间的量子关系(Stevens 1989)
2 实验设计
2.1 实验材料设计
录音在安静的录音室内进行,硬件方面使用Neumann U87Ai 话筒采集发音人的发音,软件方面我们使用Praat软件进行录音,音频文件的采样频率定为44100Hz,并以.wav格式保存。在录音前,要求发音人首先熟悉录音材料,保证能够准确、自然的发音;录音时要求发音人对着话筒,正常语速读5遍。
2.2 数据分析方法及实验流程讨论
2.2.1 数据分析方法——决策树模型简介
Mitchell(2008:10)将机器学习分为三类:监督学习(supervised learning)、非监督学习(unsupervised learning)、强化学习(reinforcement learning)。本研究使用的决策树模型是一种监督学习模型,其运行原理分为以下三步:首先,外界输入一个包含特征值与标签值数据集,人工设定数据集中训练样本与检验样本的比重,决策树会根据设置结果,把数据集中的样本随机分割为两类,训练样本与检验样本;随后,决策树会对训练样本中特征值与标签值的关系进行机器学习,根据学习结果生成一个二分的树模型以及聚类规则(见图6);最后,决策树会调用检验样本对该模型的拟合优度进行检验(检验结果体现为混淆矩阵,见表1)。
2.2.2 研究流程
参考决策树建模的一般原则(Mitchell 2008:102),本研究实验流程定义如下:
第一步,语料采集与参数提取。选取10名(5男5女)普通话等级为二级甲等的汉语母语者,录制语料,随后利用语音分析软件Praat提取出塞擦音的声学参数。
第二步,利用MATLAB软件,搭建决策树模型。将采集到的样本数据进行随机分类,分为训练样本(样本总数60%)与检验样本(样本总数40%),输入决策树模型,分别得到与塞擦音有关的混淆矩阵、树形分类图、分类规则。混淆矩阵用于检验决策树对塞擦音音位聚类的拟合优度,树型分类图计算出塞擦音实现音位分类的具体流程,分类规则计算出实现音位分类需要涉及到的声学参数以及分界值。
第三步,数据分析,首先利用混淆矩阵考察决策树是否能够真实反映塞擦音的音位聚合。在本研究中,人工设定当训练样本和检验样本的总正确率以及各项样本的判断正确率均高于95%,则说明该模型有效(Veilleux & Shattuck-Hufnagel 2008),说明决策树计算出的塞擦音树形分类图以及分类规则是可靠的,随后通过分析树形分类图,明确塞擦音实现音位分类的具体流程,最后通过分类规则,(3)关于分类规则的解释:决策树通过计算会将表征塞擦音的声学参数分为三类:主变量、与节点分类强相关的替代变量、与节点分类中等相关或弱相关的替代变量;决策树只会选择与节点分类最为密切的主变量和强相关的替代变量,作为塞擦音的分类规则,而中等相关、弱相关的替代变量不会进入分类规则;进入分类规则的参数中,主变量对各个节点分类关联度最高,强相关的替代变量对节点的关联度次之。明确不同声学参数对解释塞擦音音位分类的作用。
第四步,分析讨论。根据决策树分类规则中的变量分界原则以及变量对模型的关联程度,以主变量为标准声学参数,替代变量作为发音增强参数(Tabain 2001;Veilleux & Shattuck-Hufnagel 2008),列出塞擦音的声学界标清单,并分析该声学参数对区别特征赋值的影响,以及体现的声学—发音关系。
2.3 参数定义
参考Svantesson(1986)、Jongman et al.(2000)、Lee et al.(2014)、吴宗济(1986:210)、张家禄(1982)、冉启斌(2007)对塞擦音声学参数的定义,本次实验提取以下9项声学参数:VOT、GAP、谱重心、谱顶点、振幅、标准差、偏度、峰度、后接F2。其中VOT与GAP为时域参数,剩余7项为频域参数,以下分别介绍提取办法。
2.3.1 时域参量
VOT即嗓音起始时间, 以塞擦音的冲直条出现作为VOT的起点,元音周期波的出现作为终点,截得时长即为VOT,若冲直条在语图中缺失,则以噪声波的出现处作为起点,元音周期波的出现处作为终点来定义VOT(见下页图2);GAP即辅音闭塞段时长,以前接音节元音F2结束点为起点,以塞擦音冲直条为终点,截得时长即为GAP(见下页图3)。
2.3.2 频域参量
频域参量分为三类:一类为表征塞擦音的频谱能量,分别为:谱重心(central gravity)、谱顶点(spectral vertex)、标准差(standard deviation)、偏度(skewness)、峰度(kurtosis)为描述塞擦音的频谱能量;另外两类分别为振幅(intensity)与后接F2(F2onset)。
1)频谱能量
表征塞擦音的频谱能量的声学参数有五种:谱重心表征频谱能量的中心位置;谱顶点表征频谱能量的上限;标准差为衡量频谱分散程度的参数;偏度为衡量频谱能量集中于高频区还是低频区的声学参数,若偏度小于零,则说明频谱能量集中于高频区,若偏度大于零,则说明频谱能量集中于低频区;峰度为衡量频谱能量集中区域能量值变化的陡缓程度,其数值大小与频谱能量集中区域能量变化剧烈程度成正比。以上5项声学参数,我们利用Praat自带FFT技术,生成功率谱,并以此功率谱为基准对以上5项参数进行提取(见下页图4)。
在第二轮歌舞表演专业的考场中,别的同学都唱得特专业,美声唱法、流行唱法各种,这些歌唱技巧我都没有学过,当时整个人非常心虚,反反复复练了好几天,做梦都能念出歌词,才在最后“厚脸皮”地唱出了最拿手的《让我们荡起双桨》,而且还是紧张得跑了调。
2)振幅
选取宽带语图中塞擦音摩擦段,利用Praat自带的提取振幅的算法提取出目标段振幅的均方根值,并以此值作为塞擦音的振幅数值(见下页图4)。
3)后接F2
后接F2,即辅音后接元音第二共振峰,后接F2往往会携带辅音信息,是影响辅音感知的重要参量,其提取方法为基于宽带语图中塞擦音与后接元音的过渡段,利用Praat自带的共振峰跟踪算法,提取出改点的第二共振峰数值,即为后接F2(见下页图5)。

图2 VOT、振幅提取示例(4) 此图为一名男性发音人所发的“我在读/hi55/”,目标音节/hi55/(最后一个音节)的VOT,即为两条红线之间区域时长,为188ms;振幅即为所选区域的振幅的均方根值,为-5.88dB。

图3 GAP提取示例(5) 此图为一名男性发音人所发的“我在读/hi55/”的语图,目标音节/hi55/ (最后一个音节)的GAP,即为两条红线之间区域的时长,时长为28ms。

图4 FFT图谱(6) 此图为一名男性发音人/hi55/的FFT图谱,横轴为赫兹,纵轴为分贝,利用Praat自带的查询(query)功能,分别求出该图谱中的谱重心(5543Hz)、谱顶点(5807Hz)、标准差(2144Hz)、偏度(1.01)、峰度(3.16)。
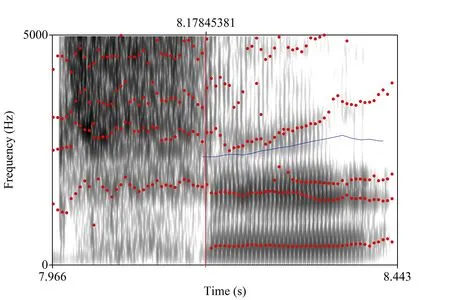
图5 后接F2提取示例(7) 此图为一名男性发音人所发/hi55/的语图,选取塞擦音与后接元音过渡段,即红线所处位置,利用Praat自带的共振峰提取算法提取后接F2,数值为2110Hz。
3 数据分析
利用MATLAB搭建决策树(使用CRT算法,多重变量检测),将9项声学参数作为因子,将每个样本所属的塞擦音音位类别(即//、/h/、//、/h/、//、/h/)作为因变量输入模型,并设定60%的样本(即1080个塞擦音样本)作为模型的训练样本,另外40%的样本(即720个塞擦音样本)作为模型的检验样本,检验该模型的可靠性。决策树经过学习,生成了混淆矩阵(见下页表1)、树形分类图(见下页图6)、分类规则(见表2、表3),以下我们分别讨论。
3.1 模型准确度的讨论
首先,我们利用决策树计算出的混淆矩阵(见表1)对模型的可靠性进行评估。
表1 塞擦音音位混淆矩阵

样本已观测已预测///h//ʦ//ʦh//ʨ//ʨh/正确百分比训练//18000000100.0%/h/01800000100.0%/ʦ/0017630098.0%/ʦh/0001770098.5%/ʨ/0040175497.0%/ʨh/0000517697.7%总计百分比16.7%16.7%16.7%16.7%16.7%16.7%98.1%检验//12000000100.0%/h/01200000100.0%/ʦ/0011740097.5%/ʦh/0001160097.0%/ʨ/0030116596.3%/ʨh/0000411595.7%总计百分比16.7%16.7%16.7%16.7%16.7%16.7%97.8%
在表1中,横列为预测值,即决策树通过计算对各个样本进行音位归类的结果,纵列为观测值,即每个样本本身所属的塞擦音音位类别,每个样本的即标签值,当纵列与横列的结果一致即为预测正确样本的数量(粗体字),通过观察该表我们可以发现:六个塞擦音预测正确率存在以下序列://、/h/> /h/> //>/h/> //,//与/h/在检验样本和预测样本中全部预测正确;/h/和//次之,/h/在训练样本和检验样本中预测正确率分别为98.5%和97.0%,//在训练样本和检验样本中预测正确率分别为98.0%和97.5%;/h/和//预测正确率最低,/h/在训练样本和检验样本中预测正确率分别为97.7%和95.7%,//在训练样本和检验样本中预测正确率分别为97.0%和96.3%。从训练样本和检验样本的预测正确率来看,两类样本的预测正确率均高于95%,分别为98.1%(训练样本)、97.8%(检验样本)。这说明决策树模型可靠性较强,接下来我们将在3.2考察塞擦音的音位聚类流程。
3.2 决策树分类流程的讨论
决策树经过学习生成了塞擦音的音位聚类流程,见图6。
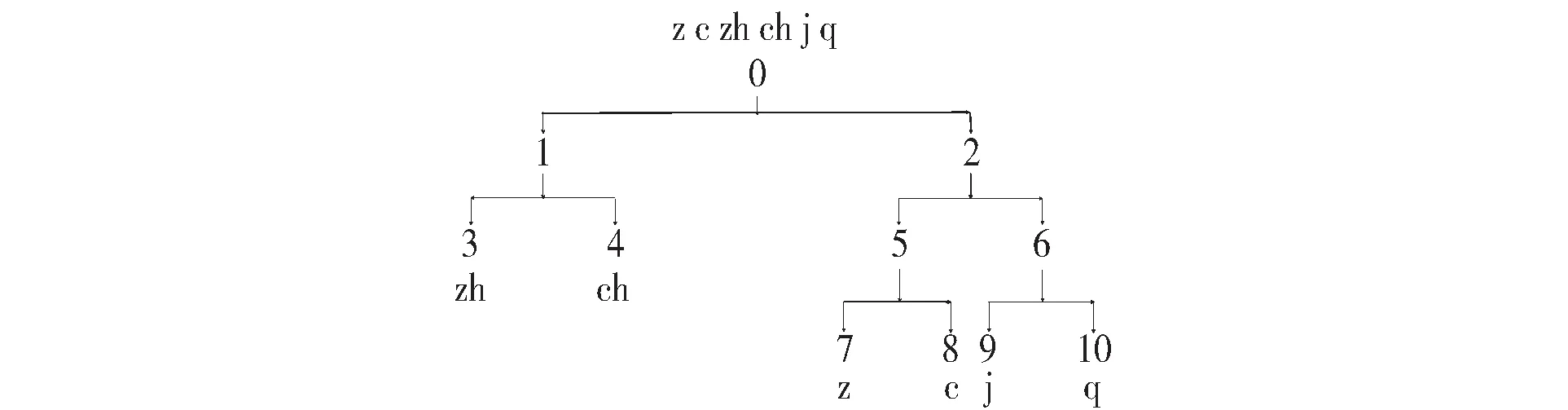
图6 塞擦音音位聚类流程
第一步,实现成阻部位前后的区分:决策树以节点0为父节点向下分类生成节点1和节点2,其中节点1为舌尖后塞擦音//、/h/,节点2为舌面前塞擦音//、/h/和舌尖前塞擦音//、/h/。
第二步,实现成阻部位面积大小的区分:决策树以节点2为父节点向下分类生成节点5和节点6,其中节点5为舌尖前塞擦音//、/h/的聚合,节点6为舌面前塞擦音//、/h/的聚合。
第三步,实现送气状态的区分:决策树分别以节点1(舌尖后塞擦音//、/h/)、节点5(舌尖前塞擦音//、/h/)、节点6(舌面前塞擦音//、/h/)为父节点,向下分类分别生成节点3(舌尖后不送气塞擦音//)、节点4(舌尖后送气塞擦音/h/)、节点7(舌尖前不送气塞擦音//)、节点8(舌尖前送气塞擦音/h/)、节点9(舌面前不送气塞擦音//)、节点10(舌面前不送气塞擦音/h/)。
3.3 决策树分类规则的讨论
决策树为还计算出分类规则,并将入选决策树的声学参数的声学分类标准以及相关节点的关联系数整理出来,见表2(括号内为声学参数作用的节点)、表3。
表2 决策树分类规则(终端节点)

分类规则/ʨ/VOT<99ms(节点6)、5017Hz<谱重心<7213Hz(节点0、节点2)、后接F2>2017Hz(节点2) 、偏度<0(节点0)/ʨh/VOT>99ms(节点6)、5017Hz<谱重心<7213Hz(节点0、节点2) 后接F2>2017Hz(节点2)偏度<0(节点0)/ʦ/VOT<96ms(节点5)、谱重心>7213Hz(节点0、节点2)后接F2<2017Hz(节点2) 偏度<0(节点0)//VOT>94ms(节点1)、谱重心<5017Hz(节点1)后接F2<2017Hz(节点3) 偏度>0(节点0)/ʦh/VOT<96ms(节点5)、谱重心>7213Hz(节点0、节点2)后接F2<2017Hz(节点2)偏度<0(节点0)/h/VOT>94ms(节点1)、谱重心<5017Hz(节点1)后接F2<2017Hz(节点4)偏度<0(节点0)
表3 相关声学参数在各节点关联系数汇总(8)关联系数值域等级:1.0-0.8为极强相关,0.6-0.8为强相关,0.4-0.6为中等程度相关,0.2-0.4为弱相关,0.0-0.2为无关联。

谱重心后接F2偏度VOT节点01.00(主变量)0.76(替代变量)节点20.73(替代变量)1.00(主变量)节点11.00(主变量)节点51.00(主变量)节点61.00(主变量)节点31.00(极强相关)节点41.00(极强相关)
基于表2、表3,并结合塞擦音的分类流程(图6),发现决策树利用谱重心、偏度、后接F2、VOT四项参数作为分类规则。接下来,分别以节点为单位,分析这四项参数如何作用于塞擦音的聚类流程:
1)在节点0,决策树以谱重心为主变量,以偏度为替代变量,实现舌尖后塞擦音(//、/h/)与舌面前塞擦音(//、/h/)、舌尖前塞擦音(//、/h/)区分,其中谱重心的分类规则如下://、/h/<5017Hz
2)在节点2,决策树以后接F2为主变量,以谱重心为替代变量,实现舌尖前塞擦音(//、/h/)与舌面前塞擦音(//、/h/)的区分,其中后接F2的分类规则为//、/h/<7213Hz2017Hz>//、/h/。
3)在节点1、节点5、节点6,决策树以VOT为主变量,分别实现各个发音部位的送气音与不送气音的区分,区分规则分布如下://<94ms
4 讨论
普通话塞擦音依靠以下三组区别特征:[后]([back])、[面部]([coronal])、[送气嗓音]([spread glottis])(9)QNS在构建声学清单时选择了Chomsky & Halle(1968)提出的区别特征体系,根据该体系,普通话塞擦音中送气与不送气的对立应用[送气嗓音]描述。实现六个塞擦音音位(//、/h/,//、/h/、//、/h/)的区分,结Chomsky & Halle(1968:113)提出的器官绑定特征和器官自由特征以及发音增强理论(Stevens 1989; Stevens & Keyser 2010),对以上三类区别特征与相关声学参数的关系进行如下描述:特征[后]实现舌位前/后的定义,特征[面部]实现舌面/尖音的区分,两项特征与特定的发音器官绑定,为器官独立特征,其中谱重心为标记特征[后]的标准声学参数,偏度为起到发音增强的参数,后接F2为标记[面部]特征的标准声学参数,谱重心对该特征起到发音增强的参数;[送气嗓音]因反映送气与不送气的对立,该特征不与具体发音部位绑定,反映的是两种声门开合状态的对立,即声源的对立,为器官自由特征,VOT为标记该特征的标准声学参数。
综上所述,可对塞擦音声学界标进行如下表述,见表4。
表4 塞擦音声学界标清单

器官绑定特征器官自由特征[后][面部][送气嗓音]谱重心(标准声学参数)偏度(发音增强参数)特征赋值后接F2(标准声学参数)谱重心(发音增强参数)特征赋值VOT(标准声学参数)特征赋值//<5017Hz//>0[+后]//<2017Hz[-面部]//<94ms[-送气嗓音]/h/<5017Hz/h/>0[+后]/h/<2017Hz[-面部]/h/>94ms[+送气嗓音]/ʦ/>5017Hz/ʦ/<0[-后]/ʦ/<2017Hz/ʦ/>7213Hz[-面部]/ʦ/<96ms[-送气嗓音]/ʦh/>5017Hz/ʦh/<0[-后] /ʦh/<2017Hz/ʦh/>7213Hz[-面部]/ʦh/>96ms[+送气嗓音]/ʨ/>5017Hz/ʨ/<0[-后]/ʨ/>2017Hz/ʨ/<7213Hz[+面部]/ʨ/<99ms[-送气嗓音]/ʨh/>5017Hz/ʨh/<0[-后]/ʨh/>2017Hz/ʨ/<7213Hz[+面部]/ʨh/>99ms[+送气嗓音]
由表4可知,与[后]相关的声学参数为谱重心与偏度,两者分别以5017Hz和0为声学界标。谱重心小于5017Hz,偏度大于0的//、/h/被赋予[+后]特征,谱重心大于5017Hz,偏度小于0的//、/h/、//、q/h/赋予[-后]特征(见表4);与[面部]相关的声学参数为谱重心与后接F2,两者分别以7213Hz和2017Hz声学界标,其中//、/h/因后接F2小于2017Hz,直接被赋予[-面部]特征,而//、/h/后接F2小于2017Hz,谱重心大于7213Hz,被赋予[-面部]特征,//、/h/因后接F2大于2017Hz,并且谱重心小于7213Hz被赋予[+面部]特征(见表4);与[送气嗓音]相关的声学参数为VOT,VOT分别以94ms、96ms、99ms为声学界标,实现[-送气嗓音]与[+送气嗓音]的区分,其中//、//、//因VOT数值分别小于94ms、96ms、99ms,被赋予[-送气嗓音]特征,/h/、/h/、/h/的VOT数值分别大于94ms、96ms、99ms,被赋予[+送气嗓音]特征。
通过上述分析可知,属于器官固定特征的[后]和[面部]特征均需要两项声学参数充当声学界标,才能完成区别特征的赋值,而属于器官自由特征的[送气嗓音]只需一项声学参数充当声学界标,便能完成特征赋值(见表4)。两类特征所需声学界标数量的差异,反映了声源对立与前腔滤波对立的生理差异。声源上的送气与不送气是一个简单的二元对立状态,而反应发音部位差异的前腔滤波,因前腔收紧点位置前后以及前腔收紧点面积的大小,则呈现出一种多元对立的状态,以下分别讨论。
4.1 关于器官自由特征的赋值
先来讨论与声源类型密切相关的器官自由特征。对于普通话塞擦音,[-送气嗓音]与[+送气嗓音]的对立,本质上反映了塞擦音在发声时声门开放程度的均在一种二元对立的状态,不送气音清音声门开放程度约为喉开态(即:声门最开的状态,下同)的40%-55%,此时临界期流量率为120-210 m2/s;送气清音的声门开放程度约为喉开态60%-95%,临界期流量率为250-300m2/s(朱晓农2008:69)。苏敏和于洪志(2016)利用PAS,从发音生理的角度,考察了普通话塞擦音发声时的PEA值(Peak Expiratory Airflow 即峰值气流,该值的大小与声门的张开面积成正比,声门张开程度越大,其数值越大,反之则数值越小),其结果见表5。
表5 塞擦音PEA值汇总

音位类别///h//ʨ//ʨh//ʦ//ʦh/PEA均值特征赋值1.04[-送气嗓音]2.19[+送气嗓音]1.20[-送气嗓音]2.71[+送气嗓音]0.69[-送气嗓音]1.76[+送气嗓音]
通过观察反映塞擦音发音时声门气流量大小的PEA值(见表5),可发现如下规律://(1.04)
4.2 器官绑定特征的赋值
相比之下,反映前腔滤波差异的器官绑定特征则的特征赋值相对复杂。不同发音部位的塞擦音,因收紧点差异,实现不同的前腔滤波,体现在音位系统上便是不同发音部位的对立,即器官绑定特征。对于塞擦音来说,声腔内收紧点的位置从前往后有三种选择分别为:舌尖前、舌面前、舌尖后。舌尖前塞擦音发音时舌尖与上齿龈接触,舌面前塞擦音发音时舌面的接触点位于上齿龈与硬腭的交界处,舌尖后塞擦音发音时舌尖与硬腭接触;从收紧点面积大小来看,收紧点面积有两种选择,分别为舌尖与舌面,舌面音的接触面积要大于舌尖音的接触面积(鲍怀翘和林茂灿 2014:158)。这种多元状态下的对立,鲍怀翘和郑玉玲(2011)利用EPG从CC值(与舌腭的靠前性(contact anteriority)有关,数值越大,其前靠性越前)与CA值(描述舌与上腭之间接触的宽度,数值大小与接触面积成正比)对塞擦音生理参数进行了量化研究,见下页表6。
通过观察反映收紧点前后的CA值(见表6),塞擦音收紧点由前往后依次为// (0.93)、/h/(0.88)> //(0.85)、/h/(0.80)> //(0.75)、/h/(0.76),这与谱重心作为标准声学参数体现出的序列://、/h/>7021Hz>//、/h/>5017Hz>//、/h/是一致的(见表4)。可见塞擦音在收紧点前后位置上存在前、中、后三种选择,三分的范畴如何在声学上实现[-后]与[+后]二分对立呢?Stevens & Keyser(2010)的“发音增强”理论完美的解释了这一问题:任何一个区别特征的声学界标都由一个标准的声学参数来标记,并由此反映“声学—发音”基本格局,但在实际语流中常常还有别的声学参数可以起到强化区别特征在听觉上对立的显著性(perceptual saliency)的作用。对于普通话塞擦音来说,[后]的标准声学参数为谱重心,谱重心数值大小直接反映了收紧点的前后顺序,但由于塞擦音收紧点的前后位置存在前(舌尖前)、中(舌面)、后(舌尖后)三种选择,为了凸显标准声学参数谱重心以5017Hz为界标对[-后]与[+后]的分界,普通话选择用偏度的正负对立来增强[-后]与[+后]的对立,其中偏度若大于0说明频谱能量主要集中于低频区,即收紧点是较为靠后的,因而被强化[+后]特征(如//、/h/);偏度若小于0说明频谱能量主要集中于高频区,即收紧点靠前,因而被强化[-后]特征(如//、/h/、//、/h/)(见表4)。
表6 塞擦音CA值、CC值汇总
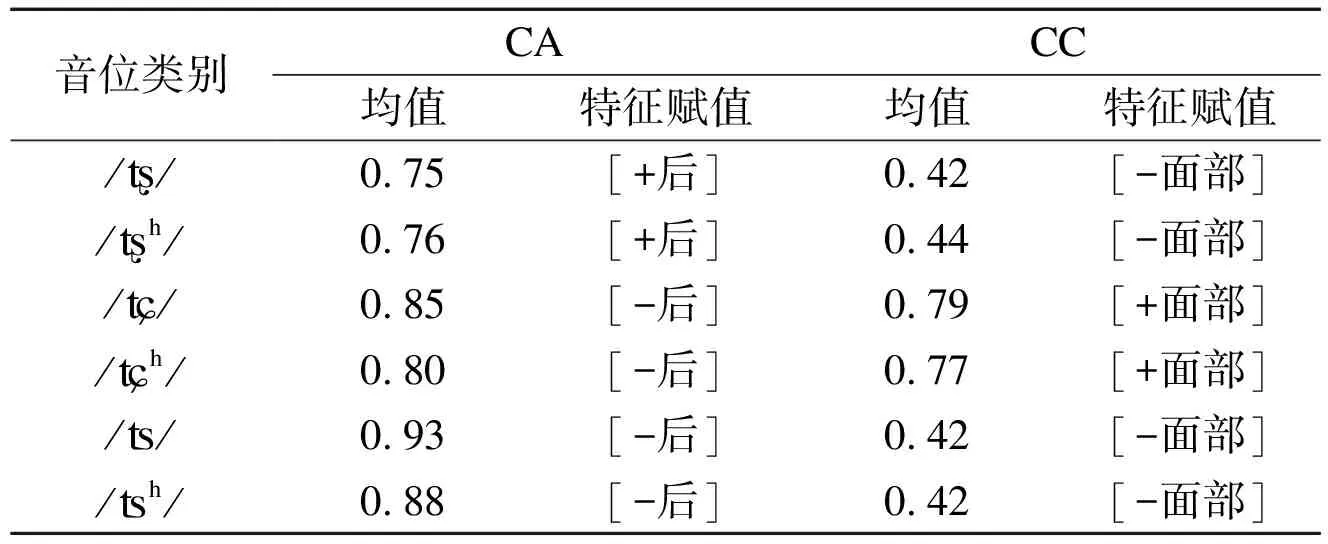
音位类别///h//ʨ//ʨh//ʦ//ʦh/CACC均值特征赋值均值特征赋值0.75[+后]0.42[-面部]0.76[+后]0.44[-面部]0.85[-后]0.79[+面部]0.80[-后]0.77[+面部]0.93[-后]0.42[-面部]0.88[-后]0.42[-面部]
接下来讨论[面部]的赋值情况。观察CC值(见表6),塞擦音与上腭或齿龈的接触面积体呈现出如下序列://(0.42)、/h/ (0.42)、// (0.42)、/h/ (0.44)
Stevens & Keyser(2010)认为,区别特征与“发音增强”存在三种关系:1)有些特征只需要一项标准声学参数,便可以完成区别特征的赋值,不需要其他参数进行发音增强;2)某项声学参数只对一种区别特征起到发音增强的作用,与其他区别特征的赋值无关;3)某项声学参数可以在某一区别特征中起到发音增强的作用,也可以与其他区别特征赋值相关(Stevens & Keyser 2010)。根据以上讨论,不同声学参数在对塞擦音进行区别特征赋值时,正体现了以上三种情况:1)[送气嗓音]的特征赋值与具备[+后]特征的//、/h/在进行[-面部]特征的赋值时不存在“发音增强”,只需要调用标准声学参数便可完成特征赋值;2)[后]特征的赋值,既需要标准声学参数(谱重心)进行赋值,也需要调用偏度作为发音增强的参数强化特征赋值,而偏度不与其它特征的赋值产生关联;3)同时具备[-后]特征的//、/h/与//、/h/在进行[-面部]与[+面部]的特征赋值时,不仅调用标准声学参数(后接F2),同时也调用了谱重心作为发音增强的参数强化特征赋值,而谱重心在[后]特征的赋值中,是标准声学参数。区别特征与发音增强的这种不对称关系,也从另一个侧面反映了“声学—生理”的对应关系。
4.3 其余参数讨论
还有一个现象值得关注。本次实验共选用VOT、GAP、振幅、谱重心、谱顶点、偏度、峰度、标准差、后接F2等9项参数描述塞擦音的声学特征,但决策树只选择了VOT、谱重心、偏度、后接F2这4项参数作为普通话塞擦音的分类规则。GAP、振幅、峰度、标准差、谱顶点5项参数均未入选塞擦音音位的分类规则,为了进一步量化考察这5项未被入选的参数,我们将其对应所在节点的关联度整理为表7。
表7 GAP、振幅、标准差、峰度、谱顶点关联系数汇总(10)表7的关联等级,请参考表3的注释。
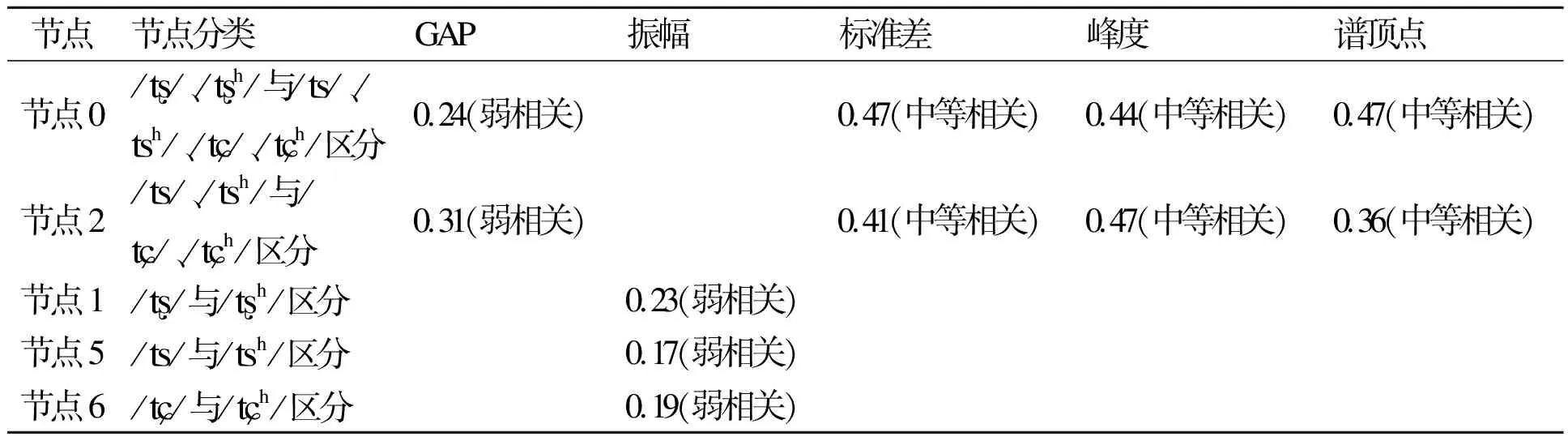
节点节点分类GAP振幅标准差峰度谱顶点节点0//、/h/与/ʦ/、/ʦh/、/ʨ/、/ʨh/区分0.24(弱相关)0.47(中等相关)0.44(中等相关)0.47(中等相关)节点2/ʦ/、/ʦh/与/ʨ/、/ʨh/区分0.31(弱相关)0.41(中等相关)0.47(中等相关)0.36(中等相关)节点1//与/h/区分0.23(弱相关)节点5/ʦ/与/ʦh/区分0.17(弱相关)节点6/ʨ/与/ʨh/区分0.19(弱相关)
由表7可知,决策树认为GAP、标准差、峰度、谱顶点作用于节点0和节点2(见图2),即区分三类发音部位:舌尖前、舌尖后、舌面前,认为振幅作用于节点1、节点5、节点6(见图2)即送气状态的区分,但以上五类参数均对各自节点的分类关联度不高,其关联水平均处于弱相关或中部相关,因而决策树将没有将这五项参数列入分类规则。(11)我们只承认GAP、标准差、峰度、谱顶点、振幅这5项参数无法有效反映塞擦音内部音位聚类关系,但这5项参数是否能够真正反塞擦音与擦音的对立以及其他音位之间的区分,仍需进一步量化考证。基于以上数据,我们认为并不是所有表征塞擦音声学特性的声学参数均能反映塞擦音在声学—生理上的量子关系。石峰(2008:1)指出:语音研究应当从“口耳之学”转向“数值之学”。近年来围绕语音声学特征所做的定量研究,深化了语音的认识,不过在进行定量研究时,应当避免走极端,不能片面地将声学参数的数值差异当成区别特征对立的声学表现。区别特征是一个音位学概念,涉及到人类对语音的听觉感知,而声学参数是一个声学概念,是一个物理量,任何一种语言的语音都会包含多种类别的声学参数,但这并不等同所有语言在实现音位对立时 选择相同的声学参数。正如,Hjelmslev对“表达实体”和“表达形式”的区分:语言的表达实体为人类发音器官所能发出的一切语音,表达形式为不同语言对语音的切割结果;表达实体在不同的语言系统中可以切分为不同的表达形式(刘润清2013:134)。Stevens & Keyser(2010)继承了这一思想,他指出:不同语言“声学参数—区别特征—发音参数”的对应关系均存在差异。如果仅考虑“声学特征—区别特征”对应关系,同一区别特征很在不同语言的声学实现上有可能存在差异,反映在声学界标上,即为不同音系对区别特征声学界标的选择均存在自己的特点。此次研究,完美地证明了Hjelmslev和Stevens的观点,VOT、谱重心、后接F2、偏度4项参数,可反映塞擦音的“声学参数—区别特征—生理参数”关系,而GAP、标准差、谱顶点、标准差、振幅5项参数对于反映塞擦音内部的“声学参数—区别特征—生理参数”的量子关系,联系不大(刘润清2013:134; Stevens & Keyser 2010)。
5 结论
本研究基于QNS理论,对普通话塞擦音的声学界标清单进行了探索性研究,得出以下三点结论:
1)谱重心、VOT、偏度、后接F2可以作为声学界标来描述塞擦音的声学清单,其中反映器官自由特征的[送气嗓音]特征只需要VOT一项参数,作为标准声学参数便能实现特征赋值,反映器官绑定特征的[后]需要借助谱重心和偏度来完成特征赋值,反映器官绑定特征的[面部]特征需要借助后接F2、谱重心完成特征赋值。
2)对于器官绑定特征来说,其区别特征的赋值不仅与反映其基本声学特征的标准声学参数有关,还需要其他参数用来凸显特征对立的显著性。谱重心为标记[后]特征的标准声学参数,偏度仅起到增强[-后]与[+后]的对立效果;后接F2为标记[面部]特征的标准声学参数,谱重心(仅限于//、/h/与//、/h/区分)仅起到增强[-面部]和[+面部]的对立效果。
3)并不是所有表征塞擦音的声学参数均能充当声学界标,反映塞擦音“声学参数—区别特征—生理参数”之间的量子关系。本次实验我们发现GAP、谱顶点、振幅、标准差、峰度5项参数对于解释塞擦音音位聚类的关联度较差,无法反映塞擦音的“声学参数—区别特征—生理参数”量子关系,因而不能充当塞擦音内部聚类的声学界标。
