基于Scrapy的招聘信息爬虫设计与实现
2019-11-04鲁丰玲
鲁丰玲

摘 要:随着互联网发布的各种数据在急剧增长,人们正常进入网站精确获取信息的速度较慢而且信息量较小,按照一定的规则编写的计算机指令——网络爬虫应运而生,它可以在较短的时间内从网络上自动抓取大量数据信息。该文研究的是基于Scrapy框架的一种招聘信息主题网络爬虫的设计与实现。主题网络爬虫只搜索与主题信息有关的资源数据,用来服务于高校毕业生群体,作为就业前收集招聘信息的辅助手段。
关键词:Python 网络爬虫 主题网络爬虫 网页信息抓取
中图分类号:TP393.092 文献标识码:A 文章编号:1672-3791(2019)07(b)-0007-04
Abstract: With the rapid growth of various data released by the Internet, people normally enter the website to obtain accurately information is Comparatively slower and the amount of information is less.The computer instructions written according to certain rules——web crawlers came into being, it can be shorter Automatically grab large amounts of data from the network during the time. This paper studies the design and implementation of a recruitment information topic web crawler based on the Scrapy framework. The theme web crawler only searches for resource data related to the topic information, which is used to serve the college graduates as an auxiliary means of collecting recruitment information before employment.
Key Words: Python; Web crawler; Topic web crawler; Web page crawling
随着网络技术与新媒体技术的快速发展,互联网产生的数据也在快速增长,人们也越来越注重数据的意义,重视研究数据挖掘的价值。传统的人工数据采集方法,因样本小、误差大等因素,已经无法满足高质量分析的需求,在信息迅速膨胀的时代,网络爬虫就备受人们追捧,成为当下信息采集数据挖掘的主要方式之一。一些学者提出:互联网上60%的流量都是由网络爬虫带来的[1]。
1 网络爬虫简介
1.1 网络爬虫
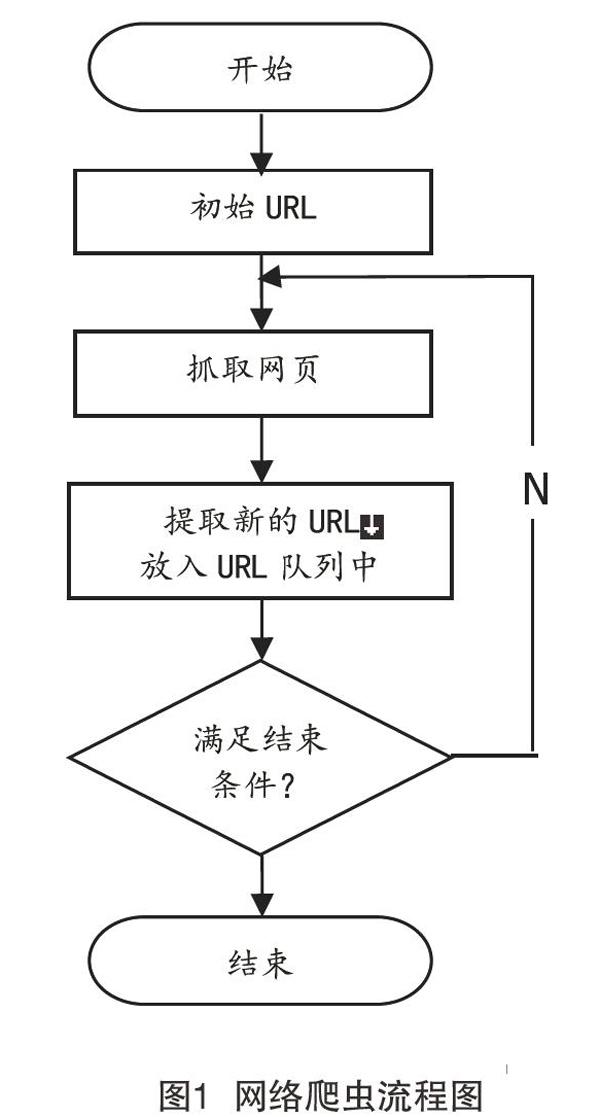
网络爬虫是一种用于抓取Web信息的计算机程序或指令脚本[2],它遵循某些特定的规则,可以从网络上自动获取所需要的信息,可以理解为网络上的“机器人”[3],它有多个名字,如Web信息收集器、Ant、自动索引、蠕虫等,有时也被称为网页蜘蛛。网络中的每个网页都有与其对应的唯一URL链接地址,网络爬虫从指定的某个URL出发,开始向目标网站发出请求,服务器正常响应后访问相关联的所有页面的URL,从中提取该页面有价值的数据,这些数据可以是字符串、HTML等类型,并且把符合需求的URL添加到请求队列中,从而构成新的URL请求列表,接着进行下一轮的访问提取工作,直到爬虫搜索完整个URL队列页面,或者满足结束条件时结束访问,爬虫工作的基本流程如图1所示。
1.2 主题网络爬虫
主题网络爬虫是根据指定的主题,只搜索抓取与主题相关的网站页面,因而大大提高爬取速度,获取的网页有针对性,保存数量减少,可以节省大量的网络资源,完全可以满足特定人员对某种特定域信息的需求[4]。主题网络爬虫之所以能实现对特定信息的获取,在于它对网页目标主题相关度的计算及筛选[5],这是主题爬虫的优势所在。网页主题相关度的计算方法可以按照计算分析具体内容的不同分为3类:基于网页内容的算法、基于链接结构的算法、基于综合价值的算法。
2 Python语言简介
2.1 Python语言
Python是解释型、面向对象的计算机开源编程语言,语法规则简单,有“功能齐全”的标准库和强大丰富的第三方库支持,其中如Requests库、Urllib库、Scrapy库等均可以用来编写爬虫[6],其中Scrapy库的使用最普遍。Python具有极好的可扩展性,可以实现动态编程。它可以与用其他编程语言(如C/C++和Java)生成的各种模块很容易地接口,拥有强大的HTML语言解析器和网络支持库,运用Requests网络支持库通过少量代码的编写就可以下载网页,运用Beautiful Soup网页解析库可以轻松从HTML或XML网页中解析各个标签,并快速提取页面内容。在实际应用中,利用Python语言构建的程序原型,甚至包括原型的用户界面,如果有一些要实现特别的功能需求,还可以改用另外的计算机语言去编写,因此,它常被称为胶水语言[7]。Python语言很容易学习使用,可移植的性能使它对开发平台没有很高的要求。
2.2 Scrapy框架
Scrapy框架是Python开发的、用来爬取网页信息的框架,它是基于Python爬虫开发中使用最广泛的框架,可以应用于数据挖掘、数据监测以及信息处理等方面。Scrapy框架主要由以下组件构成:引擎(Scrapy Engine)、調度器(Scheduler)、爬虫(Spiders)[8]、下载器(Downloader)、项目管道(Item Pipeline)、Spider中间件(Spider Middlewares)、下载器中间件(Downloader Middlewares)[8]。
2.3 Scrapy框架的工作流程
在Scrapy框架中引擎处于框架的中心位置,控制各组件间的数据流向,它爬取的工作流程简要如下。
(1)确定要抓取的目标网站之后,由爬虫发出要处理的第一个URL信息请求,请求被发送到引擎。
(2)引擎接收到请求信号,通知调度器把与爬取主题相关的页面请求送入队列。
(3)调度器收到来自引擎的请求信号,按照某种方式将请求信息整理后放入URL队列,待到有需要时再重新交还给引擎,与此同时,调度器将下一个待爬取的URL传送给引擎,引擎将URL通过下载中间件转发给下载器。
(4)下载器获得Requests请求后根据指令从页面上获取数据,抓取的响应交还给引擎。
(5)引擎从下载器中接收到响应信号,通过Spider中间件转交给爬虫去处理。
(6)爬虫分析獲取的响应信息,把item字段所需要的数据信息提取出来,交给项目管道去下载,并返回爬取到的项目内容及需跟进新的URL请求给引擎。
(7)引擎通知项目管道处理获取到的数据,项目管道接收到爬虫传递的数据,并对这些数据进行清理、验证及存取等处理。
(8)引擎通知调度器跟进新的URL,调度器获取到URL,重复以上操作,直至调度器里URL队列为空时,结束爬虫运行[9]。
3 基于Python的招聘信息主题爬虫的分析、设计与实现
3.1 招聘信息主题爬虫的分析
该文的招聘信息主题爬虫划为分类模块、爬虫模块、提取模块3个部分。其中分类模块用来分析提取URL信息,该模块侧重于参照网页参数判断招聘主题的相关性,使用正则表达式和值来判断招聘主题的相关性,评估分析网页URL的信息提取价值,并且给出与之相应的搜索次序[10];爬虫模块功能在于实施招聘主题信息网页的抓取,在满足爬取规则的范围内抓取符合招聘主题信息的网页数据,将抓取的网页数据存入到数据库中并为它们建立索引,根据用户输入的关键字,从数据库中查询符合用户需求的数据页面并把它们取出;提取模块指出抓取页面的顺序,提取招聘主题网页的内容,下载页面源代码,该模块中主要涉及主体内容和网页源代码的提取。
3.2 招聘信息主题爬虫的设计
3.2.1 创建Scrapy新项目
编写网络爬虫,第一步建立一个Scrapy项目文件,在CMD窗口中运行更改目录的命令,把当前位置切换到将要用于保存爬虫代码的文件夹中,运行命令“scrapy startproject 自定义爬虫名称”,文件夹中会自动创建爬虫的项目框架。该项目文件夹里的内容包括:项目配置文件、python模块、item文件、pipelines管道文件、设置文件和爬虫目录文件夹等几个部分。
3.2.2 定义Item容器
为已爬取的网络数据定义用于保存的容器,与python字典的使用方法相似,而且定义Item容器为消除由于拼写错误带来的麻烦,增加了额外保护机制。根据实际需要在item.py文件中对提取的数据定义相应的字段,比如网站的标题、网站的描述、网站的链接等。
3.2.3 编写爬虫
爬虫程序用于爬取网站信息,它的实现内容包含有初始下载的链接地址即URL列表、后续跟进网页的URL链接、判断网页内容是否与主题相关、采用何种算法、提取数据生成item的方法,具体程序内容是用户自己编写的类。
编写爬虫时首先要观察网页明确需求,该文选用招聘信息主题网站前程无忧51job网站的职位搜索列表页面,开发前先进行数据分析:分析招聘主题信息爬虫要爬取的数据信息包括职位名、公司名、工作地点、薪资、发布时间等;观察51job页面的源代码和页面结构。通过观察51job页面的源代码和页面结构,发现页面主题部分有用的信息数据都由div区分,因此提取数据时使用XPath方法解析相对方便。
用户在创建自定义爬虫时,必须继承scrapy.Spider类的属性与方法,它还应该定义3个属性:name属性(不同的spider必须设置不同的名称以区别其他爬虫)、start_urls属性(包括爬虫开始时的URL列表)和parse()回调函数。其中回调函数,在下载器返回响应对象Response时就会被调用,当下载完初始URL后,生成的响应对象Response被作为参数发送回parse()函数。此属性用来解析返回的数据、提取数据、对需要进一步访问提取数据的URL链接生成的请求对象Request。在这里选用的是,在51job网站进行职位搜索“平面设计师”及工作地点定位于“河南”地区的列表页面URL作为起始start_urls。
3.3 招聘信息主题爬虫的运行
3.3.1 运行爬虫爬取数据
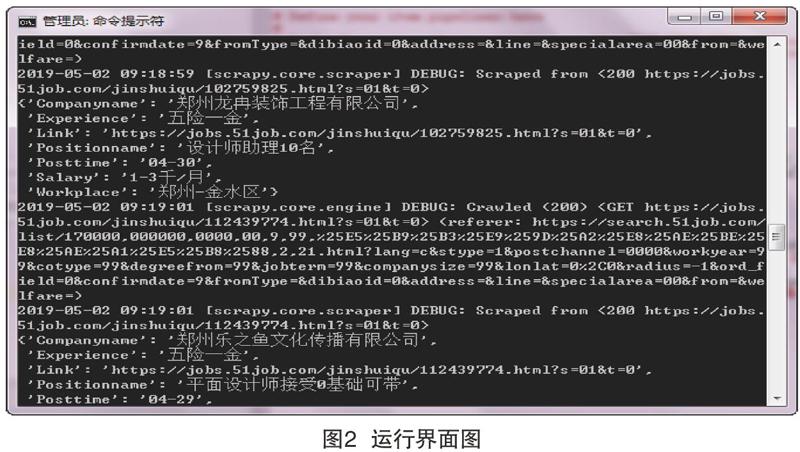
通过“cd 自定义爬虫名称”命令进入到爬虫项目文件夹根目录中,运行启动爬虫的命令“scrapy crawl 自定义爬虫名称”,Scrapy为爬虫的start_urls属性中的每个URL链接创建对应的响应对象Response,为创建的响应对象指定回调函数prase(),接着调度响应对象、执行下载器程序,执行完成后生成响应对象,最后把响应对象反馈到Spider类。在主题爬虫的运行过程中,首先收集与主题相关的页面并将其称为URL种子集,然后从种子页面开始,将与主题相关度大的URL链接放入等待队列,减少无关网页的下载带来的消耗,确定每个链接的优先级。运行过程中的界面如图2所示。
3.3.2 存储内容
由于该文选用的是前程无忧51job网站,将爬取筛选后的数据存放到item中,运用Scrapy框架里包含的Feed exports命令可以很方便地导出文件,保存爬取到的信息。但是该文提取招聘信息的目的是为了方便服务学生,因而最终希望将爬取的信息数据导出到Excel文件中。Python丰富强大的库中有专门处理Excel文件的库,如xlrd、xlwt、xlutils、openpyxl等库。其中xlrd库用来读取Excel格式文件;xlwt库是针对Excel格式文件的创建、格式的设置、数据的写入、文件的保存等操作进行处理;xlutils库对Excel格式的文件既可以读取,又可以写入、修改。这里选用的是openpyxl库,这是一个比较简单的第三库,它可以用来处理xlsx格式的Excel文件,只需要先实例化一个Workbook对象,然后用save()方法保存即可,运行结果如图3所示。
3.3.3 结果分析
从以上运行的结果可以看出,Excel文件中爬取的内容都是近期发布的、想要搜索的“河南区域”范围内的“平面设计师”招聘信息,搜集的数据基本符合所要查询职位的相关信息,但也出现了个别数据不确切的情况,基本可以满足学生就业查询的需求,整体来看影响不大。在今后的实际运行过程中可以更换起始页面的URL信息,来爬取其他就业岗位的相关招聘信息,以服务更多不同专业需求的学生。因此,招聘信息主题爬虫技术可以作为服务于毕业生的技术手段,帮助其以快速获取相关专业的各类招聘信息。
4 结语
网络信息资源充盈的今天,网络信息的获取工作十分重要,该文主要从网络爬虫、Python语言与Scrapy框架几个方面进行阐述,简单介绍了招聘信息主题网络爬虫的工作流程、开发与实现,希望所抓取的数据信息能够服务于院校毕业生的就业工作。与一般的爬虫技术相比,主题网络爬虫有明显的精确性特征,可以精准地搜索与主题相关的网页信息,增强了网络搜索的实效性。但是,由于主题爬虫要根据主题信息进行相关度数据分析,会产生诸多等待时间,因此主题网络爬虫的搜索技术仍有很大的改善空间,比如采用多进程、多线程等主题爬虫来提高爬取信息的效率。在今后的研究工作中,继续改进招聘信息主题爬虫的设计,完善有关功能,提升爬取数据的效率,经常关注招聘信息网站的更新,以期更好地为学生就业工作提供更多的帮助。
参考文献
[1] 韩贝,马明栋,王得玉.基于Scrapy框架的爬虫和反爬虫研究[J].计算机技术与发展,2019(2):139-142.
[2] 洪芳.基于Selenium2的Web UI自動化测试框架的设计与实现[D].西南交通大学,2017.
[3] 刘杰,葛晓玢,闻顺杰.基于Python的网络爬虫系统的设计与实现[J].信息与电脑:理论版,2019(12):92-93,96.
[4] 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术,2010(15):4112-4115.
[5] 薛丽敏,吴琦,李骏.面向专用信息获取的用户定制主题网络爬虫技术研究[J].信息网络安全,2017(2):12-21.
[6] 魏冬梅,何忠秀,唐建梅.基于Python的Web信息获取方法研究[J].软件导刊,2018,17(1):41-43.
[7] 郭丽蓉.基于Python的网络爬虫程序设计[J].电子技术与软件工程,2017(23):248-249.
[8] 刘宇,郑成焕.基于Scrapy的深层网络爬虫研究[J].软件,2017,38(7):111-114.
[9] Qingzhao Tan,Prasenjit Mitra.Clustering-based incremental web crawling[J].ACM Transactionson Information Systems(TOIS),2010,28(4):85-89.
[10] 方星星,鲁磊纪,徐洋.网络舆情监控系统中主题网络爬虫的研究与实现[J].舰船电子工程,2014,34(9):104-107.
