影响区域房价的客观因素挖掘分析
2019-11-12张智鹏郑大庆
张智鹏 郑大庆,2
1(复旦大学计算机科学技术学院 上海 200433)2(上海财经大学信息管理与工程学院 上海 200433)
0 引 言
房价一直被国人广泛关注,因为这个问题是个广受关注,而又一直没有得到良好解决的社会问题。而关于房价预测也成为了全世界各个国家政府、市场与人民关注的热点话题。在完全市场环境下,房价由需求和供给共同决定,但是由于在当前的社会,房屋既具有居住效用,又兼具投资效用[1],使房价问题的研究非常复杂,预测长期房价成为一个不可能完成的任务。
基于这样的现状,本文把影响房价的因素分为两个方面:首先是政府的宏观政策层面的影响因素,包括货币政策、税收政策和土地供应等对房价的影响;其次是基于特征的房价预测(Hedonic pricing)[2]。房屋特征包括两个方面:中观层面的区位因素对房价的影响,包括地理位置的优越性和周边的公共设施的便利程度等;房屋本身的因素对房价的影响,例如楼层、采光、朝向等。宏观政策具有不可预见性的特点,属于典型的外部冲击,其对房价的影响非常复杂,所以研究房屋特征对房价的影响成为越来越重要的趋势[3]。而房屋本身的个体异质性对房价影响的现实意义有限。在房价预测中,最有借鉴意义、比较可行的问题归结为区位因素对房价的影响,即区域房价的预测。
本研究的目的是寻找区域平均房价与城市中社会情境要素之间的关联性。在具体的案例研究中,我们以北京市居民居住住房作为研究对象,应用梯度提升决策树(Gradient Boosting Decision Tree)模型来挖掘其特征空间中的非线性关系,并且达到92%的拟合程度,优于常见的基准算法。此外,通过特征排序,我们也找到一些影响区域房价的重要因素,包括住户区包含的住宅数量,住户区周边的出租车流量、公共设施、学校、购物服务、地铁线路、生活服务等。这让房价研究从数据挖掘的角度找到合理的依据,避免单纯从直觉判断。
本文主要贡献点如下:
(1) 本研究将多源、异构的城市基础数据进行融合,采用机器学习的方法,寻找影响区域房价的客观因素。这种研究思路利用了把分散的数据进行融合、提高预测效果的大数据思维方式。
(2) 利用基于学习模型的特征排序,通过GBDT模型选择影响房价变化的客观因素中重要的因素,进而探究对某区域房价影响最大的相应属性。
(3) 工程化实验过程,设计房价预测界面,模拟实验思路进行人机交互,持续获取房价与客观属性的信息。
1 相关工作
区域房价的研究属于城市计算的范畴,近些年有越来越多的研究开始关注城市计算,不少学者也通过城市大数据找到了城市中很多潜藏的规律,并以此帮助城市建设者们进行决策。例如,可以通过机器学习来解决区域功能识别[4]和共享单车的放置[5]问题,通过探究POI数据和地理信息数据预测人的流动性[4,6]等。种种研究都表明城市大数据之间存在着广泛的相关性,而这些相关性为城市的持续智能化提供了信息线索。
房价方面的研究方兴未艾,少数从计算机技术出发的房价研究工作切入点都不尽相同。文献[7]通过网络查询数据对房价规律做研究,认为网络搜索的数据可以反映搜索者的关注,因此去寻求住房价格指数与网络搜索数据之间的相关性,对不同经济层次的两个区域(北京和兰州)进行比较分析。文献[8]则利用非参数隐流形模型探究房价构成,利用洛杉矶的一个房屋信息数据集,分成两个训练组。第一个是一个参数化模型,预测影响房价的“内在”因素。第二个是一个非参数模型。房屋的预测价格是其内在价格和期望值的乘积。对这两个训练组进行训练,同时使用EM算法估计参数。最终,他们认为房价取决于不可测量的一些因素,如房子的特点、对邻里的可取性等。文献[9]通过对不同房型房价产生影响的因素做分析,对6组影响变量做回归分析,最后认为人均收入的影响最明显。文献[10]则通过神经网络做房价预测,他们采用两种算法来预测新加坡的房地产市场,即人工神经网络(ANN)模型与自回归移动平均(ARIMA)模型,通过两者比较发现更优的模型是神经网络模型,并用此模型预测未来的公寓价格指数(CPI)。文献[11]使用经典时间序列分析方法预测上海房价指数。文献[12]采用两种建模方法,多层次模型和人工神经网络来模拟房价。并将这些方法和标准Hedonic价格模型在预测准确性、捕获位置信息的能力以及解释力方面进行了比较。文献[13]使用延迟神经网络模型来预测新加坡的公共住房价格,具体用来估计新加坡房屋发展局(HDB)的房屋转售价格指数(RPI)的趋势,最终他们找到九个独立的经济和人口变量。结果表明,延迟神经网络模型能够产生良好的拟合预测。文献[14]则开发了一种基于多任务学习的回归方法来预测房地产DOM指数,他们选择从异构的房地产相关数据中全面考察多个因素,这给予了我们全面考察与房价相关数据的思路。文献[15]开发了一套在线住房选址可视分析系统ReACH,将价格、面积、卧室数量等要素包括在内的同时,也重点考虑了在地理决策中占据重要地位的地标位置可达性(Reachability),他们关于人机交互系统的开发也给予了我们设计人机交互界面的思路。以上方案都针对房价的不同层面进行研究,所采用的数据挖掘算法也不尽相同,基本上都是规律挖掘,对实际情况的检验方面都没有很详细的阐述。
与以上研究相比,本文将重点聚焦在短时间段的区域房价上。首先,为了避免不同房屋特性对于房价的影响,本文关注小区的平均住宅价格的变化,以及其价值背后的原因;另外,短时间指的是某一天内,在这个时间段上任何主观因素对于房价的影响都不会持续很久,真正对区域平均房价产生影响的更多来自于住户区周边的客观因素。通过对这些客观因素的挖掘,对住户区平均房价进行精准画像。这样选择的实际意义就在于能够从社会情境的角度,帮助区域房屋定价找到一个客观标准。
具体上,我们以广受关注的北京市居民居住住房作为研究对象,利用其作为国际化大城市而拥有的丰富社会情境要素和充足的住房数据,可被用于训练和验证。实验表明其拟合程度达到0.92上下。同时也发现住户区包含的住宅数量,住户区周边的出租车人流数量、公共设施、学校、购物服务、地铁线路、生活服务等是对住户区房价有明显影响的因素。此外,在完成关联关系挖掘之后,本文也将实验过程工程化,设计和开发了住户区房价的人机交互,力求实验结果能在现实生活中得到有效利用。
2 方法设计
2.1 问题描述
本文方法的总流程框架如图1所示。

图1 流程框架
(1) 针对具体位置,统计其所处环境的社会情境,具体的社会情境要素是指当地住房数目、游客数量、城市基础设施、以及在一定半径内的地铁线路的数量等。将这些异构数据进行数据清洗和预处理,得到其社会情境要素。
(2) 寻找社会情境和具体房价之间的相关性,建立一个预测模型。同时,找出影响预测的变量,即影响房价变化的客观因素。
(3) 系统实现实验规律,设计人机交互界面,用户通过访问界面来得到某区域内的房价预测,以及支撑这样价格的客观背景因素。
2.2 社会情境
本文的目标是挖掘社会情境和房价之间的关系,因此选取居民住户区在半径为1公里的圆形区域作为目标地点,统计其区域住宅价格、户数、出租车上下车数量、POI等,在范围为2公里的区域内统计其所包含的地铁线路。1公里的范围基本可认定为步行可达区域,而2公里范围的地铁路线可为该区域提供轨道交通服务。根据这些因素与房价之间的关系,揭示每个变量对房价变化的影响。图1展示了区域平均房价预测与分析的流程图,其中基于GBDT的特征排序旨在找到影响房价的变量,从而在客观因素上提供房价变化的原因。主要社会情境要素的详细定义如下:
(1) 人群流量 利用出租车GPS轨迹,我们可以找到反映人群流动的起始-目的地(OD)流,这对于房价预测是很重要的,因为访问者的数量可以体现一个住户区的热闹程度。在这里,让OCVi和DCVi代表进入住户区i和离开住户区i的人群流动数目,作为两个变量。
(2) 住宅数量 住户区包含的户数体现了该住户区的疏密程度,同时也反映了周边地区的人口。通常一个区域所包含的住户数,与小区的规划、规模、定位、档次都有关系。因此,我们统计了住户区i的住宅数量HNi。
(3) 区域功能 众所周知,一个区域所包含的各类基础设施体现了该区域的功能属性,而一些重要的功能属性会影响该区域内的房价变化。例如,包含学校的区域就会形成“学区房”,即使周边基础设施一致,通常情况下“学区房”的价格也会高一些。在这里,我们利用“BoW”模型来表征每个地区的城市功能,在1公里的范围内计算不同类别的POI的分布。对于住户区i,将其范围内的POI表示成矢量形式:
(1)
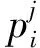

表1 POI的21个种类
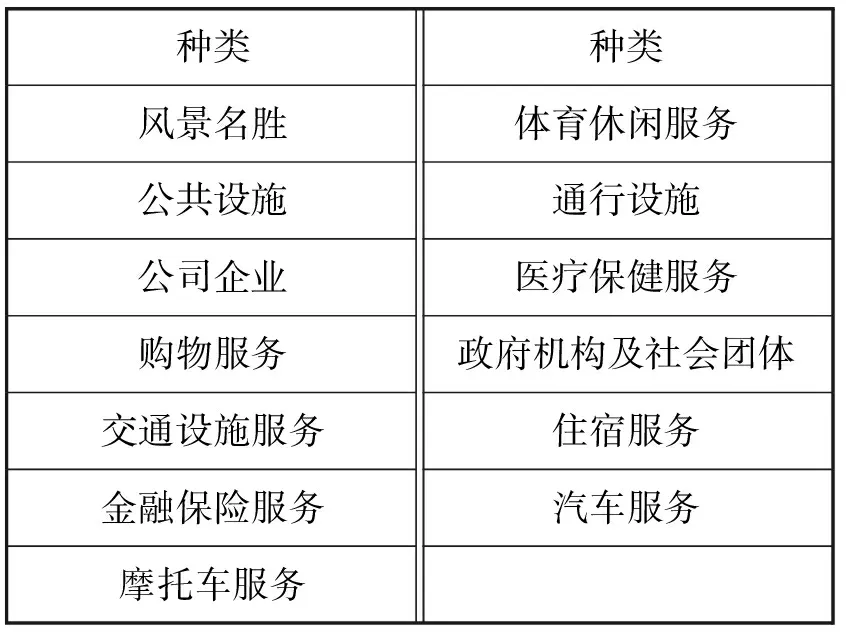
续表1
(4) 地铁线路 地铁线路对于房价的影响在大城市中越来越重要,因为地铁的准时和无延迟性,使得地铁已经成为大多数上班族上下班出行的方式,考虑到每个地铁站根据不同地铁连线而产生的多条出行路线,因此有:
ROUi=METN·METi
(2)
式中:ROUi代表区域i可通行路线;METN代表区域内地铁站数;METi代表某地铁站路线数。这样既包括了影响人们出行的地铁站的个数,也将其出行选择可能性包含在内。
2.3 数据处理
• 去除噪音数据 噪音数据有以下两个特征:(1) 数据本身没有意义或意义模糊;(2) 噪音数据离差(样本值与样本空间均值的差的绝对值)过大。噪音数据对实验造成很大的误差,因此,设定判决门限去除无意义或意义模糊的噪音数据。
首先,针对现实意义中为错误的数据进行过滤,如区域平均房屋价格小于1 000、各属性数据为负等。对数据进行遍历,剔除错误样本。
另外,针对离差过大的数据,利用随机采样一致性的方法进行过滤[16]。利用随机抽取数据建立一个带参数的模型,不断迭代其余数据在此模型上的误差,并最小化误差,将误差大的样本点进行剔除。
• 数据标准化 多模态数据所处的参考系不同,数据的属性取值范围也是千差万别。若要实现多模态的数据综合分析,则要将异构数据放到同样的参考系中,对数据进行标准化。本实验采用线性标准化手段处理数据,如下:
(3)
式中:n是样本个数。
2.4 关联挖掘
本文统计了北京大部分小区的平均房价,鉴于单独房屋的价格对于社会情境要素的关联性比较小,因为其更多的会受到房屋本身的影响,比如楼层、格局等等。而整个小区的平均价格能够降低房屋本身因素的影响,因此本文用HPi代表住户区i的平均房价。
根据以上社会情境因素统计(具体见表2),本文将住户区i的社会情境要素整理成以下矢量:
SCi=[OCVi,DCVi,HNi,Fi,ROUi]
社会情境要素SCi与房价HPi的关联关系如下,其中p代表住户区的数量。

表2 输入与输出
3 实 验
3.1 实验模型
实验通过异构数据的整合,对房价进行模型训练,并用交叉验证的方法进行评估,这里我们利用梯度提升决策树GBDT。梯度提升决策树是Gradient Boost框架下使用较多的一种模型,在梯度提升决策树中,其基本学习器是分类回归树CART。GBDT采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据的回归,比较适合本实验这种多维数据的处理。具体算法如下:
算法1GBDT
输入:训练集样本D={(x1,y1), (x2,y2), …,(xm,ym)},最大迭代次数T,损失函数L
输出:强学习器f(x)
1) 初始化弱学习器:
(4)
2) 对迭代轮数t=1,2,…,T:
(1) 对样本i=1,2,…,m,计算负梯度;
(2) 利用(xi,Tti)(i=1,2,…,m),拟合一棵CART回归树,得到第t棵回归树,其对应的叶子结点区域为Rtj,j=1,2,…,J。其中J为回归树t的叶子结点的个数;
(3) 对叶子区域j=1,2,…,J,计算最佳拟合值:
(5)
(4) 更新强学习器:
(6)
(3) 得到强学习器f(x):
(7)
3.2 性能评价指标
本实验为房价模型的回归分析,对于回归模型的效果选择相关系数R2作为实验的评价指标,R2可以度量样本是否能够通过模型被很好地拟合。R2越大表示被解释变量中的信息由解释变量解释的比例就越大,反之相反。具体指标如下:
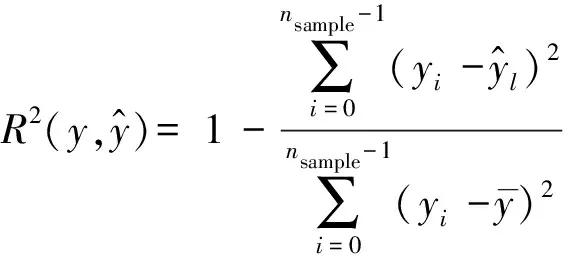
(8)
同时,通过1-MAPE来表征准确率,用来衡量模型预测结果的好坏,具体如下:
(9)
3.3 数 据
本实验的数据包括北京POI数据(来自http://map.baidu.com/)、北京住房信息数据(来自http://www1.fang.com/)、2014年6月份出租车轨迹数据(考虑个别月份因节假日会出现实际场景下的异常情况,以6月为例可以最大程度地避免异常数据对准确率的影响)、北京地铁站线数据,具体内容如表3所示。
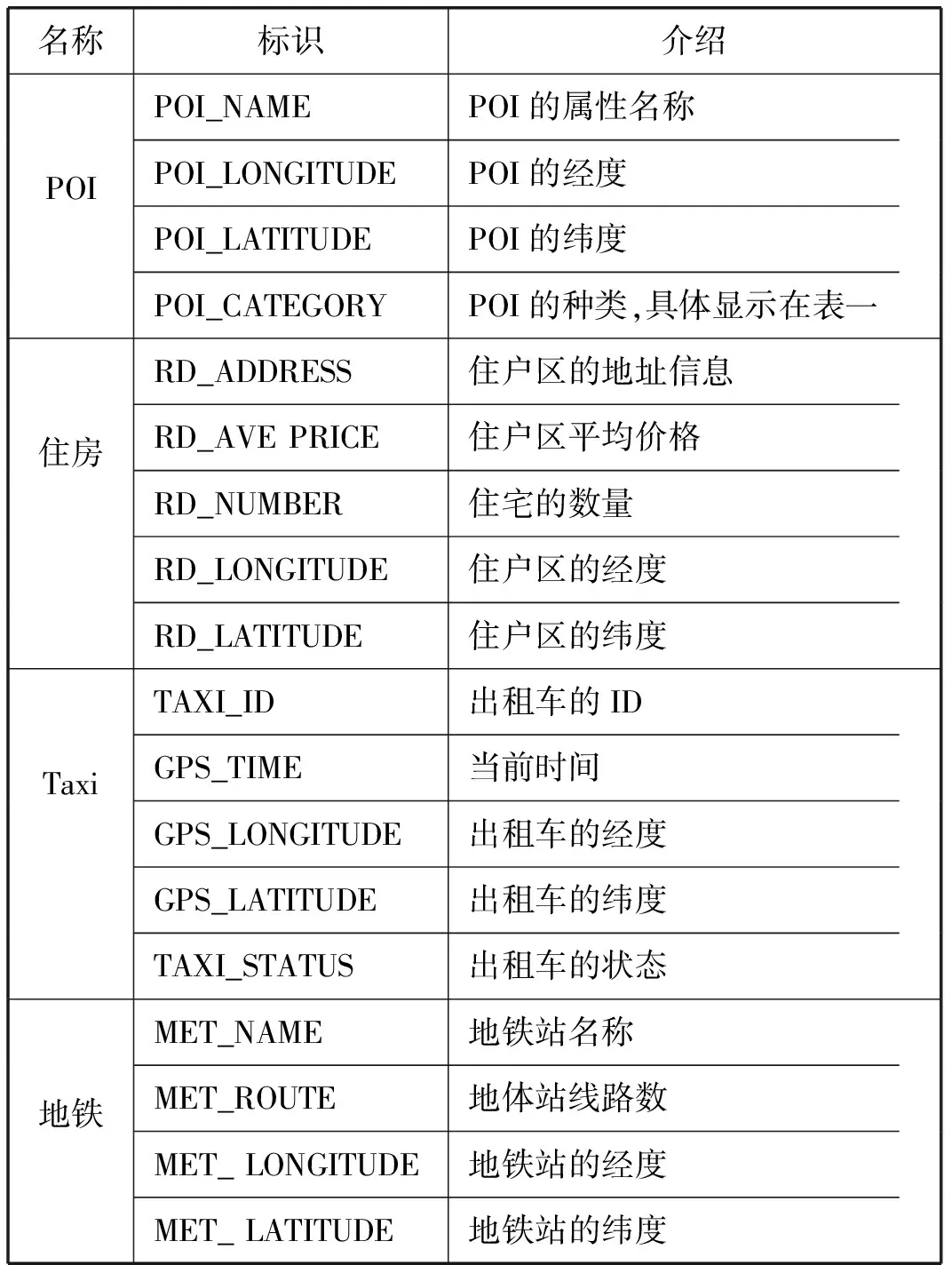
表3 数据情况
3.4 实例研究
本实验选择北京市居民住房作为研究对象,原因在于像北京这种大城市的住房价格一直是社会关注的重点,并且作为国际化大城市其拥有足够的社会情境要素,能够更方便地挖掘出社会情境要素对于房价的影响,同时北京市的房屋数量巨大,可用于训练和验证的数据比较丰富,更适合作为实验对象。
实验设置了五迭验证(5-fold CV)。具体为将数据分成五份,其中四份作为训练数据,一份作为验证;以10作为步长在[0,1 000]的范围内进行网格搜索,选择最好的迭代次数;并以均方差作为损失函数对GBDT模型进行训练,实验结果的拟合程度R2达到92%。
基于学习模型的特征排序,可以在训练的模型中找到影响因变量变化的重要特征,特征和响应变量之间的关系是非线性的,因此我们利用基于树的方法进行特征排序。根据GBDT的特征排序,我们提取了影响房价变化的最重要的七种因素,分别为:住宅数量,出租车下车数量、公共设施、学校、购物服务、地铁线路、生活服务。
根据实验结果,我们可以得知区域的平均房价确实会受到其周边社会情境要素的影响,并且关联程度很高。当然,能够实现关联关系相对应的前提是房价不会受到较大冲击,譬如政策性调整或者经济形势变化等。本文用GBDT模型进行训练取得较好的效果也表明对于这种复杂规模的数据,集合弱分类器来缩小误差是有成效的。另一方面,通过GBDT模型的特征排序,我们也可以得知对于区域房价起重要影响的因素是哪些,这样从客观的角度给房价的估值提供了新的理由;而在事实层面上,以上挖掘出来的社会情境要素也具有可解释性。
3.5 与基准算法的比较
根据数据维度高,信息量大的情况,本实验选择了四种能够良好应对多维回归拟合的机器学习算法,具体为支持向量回归(SVR)、多元线性回归、AdaBoost回归、贝叶斯岭回归,具体指标如图2、图3所示。

图2 准确率
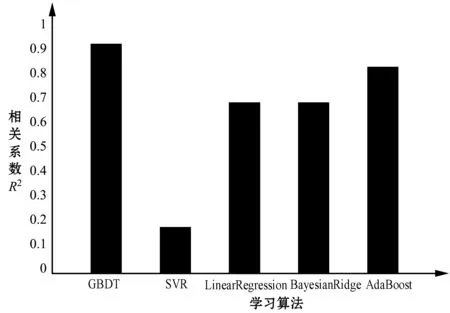
图3 相关系数R2
(1) 准确率方面 在准确率上几种经典的回归模型都有较好的表现,其中多元线性回归、AdaBoost回归、贝叶斯岭回归的准确率都达到80%以上,而支持向量回归的表现差强人意,这里GBDT的效果最为优秀,达到94.6%的准确率。
(2) 相关性方面 相关系数代表模型在拟合数据时的相关程度,也是判断模型训练效果的重要指标。实验结果表明多元线性回归与贝叶斯岭回归的相关系数维持在60%~70%之间,而AdaBoost回归的相关系数在75%左右。支持向量回归的表现仍然不好,其变量的拟合效果不佳。而GBDT的相关系数达到92%,证明其模型的拟合程度较强,模型的泛化能力突出。
根据对比分析,我们发现无论是通过最小二乘法最小化误差平方和寻找最佳函数的多元线性回归,或是带二范式惩罚参数的贝叶斯岭回归,结果都不太理想。而同样作为boosting方法(通过给样本设置不同的权值,每轮迭代调整权值机型训练),GBDT与AdaBoost表现也有差异,具体来说Adaboost通过增加被错误分类的样本的权值,分类器依赖于错误率;GBDT也是迭代,但其使用了前向分布算法,并且弱学习器限定了只能使用CART回归树模型,在迭代思路GBDT也和Adaboost有所不同,这都对结果产生影响。
4 系统实现
4.1 实验工程化
对于区域平均房价这种与人民生活息息相关的话题,需要我们在实践中进行探索和检验。之前的很多对于房价的研究都基于过去的知识、经验、背景挖掘规律,真正体现在当下的反馈凸显不足。而目前很多研究都开始加入人机交互的工作,有的是实现数据的调研,有的是利用大家的计算能力统筹处理一个任务。例如文献[17]提出利用人机交互实现对腰痛的研究。为了利用实验的结果给现实中用户提供服务,本文设计了一个人机交互界面,用户通过界面使用模型,得到他们关注的房产周围的有价值信息,在实际情况中使用本实验所挖掘的规律,进行真实场景的预测。
4.2 人机交互
具体人机交互的实现方式如下:用户在经纬度输入框输入其需要预测或分析房价的地点坐标,或者在地图上通过单击鼠标选择其预测位置经纬度,如图4所示。系统会根据用户选择的地区,将经纬度发送给后台预测模型。通过已经训练好的模型,计算该区域存在的客观社会情境要素,并返回经纬度对应点所属相关区域内的预测房价,同时将一些当地重要信息反馈给用户,实现区域平均房价的预测和重点信息的采集工作。

图4 人机交互界面
5 结 语
本文探讨了区域平均房价与周围社会情境之间的关系,统计了二十余种与房价相关的社会情境要素,利用机器学习中的GBDT进行预测,最终模型的拟合程度达到92%左右。这说明了一个区域的平均房价确实受到该区域的社会情境信息的影响,这种复杂的影响关系可以为房屋建设、投资、买卖的人提供参考。并且本文也基于学习模型的特征排序,通过GBDT模型选择影响房价变化的客观因素中重要的因素,我们发现了像北京这种国际化的大都市,其区域房价对住户区包含的住宅数量,住户区周边的出租车人流数量,公共设施、学校、购物服务、地铁线路、生活服务等因素比较敏感,这些因素也是影响北京区域房价的一些关键因素。
在本研究中,我们探索了北京房价的变化原因,但在不同城市、相同城市的不同历史阶段,没有通用的模型能处理所有房价变化的情况。本文所用的GBDT算法在数据集上准确率高,但对于不同类型的城市,社会情境中的每个变量如何影响着区域房价的变化可能遵循不同的规律。因此,有必要为每个特定的城市类型训练对应的预测模型。本研究是把非结构化数据应用到区域房价研究的一次尝试,未来会融合更多方面的数据、提出更加通用的算法完成进一步研究。
