多元特征融合的GRU神经网络文本情感分类模型
2019-11-09王根生黄学坚
王根生,黄学坚,闵 潞
1(江西财经大学 计算机实践教学中心,南昌 330013) 2(江西财经大学 国际经贸学院,南昌 330013) 3(江西财经大学 人文学院,南昌 330013)E-mail:wgs74@126.com
1 引 言
随着互联网平台的快速发展和普及,越来越多网民通过网上发表自己的观点和评论.如何快速准确的对这些信息进行情感分类是网络舆情监控的一个重要环节[1,2].目前文本情感分类主要分为基于语义理解的算法、基于人工特征工程的机器学习算法、基于深度学习的算法和混合型算法[3].
基于语义理解的文本情感分类算法通过情感词典和情感句式模板对文本进行情感判断[4].如Recchia通过点互信息(point mutual information,PMI)度量词语和情感词典中褒贬词的相似度,并通过这个相似度来计算词语的情感度,再通过对文本所有词语的情感度进行累加判断文本情感[5];Bin通过HowNet语义字典计算词语情感度,并对副词、连词和句子结构进行分析,构建文本情感分类算法[6];Agarwal针对情感表达的多词特征,使用非结构化的文本情感词进行情感表示,并通过语义取向的方法对多词特征进行覆盖,从而实现更精准的文本情感分类[7];王日宏通过加入情感义原从新定义情感相似度的计算,侧重情感词、否定词、副词的组合分析,提出否定词和程度词综合处理模块,并结合连词为划分标准的语句情感倾向分类[8];史伟通过情感空间模型,将在线评论情感细分为情绪表达和特征评价两方面,构建句子到文档层的情感计算方法[9];冯时提出一种基于句法依存分析技术的算法(sentiment orientation analysis based on syntactic dependency,SOAD)对博文搜索结果进行情感倾向性分析[10].
基于人工特征工程的机器学习算法通过对已标注情感类别的训练样本进行人工特征选取,再使用机器学习算法进行训练,得出分类模型[11].这类机器学习算法主要有朴素贝叶斯(naïve bayesian,NB)、K-近邻(k-nearest neighbor,KNN)、支持向量机(support vector machine,SVM)等[12].如Nivet通过贪心法进行情感特征搜索,再使用多项式朴素贝叶斯算法进行训练,得出情感分类模型[13];Kalaivani使用信息增益(information gain,IG)进行特征选择,再通过KNN算法对文本的情感类别进行判断[14];Yang提出一种基于改进一对一(one vs one,OVO)策略和SVM组合的多类别情感分类算法,使用多个SVM分类器构成置信度得分矩阵,使用改进的OVO策略确定文本的情感类别[15];冀俊忠通过特征选择对情感词典中的词赋予不同权重,分析词语情感极性和文档情感的相关性,将情感词语义权重特征融合到朴素贝叶斯算法中,实现文本情感分类[16];唐晓波通过计算情感词的数量和情感度大小,提出贬义量和褒义量的概念,作为K-近邻算法的特征向量,进行文本情感分类[17];肖正利用潜在语义分析(latent semantic analysis,LSA)方法建立“词-文档”的语义距离向量空间模型,然后使用SVM算法进行情感分类[18].
基于深度学习的算法是目前比较流行的文本情感分类算法[19],主要分为两个部分,一部分是通过神经网络语言模型学习低维词嵌入(word embedding)向量,第二部分是通过深度神经网络对词嵌入数据进行建模,实现文本情感特征深层学习.如Xiao通过多层RBM(Restricted Boltzmann Machine)构建DNN(Deep Neural Network)网络结构,以获得更好的高层特征表示,实现微博的情感分类[20];Tao提出一种分而治之的方法,首先通过循环神经网络模型把句子分成不同类型,然后利用一维卷积神经网络对每种类型的句子做情感分类[21];Minlie通过标签学习函数得到词语的词性标签,把这些词性标签编码到神经网络中增强句子和短语的表达,并通过正面(POS)标签控制树形LSTM网络的门,得到情感分类模型[22];张海涛通过Word2vec训练得到词嵌入向量,再使用卷积神经网络(convolution neural network,CNN)对微博情感特征进行局部到全局的学习,得到情感分类模型[23];罗帆使用循环神经网络(recurrent neural networks,RNN)对词语和句子序列建模,通过卷积神经网络识别跨语句的情感信息,构成多层H-RNN-CNN网络的文本情感分类模型[24];孙晓提出一种基于多维扩展特征与深度学习的微博短文本情感分析模型,针对微博短文的特征稀疏,引入社交关系网络进行特征扩展,通过叠加多层玻尔兹曼机(RBM)构建深度信念网络(DBN),实现情感分类[25];
混合型算法主要有基于语义理解获得文本情感特征,再结合机器学习算法或者深度学习算法进行情感分类;通过深度学习获得低维词嵌入向量再结合机器学习算法进行情感分类;通过构建多分类器进行分类.如Zhang利用Word2evc进行词嵌入的学习,然后采用主成分分析方法(principal component analysis,PCA)对高维度向量进行降低维度处理,形成特征向量,最后利用SVMperf对评论文本进行训练和分类[26];Catal基于朴素贝叶斯和支持向量机构建多情感分类器系统(MCS),利用投票的形式决定最终文本的情感类别[27];Wu通过融合情感词典和词语间的特定领域关系,构建多源领域的情感分类模型[28];徐健锋在使用信息增益对高维样本降维的基础上,将语义理解和机器学习相融合,设计一种混合语义理解的机器学习中文情感分类算法[29];王汝娇结合Tiwtter自身语言特征、情感字典资源设计原料特征和词典特征,利用卷积神经网络实现情感极性判断[30];朱军提出一种词嵌入+支持向量机+情感词典+朴素贝叶斯的集成学习情感分类模型[31].
通过研究分析发现,基于语义理解的文本情感分类算法相对简单,对复杂多变的文本情感模型不易发现,很难建立完善的情感词典和句式搭配模板,导致算法具有很强的局限性;基于人工特征工程的机器学习文本情感分类算法的效果很大程度上取决于人工特征工程,传统人工特征工程存在语义丢失、矩阵稀疏、维度爆炸等问题,且该类算法是基于浅层的分类模型,对深层次的特征难以捕获,所以算法的泛化能力不强;基于深度学习的文本情感分类算法通过神经网络语言模型可以实现更好的文本表示,可以捕获文本的深层特征,所以相比较前两种算法能获得更好的分类效果.但大部分深度学习算法追求数据驱动,忽略了自然语言中关于情感、权重的先验知识,导致算法需要大量的训练样本才能获得较好的效果.基于以上分析,本文提出基于词嵌入特征、词情感特征、词权重特征三者融合的门控循环单元(Gated Recurrent Unit,GRU)神经网络文本情感分类模型(TMMG).
2 研究基础
2.1 词嵌入和Word2evc
为了让计算机能够处理文本,需要把词语进行数字化表示.最常见的思路是把词语转化成一个向量,如one-hot编码,但one-hot编码向量维度高、矩阵稀疏、语义缺失[32].针对这些问题,Bengio提出一种神经概率语言模型[33],把词语映射到一个低维的向量空间,词向量间的距离可以反映词语的语义关系.Word2evc[34]是目前实现词嵌入的主流框架.
Word2vec利用神经网络从大规模文本库中学习词嵌入向量,其包括Skip-Gram和CBOW两种算法模型.Skip-Gram算法通过输入词wt来预测其上下文Swt=(wt-k,…,wt-1,wt+1,…,wt+k),其中k为wt上下文窗口大小.CBOW模型则是根据上下文Swt去预测wt.Skip-Gram和CBOW训练目标优化函数分别如公式(1)和公式(2)所示:
(1)
(2)
其中C为文本库中所有的词语.Word2vec训练得到的模型是为了得到训练后神经网络中隐藏层的参数矩阵,这些隐藏层参数是Word2vec学习的词嵌入向量.
2.2 门控循环单元(GRU)神经网络
门控循环单元(GRU)神经网络[35]是长短期记忆(LSTM)神经网络[36]的变体.LSTM克服了循环神经网络(RNN)[37]在处理远距离依赖时的梯度消失或梯度爆炸问题,可以很好的保持时序数据中长短距离的依赖关系.GRU在保持了LSTM优势的同时网络结构也更简单,相比于LSTM输入门(input gate)、输出门(output gate)、遗忘门(forget gate)的三门结构,GRU只有更新门(update gate)和重置门(reset gate),GRU单元网络结构如图1所示.

图1 GRU单元结构Fig.1 GRU structure
GRU网络向前传播计算如公式(3)至公式(7)所示:
rt=σ(Wr·[ht-1,xt])
(3)
zt=σ(Wz·[ht-1,xt])
(4)
(5)
(6)
yt=σ(Wo·ht)
(7)

3 模型构建
3.1 构建多元特征融合向量文本表示算法
基于深度学习的文本情感分类算法,一般直接把基于词嵌入向量的文本表示作为神经网络的输入,这种方式免去人工特征工程的繁琐,减少了人为的干预,实现了端到端的自动化,但该类算法忽略了人们对文本情感的先验认识,如词语的词性、情感色彩、权重等先验知识,导致算法需要大量的训练数据.所以本文在已有的词嵌入向量特征基础上,融入词语情感特性和权重特征,形成多元特征融合的文本表示——多元特征融合向量文本表示算法,该算法模型如图2所示.
3.1.1 词嵌入向量特征
为了获得文本预处理后的词嵌入向量,需要建立词嵌入向量库,通过Word2vec框架构建词嵌入向量库是目前主流方式,并且已经有相关研究团队公布了开源词嵌入向量库,如北京师范大学和人民大学的自然语义处理研究小组研发的基于全网超大规模文本开源词嵌入向量库CWV[38].这种开源库覆盖范围广,向量间距离反应的语义关系符合全局环境,向量维度也较固定.由于本文研究的文本对象是具有感情色彩的电影评论,具有情感特征和行业特征,不具有全局性和普遍性,所以本文提出基于Word2vec独立训练词嵌入向量库:训练时,神经网络隐藏层神经元个数设为100-300之间,隐藏层神经元的个数即为词嵌入向量的维数;得到词嵌入向量库后,对文本d进行分词和去停用词处理,得到文本的词序列W=[w1,…,wn],n为文本中词语的总个数;根据Word2vec训练得到的词嵌入向量库把词序列W替换成词嵌入向量矩阵,V(W)=[Vw1,…,Vwn],其中,Vwi为词wi的词嵌入向量,其表示如公式(8)所示:
Vwi=[v1,v2,…,vk]
(8)
其中k为词嵌入向量的维度.

图2 多元特征融合向量文本表示算法Fig.2 Multi feature fusion vector text representation algorithm
3.1.2 情感向量特征
①构建情感要素字典
根据自然语言文本情感表达特点,建立情感要素字典,该字典包括六种情感要素:正面情感词、负面情感词、程度词、主张词、否定词、转折词.六种情感要素说明如下:
a)正面和负面情感词是体现文本情感的主要因素;
b)程度词增强或减弱情感词的情感度;
c)主张词后面表达的情感很大程度上决定了整个文本的情感色彩;
d)否定词反转情感词的情感倾向;
e)转折词连接前后相反的两个情感表达.
本文结合最新的知网情感分析词语集(HowNet),构建了常见情感要素字典,如表1所示.
②情感向量特征表示
情感特征向量根据六种情感要素,建立六维特征表示,如公式(9)所示:
E(wi)=[e1,e2,e3,e4,e5,e6]
(9)
E(wi)为词语wi的情感特性向量,向量六个维度从左到右分别对应正面情感词、负面情感词、程度词、主张词、否定词、转折词.把词语wi和情感要素字典一一匹配,匹配规则如下:
a)主张词、否定词、转折词不存在度量,如果匹配成功时把对应的情感特征向量位置设为1,不匹配则设为0;
b)程度词级别分为极其、很、较、稍、欠5个级别,分别用1、2、3、4、5表示,和某个级别的程度词匹配时填入对应级别;
c)情感词使用情感度进行表示,本文提出使用情感词嵌入向量和所有情感种子词嵌入向量的平均余弦相似度来衡量,情感种子为情感表达明显的词,具体计算如公式(10)所示:
(10)

表1 情感要素字典Table 1 Emotion factor dictionary
Dwi为情感词wi的情感度,m为情感种子词数量,本文从正负情感词中各挑选100情感种子词,Vwn和Vwi分别代表情感种子词wn和情感词wi的词嵌入向量,符号(·)代表两个向量的点乘,‖Vwn‖*‖Vwi‖代表两个向量的模长相乘.
3.1.3 权重特征
本文使用TF-IDF算法计算词语权重,TF-IDF由词频(term frequency,TF)和逆向文档频率(inverse document frequency,IDF)组合而成,TF的计算如公式(11)所示:
(11)
tfi,j代表词语wi在文档dj中的词频,ni,j为wi在文档dj中出现的次数,k为文档dj中不同词语的个数,分母为文档dj中所有词语出现次数总和.IDF计算如公式(12)所示:
(12)
idfi代表词语wi在文本库d中的逆向文档频率,nd为文本库d中文档的总个数,df(d,wi)为文档库d中包含词语wi的文档个数,加1是为了防止df(d,wi)为零的情况.最后TF-IDF归一化后的计算如公式(13)所示:
(13)
通过公式可以看出,词语Wi的权重和它在文档dj中出现的频率成正比,和在整个文本库d中包含词语Wi的文档数成反比.
3.1.4 多元特征融合向量文本特征表示算法
在图2多元特征融合向量文本特征表示算法模型中,首先按照公式(8)计算词嵌入向量特征,按照公式(9)计算情感向量特征,按照公式(13)计算权重特征;然后把情感向量和词嵌入向量进行拼接,组成一个新的向量,新向量的前半段为情感向量,后半段为词嵌入向量;最后把权重和拼接向量相乘,形成多元特征融合的文本特征表示,计算如公式(14)所示:
M(wi)=tf_idf*[E(wi),Vwi]
(14)
3.2 GRU神经网络文本情感分类模型(TMMG)构建
3.2.1 TMMG模型构建
根据公式(14)多元特征融合向量文本表示算法,将文本表示为融合特征序列,如公式(15)所示:
d=[M(w1),M(w2),…,M(wi-1),M(wi)]
(15)
M(w1)为文本中第1个词的融合特征,,M(w2)为第2个,依次类推,再把这些序列化数据依次作为GRU神经网络单元的输入,构成TMMG模型,如图3所示.

图3 TMMG模型Fig.3 TMMG model

3.2.2 TMMG模型训练分析
TMMG模型训练过程如图4所示.
①GRU神经网络正向传播

②GRU神经网络误差反向传播
GRU神经网络反向传播中的损失函数L是用来指导反向传播参数调节,在t时刻单元的损失函数L(t)计算如公式(16)所示:
(16)
根据公式(16),则整个GRU神经网络序列的损失函数L如公式(17):
(17)
Wr=Wrx+Wrh
(18)
Wz=Wzx+Wzh
(19)
(20)


(21)

(22)

(23)
(24)
(25)

(26)

(27)
(28)
(29)
(30)
δt=δh,t·zt·σ′
(31)
(32)
(33)
(34)
(35)
(36)
(37)
(38)
(39)
(40)
(41)
(42)
4 实验分析
4.1 实验数据
4.1.1 原始数据
实验环境基于TensorFlow和Python3.6;实验数据来源于豆瓣影评,使用Python数据爬虫,共爬取了404972条影评数据,其中1026条为缺失数据,最后保留403946条数据,包含8872部电影.
4.1.2 数据预处理
为了取样均衡,每部电影最多选取200条数据,每条完整的影评数据包含评论内容和星级评分,星级评分等级(rating)为1-5星,采用粗粒度情感表示:正面情感、负面情感和中性情感:
①星级评分大于等于4星的标注为正面情感文本;
②星级评分小于等于2星的标注为负面情感文本;
③星级评分为3的标注为中性情感.
由于,本文只对文本情感进行正面和负面的二元分类,所以中性情感评论不考虑;同时删除分词结果大于150个词的评价文本,最后得出的实验数据如表2所示.

表2 实验数据Table 2 Experimental data
其中每个类别随机选择90%做为训练样本,10%为测试样本.在进行实验之前还需要得到词嵌入向量库,本文使用google开源的Word2vec框架和CBOW模型对所有实验样本进行训练.为了对比不同词嵌入向量维度下的模型效果,分别选取了50、100、150、200四个维度进行词嵌入向量生成.针对文本中出现的一些非词语(表情、符号)也当成词语放入Word2vec模型中训练,得出其词嵌入特征,因为这些表情和符号也是情感表达的重要因素;考虑到豆瓣影评中的表情符号并不是来自一套固定的表情工具包,而是由用户的输入法产生的,其形式如︿ ′ 、╭(╯^╰)╮、⊙▽⊙等,情感难于区分和计算,所以忽略其情感特征E(w),使用零向量代替.
4.2 TMMG模型实验
4.2.1 TMMG模型算法
算法1.TMMG模型算法
Step 1.Selecttrainingset//分别选取4.1节中数据的90%作为训练样本,10%作为测试样本;样本表示为(xi,yi),xi为第i个样本,yi为样本xi的情感标签,正面情感标记为1,负面者标记为0.
Step 2.Preprocessingtext//使用jieba工具库进行分词,对文中高频出现的连词、代词、介词进行删除.
Step 3.Getwordembedding//根据Word2vec训练得到词嵌入向量库,依次替换文本预处理后的词.
Step 4.Calculationemotionalfeaturevector//根据情感要素字典依依匹配,如果是主张词、否定词、转折词中的一类,则直接情感特征向量的相应维度填1;如果是程度词则根据程度级别在对应维度填入对应值;如果是情感词,则根据公式(10)计算其情感度,填入对应维度;所有其他维度都填0.
Step 5.Calculationwordweight//使用归一化后的tf_idf计算词权重,具体计算见公式(13).
Step 6.Featurefusion//根据公式(14),把词嵌入向量、情感特征向量、词权重进行融合,得到多元融合特征.
Step 7.Textrepresentaion//根据融合特征,将文本表示为融合特征序列d=[M(w1),M(w2),…,M(wi-1),M(wi)].
Step 8.Train//把文本特征序列从后向前依次输入GRU神经单元,即最后一个融合特征放入最后一个GRU单元,倒数第二个融合特征放入倒数第二个GRU单元,依次类推;最后剩余的GRU单元使用零向量填充.
Step 9.Test//在得到训练结果后使用测试数据集进行测试,最后放入训练后的模型进行测试,其中测试数据集也需要经过步骤2-7处理.
4.2.2 超参数
在训练TMMG模型时不同的超参数也会影响到实验结果,但不同超参数的实验对比不是本文的主要研究内容,通过查阅相关资料和验证测试,本实验主要超参数采用情况如表3所示.

表3 TMMG模型超参数Table 3 TMMG model super parameter
4.2.3 实验结果
本实验选取Word2vec训练得到的4套词嵌入向量库(维度分别为50、100、150、200)和开源词嵌入向量库CWV[38](其维度为300)进行对比,算法的分类性能分别从精准率(precision)、召回率(recall)、F1-Measure三个指标进行评价,测试结果如表4所示.
实验显示:①TMMG模型在词嵌入向量维度为100时性能最好,精准率、召回率、F1-Measure分别达到了94.2%,94.1%,94.1%;②TMMG模型分类性能在利用自己训练的词嵌入向量库上进行实验,其性能优于CWV词嵌入向量库,这是由于CWV使用了面向全网各个领域的语料库进行训练,得到的词嵌入向量更符合全局环境,并且它不能完全覆盖本实验所有的词和表情符号;③所有实验数据训练的词嵌入向量不仅能够能覆盖所有的词和表情符号,并且得到的词嵌入向量相对全局词嵌入向量更贴切该局部问题领域.

表4 TMMG模型测试结果Table 4 TMMG model test results
4.3 实验对比分析
在以下对比试验过程中,TMMG都使用自己训练维度为100的词嵌入向量库.
4.3.1 与传统机器学习算法对比
为了对比TMMG和基于传统机器学习文本情感分类算法的性能,分别选取朴素贝叶斯(NB)、K-近邻(KNN)、支持向量机(SVM)三类传统的机器学习文本情感分类算法进行对比,使用相同的样本数据进行训练与测试,三种算法具体流程分别如算法Ⅱ、Ⅲ、Ⅳ描述所示.
算法2.基于NB的文本情感分类算法
Step 1.Selecttrainingset//来源于事先标注情感标签的文本.
Step 2.PreprocessingText//分词处理,排除停用词.
Step 3.Featureselection//根据预处理结果使用卡方检测(chi-square test,CHI)进行特征选择.
Step 4.Textrepresentation//使用词袋模型(bag-of-words,BOW)对文本进行表示.
Step 5.Trainingclassifier//选用伯努利模型进行训练,得出由先验概率和似然函数构成的分类器.
Step 6.Testclassifier/选择测试集测试分类器性能的相关指标.
算法3.基于KNN的文本情感分类算法
Step 1.Selecttrainingset//来源于事先标注情感标签的文本.
Step 2.PreprocessingText//分词处理,排除停用词.
Step 3.Featureselection//根据预处理结果使用卡方检测(chi-square test,CHI)进行特征选择
Step 4.Weightcalculation//使用TF-IDF进行特征权重计算
Step 5.Textrepresentation//使用向量空间模型进行文本表示.
Step 6.SelectKneighborsamples//依次计算测试样本和每个训练样本间的距离,并选取距离最小的k个临近样本,具体k值的选取使用交叉验证方式确定.
Step 7.classification//使用k个临近样本中出现频率最高的类别作为测试样本分类预测.
算法4.基于SVM的文本情感分类算法
Step 1.Selecttrainingset//来源于事先标注情感标签的文本.
Step 2.PreprocessingText//分词处理,排除停用词.
Step 3.Featureselection//根据预处理结果使用卡方检测(chi-square test,CHI)进行特征选择
Step 4.Weightcalculation//使用TF-IDF进行特征权重计算
Step 5.Textrepresentation//使用向量空间模型进行文本表示.
Step 6.Trainingclassifier//利用LIBSVM对样本进行训练,训练时选用RBF核函数.
Step 7.Testclassifier//选择测试集测试分类器性能的相关指标.
算法间的性能对比使用F1-Measure进行衡量,对比实验结果如图5所示.
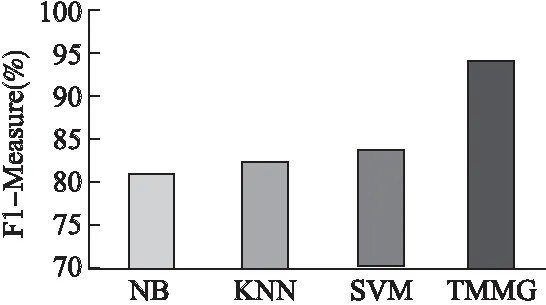
图5 与传统机器学习算法性对比Fig.5 Comparison with traditional machine learning algorithms
通过实验发现NB、KNN、SVM三个算法的平均F1-Measure值分别为81.2%、82.3%、83.4%,文本算法的F1-Measure值为94.1%,明显优于传统的机器学习文本情感分类算法.
4.3.2 与其他深度学习算法对比
为了进一步验证TMMG模型,分别选取基于卷积神经网络(CNN)、循环神经网络(RNN)、长短记忆网络(LSTM)、门控循环单元神经网络(GRU)的深度学习文本情感分类算法进行对比.
为了减少实验对比过程中不同超参数带来的影响,所以尽量保持它们的一致,其超参数具体如表5所示.
依据表5超参数,使用相同的样本数据进行训练与测试,算法的分类性能分别从精准率(precision)、召回率(recall)、F1-Measure三个指标进行评价.最后得出测试结果如表6所示.

表5 TMMG、CNN、RNN、LSTM、GRU 5种算法的超参数Table 5 Super parameters of five algorithms of TMMG,CNN,RNN,LSTM and GRU

表6 TMMG、CNN、RNN、LSTM、GRU 5种算法的测试结果Table 6 Test results of five algorithms of TMMG,CNN,RNN,LSTM and GRU
通过对比实验发现,深度学习算法都能保持较高的分类准确性,CNN、RNN、LSTM、GRU四种不添加任何情感和权重特征的算法性能相差不大,TMMG性能只是略高于其他几类算法.为了探究在不同训练数据集大小的情况下算法的性能差异,再分别选取训练数据集从初始1万依次递增到32万,每次以2倍递增,共6次实验对比,实验对比结果如图6所示.
通过实验发现在训练数据集比较小的情况下TMMG的性能明显优于其他算法,而随着训练数据增加这种优势也慢慢减少.这种情况是因为在训练数据量比较小的情况下,算法纯粹靠数据驱动进行模型训练很难真正学到数据背后隐藏的知识,而通过引入情感和权重的先验知识,一定程度上可以弥补数据量不足而产生的欠学习问题;当数据量达到一定规模后,深度学习算法依靠其强大的学习能力,不加入任何先验知识也能很好的学习到数据背后的隐藏知识.

图6 不同训练数据集下的实验对比Fig.6 Experimental comparison of different number training datasets
4.3.3 不同特征组合下的GRU对比
为了对比词嵌入特征(Word2vec)、词情感特征(Emotion)、词权重特征(TF-IDF)3个特征不同组合下GRU的实验效果,进行6组不同特征组合实验(Word2vec、Emotion、Word2vec+Emotion、Word2vec+TF-IDF,Emotion+TF-IDF、Word2vec+Emotion+TF-IDF),实验结果如表7所示.
通过对比发现,在单个特征中,Word2vec比Emotion效果好;两两组合比单个特征效果好,其中Word2vec+Emotion组合比Word2vec+TF-IDF和Emotion+TF-IDF的效果好;Word2vec+Emotion+TF-IDF三者组合为最优.其中,Word2vec+Emotion+TF-IDF这种组合模式就是本文提出的TMMG算法模型.

表7 不同特征组合下的GRU对比Table 7 GRU comparison under different feature combinations
5 结 语
随着互联网和自媒体的快速发展,越来越多的民众通过网络来发表观点,如何对这些网络文本进行情感自动分类是网络预警监测的一个重要环节.基于语义理解的文本情感分类算法,由于文本表达的多样性,很难建立完善的情感词典和句式搭配模板,导致算法具有很强的局限性;基于人工特征工程的浅层机器学习文本情感分类算法存在语义丢失、矩阵稀疏,维度爆炸等问题,并且对深层次的特征难以捕获,所以算法的泛化能力不强.近年来随着数据量的增加和计算性能的快速提升,基于深层神经网络的深度学习算法凭借其强大的学习能力,在自然语言处理、计算机视觉、图像处理等领域快速发展;而大部分学者提出的基于深度学习文本情感分类算法追求数据驱动,忽略了自然语言中关于情感、权重的先验知识,导致算法只能在大规模数据集的情况下才能获得较好的性能.所以,本文提出基于词嵌入特征、词情感特征、词权重特征融合的门控循环单元(GRU)神经网络文本情感分类模型TMMG,实验结果表明:TMMG模型性能远高于传统机器学习算法,相比于其他深度学习算法也具有一定优势,并且在训练数据不足的情况下这种优势更加明显;但TMMG模型在计算词情感特征和词权重特征时需要花费不少时间,其训练时间也远高于传统机器学习算法,如何在分类性能和训练耗时上获得一个较好的平衡是值得继续研究的方向.
