基于改进EMD距离的信息特征单元的聚类方法
2019-11-07兰慧红黄紧德
兰慧红,黄紧德
基于改进EMD距离的信息特征单元的聚类方法
兰慧红,黄紧德
广西教育学院数学与信息科学学院, 广西 南宁 530023
为研究基于改进EMD距离的信息特征单元聚类方法,本文利用向量空间方法提取信息特征单元,设置EMD地面距离作为不同信息特征单元间的距离,将信息特征单元比作供货商与消费商。为避免利用EMD距离聚类引起的信息特征单元过分割、正例现象增多以及供货商无法供货问题,设置符合特征相似条件的供货商增大权值的相似阈值,利用阈值令运输以低成本的供货商为主,改进EMD距离;利用改进EMD距离算法实现信息特征单元的有效聚类。经仿真平台验证,该方法对文本、股票等不同类型信息特征单元聚类精度达到99%以上,并且聚类过程迭代次数少,聚类性能优。
EMD距离; 信息特征单元; 聚类方法
近年来网络发展飞速,人类生活已经越来越走进信息化[1]。在这种大数据环境下,如何从繁琐无规律的信息中有效寻找自身需要且具有价值信息是目前急需解决的问题[2]。在大数据环境下检索信息特征单元,并将信息特征单元进行分类与融合,在数据挖掘、知识管理与数据搜索等领域中都具有重要意义[3,4]。
以往信息特征单元聚类方法的聚类效果都较为粗糙,例如基于GDD算法的聚类方法可将大部分信息特征单元聚类,但是存在单元过分割问题,聚类精度低;基于PCAP算法的聚类方法精度可达到要求,但计算过程复杂,并容易受噪声影响[5]。本文针对以上聚类方法存在的缺点,提出基于改进EMD (Earth Mover's Distance)距离的信息特征单元聚类方法,通过该方法进行信息特征单元聚类,可有效处理含有噪声的信息特征单元,解决单元过分割、正例现象增多等问题,使信息特征单元聚类结果更加精确[6]。
1 信息特征单元聚类方法分析
1.1 提取信息特征单元
采用向量空间方法提取信息特征单元。设待提取信息特征单元集为S=(t1,w1;t2,w2;L;t,w),该特征单元集中,t1表示信息特征单元,w1表示该信息特征单元权重,利用信息特征单元间相似度衡量信息特征单元相关程度公式如下:
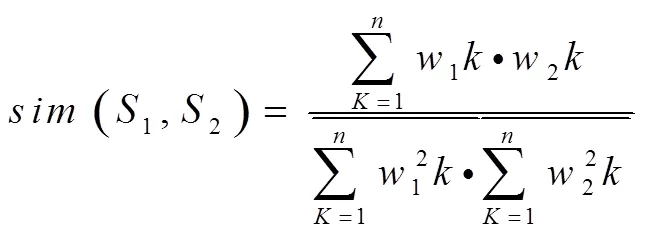
若向量维数较高,在利用提取的信息特征单元进行聚类时会增加聚类复杂度并为聚类增加干扰,为了解决含有噪声的信息特征单元,因此需先筛选候选特征信息增益再提取信息特征单元[7]。
利用信息增益衡量提取信息特征单元的度量,待聚类特征集的信息增益公式如下:

式中,n表示训练特征集中出现t的数量,(t)表示待聚类特征t的信息增益,(t)公式如下:

特征的条件熵公式如下:

以上公式中,(S|t)为特征t与特征S同时出现的条件概率。
提取的特征单元信息增益可直接反应出信息特征单元聚类能力,将所获取的(t)结果依据从大至小顺序排序,设置阈值对排序结果进行阶段,将符合阈值条件的信息特征单元为信息特征单元聚类依据[8]。
1.2 EMD距离
EMD距离是从运输问题演化而来,是一种度量相似性的方法,可实现信息与信息之间多对多优良匹配,因此很适宜用于信息特征单元聚类[9]。因此定义EMD地面距离作为不同信息特征单元间的距离[10]EMD距离具体可描述为:存在多个供应商将自身一定数量货物发送至不同消费商,寻找成本最小的货物传输途径,使货物可以满足消费商要求进行有效的发送。利用运输问题将特征聚类问题简化为线性规划问题,可以很好的解决信息特征单元聚类问题。
设上文中提取不同信息特征单元空间中含有的距离映射用表示,:×®+,则有:

以上公式中,,Î为该特征空间中一点,点的权值用w表示。
设=[d]为地面距离矩阵,表示点与点间地面距离。设点p与点q间流用S表示,存在流矩阵=[S]以保证全局代价函数为最小,且应满足的约束条件如下:
S≥0,1≤≤,1≤≤(6)
利用以上公式解决EMD距离的运输问题,获取矩阵,可得EMD距离的运输工作规格化值:
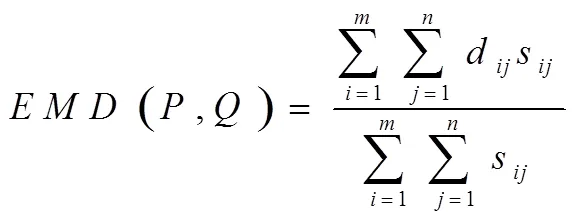
EMD距离中EMD值不会随特征分布的微小变化而引起波动,因此具有连续性;EMD距离的特征分布紧凑型与灵活性可避免属性相似性度量的量化问题;有利于特征匹配的平衡。虽然EMD距离具有以上优点,但是EMD距离也有着对精度要求高导致计算过于复杂的缺点,因此在进行信息特征单元聚类时需要对EMD距离进行改进。
1.3 基于改进EMD距离的信息特征单元聚类
针对EMD距离的信息特征单元聚类问题,可将信息特征单元比作供货商与消费商,设二者分别为S={x,=1,2,…,}与S={x,=1,2…,},且满足xÎR,xÎR。两信息特征单元的EMD距离随权值w,w与运输成本d改变而改变。信息特征单元间距离相似性用d衡量,具体公式如下:

将现有的信息单元特征值集定义w。对信息单元特征集以“分割特征数量与总特征集比值”作为相应区域权值。通过特征与质心距离计算信息特征单元集,具体计算过程为:

式中,O表示特征S质心。
采用未改进EMD距离聚类信息特征单元时,会引起特征单元过分割、正例现象增多以及供货商无法供货的问题,因此需改进EMD距离,使信息特征单元聚类结果最优。
计算信息特征单元集S内的示例相似性,将小于阈值的特征合并,计算特征相似性公式如下:

若公式(11)计算结果sim(x,x)<,那么对应特征示例可合并为新示例,合并过程如下:
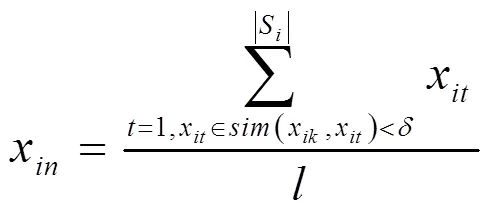
以上公式中,为|S|内与x相似示例数量。
2 实验分析
为检验改进EMD距离方法对信息特征单元的聚类效果,在Matlab仿真实验平台中编写本文方法进行聚类实验,实验目标分别为(1)来自中国科学院计算技术研究所文本数据;(2)Iris数据库中选取的信息特征单元;(3)MIL标准数据库中数据集MUSK;(4)中国财经股票2018年1月1日至12月31日的30支股票数据。并将本文方法聚类结果与GDD方法和PCAP方法聚类结果进行比较。
2.1 文本特征单元聚类结果
将来自中国科学院计算技术研究所文本信息特征单元10000例进行分析,利用本文方法、GDD方法和PCAP方法三种方法进行聚类,结果见表1。
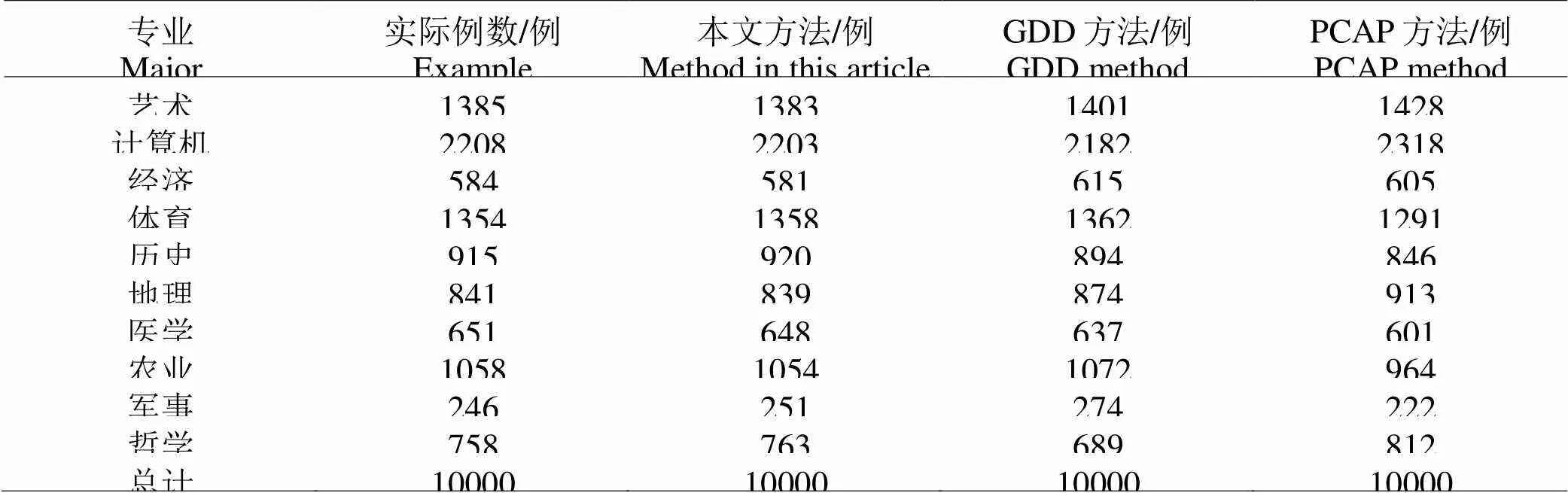
表1 三种方法聚类文本特征单元结果
三种方法聚类文本特征单元结果准确率见图1。

图1 三种方法聚类文本特征单元准确率
从表1与图1结果可以看出,本文方法聚类中国科学院计算技术研究1000例文本信息特征单元结果准确率最高,准确率均在99%以上,说明了本文方法的聚类有效性。
2.2 Iris数据库聚类结果
在Iris数据库中选取鸢尾花特征作为聚类信息特征单元,该信息特征共有200例,分为4类,每类包含50例,各例信息特征单元中含有4个属性。三种方法聚类结果见表2。

表2 三种方法聚类鸢尾花信息特征单元结果
表2可以看出,本文方法聚类结果较准确,正确率在95%以上,而GDD方法正确率仅为80%左右,PCAP方法正确率最高仅为76%,验证了本文方法的聚类有效性及准确性。
2.3 MIL标准数据库聚类结果
在MIL标准数据库中选取MUSK数据集作为实验对象,MUSK数据集是来自麝香分子的样本,该数据集中包括Musk1与Musk2两个子信息特征单元,Musk1中包括57例正向信息特征单元与64例负向特征单元,Musk2中包括162例正向信息特征单元与174例负向特征单元。三种方法聚类实验结果见表3。

表3 三种方法聚类MUSK信息特征单元结果
表3结果可以看出,本文方法聚类457例信息特征单元仅有一例聚类错误,正确率为99.8%,而GDD方法和PCAP方法正确率分别为97.8%与97.4%,再次验证了本文方法的聚类准确性。
2.4 迭代次数统计
为验证本文方法聚类效率,在实验中统计了以上三种方法迭代次数,结果见图2。
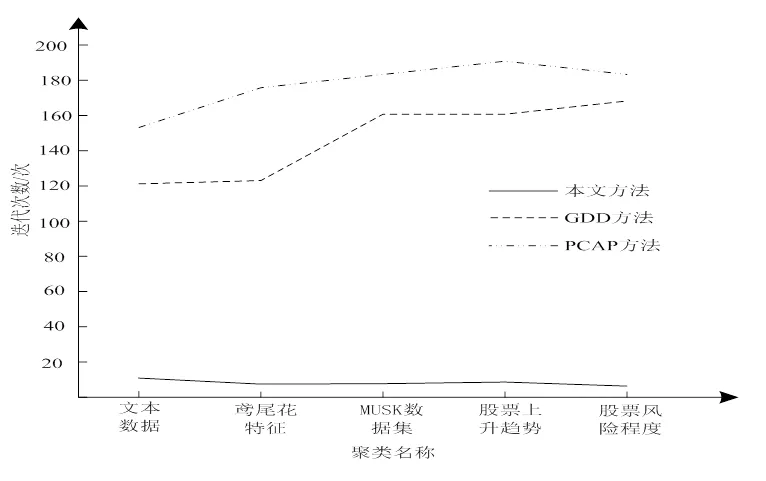
图2 三种方法聚类迭代次数
从图2可以看出,本文方法在聚类五个信息特征单元集时迭代次数均在10次以下,而GDD方法在聚类依据风险程度进行股票聚类时迭代次数达到了160次,PCAP方法在聚类依据上升趋势进行股票聚类时迭代次数高达185次,迭代次数的增多不仅会为算法的计算增加复杂多,并且影响聚类的准确度,因此可以看出本文方法聚类效率最高。
根据以上实验分析三种方法对不同类型信息特征单元的聚类结果、聚类准确率以及方法聚类迭代次数可以看出,本文方法聚类准确率明显高于其它两种方法,并且迭代次数最少,不仅节省了运算时间,也增加了信息特征单元聚类准确性。
3 结 论
数据挖掘是信息处理的重要发展方向,而信息特征单元聚类是数据挖掘中的重要概念,有效的信息特征单元聚类方法可以为,高精度检索海量数据中隐藏的有价值信息特征提供可靠依据。本文采用改进EMD距离的信息特征单元聚类方法,解决信息特征单元聚类问题。本文方法优化传统EMD距离计算过于复杂问题,使信息特征单元聚类性能达到最优,并且解决了传统信息特征单元聚类方法存在的抗噪性差、单元过分割、正例现象增多等问题,实现信息特征单元的高精度聚类。
[1] 徐敏姣,徐青山,袁晓冬.基于改进EMD及Elman算法的短期光伏功率预测研究[J].现代电力,2016,33(3):8-13
[2] 黄友朋,赵山,许凡,等.EEMD排列熵与PCA-G K的滚动轴承聚类故障诊断[J].河南科技大学学报:自然科学版,2017,38(2):17-24
[3] 姜万录,王浩楠,朱勇,等.变分模态分解消噪与核模糊C均值聚类相结合的滚动轴承故障识别方法[J].中国机械工 程,2017,28(10):1215-1220
[4] 张淑清,李威,张立国,等.基于多元经验模态分解互近似熵及GG聚类的轴承故障诊断[J].中国机械工程,2016,27(24):3362-3367
[5] 陈安华,莫志军,蒋玲莉,等.基于复杂网络社团聚类的复合故障特征分离诊断方法[J].振动与冲击,2016,35(7):76-81
[6] 余炜,韩强,马晶晶,等.EMD和FCM的脑电信号处理方法[J].数学的实践与认识,2016,46(15):223-228
[7] 魏林,白天亮,付华,等.基于EMD-LSSVM的瓦斯浓度动态预测模型[J].安全与环境学报,2016,16(2):119-123
[8] 程静,刘家骏,高勇.基于时间序列聚类方法分析北京出租车出行量的时空特征[J].地球信息科学学报,2016,18(9):1227-1239
[9] 杨慧,李振,霍纬纲.改进小波聚类算法在QAR数据中的应用[J].计算机工程,2017,43(9):29-33
[10] 张林,李秀友,刘宁波,等.基于分形特性改进的EMD目标检测算法[J].电子与信息学报,2016,38(5):1041-1046
The Method Clustering the Information Feature Units Based on Improved EMD Distance
LAN Hui-hong, HUANG Jin-de
530023,
To study on the method clustering information feature units based on EMD distance, this paper extracted information feature units by the vector space method to set EMD ground distances as the distances between different information feature units and information feature units were compared to suppliers and consumers. In order to avoid the over-segmentation for information feature units caused by EMD distance clustering, the increase of positive phenomena and the inability of suppliers to set a similar threshold for suppliers with similar characteristics to increase their weight and the use of thresholds made transportation mainly for low-cost suppliers improve EMD distance; An improved EMD distance algorithm was used to achieve effective clustering of information feature units. The method could effectively cluster different types of information feature units, such as text and stock, with an accuracy of more than 99 %, and the clustering process had fewer iterations and excellent clustering performance.
EMD distance; information feature units; clustering method
TP391
A
1000-2324(2019)05-0885-04
10.3969/j.issn.1000-2324.2019.05.033
2018-03-26
2018-05-09
广西教育厅科研项目:基于文本聚类的东盟跨语言查询扩展模型及算法研究(2019KY1678)
兰慧红(1985-),女,硕士,讲师,主要从事数据挖掘和信息检索等研究. E-mail:lanlandoll@163.com
