基于自编码器框架的自适应视频异常检测方法
2019-11-06蔡德秀杨大为
蔡德秀,杨大为
(沈阳理工大学信息科学与工程学院,沈阳 110159)
1 引 言
从视频中发现并检测出异常事件具有重要的意义,但视频中异常事件的定义通常比较模糊,比如,在餐厅内跑步是异常事件,但在公园跑步则是正常事件。一个人在地铁站台上走动是正常的,但一些人也可能因为某种理由认为他可疑,从而是异常的。再加之视频数据维度高,且存在噪声及大量事件交互,对异常事件的表示及建模构成了一定的挑战。
在行为识别领域有很多成功的案例[1-3],这些方法只适用于有标签的视频片段,其中感兴趣的事件是明确定义的,而且为每种类型事件贴上标签的成本非常高,也不能保证涵盖所有过去和未来的事件。近年来,人们将异常检测任务视为二分类问题(正常和异常)[4],证明了该方法的有效性和准确性,但由于异常事件的罕见性,很难获得异常事件的图像,因此此类方法的实用性受到了限制。很多研究人员转向了在很少或者没有监督的情况下的训练模型,包括时空特征[5-6]、字典学习[7]和自动编码器[8-9]。随着深度学习,特别是卷积神经网络在对象识别[10]、人脸检测[11]、动作识别等应用中的成功[12],使得深度学习的方法在异常检测中的应用越来越多。使用3D ConvNet 对异常进行分类[4,13],使用端到端的卷积自编码器来检测监控视频中的异常[14],证明了通过卷积层对视频进行学习表示的有效性。长短记忆(LSTM)模型以学习时间模式和预测时间序列数据而闻名[15-16]。
在此提出一种基于自编码器框架的自适应异常检测方法。利用ConvLSTM 网络模型构建编码器与解码器,分别用来学习视频序列的空间特征表示和重构视频序列,并基于重构误差,进行自适应的异常事件检测。
2 相关工作及其原理
RNN 的工作原理类似一个前馈网络,只是它的输入向量的值不仅受输入向量的影响,而且受整个输入历史的影响。从理论上讲,RNNs 可以在任意长的序列中使用信息,但在实现过程中,由于梯度的消失,它们只能返回几个步骤。为了克服这一问题,引入了RNN 的一个变种,长短时记忆(LSTM)模型,如图1所示。使用这种新结构,LSTMs 可以防止反向传播的误差弥散和爆炸,因此可以处理长序列,并可以将它们叠加在一起以捕获更高阶别的信息。

图1 典型LSTM 单元的结构
LSTM 架构的一个变体,卷积长短时记忆(ConvLSTM)模型,与通常的全连通LSTM(FC-LSTM)相比,矩阵运算被卷积所取代。通过对输入到隐藏连接和隐藏到隐藏连接使用卷积,ConvLSTM 要求更少的权重,并生成更好的空间特征图。该ConvLSTM单元的公式可概括为以下各式:
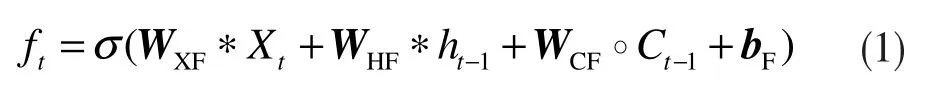
其中,ft为遗忘门的输出值,其决定从存储单元中删除或遗忘一部分信息,ht-1为上一时刻的输出值,Xt为当前的输入值,W 和b 分别是系数组成的矩阵和偏置的向量,σ 是激活函数sigmoid;
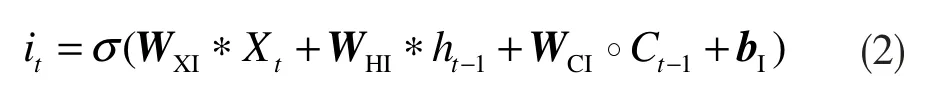
此式用来计算输入门的it值,以此决定更新多少信息,输出为0~1 之间的某个值;
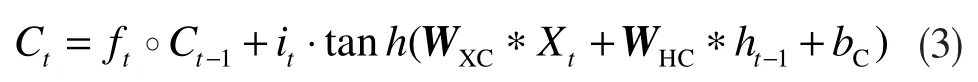
此式用来更新细胞状态,旧的细胞状态Ct-1与遗忘门输出值ft相乘,输出更新的后选值表达式与输入门it相乘,二者相加得到新的细胞状态Ct;
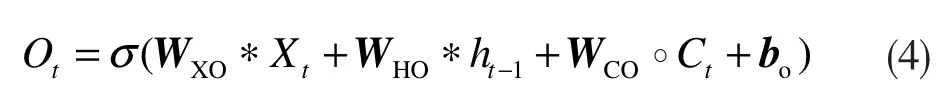
此式用来计算输出门output gate 的值Ot,它决定多大比例的记忆用于输出;

此最后一步是使用双曲正切函数更新Ct值,使其处于-1~1之间,将输出门值Ot与其相乘,得到t时刻的最终输出值ht。
以上各式中:∗表示卷积运算;°表示Hadamard乘积;Xt代表t时刻的输入图像;it代表t时刻的输入门输出信息;Ct-1代表t-1时刻记忆单元的信息;WHI是输入门到遗忘门的权值矩阵,其余矩阵依此类推。
3 异常检测方法
所提出的异常检测方法是基于这样的一个原则:当异常事件发生时,当前视频帧与先前视频帧将有明显的不用。据此,训练一个端到端模型,该模型由一个空间特征提取器和一个时间编码-解码器组成,它们共同学习输入视频序列的时间模式。该模型只训练由正常场景组成的视频,目的是最小化学习模型重建的输入视频与输出视频之间的重构误差。对于模型进行适当的训练后,期望正常的视频量具有较低的重构误差,而期望包含异常场景的视频具有较高的重构误差。通过对每个测试输入视频产生的误差进行阈值化,可自适应地检测出异常事件。
3.1 数据预处理
预处理的任务是将原始数据转化为模型可接受的输入。从原始视频中提取出来每一帧图像都调整为统一尺度n×n(在此采用224×224),并进行归一化处理,即以每帧图像减去视频中所有图像的均值。模型的输入是视频卷,即连续的T帧图像序列。
3.2 特征学习的自编码器网络
基于自编码器框架来学习训练视频中的规则模式,由两部分组成,即用于学习每个视频帧的空间结构的空间自动编码器和用于学习时间结构的时间编码解码器,网络结构如图2所示。空间编码器和解码器分别由两个卷积层和反卷积层组成,而时间编码解码器是由一个三层卷积LSTM模型构成。
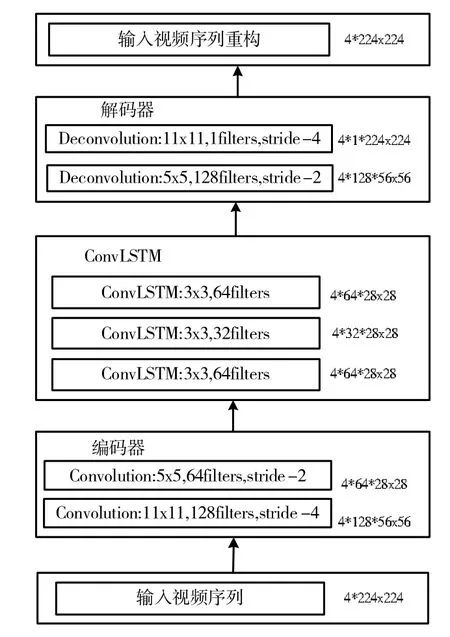
图2 特征学习自编码器网络结构示意图
它取一个长度为T的序列输入,然后输出重构的输入序列。最右边的数字表示每个层的输出大小。空间编码器每次取一帧作为输入,处理T=4帧后,将T帧的编码特征串接到时间编码中进行运动编码。解码器镜像编码器来重构输入的视频卷。
自编码器由两部分组成:编码和解码。它通过设置编码器输出单元的数量小于输入来降低维数,并采用无监督的反向传播方法训练,最大限度地减小解码结果的重构误差。由于选择的激活函数是非线性的,自动编码器可以提取出比一些常用的线性变换方法(如PCA)更有用的特征。
卷积网络中卷积的主要目的是从输入图像中提取特征。卷积网络在训练过程中会自动学习滤波器的值,但训练前需要指定滤波器的个数、大小、层数等参数。随着滤波器数量的增加,可以提取更多的图像特征,网络的识别性能也变得越来越好。但更多的滤波器会增加计算时间并更快地耗尽内存,应用中需要合理设置来达到精度与速度的平衡。
3.3 规律分数
训练好的模型可用于获得输入视频序列的重构。重构误差由下式表示:
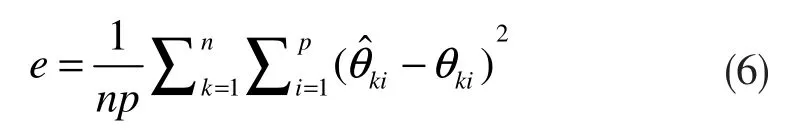
基于误差值计算视频的规律性分数。规律分数将每个视频序列的重构误差归一化到0和1之间。序列的规律分数如下式所示:
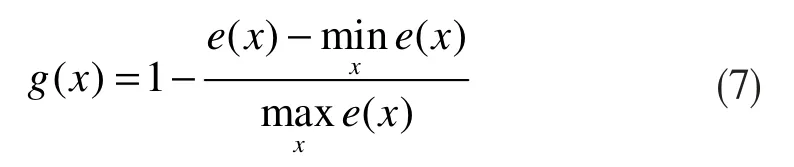
其中,x是输出的重建序列,e(x)是该序列的重构误差。包含正常事件的视频序列具有较高的规律分数,因为它们与用于训练模型的数据类似,而包含异常事件的序列具有较低的规律分数。
3.4 自适应的异常事件判定
通过对每个测试输入视频帧产生的重构误差进行阈值化得到规律分数,就可以判断一个视频帧是正常还是异常的。每一帧的规律分数决定了该帧是否属于异常。阈值决定了检测系统的行为有多敏——例如,设置一个较高的阈值会使系统对场景中发生的事情变得敏感,从而触发更多的警报。由规律分数自适应地设置阈值,这样就不会出现过多的误警误报的信息。自适应设置阈值的过程如下式:
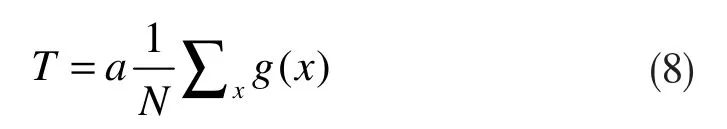
其中a是调节参数,N是视频的总帧数,g(x)是规律分数。
阈值设定之后,出现异常的部分被标记红色阴影,异常事件计数。为了减少规律分数的噪声和无意义的极小值,使用固定时间窗W(此处取50)帧的局部极小值进行分组。假设W帧内的局部极小值属于同一异常事件,这是一个合理的时间窗口长度,作为一个异常事件应该至少2~3秒长才有意义。(视频以24~25帧/秒的速度捕捉)。
4 实验结果与分析
为了验证本算法的有效性,在通用数据集上进行了实验。采用的数据集包括Avenue、UCSD Ped1和ped2。所有的训练视频只包含正常的事件,测试视频则既有正常事件,也有异常事件。
Avenue dataset 中共有16 个训练视频和21 个测试视频,每段视频的时长为1~2 分钟之间不等。正常的场景是人在楼梯和地铁入口之间行走,异常的场景包括是人在奔跑、朝相反方向行走等。UCSD Ped1 数据集包括34 个训练视频和36 个测试视频,每个视频包含200 帧。这些视频由一群人走向和离开摄像机组成。
模型训练的目的是最小化重构误差。实验得到的误差结果如图3所示。
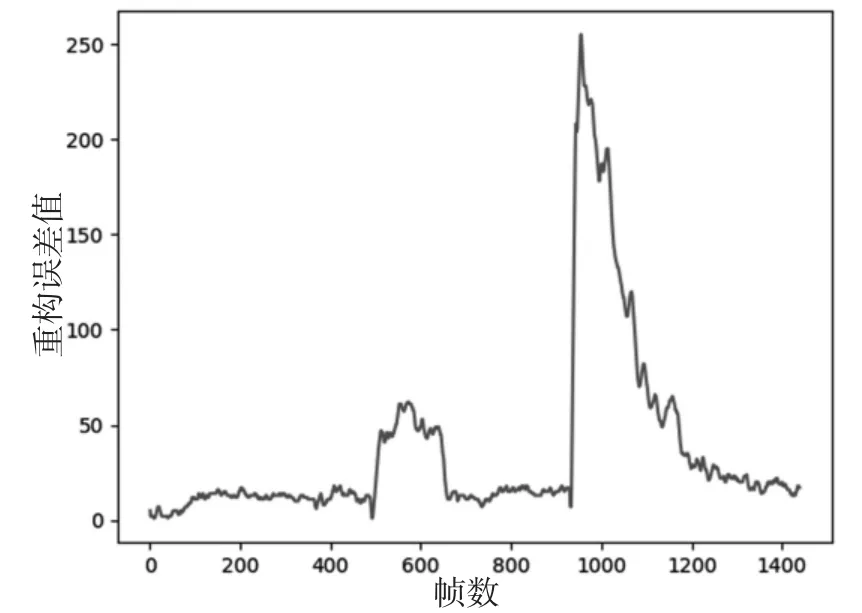
图3 视频序列的重构误差
图中结果来自于avenue dataset#01testing video经过训练好的网络模型重构视频帧的重构误差。正常的视频帧具有较低的的重构误差,而包含异常情况的视频帧具有较高的重构误差。
由重构误差归一化得到对应的规律分数,图3曲线所对应的规律分数曲线如图4所示。当出现不规则运动时,规律分数显著下降。
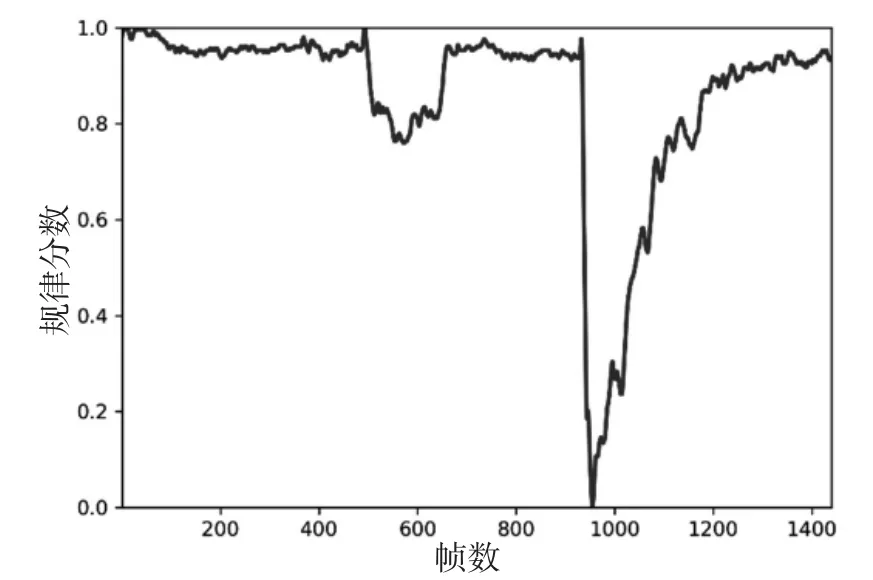
图4 视频序列的规律分数
直接设置阈值,异常检测系统根据规律分数和阈值的大小判断是否出现异常。图5为此设置下的的avenue dataset#01testing video 异常检测结果图,红色(阴影)区域表明视频中出现异常。视频中只能检测出一个异常情况,而且检测出异常的区域变窄,这说明检测异常出现和消失的时间点不是很准确,还存在漏检的可能。
采用自适应设置阈值,根据规律分数,按照自适应的异常事件检测准则,即可检测出视频中的异常事件,图6为相应的avenue dataset#01testing video异常检测结果图,红色(阴影)部分就是原视频中出现异常的部分,有两个异常情况被检测出来,分别为[508,648]帧和[936,1176]帧之间。可见,异常检测系统的能力有了明显提高。
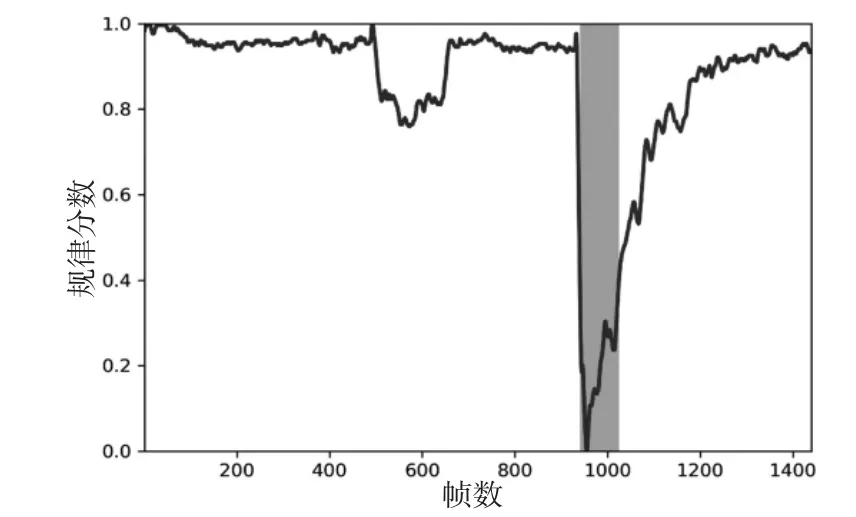
图5 avenue dataset#01 异常检测(直接设置阈值)
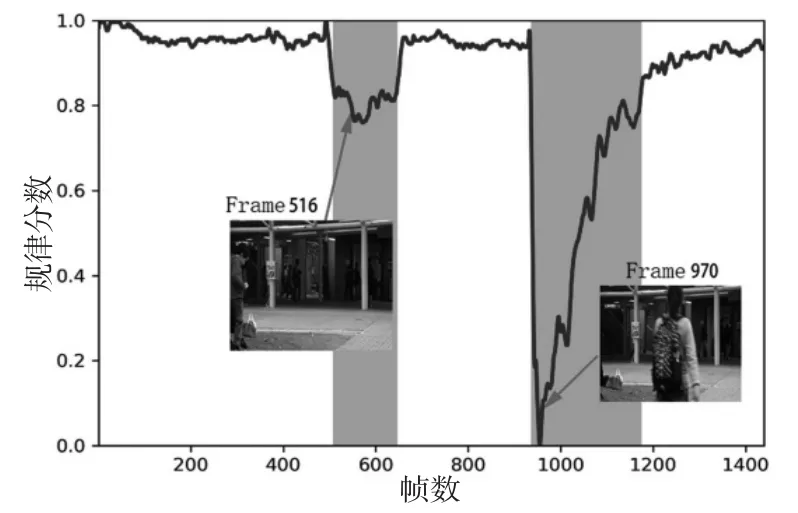
图6 avenue dataset#01 异常检测(自适应设置阈值)
直接设置阈值也有可能出现检测错误,将正常情况被判为异常。图7为直接设置阈值时的avenue dataset#04testing video 异常事件检测结果图,图中检测出两个异常情况,与实际出现异常的情况相差极大,第一异常情况从第1 帧开始持续到了第742帧;第二个异常情况发生在第884 帧到第935 帧。相比之下,采用自适应设置阈值,异常检测结果如图8所示,异常区域有三处,帧数区间分别在 [1,137]、[361,464]、[649,740],第一处的异常是由拍摄视频的摄像头抖动导致规律性分数特别低,第二、三处的异常情况是有人在奔跑。

图7 avenue dataset#04 异常检测(直接设置阈值)
实验结果表明,对于不同的数据集,模型能够自适应地检测视频中的异常情况。不断调整自适应阈值,检测效果会越来越好。如图8所示,出现异常时,规律分数有较明显的下降,出现异常的区间内,规律分数一直较低,一旦异常消失,规律分数便回升正常阈值之上。阈值决定了异常检测系统的性能,例如,设置较高的阈值会使系统对场景中发生的事情变得敏感,从而触发更多的误报;设置较低的阈值会使系统检测异常时对真正的异常漏报。相比之下,自适应设置阈值,可大大提高异常检测体系的性能。
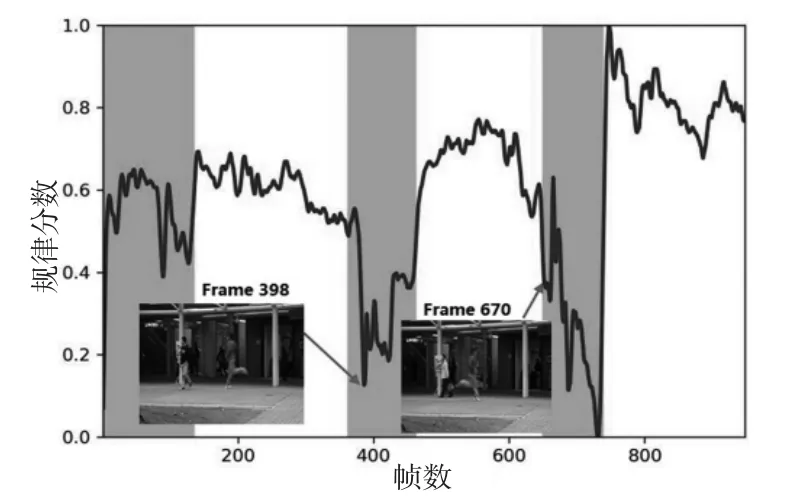
图8 avenue dataset#04 异常检测(自适应设置阈值)
5 结 束 语
提出的这种基于自编码器模型的自适应视频异常事件检测方法,其自编码器中的ConvLSTM 层不仅保留了FC-LSTM 的优点,而且由于其固有的卷积结构,也适用于时空数据。将卷积特征提取器结合到编码解码结构中,成功建立起视频异常检测的端到端可训练模型。以该网络模型来重构输入帧序列,并利用输入与重建帧之间的重构误差进行自适应异常检测,大大提高了系统异常检测的能力。
