Standardization of Robot Instruction Elements Based onConditional Random Fields and Word Embedding
2019-11-06HengshengWangZhengangZhangJinRenandTongLiu
Hengsheng Wang, Zhengang Zhang, Jin Ren and Tong Liu
(1. College of Mechanical & Electrical Engineering, Central South University, Changsha 410083, China;2. State Key Laboratory for High Performance Complex Manufacturing, Changsha 410083, China)
Abstract: Natural language processing has got great progress recently. Controlling robots with spoken natural language has become expectable. With the reliability problem of this kind of control in mind, a confirmation process of natural language instruction should be included before carried out by the robot autonomously; and the prototype dialog system was designed, thus the standardization problem was raised for the natural and understandable language interaction. In the application background of remotely navigating a mobile robot inside a building with Chinese natural spoken language, considering that as an important navigation element in instructions a place name can be expressed with different lexical terms in spoken language, this paper proposes a model for substituting different alternatives of a place name with a standard one (called standardization). First a CRF (Conditional Random Fields) model is trained to label the term required be standardized, then a trained word embedding model is to represent lexical terms as digital vectors. In the vector space similarity of lexical terms is defined and used to find out the most similar one to the term picked out to be standardized. Experiments show that the method proposed works well and the dialog system responses to confirm the instructions are natural and understandable.
Keywords: word embedding; Conditional Random Fields (CRFs); standardization; human-robot interaction; Chinese Natural Spoken Language (CNSL); Natural Language Processing (NLP)
1 Introduction
People want robots more human-like in almost all aspects, with no exception in communication and interaction. In Ref.[1], a scenario of remotely directing a mobile robot in disaster sites for rescue jobs with (Chinese) Natural Spoken Language (CNSL) was proposed, in which a cascaded CRF model was used to extract navigation elements from natural language instructions to make the robot understand what the instruction is about. The extracted navigation elements formed the structured navigation instruction (SNI) for robots. The intention was to train robots other than humans to make the interaction process easier and more natural. It cannot certainly suggest that robot understanding of the instructions always get perfect match to what it really means. For example, the command text from voice recognition might be incorrect, and disambiguation and conformation should be needed. We have been working on a dialog system, through turns of asking and answering, to make confirmation about (Chinese) Natural Spoken Language Instructions (CNSLI) during human robot interaction with CNSL and to make sure that the robot really knows what to do before completing the instruction. This system is called Dialog system of Human-Robot-Interaction through Chinese Natural Spoken Language or shortly DiaHRICNSL. The dialog system[2-3]for human robot interaction through natural spoken language is different from those for tickets in travel agencies, which have fixed procedure for information collection about destination, transportation, accommodation, etc., and also different from ordinary chatbots which usually have only one turn of asking and answering. More flexible and diverse interactions are expected in DiaHRICNSL. This paper focuses on one particular problem in the development of DiaHRINSL, which comes from the fact that people usually speak in different ways for the same meaning. For example, in an instruction like “走到前面的路口” (go forward to the intersection ahead), the destination place “路口” (intersection) can be expressed in different ways in CNSL like “岔道” (cross road), “口子处” (cross place), “拐角” (corner), or sometimes even more particularly as “十字路口” (cross intersection), “丁字路口” (T-intersection) etc., and the action word “走” (go or walk) can also be expressed differently as “移动” (move), or even simply as “到……去” (to). We call this problem STANDARDIZATION for the elements of CNSLI for robot control. After standardization of elements, the robot should, for example, understand the end place “路口” (cross road) as the same meaning with “岔道” (intersection), “口子处”(cross place), “拐角” (corner) etc., or replace all the later three with the standardized former one, “路口” (cross road), in dialog procedure, or randomly use one of them for natural conversation.
A possible way to tackle this problem is to put all the synonymous words, in the context of robot control (say navigation) with CNSL, together into a synonym dictionary, but it is tedious and hardly complete. There is another method called Approximate String Matching (ASM) in some Chinese language related applications, which is to search similar Chinese characters, but which does not show any semantic connections that are just the concerns of our system. For instance, the input character “北京” (Beijing) may be returned with choices of “北京市” (Beijing City), “北京路” (Beijing Road), “北京餐馆” (Beijing Restaurant), “北京烤鸭” (Beijing Roast Duck), etc., which are very different in meanings. And in our situation place names like “岔道” (intersection) and “路口” (cross road), “厕所” (toilet) and “洗手间” (washroom),“走廊” (passageway) and “过道” (aisle) have similar meanings but share no Chinese characters. So the ASM approach does not suit our needs.
This paper proposes an approach to tackle this problem which is called standardization here. We build a standardized vocabulary for each NE. We extract lexical Terms To Be Standardized (TTBS) from SNI with a CRF model (Section 2). TTBS are then replaced with the most suitable standard lexical Terms In Vocabulary (TIV) by comparing the similarity between TTBS and TIV using word embedding model (Section 3). Section 4 shows experimental results of the methods given in Section 2 and 3. Conclusions of the work are given in Section 5.
2 CRF Models for Navigation Instructions
2.1 Extracting Navigation Elements from Instructions
The outline of extracting navigation elements from CNSLI, proposed in Ref.[1], is shown in Fig.1. From the input navigation instruction (NI) finally we get the output of SNI. The big circle enclosed parts indicate handling steps, the first (shaded) one of which uses the on-line service from free website (Jieba) to do lexical segmentation and part of speech (POS) tagging on the input sequence of NI, and the arrows around which indicate the input and output information marked with words inside the dashed squares. There are slight differences in Fig.1 compared with Ref.[1] where we had three cascaded layers of CRF but here we have only two layers. We simplifies the NE (Navigation Elements) from six in Ref.[1], namely, Start Place (SP), End Place (EP), Action (AN), Direction (DN), Distance (DC), and Speed (SD), to four, and the SP is neglected because it always means the current place to start in instructions, and we combine the AN and DN as a new AN including direction information. So the third layer of CRF which was to distinguish the elements of SP and EP is neglected here.
The CNSLI is structured with four NEs which the corresponding four slots are to be filled with. Fig.2 shows a slot-filling example where there is no DC element in the instruction and the DC slot remains empty. NPOS in Fig.1 means Navigation Part Of Speech defined in Ref.[1], which is the basis for procedures followed including filling the slots.
2.2 Extract TTBS from NEs
In the four elements of NEs, EP has the greatest variation in the description because of various place names used in instructions, while the other three elements have relatively less variations and so are relatively simple. We take the example of EP to demonstrate the procedure of standardization.
Place names (used for EP) usually come with attributive words or phrases modifying them, like“旁边的教室” (next door classroom), “走廊的尽头” (the end of corridor), “空调旁边的椅子” (the armchair next to the air conditioner). It is the core words, like “教室” (classroom), “走廊” (corridor) and “椅子” (armchair) in above example Eps that people usually use with different expressions and that deserve the process of standardizing. We want to pick up these words as TTBS and neglect the others.
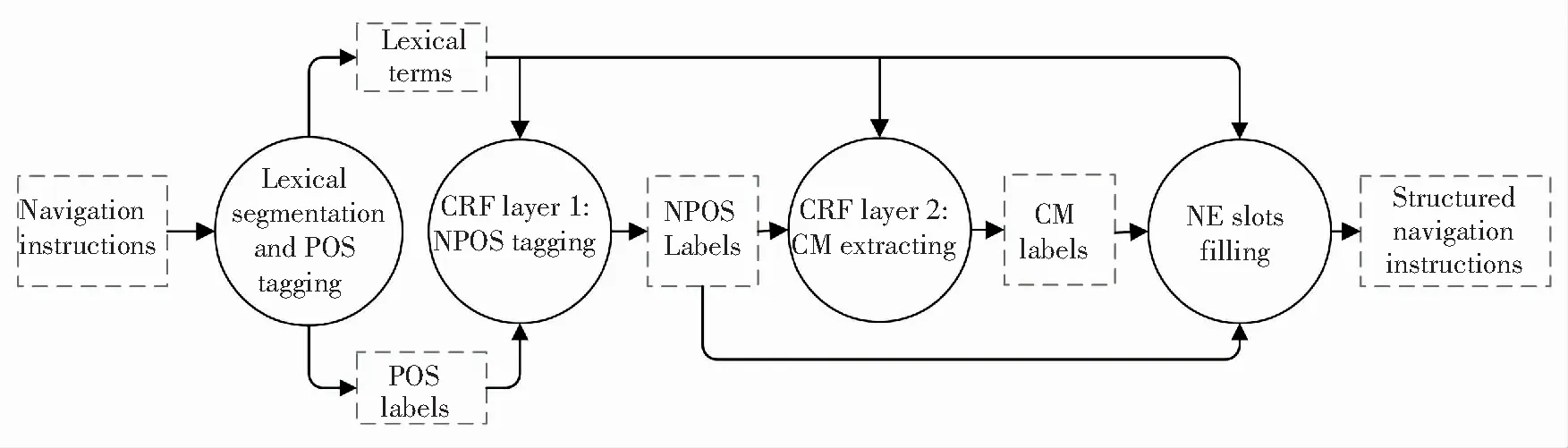
Fig.1 Procedure of handling from CNSLI to structured navigation instruction

Fig.2 Filling slots with NEs from structured navigation instructions
We use another CRF model to extract the TTBS navigation elements[4-5](as shown in Fig.3). The features for this CRF model are the token terms after segmentation, its POS, and its context mainly refer to the interdependencies between the token and the terms nearby. The inputs of feature function are:
(1)Observed sequenceSconsisting of segmented terms and their POS tags;
(2)Token’s spoti;
(3)TTBS Tags of the tokenliand its adjacent termsli±n(nis the length of the context window that we set);

Fig.3 TTBS tagging
The feature functions are extracted from navigation instructions via template file. Take the word “的” (of) from instruction “到前面的路口左转” (turn left at the intersection ahead) as a token whose spot is 0, and then the example template and feature are shown in Table 1.
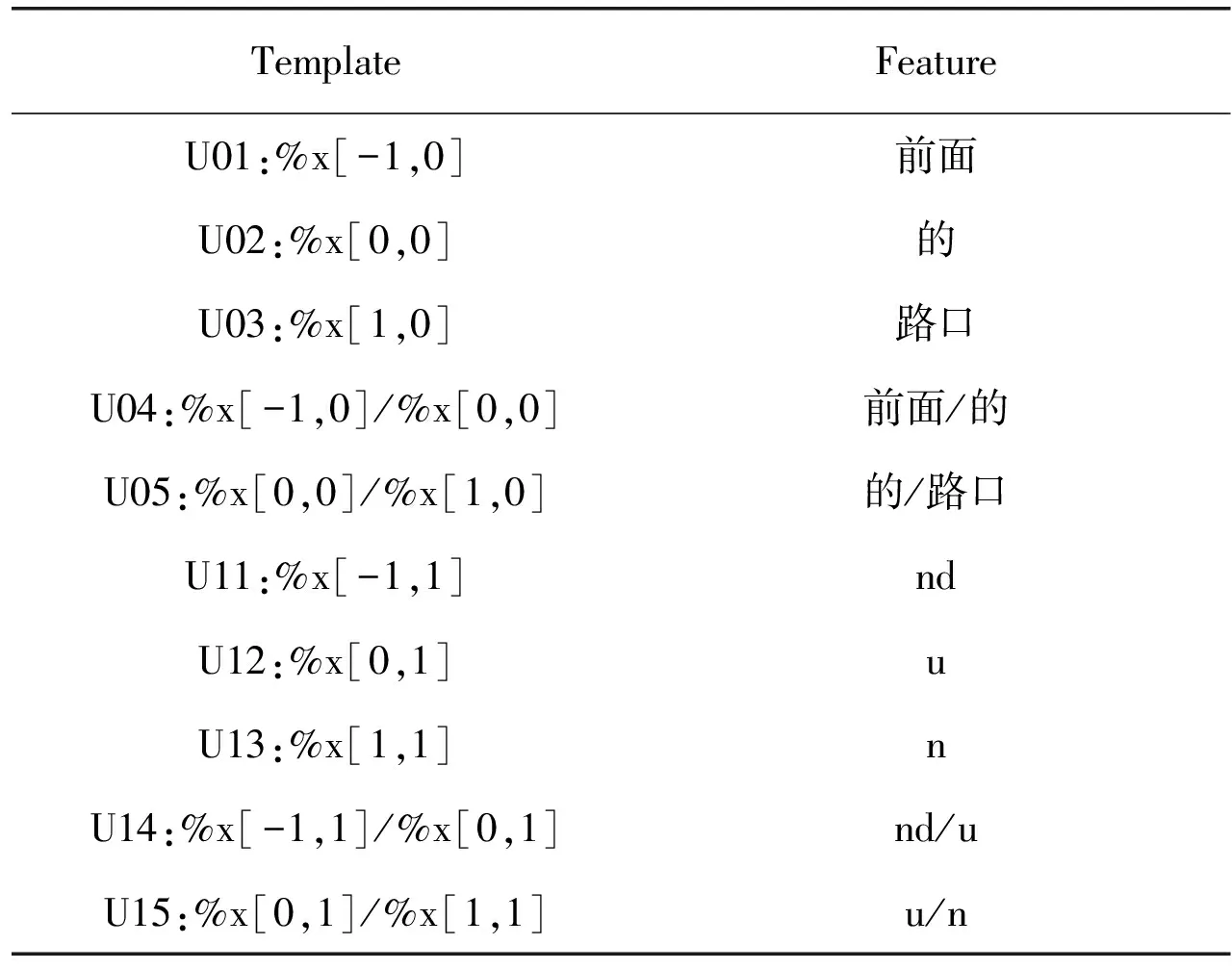
Table1 Template and feature
The“row” in %x[row, col] represents the relative row deviated from the current token, and the “col” is the column count (“col 0” for word and “col 1” for POS). POS tags: nd, u, n indicate noun of direction, auxiliary and noun accordingly. “/” is to separate two successive features in one template. The length of the context window is 3 in Table 1, and we found out that the best length is 5 for this model from training practice. Every row in Table 1 generates a feature function, and we collect training corpus to form feature functions for all sample instructions. The label sequence consists of four types of tags shown in Table 2. The CRF model is then trained based on the feature functions and the corresponding tags.

Table 2 Tags of TTBS
As an example for tags, we take the place name“武汉长江大桥” (Wuhan Yangtze River Bridge) which might be incorrectly segmented to several names like “武汉” (Wuhan), “长江” (Yangtze River) and “大桥” (Bridge). In this case we must label it as follows: “武汉” (Wuhan)/ B-A, “长江” (Yangtze River) / I-A , “大桥” (Bridge)/ I-A, and the place name “武汉长江大桥” (Wuhan Yangtze River Bridge) would be recognized as a whole in tests because of the tagging.
The CRF model was trained with CRF++, an open software. Table 3 shows the test result for a navigation instruction“沿着玉带河走到机电楼门口进去到桌子边上停下” (go along the Yudai river to the entrance of the M&E Building and go inside, and then stop at the reception desk). The maximum probability for each term gives the output tag sequence {N,N,N,N,A,N,N,N,A,N,N}, and the TTBS terms are “机电楼” (M&E Building) and “桌子” (reception desk) corresponding to “A”s in the tag sequence, which are correct.
The POS tags in Table 3: p, ns, v, n, nl, nd, indicate preposition, noun of places, verb, noun, noun phrases and noun of direction, accordingly.
3 Word Embedding for Standardization
3.1 Word Embedding and Word2Vev
Word embedding is a method of representation of words with numerical vectors which have advantages of handling words and relations between words with numerical calculations, or simply word embedding is word vector. In Chinese, the meaningful unit in sentences usually is phrase, or fixed word-sequence, which is called lexical term (or simply term) in this paper. We will represent Chinese lexical terms with numerical vectors by the method of word embedding, and terms are segmented from a sentence thanks to a free website service of lexical segmentation.
Word embedding was proposed by Hinton[6]in 1986. Xu[7]introduced the idea of neural network into the training of word vectors in 2000. Bengio[8]proposed a multi-layer neural network in model training. Collobert[9]applied word embedding to accomplish part-of-speech tagging, semantic role labeling, phrase recognition in NLP. Mnih[10-11]started training word embedding language model with deep learning, and proposed a hierarchical method to improve training efficiency. Mikolov[12]started using Recurrent Neural Network (RNN) in 2010 to do the word embedding training. Huang[13]attempted to make word embedding contain more semantic information. Word embedding had been used in many NLP tasks such as language translation[14]and text classification[15].
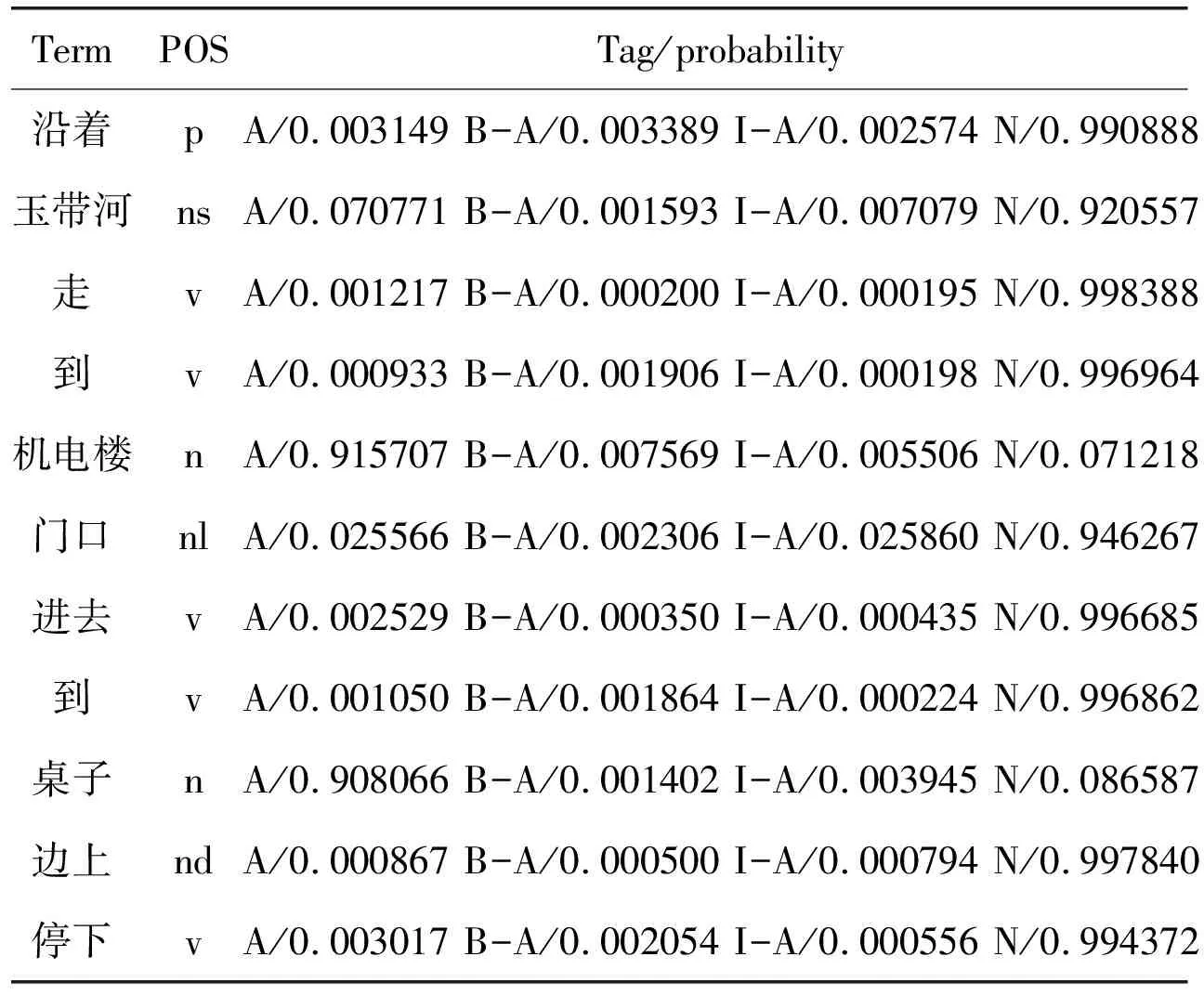
Table 3 Output of CRFs model
In 2013,Mikolov developed Word2Vec free software for the training of word embedding[16-17]which became a main tool in the research community[18-20]. It is a prediction model using shallow neural network based on Continuous Bag-of-Words (CBOW) and Skip-gram and the training is efficient. Fig.4 shows the prediction of the token wordv(wt) from its context words ofv(wt-2),v(wt-1),v(wt+1),v(wt+2) based on CBOW, and after training the word vectors are contained in the parameters of the projection layer.v(.) in Fig.4 indicates the One-hot Representation of a word over a fixed vocabulary, andwtindicates the token word.
Apart from CBOW there is an option of Skip-Gram model which predicts the context words according to the token words. CBOW model is better for the case of scarce training data while Skip-Gram usually for abundant training data. Word2Vec also provides Hierarchical Softmax (HS) and Negative Sampling (NEG) algorithms for efficient training process.

Fig.4 CBOW model
3.2 Training
We collected 314 sentences of instructions for robot navigation, some other materials from news, literatures and messages of BBS, all of 4017 sentences as our corpus. After preprocessing of lexical segmentation with Jieba free software, the vocabulary has 41149 lexical terms.
The Word2Vec in Gensim[21]package was used to train the model, and the options we chose were as follows: vector size (dimension), 150; windows size (the maximum distance for context), 5; min_count (the minimum occurrence of terms less than which will be ignored), 3; sg (training algorithm selection), 0 for CBOW; hs (choice for HS), 1; negative (choice for NEG), 0; iter (the number of training iterations), 10; alpha (initial learning rate), 0.025.
3.3 Similarity Between Terms
We use cosine similarity measure for the standardization of TTBS.
(1)
4 Experiments and Results
We used iFLYTEK[22]to obtain the text from Chinese spoken language, and Jieba[23]for Chinese word segmentation and POS tagging.
4.1 Experiment 1
The CRF model introduced in Section 2 for the tagging of TTBS was tested. In the first case, there were 200 instructions in the test set, which intentionally included TTBSs; and 100 instructions in the second case without TTBS. The results are shown in Table 4. The CRF model shows good performance for the selection of TTBSs from input instructions. The reasons for fault tagging are mainly, (1) wrong text recognition of spoken language, and (2) wrong word segmentation because of non-covered phrases in training set. The further improvement of tagging can be achieved by the enlargement of the positive training set in experiments.

Table 4 Result of Experiment 1
4.2 Experiment 2
The word embedding model introduced in section III for the standardization of TTBS was evaluated; and the results were also compared with traditional ASM method.
The procedure of the experiment was based on our prototype of dialogue system. Chinese spoken instruction inputs were given and the dialogue system responded with generated natural language. The process in between includes the models introduced in this paper. The response of the dialogue system was used as a criterion for the judgement of whether the standardization worked well or not. The generation of the natural language response was created through AIML (Artificial Intelligence Markup Language). For the diversity of the natural language instructions, the test set was collected from 5 different students with 20 instructions each.
The response was judged with Matching Rate (MR) and Intention Rate (IR). MR measures the matching count of TTBS to TIV, but not necessarily in accordance with the intentions of the input instructions which are measured by IR. For example a navigation instruction “快点去岔道” (Go to the crossroad fast) might be standardized as “快点去楼道” (Go to the corridor fast). This is a kind of matching, but not the intention of the instruction at all, which might be from the imperfect standardization wrongly putting “岔道” (crossroad) in the position most closer to “楼道” (corridor) which should be “路口” (intersection) instead. IR is defined as:
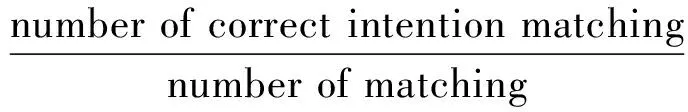
100%
(2)
Table 5 shows the experiment results, in which two methods have close results of MR while apparently higher IR result occurs with word embedding matching. This is because word embedding method reflects the semantic meanings of the words while ASM method is only based on the similarity of strings of characters literally without any intrinsic semantics related. Three examples of spoken instruction input is shown in Table 6 with the responses from our prototype dialog system with different standardization methods, which shows how incorrectly the ASM method sometime responses. In the first case two methods have correct intention matching; in the second case, ASM method wrongly matches corridor (楼道) with staircase (楼梯) because these two place names in Chinese share the same word “楼”, while word embedding method correctly matches corridor (楼道) with passageway (走廊) although they do not share any word in Chinese. In the third case, ASM method has got no match of the place name W.C. (厕所), while word embedding method matches the W.C. (厕所) correctly with washroom (洗手间).
This experiment shows that the word embedding model trained in this paper is good as a digital expression of lexical term which was used to find a substitution meaningfully for a lexical term in a spoken instruction which was recognized as TTBS. Furthermore the goodness or accuracy of the word embedding model can be improved through practical use with more enlarged training set; while the ASM method depends more on the rules created manually which quickly become too complicated to be improved.

Table 5 Result comparison of two methods
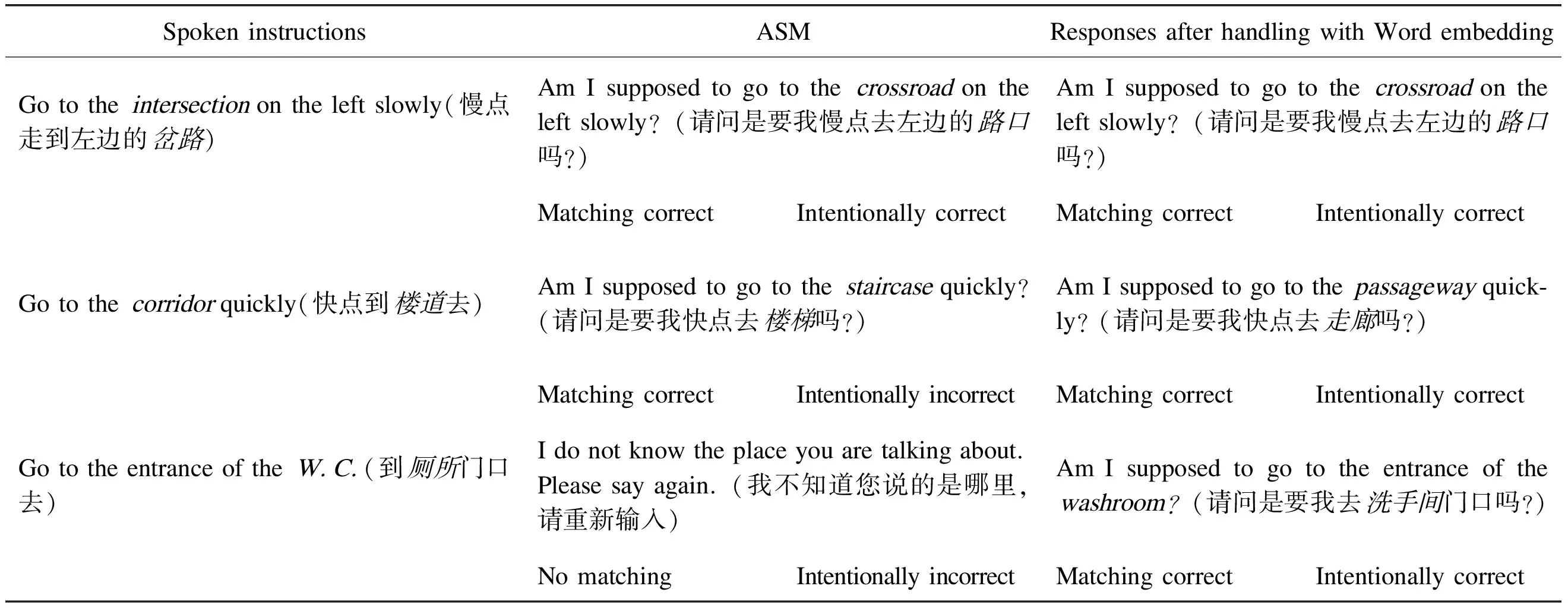
Table 6 Experimental instances of responding from the dialog system
4.3 Experiment 3
The selection of threshold value of similarity was tested in this experiment.Only when the largest similarity between TTBS and the candidate TIV is greater than the threshold, the pair is considered as a match, and so the threshold can be used to filter out irrelevant matches. The absolute value of similarity is less important although the larger values generally indicate better model trained. The relative value counts more.
The experimental result is in Table 7 which shows that the value of 0.5 got less than half (26%) of TTBS being standardized with TIV but which are almost all (11 out of 13) intentionally correct. The value of 0.4 in Table 7 seems a better one because we got more matches, yet negatively the IR value went down also. The procedure can be shown in Fig.5.

Table 7 Effect of threshold value
It is not likely to obtain the optimized one in the way of arbitrarily choosing the threshold value shown in Fig.5. In fact, more accurately the value should be different for every TIV. We developed a scheme to avoid this hard selection of threshold value, in which Reinforcement Learning (RL) is used (as shown in Fig.6). The main idea is the Q-value matrix which is being optimized through the collected and continuous updating corpus from recordings of actual interaction on the dialog system. The details of learning model are not presented here, but the experimental result is presented in Fig.7 which shows the growth of both MR and IR (dashed lines in Fig.7) with the increase of the number of interactive instructions when using RL. The solid lines in Fig.7 show that the MR and IR stay relatively in the same level.

Fig.5 The threshold value of similarity

Fig.6 The reinforcement learning added in the threshold value selection

Fig.7Comparative results of MR and IR with and without RL added (threshold value is0.4)
5 Conclusions
Navigating a robot with natural spoken language has been long expected, only recent advances in artificial intelligence make the application expectable. This paper stood on the fact that no matter how delicate a computational natural language understanding module is there will always be possible with misunderstanding. The confirmation of instructions to robots before being accepted and carried out should be always necessary for practical use of natural-language-controlled robots especially for some important and critical jobs like rescue and assembly. Our prototype dialog system was structured for this reason, and lexical term standardization proposed in this paper is part of the dialog system. We focused on place names, which usually are expressed in different lexical terms in everyday life, occurred in spoken natural language instructions for robot navigation in indoor environment. The aim was to substitute the place name to be understood with some known one, which was called standardization in this paper. The first step was to pick up the lexical term required to be standardized, and we trained a CRF model which picked place names from the sequence of lexical terms of instructions pretty good as expected in experiments. Then for the standardization of the picked place name, we expressed lexical terms with digital vectors using word embedding model which meant to catalog terms according to the training corpus, and the similarity value was used to standardize the picked place name with the most similar one in the vocabulary. To make the correctness of standardization non-sensitive to the threshold value of similarity, a reinforcement learning model was added. All the experiments verified the proposals, and the respond of the dialog system to human instructions became more natural and meaningful. More work need to be done in collecting robot indoor instructions and improving the word embedding model.
杂志排行

Journal of Harbin Institute of Technology(New Series)的其它文章
- Initial Phase Properties and Anti-interference Capability of Memristor Models
- Research on the Evaluation System of Epoxy Asphalt Steel Deck Pavement Distress Condition
- Novel Logarithmic Non-Singular Terminal Sliding Mode and Its Application in Attitude Control of QTR
- Study on Thermal Deformation Measurement of Optical Remote Sensing Satellite Platform Based on Machine Vision
- State Estimation for Non-linear Sampled-Data Descriptor Systems: A Robust Extended Kalman Filtering Approach
- A Descriptor System Approach of Sensor Fault State Estimation for Sampled-data Systems