一种Hadoop平台流量监控系统设计
2019-11-04长江大学电子信息学院湖北荆州434023
(长江大学电子信息学院,湖北 荆州 434023)
随着云计算的飞速发展,节点数量日益增多,节点的管理难度也逐渐增加。目前,适用于云平台的开源监控系统有MRTG、Cacti、Nagios、Ganglia、Zabbix等[3~6]。其中,MRTG、Cacti和Ganglia无报警机制,集群故障无法及时通知运维人员;Nagios无采集流量数据功能,且报警方式单一,其数据可视化需要借助外部插件实现,插件易用性差;Zabbix随着监控数据的增大会使数据库的写入成为瓶颈,后期开发要求高。但与上述其它监控系统相比,Nagios具有如下监控优点:跨平台、接口标准化、提供异常报警功能、出错的应用会自动重启、配置灵活、可监控400多台主机[7]、采用分布式监控增加监控数量、使用插件监控方便了用户二次开发和维护、采用适当的监控策略和检测方式即可降低监控系统负荷、提高监控效率;所以笔者在Nagios监控系统的基础上,结合MRTG设计了一种Hadoop平台流量监控系统。该系统以流量作为主要的监控对象进行研究,易于实现和开发,可以实时监控多种对象并提供多种报警方式,满足Hadoop云平台的监控要求。
1 相关技术原理
1.1 Hadoop原理
Hadoop是一个开源的分布式处理框架[8,9],能够让许多计算机一起工作。Hadoop的核心组件有HDFS[10](hadoop distributed file system)和MapReduce[11]。
HDFS是分布式文件系统,具有大存储量、高容错性、高吞吐量、高可扩展性、负载均衡等特点[12]。
MapReduce是并行计算框架,其为Hadoop提供文件的并行计算,将一个任务分解为多个子任务进行处理,简化了并行处理模式,程序员只需要告诉计算机对数据划分的方法即可,其他任务由系统自动完成。
1.2 Nagios监控原理
Nagios是一个可以运行在Linux、Unix和Windows操作系统上的开源监控框架[12],用户可根据需求编写插件来完成监控或通过端口号来监控。如在临床IT系统上部署Nagios监控系统,可以利用端口号对特定放射科的协议进行监控[13]。
Nagios对远程主机的监控需要借助NRPE(nagios remote plugin executor)[14]组件。它由check_nrpe插件和NRPE守护进程2部分组成,check_nrpe插件位于监控主机(monitoring host)上,NRPE守护进程位于远程被监控主机(remote linux/unix host)上[15](见图1)。
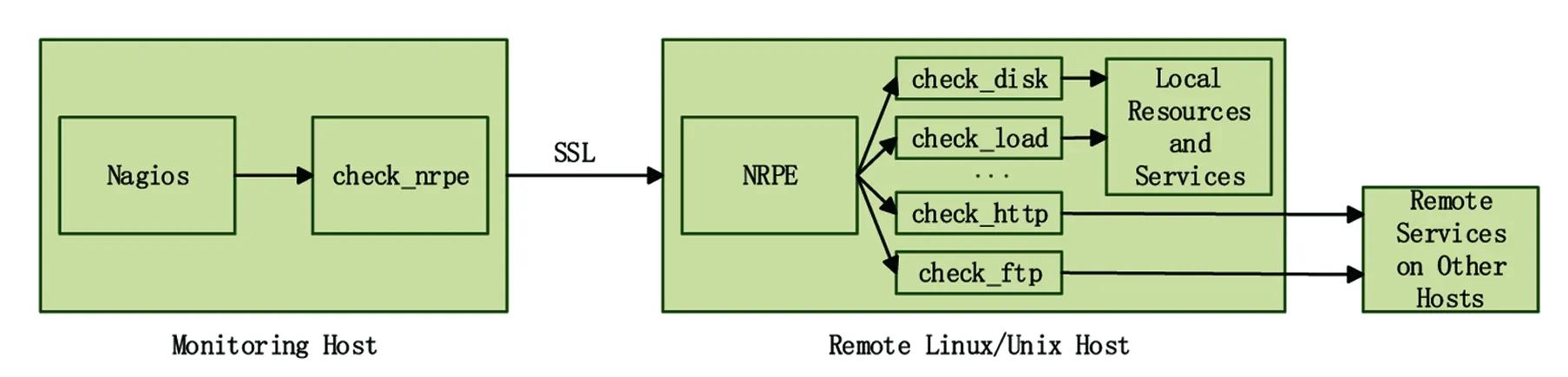
图1 NRPE的监控原理图
Nagios检测有“OK”“WARNING”“CRITICAL”“UNKNOWN”4个返回值,分别表示状态正常、异常、严重错误、未知错误或监控停止。Nagios根据插件返回值来判断监控状况,并通过Web显示出来,在监控到问题时,会根据定义的方式进行报警,这也是Nagios比较重要的一个功能。
随着我国基本医疗保险(简称医保)覆盖范围不断扩大,百姓对医保的要求逐渐提高,医院作为医保制度运行和管理的中心环节,是医、保、患三方矛盾集中及激化的焦点[1],致医疗保险相关投诉事件居高不下,是医院投诉管理的重点。PDCA循环是一种科学管理模式,按照计划(plan,P)、实施(do,D)、检查(check,C)、处理(action,A)顺序进行质量管理,其科学性、程序性及有效性均受到医院管理者的普遍关注[2-3]。PDCA循环是提高医保质量管理的重要手段,对门诊医保投诉管理有着重要的作用。
Nagios的监控方法通过配置文件确定,表1给出了必要配置文件及文件的作用,用户还需要创建service.cfg和host.cfg这2个文件,用来配置远程主机的监控方法。

表1 Nagios必要配置文件及用途
1.3 MRTG监控原理
MRTG是一个监控网络链路流量负载的软件[16],通过简单网络管理协议SNMP(simple network management protocol)获取设备的流量信息,并将流量负载以包含PNG(portable network graphics)格式的HTML(hyper text markup language)文本方式显示给用户。
SNMP是一种应用层协议,由网络设备、管理组件、代理Agent组成。SNMP运行在UDP之上,利用的是UDP的161/162端口。其中,161端口被代理Agent监听,等待管理组件发送管理信息;162端口由管理组件监听,等待代理Agent发送异常事件报告。
1.4 OneAlert报警技术
OneAlert[17]是国内首个SaaS模式的云报警平台,集成国内外主流监控/支撑系统,具有以下功能:在一个平台中接收所有监控系统的报警,让运维人员集中处理IT事件,避免多平台切换,提升运维效率;通过机器学习算法压缩报警,让运维人员快速定位报警根源,避免报警风暴;灵活的报警分派策略,在合适的时间,把报警推送给最合适的人员;QQ、微信、邮件、短信、电话多个渠道接收事件提醒;全面的报警分析能力,让运维人员快速直观地了解报警频发根源,提升团队运维效率。
2 监控系统设计
在基于Hadoop的PaaS(platform as a service)公有云模型[18,19]的环境下,设计了Hadoop平台的Nagios监控系统架构,在主节点hadoop1上安装有check_nrpe和NagiosPlugins,在2个从节点hadoop2、hadoop3上安装的有NRPE Daemon和Nagios Plugins,Nagios Plugins提供了许多监控插件,如check_disk、check_http等(见图2)。
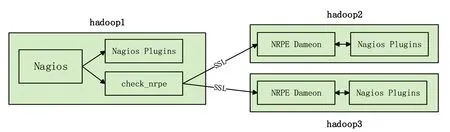
图2 Nagios的监控架构
当Nagios监控Hadoop集群的服务或资源时,需要进行以下步骤:
1)Nagios将会执行hadoop1上的check_nrpe插件,并告诉它什么服务需要监测;同样,也会执行Nagios Plugins中适当的插件监测本地服务或资源;
2)插件check_nrpe将会联系远程主机hadoop2、hadoop3上的NRPE Daemon;
3)NRPE Daemon调用Nagios Plugins中适当的插件监测服务或资源;
4)将hadoop2、hadoop3监控的数据传递到NRPE Daemon。
2.1 流量监控
由于Nagios自身无法采集流量数据,因此笔者使用MRTG来采集集群的流量数据,再通过Nagios插件check_mrtgtraf来获取流量数据并监控。采集流量数据的MRTG安装在hadoop2上,通过SNMP采集集群节点的流量数据并存储,Nagios执行check_nrpe插件,调用远程主机上的check_mrtgtraf插件来读取流量数据并处理生成Web页面(见图3)。根据Nagios和MRTG的监控原理,MRTG可以安装在Hadoop集群中的任意一个节点上。如果MRTG安装在hadoop1上,就需要hadoop1从其他节点上采集流量数据,这样Nagios和MRTG的进程都在hadoop1上,从而加大了hadoop1的负荷;如果MRTG安装在hadoop2或hadoop3上,Nagios只需要运行NRPE来调用hadoop2或hadoop3上的check_mrtgtraf插件来获取流量数据,这样就把对流量的采集工作交给了hadoop2或hadoop3,从而减轻hadoop1的负荷。
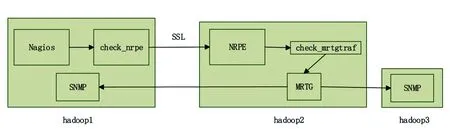
图3 Hadoop平台的流量监控原理图
2.2 报警模块
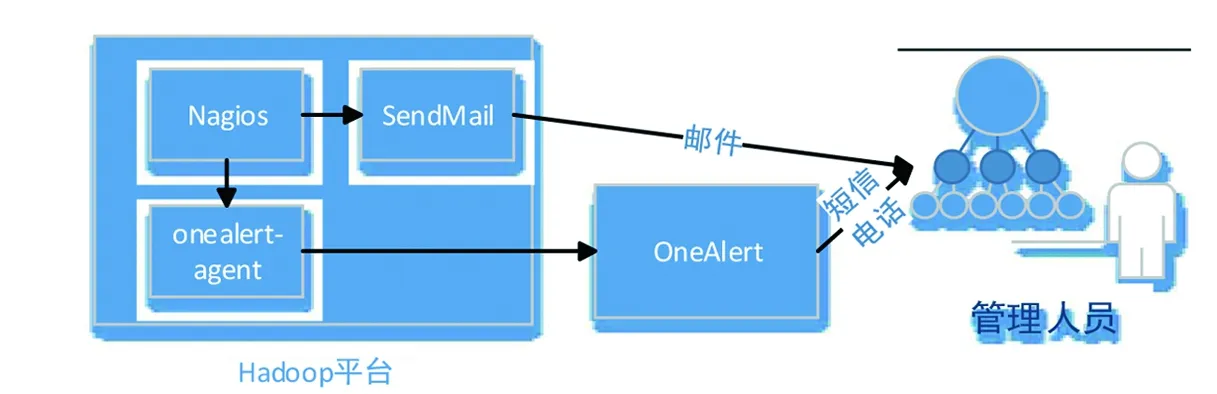
图4 报警模块原理图
利用SendMail组件和OneAlert平台设计一个多方式报警模块,如图4所示。SendMail和onealert-agent安装在监控主机上,其中,Nagios通过SendMail以邮件的方式向管理人员发送报警信息;OneAlert平台通过onealert-agent将Nagios的报警事件集成至OneAlert,实现统一压缩合并、分派和通知。该模块在发送一条报警信息后,只有报警状态被维护人员取消或在一段时间(默认30min)后才会再次在满足条件时发送报警信息。
3 结果与分析
利用VMware Workstation软件,创建了3台配置为单核、1G+20G的虚拟机,并使用Centos6.6作为虚拟机的操作系统来搭建一个拥有3个节点的Hadoop集群;1个IP为192.168.1.61的主节点(hadoop1)和2个IP分别为192.168.1.62、192.168.1.63的从节点(hadoop2、hadoop3)。参照文献[8]搭建Hadoop集群,在主节点上启动集群,通过http://192.168.1.61:50070查看Hadoop集群的HDFS情况,通过http://192.168.1.61:8088查看集群的MapReduce情况。
在主节点hadoop1上先后安装Nagios框架[20]和NRPE,进入Nagios安装目录配置Nagios文件[21~23],Nagios检测策略为:状态正常时以频率fn检测,状态异常时以频率fan连续检测nc次,然后检测频率恢复为fn。检测状态返回值为:状态正常值为“OK”,状态异常值以最后一次的检测结果评定为“OK”、“WARNING”或“CRITICAL”。设置fn=0.2次/min,fan=1次/min,nc=3。然后安装可视化模块PNP4Nagios[24],PNP4Nagios以前一次检测时间为起点,本次检测时间为终点的方式绘制检测曲线,检测曲线将实时显示Nagios检测数据。
在主节点上配置Nagios报警模块[20],在OneAlert官网注册一个账号,登陆后按以下步骤配置:选择Nagios标签页进入其配置界面,然后创建Nagios应用,设置报警时间间隔30min,获取Nagios应用的key值。在hadoop1上安装onealert-agent,在安装目录配置110monitor.cfg中pager为Nagios应用的key值;在contacts.cfg中添加联系人“110monitor”;在nagios.cfg的最后一行添加cfg_file=/usr/local/nagios/etc/objects/110monitor.cfg。上述配置完成后,可实现报警功能,Nagios的报警机制为:当监控数据超过Warning门限值且低于Critical门限值时返回WARNING并发送WARNING报警信息,当监控数据超过Critical门限值时返回CRITICAL并发送CRITICAL报警信息。

图5 localhost的流量配置内容
在从节点上安装和配置MRTG[25,26],service.cfg为系统默认配置,localhost.cfg按照图5所示格式配置。其中,“hadoop1”是被监控主机名,check_local_mrtgtraf是监控流量的插件;“usr/local/mrtg/share/192.168.1.61_2.log”是MRTG日志文件的路径;“2”表示虚拟机网卡eth1的端口;“AVG”表示平均带宽统计数据;“100,100”表示输入输出流量的Warning门限(单位为B/s);“200,200”表示输入输出流量的Critical门限(单位为B/s);“10”表示MRTG日志10min没有更新数据时插件将会返回CRITICAL状态。为验证流量监控报警功能,设置的报警门限值较低,实际应用可按需求设定。
3.1 监控结果
访问http://192.168.1.61:78/nagios查看Nagios对Hadoop平台的监控结果(见图6)。在对应Last Check时刻,hadoop1为UP开启状态,hadoop2、hadoop3为DOWN关闭状态,据此可统计出Hadoop平台中节点开启和关闭的个数。

图6 Hadoop集群的监控界面
1)hadoop1的详细情况。图7是hadoop1在执行pingbaidu.com命令时,监控对象的监控数据及状态(流量为报警状态WARNING,其余监控对象状态为OK),图8是取消ping命令且关闭部分进程时,流量报警解除的监控界面(所有监控对象状态为OK);据此可知每个监控对象的工作状态为“OK”、“WARNING”或“CRITICAL”,还可得出每个节点资源的利用率。
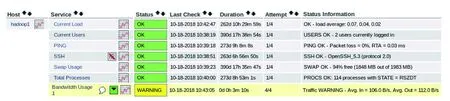
图7 hadoop1节点的监控界面1
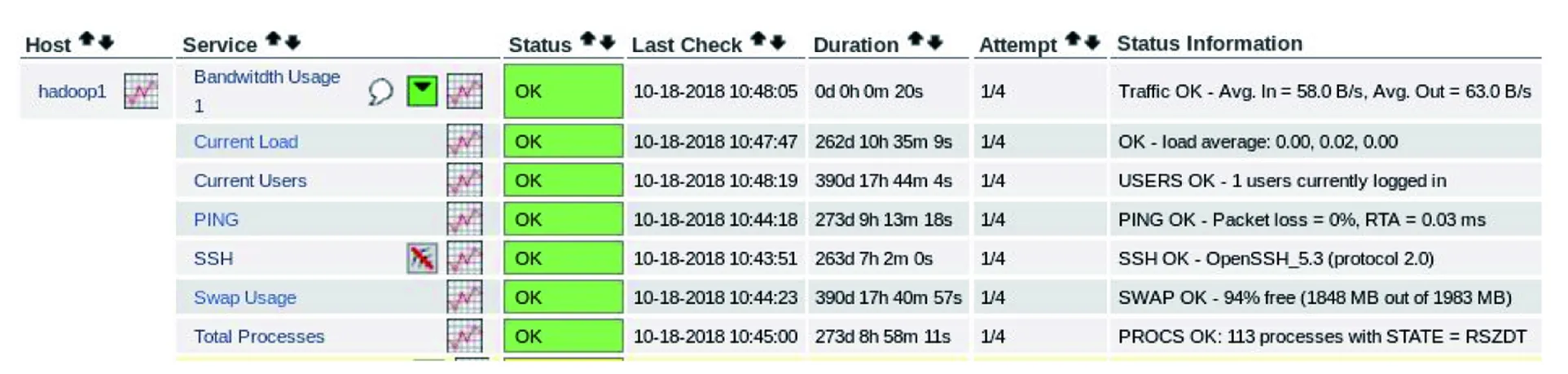
图8 hadoop1节点的监控界面2
2)流量可视化结果。图9展示了在一段时间内,每个监控对象的工作状态为“OK”、“WARNING”或“CRITICAL”,其中,Warning100.000000和Critical200.000000对应图5所设置的平均带宽门限阈值;据此可分析出现异常状态的原因,预测监控对象未来的工作状态,及时预防异常状态的发生,更好的管理平台。
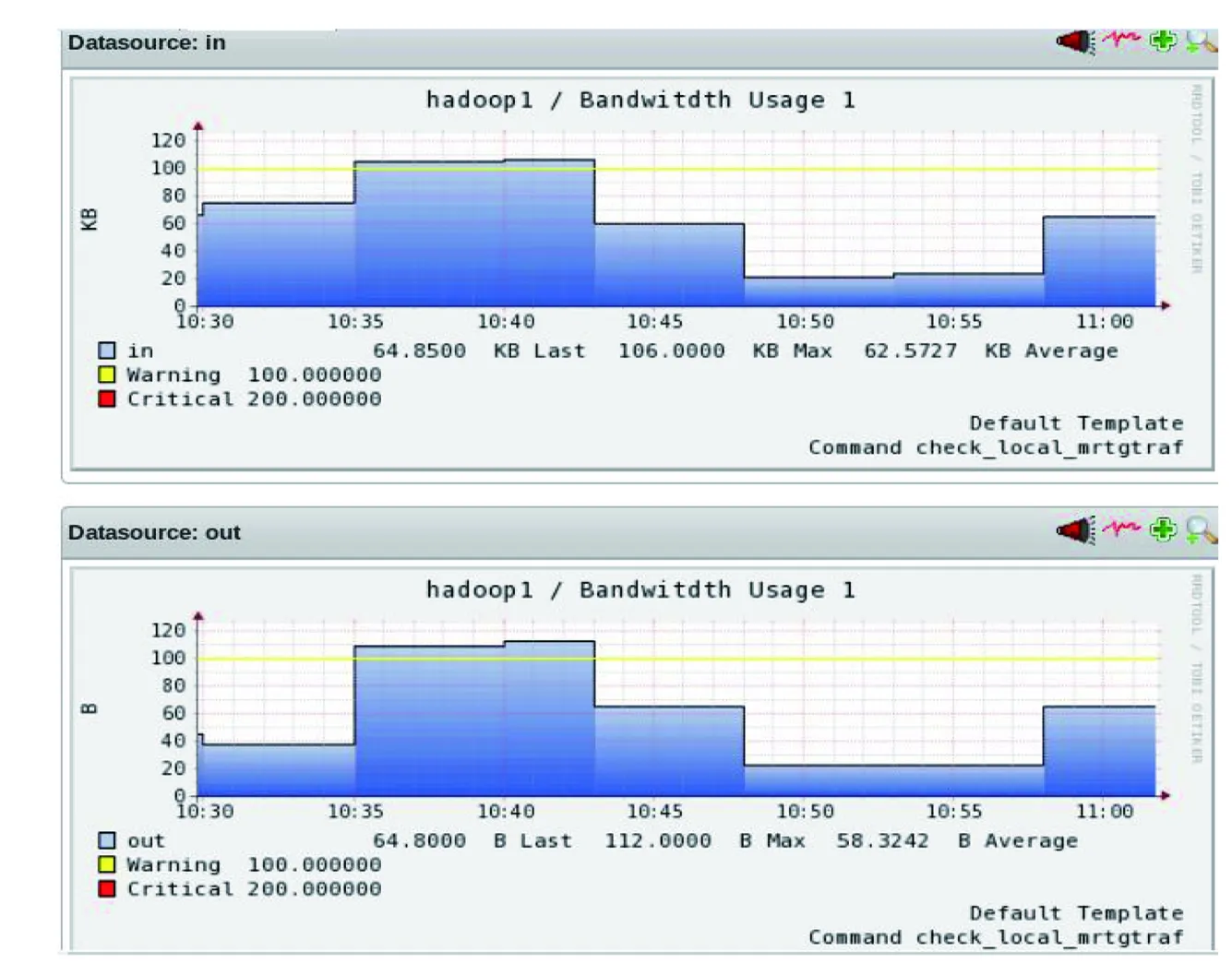
图9 hadoop1流量可视化界面
3.2 报警方式测试
系统实现了对流量异常的邮件和短信报警,当输入或输出流量中有超过图5中预定的门限阈值时,返回对应状态并发送报警信息。由图9可知,10:40,检测到流量为异常状态,所以Nagios在10:41、10:42、10:43均进行了检测,且以10:43的检测结果WARNING作为流量的监控状态。Nagios启动报警机制,运维人员将收到流量WARNING报警信息(见图10和图11)。10:48,流量状态恢复正常,Nagios会发送报警取消短信(见图12)。运维人员通过预留手机号来接受报警取消短信,从而判断监控对象的异常状态是否被消除,接受到报警取消短信表示异常状态被消除,没有接收到报警取消短信表示异常状态还在持续。
此外,浏览网页使流量为异常状态CRITICAL,运维人员将收到流量CRITICAL报警信息(见图13和图14)。由图10~图14可知,当监控对象被确定为异常状态时,监控系统能在20s时间内发送异常状态的报警信息;运维人员可以通过设定的邮箱和预留的手机号接受报警信息,方便了运维人员随时随地掌握Hadoop平台的运行情况。
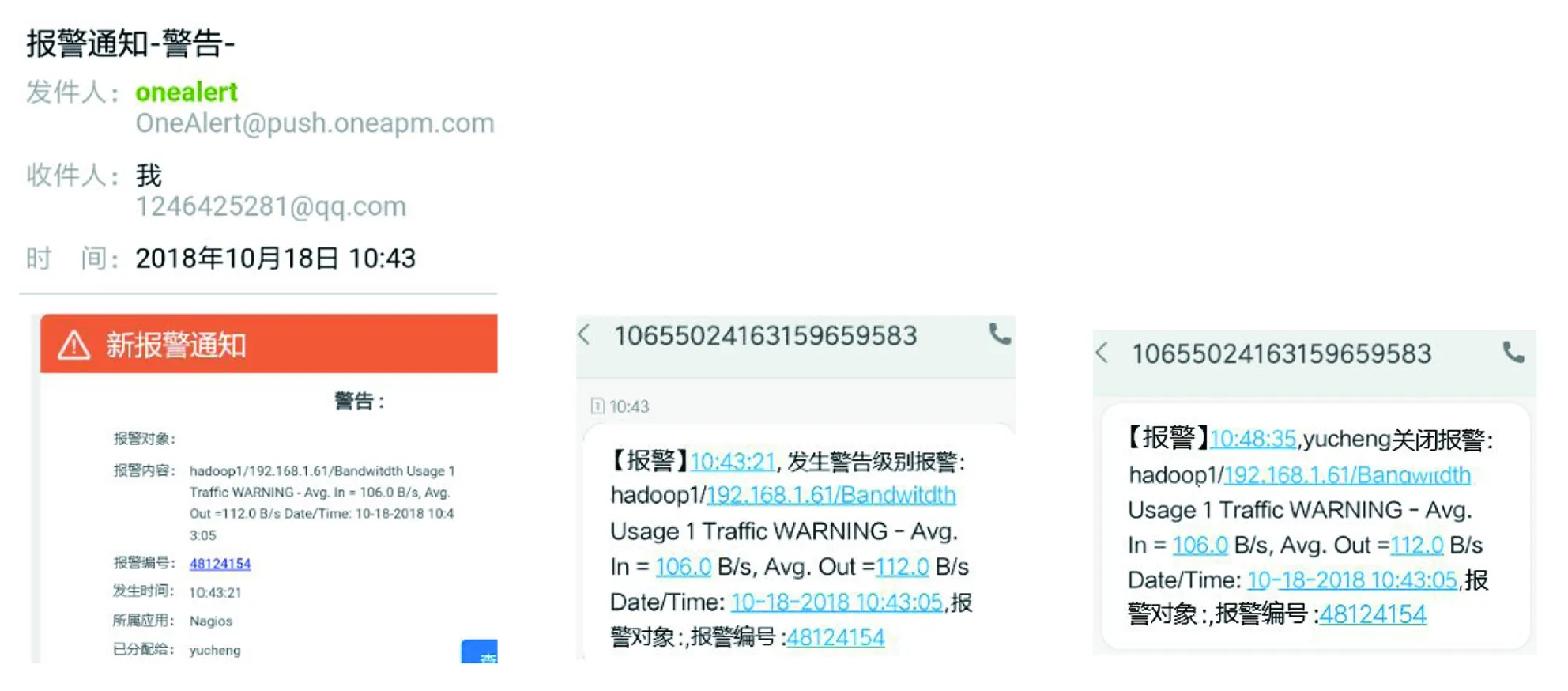
图10 流量WARNING报警邮件 图11 流量WARNING报警短信 图12 流量报警取消短信
4 结语
笔者以Hadoop流量为对象,研究了其监控方法和报警方式。利用Nagios和MRTG实现了Hadoop平台的流量监控系统,该系统还可以对平台的CPU、内存、磁盘、进程数、登陆用户数等方面进行测试、监控和报警。报警方式除了邮件之外,还实现了短信报警方式(还可以用电话方式);在平台出现异常和处理完异常时,能及时通知运维人员,便于运维人员随时随地掌握平台运行状况。由于该系统没有历史数据分析功能,笔者下一步的工作将是采用python统计分析历史监控数据,评估平台性能。
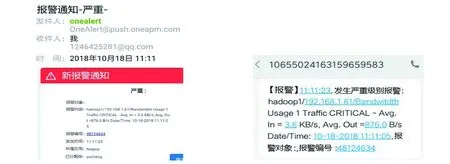
图13 流量CRITICAL报警邮件 图14 流量CRITICAL报警短信
