基于笔划三维深度特征的签名识别
2019-11-11吴坤帅魏仲慧李佩君
吴坤帅,魏仲慧,何 昕,李佩君
(1. 中国科学院 长春光学精密机械与物理研究所,吉林 长春 130033;2. 中国科学院大学, 北京 100049;3. 中国人民解放军63850部队,吉林 白城 137000)
1 引 言
签名是一项方便快速的个人身份认证方式,具有使用简单方便和签名特征稳定可区分等优点,应用范围广泛。由于个人签名容易被刻意伪造,因此签名笔迹检测科学也随之诞生,而计算机技术的高速发展,笔迹识别科学逐步进入与计算机技术紧密结合的新时代。使用计算机进行签名识别有着速度快和数据量大的优点,适合于对大量签名进行初步的筛选,给出一份或者数份待选的正确结果,节省人力和物力。签名识别技术一般包括图像预处理,特征提取,特征分类3个组成部分。近年来,国内外的学者进行了大量理论研究和实际探索,提出了许多巧妙的识别方法,并取得了一定的成果。
Ferrer等在不同背景污染的情况下,提取签名图像的局部二值模式(Local Binary Pattern, LBP)特征用于识别[1]。Ferrer等的样本大多是在书写在发票及支票等常用书写载体上,污染多为下划线和水印等常见污染,此研究与现实应用场景相近,有很高的应用价值,但对熟练仿写的签名鉴别效果有限。Okawa使用视觉词袋模型结合KAZE算法和VLAD(Vector of Locally Aggregated Descriptors)来研究签名识别。Okawa结合了计算机视觉领域的两个最新算法到签名识别之中,大大提高了识别的正确率,对伪随机签名数据集的识别率达到最先进的水平。但是其数据集包含了较多随机签名的原因,分辨难度低,应用价值有限[2-3]。Cui等使用AlexNet进行签名识别,总正确率为87.5%。他直接使用神经网络提取并进行分类,避免了人工选择特征,但神经网络需要的签名数据量较大,现实生活中很难满足[4]。Maergner等使用图编辑距离(Graph Edit Distance)度量两个签名的相似度,并使用深度神经网络进行分类,在公共数据集GPDS的随机伪签名集上取得了很高的识别正确率,但在熟练签名集上的效果明显差于随机签名集[5]。祖丽皮亚使用统计特征研究维吾尔签名的识别,统计不同方向上的像素点的数目作为特征特征向量。统计特征提取简单快速,实现方便,提高了识别的速度,但需要大量的训练数据才能达到良好的识别效果[6]。
虽然目前的研究取得了一定的成果,但依然存在一些问题:尽管使用了不同的数据集、特征、分类器以及正确率评判的标准,国内外大多数的签名识别方案的识别成功率在85%~95%之间(错误率在5%~15%)[7-12],使用熟练签名集的正确率要明显低于使用伪随机签名集的正确率,要达到较高的识别正确率则需要大量的训练数据。而在现实生活中,需要我们识别的大多是熟练仿写的签名,许多情况下我们能获取的签名数据也是有限的。
在计算机签名识别中,签名识别的成功率不会无限地提升,它存在一个上限。计算机通过计算待识别样本和真实签名的特征相似程度,给出真伪判断,而精心模仿的签名与真实签名的相似度甚至可能要高于两个真实签名之间的相似度。因此,只要研究真实签名的书写规律,仿写人就能够写出尽可能与真实签名相似的签名。这也是熟练伪造数据集识别成功率低的原因。二维特征签名识别都忽略了笔迹的三维信息,而这些信息是仿写人难以模仿的。
国内外的研究人员对笔划的三维深度特征进行过一定的研究,但目前还处于起步阶段,大多还未使用深度特征直接进行签名识别。Furukawa[13-14]采集了大量横竖撇捺笔划,发现同一书写者笔划深度之间的差异明显小于不同书写者之间的差异,这为深度特征在签名识别上的应用提供了理论支持,但他还没有使用完整的签名进行研究。申思[15]等研究了套摹签名与原始签名行笔过程中压痕曲线变化,发现原始签名在行笔过程中的极值点位置(反映了行笔笔力的变化)具有一定的稳定性,而同一套摹人的套摹签名之间的极值点位置变化较大。申思的研究证明,摹写签名之间的深度特征变化大于原始签名,这是由个人书写习惯所决定的。目前的研究已经证明笔划三维深度特征中蕴含了书写者的个人特征,具有进行签名识别的理论基础。
本文旨在研究签名笔划三维深度特征,对获取的签名笔划进行扫描和去噪处理,提取笔划的深度信息,在熟练仿写签名数据集上进行分类,证明三维深度特征在签名识别上的有效性。
2 基于笔划深度特征的签名识别
熟练伪造签名与真实签名的二维特征可以非常相似,而三维特征却难以进行模仿。中文汉字中,笔划横、竖、撇、捺的出现频率很高,在书写这4个笔划的过程中,起笔、行笔以及收笔的力度大致是稳定的,是由人的书写习惯影响的,包含了个人的生物学特征。在其他书写条件不变的情况下,书写力度短期内不会发生较大的改变,因此可以用来识别书写者的身份。书写时的力度信息属于动态特征,在离线签名识别中,无法获取书写者写下签名时的力度信息,但是可以用深度信息来代替力度信息。图1为签名识别系统原理图,它由显微镜扫描系统、签名预处理、特征提取以及分类器4个主要模块组成。
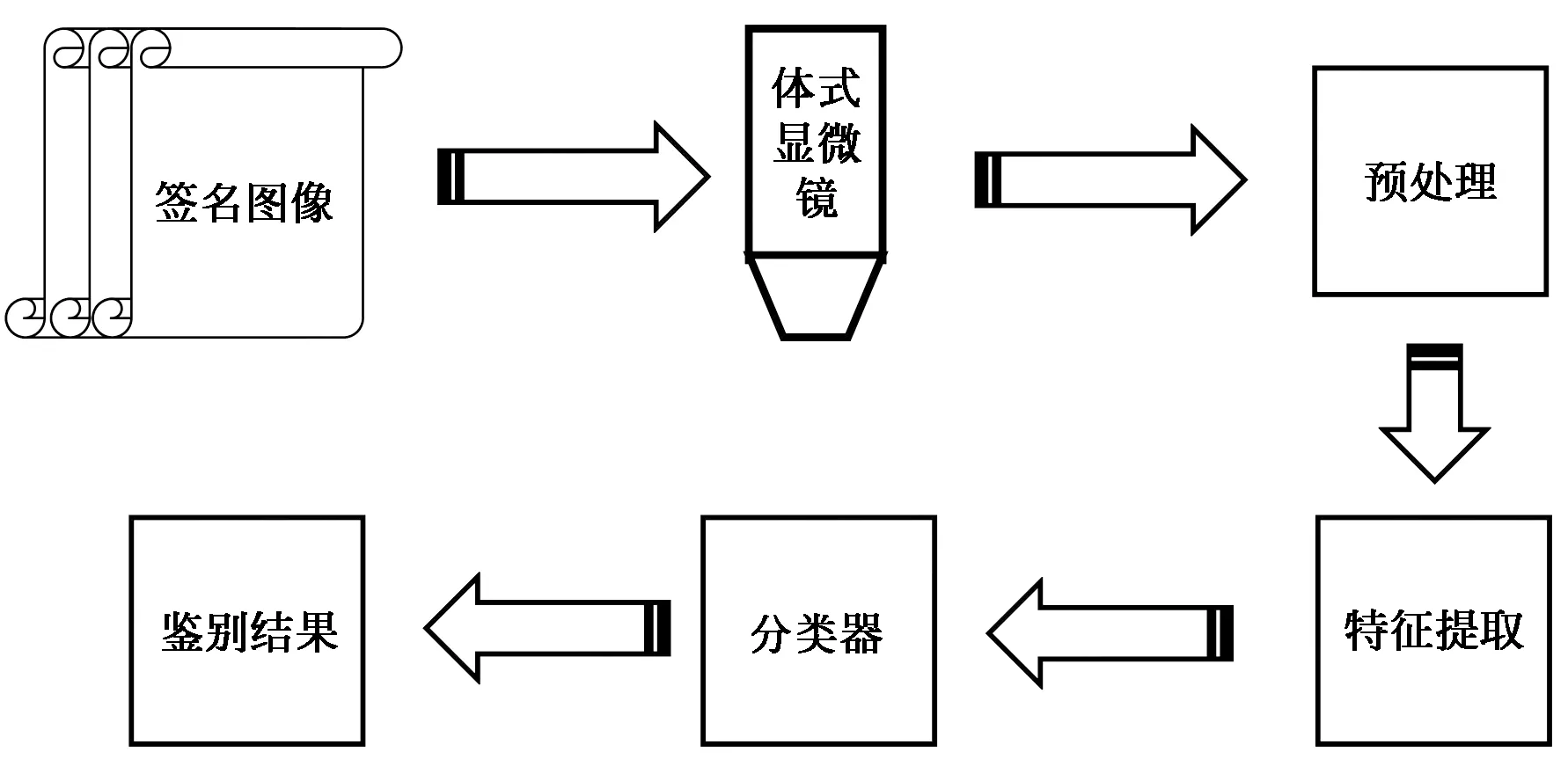
图1 签名识别系统原理图Fig.1 Block diagram of signature recognition system
2.1 签名的获取与预处理
(1)签名笔划的采集。签名笔划的深度信息需要专业的扫描设备,这里使用高精度的体式显微镜采集签名笔划的表面形态。显微镜的Z轴精度为0.1 μm,一般情况下,笔划的深度为10~60 μm之间,因此,采集误差在可接受范围之内。采集到的信息以矩阵的形式等间隔存储笔划的表面深度信息,点云相邻点之间的距离均相等,因此只按顺序存储下点的深度信息,不存位置信息,矩阵的长和宽分别为笔划的长和宽,值为该位置点的深度。笔划的深度信息存储方式与灰度图像的存储方式类似,因此可以将深度信息当作图像来处理,作为笔划的深度图像。
(2)噪声去除。采集到的笔划表面形态带有噪声,需要先进行滤波。深度图像中的噪声主要来源于机器运转时的微小振动,属于随机噪声。我们参考图像处理中图像去噪的方法过滤深度图像的随机噪声。高斯滤波是一种线性平滑滤波,对于滤去图像中的高斯或近高斯噪声有着非常好的效果。根据国际标准ISO11562规定,当使用高斯滤波器作为建立表面轮廓基准线的滤波器时,规定的权函数为:
(1)
(2)
其中:λc为截止波长,λ=λc时,滤波器的阻尼系数为0.5。二维的高斯卷积核由水平和垂直方向的卷积和直接卷积而来:
s2D(x,y)=sx(x)⊗sy(y),
(3)
在频域上表现为:
S2D(X,Y)=Sx(X)·Sy(Y).
(4)
深度图像与高斯滤波器进行卷积,得到去除噪声的图像F(X,Y) 。
F(X,Y)=Fo(X,Y)·S2D(X,Y).
(5)
2.2 签名笔划特征提取
进行深度图像采集时发现,除了噪声外,纸面粗糙度也会对特征提取造成一定的影响。常见书写纸一般表面不平整,还带有一定的纸质纤维和杂质。这造成在未书写的情况下,纸面的峰-谷可能会达到几微米,这已经与较轻的笔划造成的深度相近了。通常情况下,这些粗糙点都是凸出纸面的,影响最高点的选取。因此我们在沿笔划横截面上,选择横截面平均值与最低值的差作为该截面的高度,并计算整个笔划的深度,即:
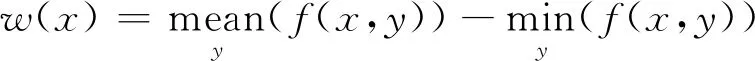
(6)
通过式(6)可得到沿笔划方向的深度矩阵,矩阵的长度为笔划的长度。深度矩阵维数较大,不适合直接用作特征分类,还需要进一步处理,选择深度矩阵的统计特征作为笔划的深度特征。常用的使用统计特性有平均值、标准差和矩阵的熵3种。笔划深度的平均值反映了笔划在行笔过程中的平均力度;沿笔划方向的深度标准差反映了行笔过程中的力度变化;深度矩阵的熵是图像处理和计算机视觉学科中度量图像纹理随性的一个常用特征,用来度量深度矩阵的随机性。深度平均值一致的两个笔划,在行笔上也可能不同,这样他们的熵值就有所区别。当深度矩阵中的数值差异较大时,熵的值就会小,当深度矩阵中所有值一致时,熵值取最大值[16]。以上3个特征分别由以下公式计算:
(7)
(8)
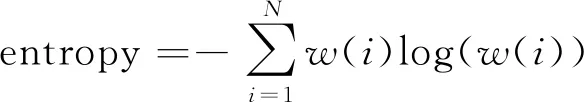
(9)
上式中,N为笔划的采集行数。将一个签名的所有笔划提取的统计特征合在一起,作为签名的完整深度特征。
2.3 签名笔划特征分类
传统签名识别中广泛运用的分类方法有支持向量机(Support Vector Machine,SVM),K-近邻分类(K-Nearest Neighbor, KNN)以及人工神经网络(Artificial Neural Network, ANN)等。由于不同的数据集在不同分类器上的效果各有优劣,因此我们同时使用这3种分类器来进行分类,寻找最适合我们样本的分类器。
2.3.1 SVM
SVM 是一种成熟的特征分类算法。在本实验中,它的目的是寻找一个超平面,将不同书写者签名的深度特征向量,以最大的间隔分类在超平面两侧。距离超平面最近的点称为支持向量。最靠近超平面的数据点与超平面之间的距离越大,分类效果越好。
2.3.2 KNN
K-近邻算法是机器学习中简单有效的分类算法,它计算待测样本特征向量与已知签名库特征向量之间的距离,并选举出K个最相邻的数据,通过统计这些数据的标签,得到样本的归属判断。KNN参数较少,实现方便,适合在样本较少的情况下使用。它的主要流程如下:
(1)计算待分类签名特征向量与签名库签名特征向量之间的距离,并按照递增排序;
(2)选取K个最相邻的数据;
(3) 统计这K个数据的标签出现次数,并得到出现频次最高的数据样本,即为待测样本的预测分类。
2.3.3 ANN
人工神经网络是用来模拟人类大脑中神经元的工作方式的人造模型。1986年,Rumelhar和Hinton等人提出了反向传播(Backpropagation,BP)算法,它的主要特点是特征向量前向传递,而误差反向传播,通过不断修改神经网络权重和偏置,使得网络的最终输出与期望输出尽可能接近,以达到训练的目的。本实验中,只使用神经网络作为分类器,输入神经网络的特征是我们上一步提取到的深度特征。
2.4 评判标准
签名识别中常用的评判标准有错误拒绝率、错误接受率和错误率3种,这里我们使用前两种。并引入总正确率作为两个指标的综合评判标准。
错误拒绝率(False Rejection Rate, FRR),FRR是真实签名当作伪造签名被系统拒绝的概率,即输入识别系统的签名为真实签名,考察系统将签名当作是伪造签名的概率。
(10)
错误接受率(False Acceptance Rate,FAR),是伪签名当作真实签名被系统接受的概率,即输入识别系统的签名为伪造签名,考察系统将签名当作真实签名接受的概率。
(11)
再使用总正确率考察两个指标的综合结果,总正确率以公式(12)求得:
(12)
3 实验结果及分析
3.1 实验数据获取
为了使签名的二维特征尽可能地相似,伪造签名使用套摹的方式得到。仿写人获得真实签名后,经过一定的练习,对真实签名进行摹写。真实签名与伪造签名对比如图2所示。选取签名中的长竖笔划进行三维扫描,获取深度矩阵,真实签名与伪造签名的对比如图所示。我们可以看到,真实签名与伪造签名的二维特征难以用肉眼进行区分,特征很相似,而笔划的深度特征有明显的区别,难以进行模仿。
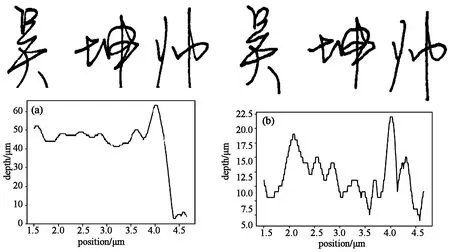
图2 真实签名与套摹签名对比。(a)真实签名与“帅”字长竖笔划的深度走势图;(b)套摹签名与长竖深度走势图。Fig2 Real signature versus forgery signature. (a)Real signature and depth chart of the vertical stroke of character “帅”; (b)Forgery signature and the depth chart of the corresponding stroke.
实验中使用的签名数据是书写人在平和的条件下写下的,排除环境因素对签名深度的影响。采集真实签名与其熟练仿写签名各10个,共计19组,即380个签名。每个签名图像采集5~6个笔划,每个笔划提取3个特征(即平均深度,沿笔划方向深度标准差和深度矩阵的熵),即每个签名提取15~18个特征,真实签名及其仿写签名采集的笔划部位一致。
为了防止过拟合,使用数据增强增加数据集。常用的数据增强方法有:翻转、旋转、平移、缩放、裁剪以及增加噪声。大量的实验表明,数据增强能明显增加识别系统的泛化能力和鲁棒性,减少错误识别率。这里我们使用增加噪声的方法进行数据增强,将数据集扩展到原先的两倍。具体增加数据集的方法为:首先使用随机数生成器产生在[-10,10]之间的随机矩阵,随机矩阵的维数与签名图像的特征维数一致;将随机矩阵乘以一个噪声因子,此处设为0.01,并与原特征矩阵进行点乘产生新的带有噪声的新的人工签名特征。新的人工签名的特征值与原特征值相差在10%以内。
3.2 实验结果及分析
3.2.1 笔划特征对比
如表1所示,是一组真实签名-伪造签名的单一笔划特征的对比,包括该笔划的平均深度(Stroke Mean)、沿笔划方向深度标准差(Stroke Std.)和熵(Stroke Entropy)3项。表中显示的了10个真实签名(或伪造签名)之间的均值和标准差。可以看到,对于笔划1,签名人和其仿写者之间,真实签名和伪造签名的3项特征的平均值有一定的差别,伪造签名的平均深度大于真实签名,且真实签名的3项特征的标准差均小于伪造签名,说明真实签名的深度更加稳定,行笔过程力度稳定性好。而仿写人由于刻意模仿笔划的轨迹,行笔力度变化较大,因此签名间的力度变化较大,深度差异大。笔划2,是由另一个签名人的签名中的某一笔划及其仿写笔划的特征。可以看到,签名人的笔划深度小于仿写人,且其特征的标准差也比较大,说明签名人签名力度较大,且力度变化范围大,而仿写人仿写时下笔较轻且沉稳。这两个笔划特征的对比中可以看出,签名笔划深度的特征值大小和稳定度并不绝对与笔划是正常情况下书写或刻意仿写相关,而是签名人和仿写人的习惯相关。这与现实情况相吻合,不同人在签名或者是仿写时,下笔的力度都会下意识遵循自己的习惯,因而与他人有所区别。
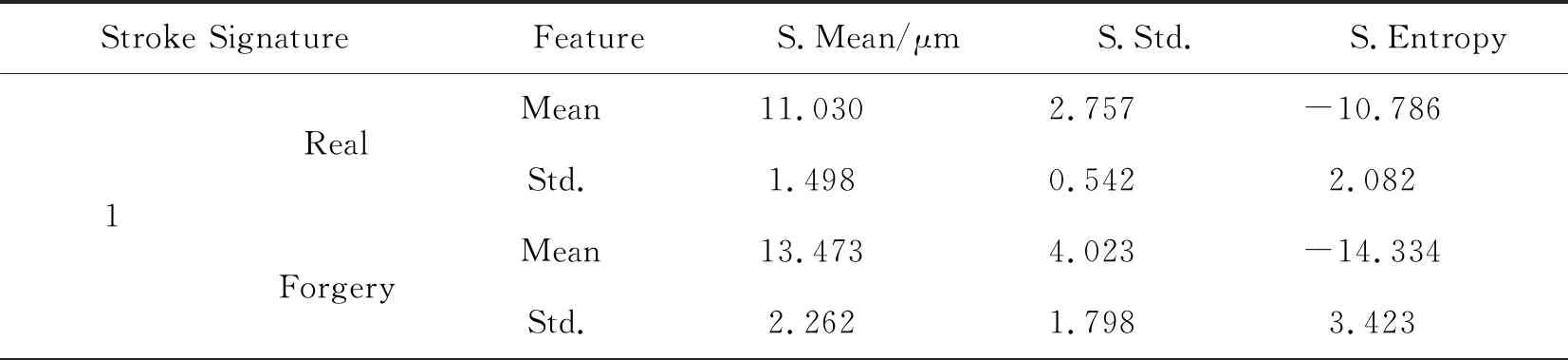
表1 真实签名与伪造签名笔划特征对比Tab.1 Contrast on stroke features of real and forgery signature
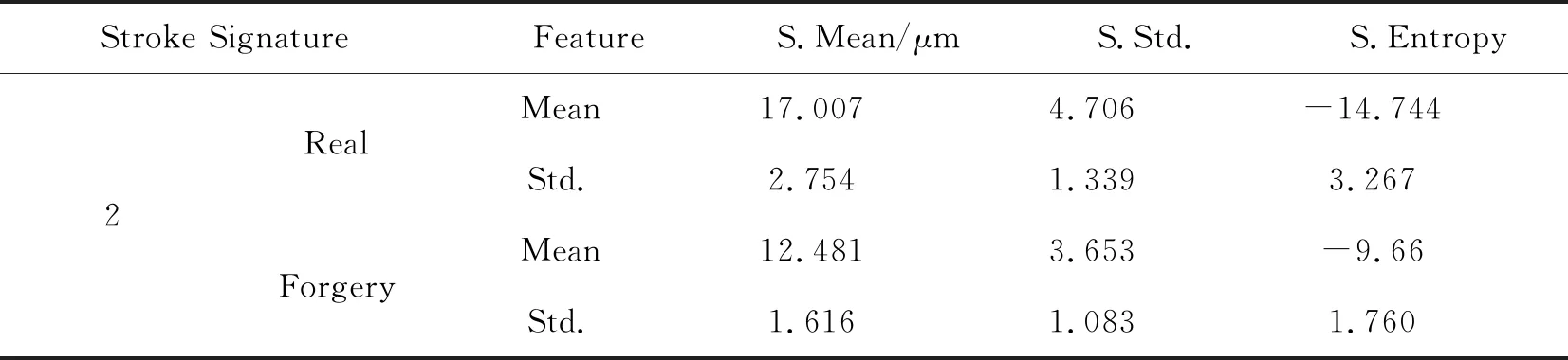
续 表
3.2.2 熟练签名集分类
在原始熟练签名数据集上进行实验,将数据集随机分为训练集和测试集,训练集占总体实验数据的比例(Training Rate, T_R)为0.5。提取到的特征分别使用支持向量机、K-近邻分类器以及神经网络进行分类。实验结果如表2所示。从表2中可以得到,SVM、KNN以及ANN3个分类器的识别正确率分别为91.686%、97.393%以及95.209%。3个结果均高于90%,其中KNN分类器的结果达到了97.393%,高于传统二维签名识别85%~95%的正确率。这说明了笔划的深度特征对于熟练签名的识别具有优秀的效果。
表2 不同训练比例和分类器下的签名分类结果
Tab.2 Recognition rates of signature with different classifier and training rate
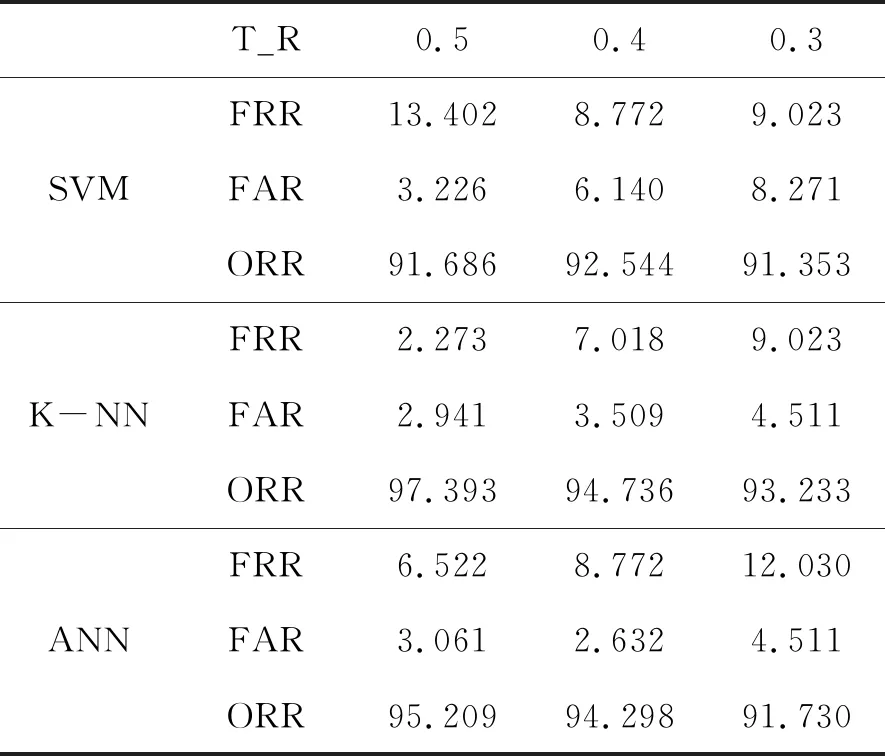
T_R0.50.40.3SVMFRR13.4028.7729.023FAR3.2266.1408.271ORR91.68692.54491.353K-NNFRR2.2737.0189.023FAR2.9413.5094.511ORR97.39394.73693.233ANNFRR6.5228.77212.030FAR3.0612.6324.511ORR95.20994.29891.730
在现实的应用中,进行签名识别时,我们能获得签名样本一般都是有限的,需要保证在较少的训练样本下也有不错识别效果。降低训练比例至0.4和0.3并进行重复试验,从表2中可以看到,减少样本训练数据量情况下,3个分类器的识别正确率依然保持在90%以上,可以认为识别系统在较少的训练数据下依然能保持较高的识别正确率。此外,训练数据的量较少,也导致了SVM和ANN这类参数较多的分类器无法充分排除所有误差,而KNN的参数较少,受到的影响相对小一些,因而,KNN的识别正确率要高于另外两个分类器。
3.2.3 数据增强后的实验结果
表3是原始签名数据集进行数据增强后的实验结果。表3显示,数据增强可以有效提高系统的签名识别正确率,SVM、KNN和ANN三分分类方式的最高分类结果分别为: 96.108%、98.690%和97.378%。3项正确率分别相对于未进行数据增强前上升了3.564%、1.297%和2.169%。数据增强后分类正确率的增加,是因为数据集增加的同时,训练数据也增加了。由于一般手写签名数据集的个数有限,数据增强是一个简单有效的增加实验数据,提升分类正确率的方法。
同时对比表2和表3可以发现,随着训练集比例的增加,分类总体正确率有上升的趋势,这也说明了训练集越大,训练越充分,分类结果越高。
表3 数据增强后签名分类结果
Tab.3 Recognition rates of signature after data augmentation
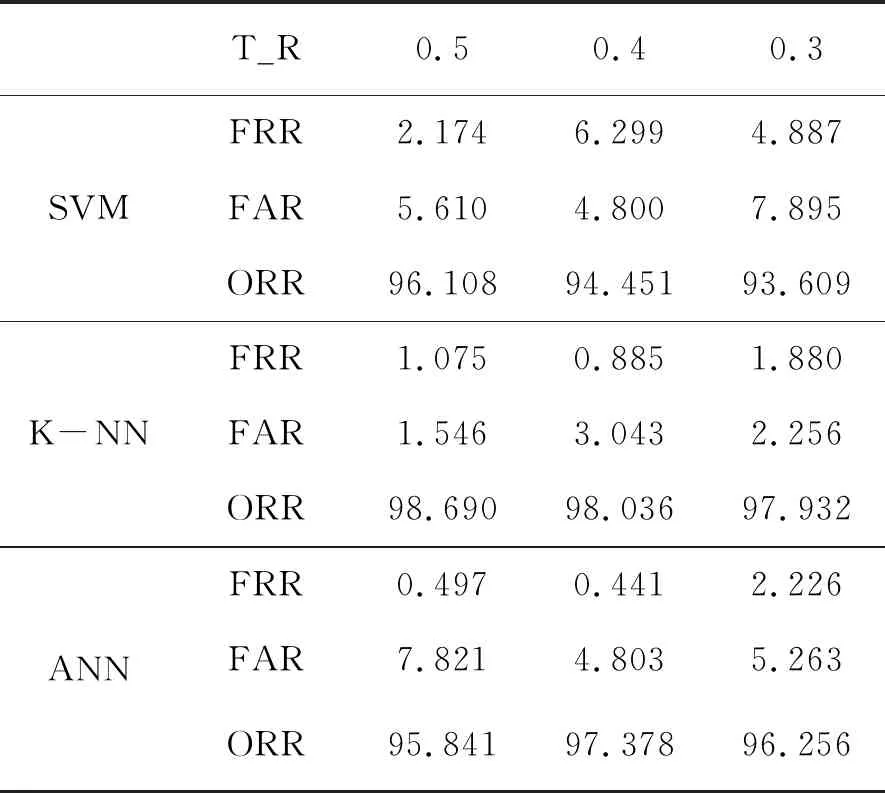
T_R0.50.40.3SVMFRR2.1746.2994.887FAR5.6104.8007.895ORR96.10894.45193.609K-NNFRR1.0750.8851.880FAR1.5463.0432.256ORR98.69098.03697.932ANNFRR0.4970.4412.226FAR7.8214.8035.263ORR95.84197.37896.256
3.2.4 与其他算法的对比
表4是本文算法与其他常用的签名识别算法对比结果。从表中可以看出,本文提出的算法的FRR和FAR均比较小,性能优于大多数的传统算法,只略差于文献[3]中的算法,表明了本文算法在签名识别方面具有优秀的性能。
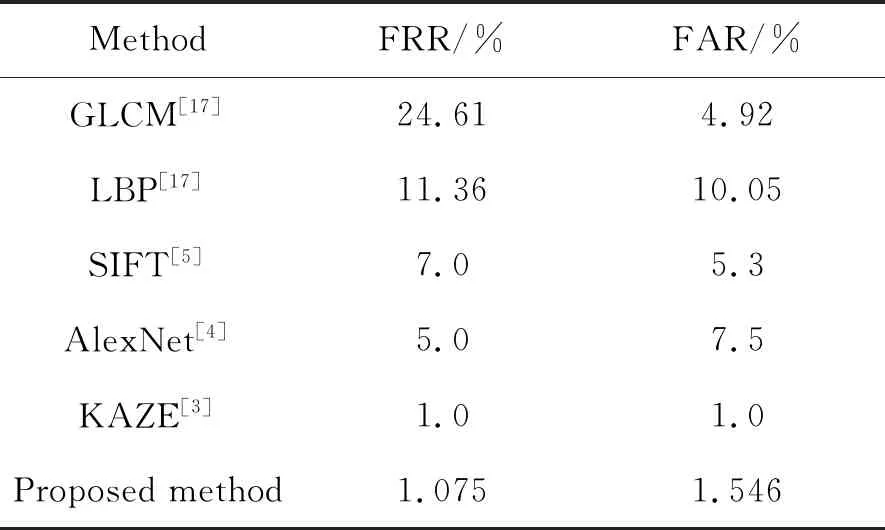
表4 不同算法的分类结果对比Tab.2 Performance comparison on different algorithm
4 结 论
本文针对熟练伪造签名识别正确率低的现状,提出了基于笔划三维深度特征的签名识别方法,并收集了真实签名和熟练伪造签名数据集,伪造签名通过套摹方式获得,使用数据增强扩充了数据集。签名特征使用了笔划深度的平均值、沿笔划方向标准差和深度的熵3个统计量。实验结果表明,笔划三维深度特征能有效识别熟练伪造签名,在KNN分类器上,签名识别正确率最高达到了98.69%,FRR、FAR优于大多数传统算法,具有优秀的识别性能。
