基于机器学习的Android系统漏洞扫描处理系统设计
2019-11-12陈朗王春玲
陈朗 王春玲
摘要:由于近年来,随着无线网络的普及和 4G 向5G网络过渡时代的到来,移动手机凭借其简单易用、便于携带等特点迅速取代笔记本电脑、台式电脑等其他移动设备成为使用率最高的个人上网设备。同时,线下生活与移动互联网大部分重叠,比如购物、支付、物流、银行、外卖等业务都可以通过手机设备来实现。研究公司Gartner最近发布了一份数据,数据显示去年在全世界销售的智能手机中,有大约99.9%的设备都是基于Android或iOS平台的,可以看出其他系统的移动设备在市场上已经没有太多的份额。作为在移动设备市场领域占有率高达 87.5%的 Android 手机,针对其漏洞扫描处理的研究对于保护个人隐私信息和财产安全具有重要意义。研究在 Android 平台的第三方app漏洞挖掘方法有利于及时发现并修补 Android 平台漏洞,同时便于提高 Android 平台的安全性。第三方app漏洞有可能是应用开发者无意或是有意留下一些漏洞,这些漏洞利用现在的木马程序通常不是一个独立的程序,而是把恶意代码注入用户使用频率高、并不会引起人警觉的app中蒙蔽用户,让用户认为与其他应用没有区别,比如上文中提到的实现购物、支付、物流、银行、外卖等功能的第三方app中,窃取用户信息和资源。恶意软件能给用户隐私带来的威胁非常普遍,但是一些看似普通的软件也达不到没有恶意行为的要求。因此,为了保障手机用户的信息和资源开发手机漏洞扫描软件保护用户安全十分必要。
关键词:5G网络;移动手机;app漏洞;恶意代码;用户信息安全
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2019)25-0020-03
对第三方app传统的漏洞扫描方法的重要目的就是最大限度地找出app中存在的漏洞威胁。以便于后续分析存在的漏洞,常用的漏洞挖掘方法是动、静态分析为主。
传统的漏洞挖掘方法包括静态分析和动态分析,静态分析是指不用运行被检测的软件,而只是静态地检查程序代码、界面或文档中可能存在的不正确内容的过程。动态分析指的是让被测程序运行起来,输入合适的测试数据,检查实际输出结果和预期输出结果相不相符的过程,所以判断一个测试属于动态测试还是静态的,唯一的标准就是看是否运行程序。
在很多的漏洞挖掘技术中,软件渗透测试,模糊測试,静态数据流分析应用相对比较广泛,其次是利用数据科学以及人工智能领域技术的方法来对app漏洞进行分析和挖掘漏洞,在2011年以后人们对机器学习和数据的挖掘技术有了很大的关注。由于机器学习方法已经在不同的应用场景都有着显著且卓越的效果,且能发现手机中存在的未知和潜在漏洞,所以本文重点研究基于机器学习的手机漏洞扫描处理系统的设计。
1 基于机器学习漏洞扫描处理系统设计
机器学习所关联范围都是基于有大量的数据基础支撑而实现的。机器学习中所涉及的监督学习会有两套不同类型的样本集,训练和测试数据,通常我们把手上总数据的90%作为训练样本来训练分类器,另外10%的数据用作测试已经训练的分类器,用于得到分类器在分类结果的正确率。数据量越大,测试结果的准确率越高。基于机器学习的app漏洞扫描处理系统的设计需要面对的问题就是如何将移动设备上的app以数据的形式呈现出来,并且选择适当的算法对各个app进行分类。
1.1 信息采集
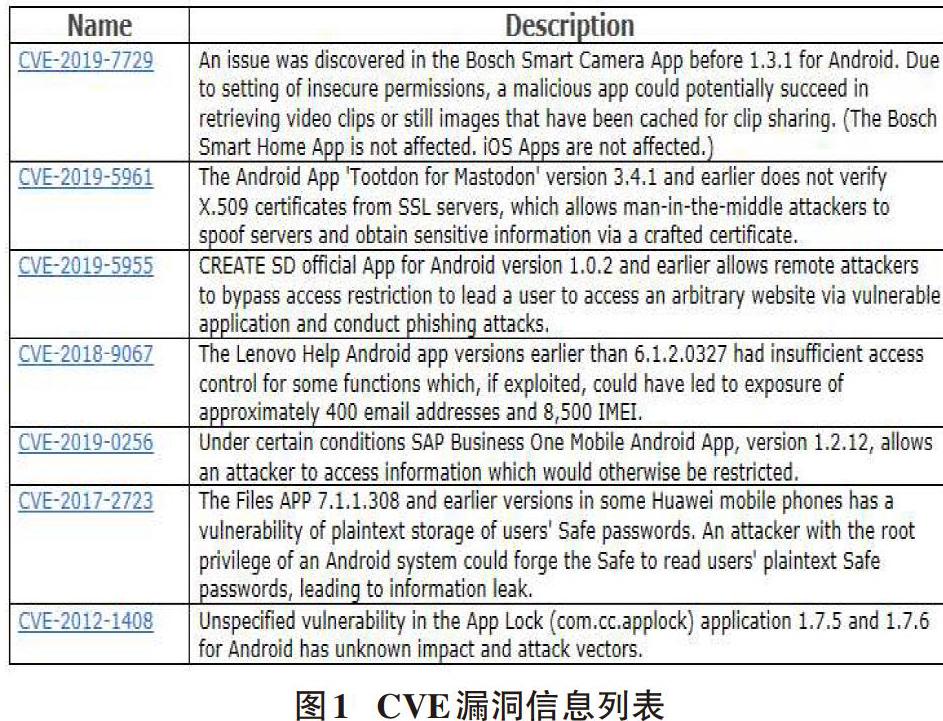
对于Android系统中第三方app的漏洞来说,找到app的相关重要属性标签,是判断其是否存在漏洞的重要依据。用机器学习的方法来实现漏洞扫描就必须又有大量的漏洞数据来支撑前期的监督学习,而建立数据集可以通过CVE来辅助实现。CVE被认为是一个字典表,即每个CVE漏洞都有它唯一的编号Name。图1是CVE漏洞信息列表的详细信息。
图中显示CVE漏洞编号以及涉及的app应用名称,版本信息,手机型号和具体漏洞信息的描述。截至目前,CVE中有119095条漏洞条目信息。在CVE中搜索列表中输入Android条目,显示有5160条信息。如果能把有关Android的漏洞信息作为机器学习的数据集基础,运用python爬虫技术爬取cve中关于android漏洞信息,那么在采集信息方面的问题已经得到解决,下一步就是处理数据信息。
1.2 漏洞信息处理
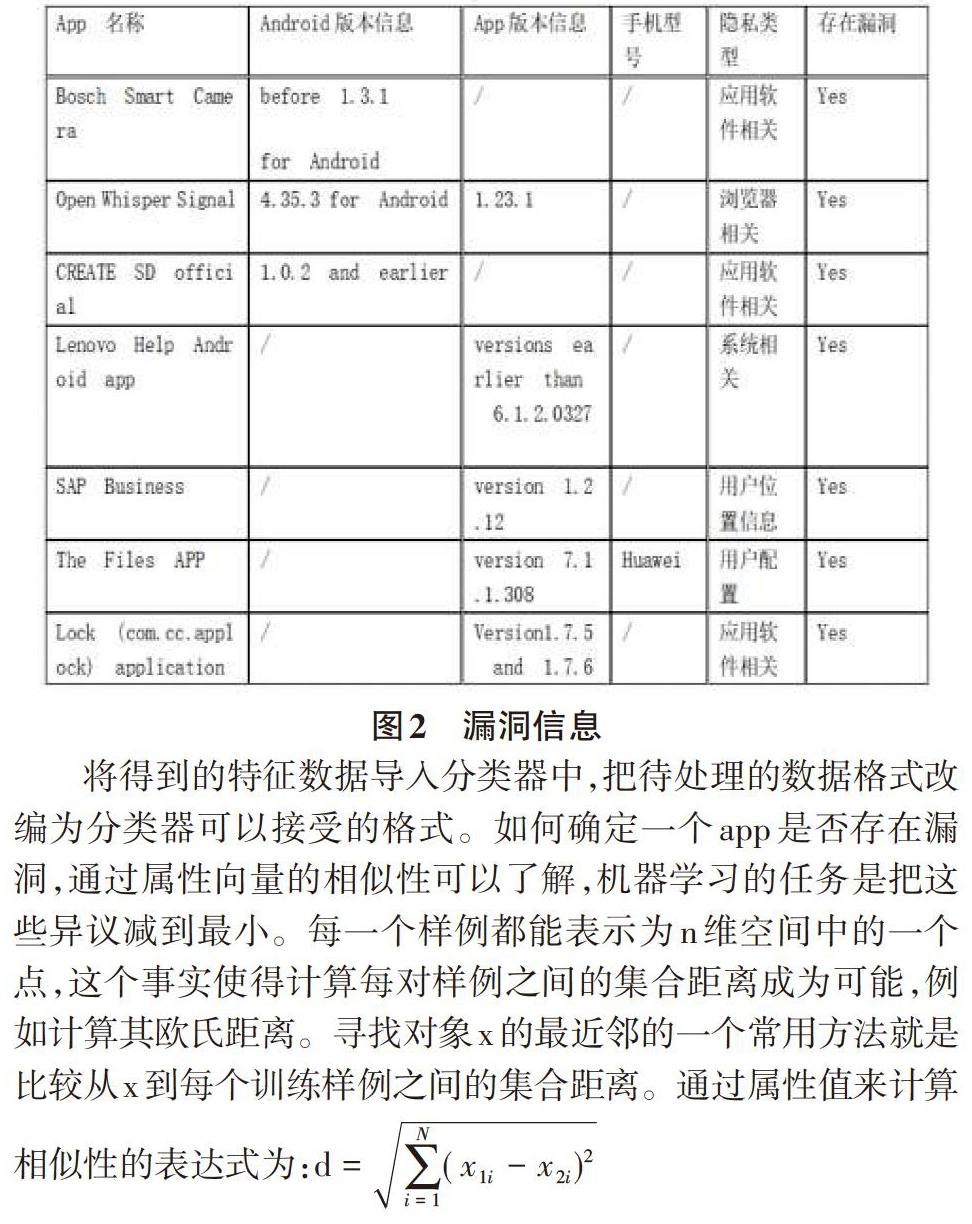
当得到样例信息之后使用k邻近算法对我们得到的信息进行分类,对模型进行训练。一旦另外输入样例的时候,在训练数据集中匹配与该实例最邻近的K个实例,这K个实例的多数属于某类,就把该输入实例分类到这个类中,差异越小,相似度越高。属性向量,为将训练样例发送给机器,我们要用合适的方法描述这些样例。最常见的方法就是使用所谓的属性,在“漏洞”问题域中,可以有种属性,比如App名称,App版本信息,手机型号,存在漏洞等,见图2。在后期的研究过程中进一步深入了解如何添加每一个样例的相关属性,减少不相关属性的影响,不相关属性会增加计算开销且存在一定的误导性。
将得到的特征数据导入分类器中,把待处理的数据格式改编为分类器可以接受的格式。如何确定一个app是否存在漏洞,通过属性向量的相似性可以了解,机器学习的任务是把这些异议减到最小。每一个样例都能表示为n维空间中的一个点,这个事实使得计算每对样例之间的集合距离成为可能,例如计算其欧氏距离。寻找对象x的最近邻的一个常用方法就是比较从x到每个训练样例之间的集合距离。通过属性值来计算相似性的表达式为:[d=i=1N(x1i-x2i)2]
1.3 训练结果
建立训练模型之后,这组数据就线性可分(linearly separable)了。为了测试分类器的效果,我们可以用已经知道结果的数据来检测结果,判断分类器给出的结果是否符合预期目标。通过大量基础的测试与数据分析,我们就可以分析出分类器的错误率。再次给分类器一个新的数据的时候,就可以分类成功从而得到结果。
由于所有的数据点都在一个平面直角坐标系中,所以此时一条线可以将此平面分割开来。支持向量(support vector)就是与分隔线距离最小的点集。接下来要试着最大化支持向量到分隔面的距离,需要找到此问题的优化求解方法。
以用户数量作为图像的y轴,隐私类型出现次数为x轴。用户数量数值越高出现的app漏洞可能性越小,用户数量和漏洞数量之间存在一定的线性关系。分析数据的过程中我们需要将差值最大的数据,也就是对实验结果影响最大的特征值数据进行调整,在处理一些有差异的取值范围的特征值时,通常采用的方法是将数值归一化。可以将取值范围调整为0到1之间。存在公式能把各种取值范围的特征值换算为0到1区间里面的数值:newValue = (oldValue-min)/(max-min) 。
输入数据给分类器会输出一个类别标签,如果输入app数据是存在漏洞的那么就会出现在图中+号集中位置,如果在-号集中位置那么则不存在漏洞。输入一个未知app数据,分析样本集中所有app与未知app的距离,按照距离的远近进行递增排序,计算出k个距离最近的app。假定k=10,则两个最靠近的电影依次是Bosch Smart Camera和Tootdon for Mastodon 。k-近邻算法按照距离最近的两个app的类型,决定未知app的类型,而这两个app都存在漏洞,因此我们判定未知app存在漏洞。
2 结语
在互联网飞速发展的时代,人们的生活逐漸向智能化迈进。相对于传统的漏洞扫描方法而言,运用机器学习方法的优势在于可以处理更大的数据量,且数据量越大准确度越高,可处理数据量远高于人工分析,体积更大且有利于对未来数据更新分类,将新输入样例与以往样例数据匹配对比得出结论。通过常用预测模型,进行实验,科学对比结果,最后通过图形,表格方式形象地表达出来,同时减少实验成本和负担。本文研究与分析了在传统Android 的系统漏洞,机器学习方法对漏洞扫描的原理和设计,使漏洞扫描系统更加智能化且效率更高。
参考文献:
[1] 于浩佳.Android应用漏洞分析及安全性评估技术研究[D].江苏:南京师范大学,2018.
[2] 刘昊晨.基于Lua引擎的Android漏洞检测工具研究[D].四川:西安电子科技大学,2015.
[3] 许杰.基于机器学习的医疗健康分类方法研究[D].河南:郑州大学,2018.
[4] 成厚富.智能手机漏洞挖掘技术研究[D].四川:西安电子科技大学,2008. DOI:10.7666/d.y1246905.
[5] [美]Peter Harrington 著,李锐、李鹏、曲亚东 译.机器学习实战[M].人民邮电出版社,2013.
[6] [美]米罗斯拉夫·库巴 著.机器学习导论[M].特机械工业出版社,2016-11-01.
[7]戴春春.漏洞利用自动生成算法的设计与实现[D].四川:西安电子科技大学,2017.
[8] 刘柳.Android手机用户隐私保护系统及其关键技术的研究[D].四川:电子科技大学,2017.
[9] 张翼飞.中国智能手机现状研究及建议[J].社会科学前沿,2018,7(10):1670-1674.
[10] 刘蓉,于浩佳,陈思远, 等.基于APP分层结构的Android应用漏洞分类法[J].信息安全研究,2018,4(9):792-798.
[11] 郝蕾.Android系统开发APP端常见安全漏洞解读[J].计算机与网络,2016,42(21):59.
【通联编辑:李雅琪】
