一种算法对于深层神经网络训练速度的提升
2019-11-03刘建黄娇洁
刘建 黄娇洁


摘要:如今深度学习在声纹识别的领域取得了不错的成绩,其中代表就是卷積神经网络(CNN),但是传统的神经网络训练过程中需要耗费大量的时间。为了解决这一问题,本文了快速批量归一化算法(FBN),用以提高网络的融合速度,缩短培训时间。卷积神经网络训练时需要大量的样本数据,本文对TIMIT数据集预处理之后进行数据增强处理,防止过拟合发生。实验结果表明,与没有FBN的网络相比,具有FBN的CNN网络减少了48.04%的额训练时间。
关键词: 声纹识别 ;CNN ;FBN;数据增强
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2019)24-0207-03
开放科学(资源服务)标识码(OSID):
An Algorithm for Improving the Training Speed of Deep Neural Networks
LIU Jian1, HUANG Jiao-Jie2
(1.School of Electronic Information , Yangtze University , Jingzhou 434023, China; 2.School of Mechanical Engineering, Hubei University of Technology, Wuhan 430068, China)
Abstract: Today, deep learning has achieved good results in the field of voiceprint recognition. The representative is the Convolutional Neural Network (CNN), but the traditional neural network training process takes a lot of time. In order to solve this problem, this paper proposes a fast batch normalization algorithm (FBN) to improve the network convergence speed and shorten the training time. Convolutional neural network training requires a large amount of sample data. In this paper, the TIMIT data set is preprocessed and data enhancement processing is performed to prevent over-fitting. The experimental results show that compared with the network without FBN, the CNN network with FBN reduces the training time by 48.04%.
Key words: Voiceprint recognition ; CNN ; FBN ; Data enhancement
声纹识别是一种生物识别技术[1],通过声纹特征来识别说话人。随着深度学习的出现,卷积神经网络(CNN)被广泛用于语音识别[2-4]。训练深度神经网络需要大量的训练样本来训练数百万个网络参数[5]来提升精确度,这也就是耗时长的问题。Le Cun 提出数据规范化可能会加速网络融合[6]。根据批量归一化(BN)[7]的启发,提出快速批量归一化算法(FBN)。本文中使用的CNN-FBN网络由五个卷积层和三个全连接层组成,在激活功能之前将FBN添加到卷积层,可以有效地加速网络的收敛。
1 算法描述
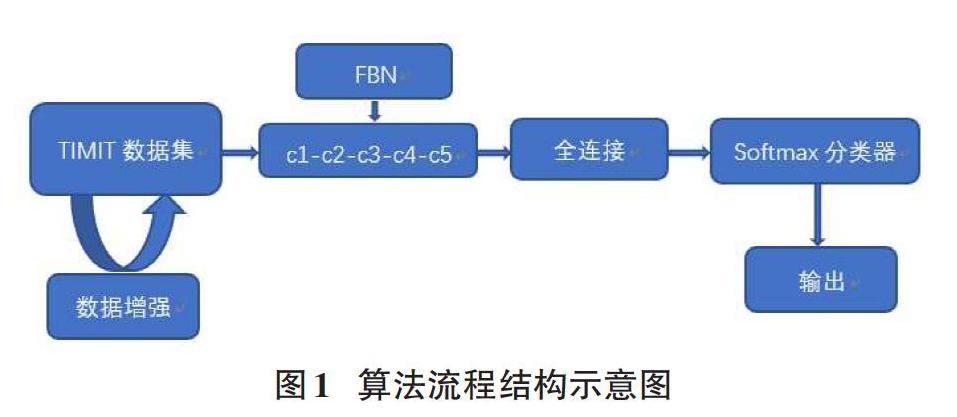
当小样本声纹数据集被用于训练CNN网络时,由于样本少,声纹的识别准确度低。为了提高样本声纹识别的性能,我们将源样本进行数据增强,并在CNN网络模型激活功能之前,将FBN添加到卷积层中。通过卷积和池化功能,CNN网络的全连接层集成了所有的声纹特征映射,达到提高识别率和训练速度。算法流程如图1所示:
2 预处理
在使用语言训练之前,由于语音信号的短时不变性,语音信号[x(t)]首先被分成[x(m,n)](m是帧数,n是帧长度),通过短时傅里叶变换获得[X(m,n)]。周期图[Y(m,n)]使用公式[(Ym,n=Xm,n×Xm,n?)] 从[X(m,n)]中获得,然后取[10×lgY(m,n)]。最后根据时间将m转换成标度M,根据频率将n转换为标度N,并根据[(M,N,10×lgYm,n)]绘制二维语谱图。语谱图(b)由原始语音信号(a)产生,如图2所示:
2.1 数据增强
为了防止过拟合,数据增强是一种方法,将一系列的几何变换添加到原始语谱图中[8]。它主要有刻度、变焦、移位和噪声。本文中,我们通过基于凸透镜成像的数据增强来增加样本集[9]。
基于凸透镜成像的方法如下:
(1) 根据凸透镜成像原理,通过取P点位置L1(F (2) 通过取P位置L2(L2=2F)得到与原始图像一样大的图像,如图3b所示。 (3) 通过取P位置L3(L3>2F)得到比原始图像小的图像,如图3c所示。 (4) 最后将所有图像尺度归一化为227*227作为CNN网络的输入。 2.2卷积神经网络模型 本文中使用CNN-FBN网络由五个卷积层、三个全连接层组成。在激活功能之前將FBN添加到卷积层。输入的训练集维度大小是227*227。卷积层CONV1使用96*11*11*3卷积核来滑动输入语谱图像的227*227维,步长为4像素。卷积层CONV2使用256*3*3*96卷积核,卷积层CONV3-CONV4-CONV5依次使用384*3*3*256,384*3*3*384,256*3*3*384卷积核。FC6-FC8中神经元数量依次为4096,4096,200。CONV1-CONV5具有获得的tezhe特征映射最大池化,全连接层用于对声纹进行分类。网络结构图如图4所示: 通过前向传播学习网络参数。在每个图层中,输入要素计算方法如下: [netl+1j=wljxlj+bl+1j] (1) [xl+1j=s(FBN(netl+1j))] (2) [xlj]表示第[l]层的第[j]个特征图,[xl+1j]表示第[(l+1)]层的第[j]个特征图,[Wl+1j]和[bl+1j]分别是权重矩阵和特征映射[xl+1j]的偏差。[s(*)]是RELU函数,[FBN(*)]是快速批量归一化算法。其中FBN算法独立应用于每个激活,本文关注的具有t维输入的层的特定激活[ek(k∈[1,t])]。FBN算法的详细情况如下: 小批量:[μ=1si=1sei] (3) 小批量差异:[σ2=1si=1s(ei-μ)2] (4) 标准化值:[gi=ei-μσ] (5) 更新全球平均值:[μB=1-ξ*μB+ξ*μ] (6) 更新全局差异:[σB2=1-ζ*σB2+ζ*σ2] (7) 更新动量值[ξ]:[ξ=ξ-γ?L?ξ] (8) 跟新动量值[ζ]:[ζ=ζ- γ?L?ζ] (9) 在FBN算法中,[μB]和[σB2]分别初始化0和1。对于学习率[γ],初始化为0.01。另外,它与[ξ]和[ζ]有关,它们是从批量数据中学习的。所以组合系数[ξ]和[ζ]实现了每次激活的自适应。验证过程中,采用[μB]和[σB2]的最终训练结果。通过规范整个网络的激活,FBN有效解决了内部协变量偏移引起的问题[7]。可以使用更高的学习率而不考虑过拟合的风险,从而加速网络的训练。 3 实验设置 3.1 数据集 本文采用的是美国国家标准技术局的TIMIT数据库[10]。TIMIT数据集中包含来自美国不同地区的630人(每人10个句子),处理过程中只得到4620张语谱图,利用数据增强将源数据集扩充到13860张语谱图,实验按照3:1的比例分为训练集和测试集,其中训练集和测试集大小为10395和3465张语谱图。 3.2 硬件设施和实验设置 实验在ubuntu 1604的操作系统中进行,具有GTX 1060 GPU,内存为8GB,python3.5上的软件平台,以及用于跨平台Qt机器的接口软件tensorflow1.2.1。CNN、CNN+BN、CNN+FBN的网络设置如表1所示: 表1中,dropout表示可以防止模型过拟合的技术,其中“--”表示网络不需要dropout,因为批量标准化可以防止模型过拟合[7]。 3.3 实验结果与分析 在设置相关参数后进行实验,训练过程中三种模型的准确率和损失函数如图5,图6所示: 由图5,图6分析可知,CNN模型的发展很成熟,所以三种模型的准确率基本都在95%以上。同时由损失函数可以发现具有FBN网络的模型收敛速度明显快于其他两个模型。 3.4 三种模型的收敛速度比较 为了证明模型的收敛速度优越性,本文进行了三种模型训练的时间对比实验,使用相同的数据集,对于没有BN和FBN的深层网络,基本学习率设置为0.01;对于具有BN和FBN的深层网络,基本学习率设置为0.05;并且整体网络损失设置为0.01。以下实验结果显示了三次实验的平均值,如图7所示: 由图7可知,CNN+FBN网络与原始网络比较,训练时间减少了48.04%,与CNN+BN比较,训练时间减少了19.11%。这有两个原因:首先,快速批量归一化操作将数据归一化为零均值和单位方差;其次,总方差和均值分别由小批量方差和均值代替,从而减少了整体计算量。经验证,将FBN网络添加到卷积过程中将加速网络的收敛。 4 总结 本文基于BN算法的启发,提出了FBN算法, 并结合卷积神经网络的方法进行了测试, 并且取得了相较好的成绩,证实本文提出的模型可以很好地解决深层神经网络收敛速度的问题。同时网络模型的准确率也比之传统的CNN网络要高。 参考文献: [1] Islam M A. Frequency domain linear prediction-based robust text-dependent speaker identi?cation. In Proceedings of the International Conference on Innovations in Science, Engineering and Technology (ICISET), Dhaka, Bangladesh, 28–29 October 2016:1–4. [2] Abdel-Hamid O,Mohamed A R,Jiang H. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [3] Huang J T,Li J,Gong Y. An analysis of convolutional neural networks for speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 4989–4993. [4] Lukic Y,Vogt C,Dürr O. Speaker identi?cation and clustering using convolutional neural networks. In Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Salerno, Italy, 13–16 September 2016; pp. 1–6. [5] Oquab M,Bottou L,Laptev, I. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1717-1724. [6] LeCun Y,Bottou L, Bengio Y,et al. Gradient-based learning applied to document recognition. Proceed. IEEE 1998, 86, 2278-2324. [7] Ioffe S,Szegedy C. Batch normalization: Acceleratingdeep network training by reducing internal covariate shift. In Proceedings of the International Conference Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [8] Dutta T.Dynamic time warping based approach to text-dependent speaker identification using spectrograms.In Proceedings of the 2008 IEEE Congress on Image and Signal Processing CISP08, Hainan, China, 27–30 March 2008; pp. 354–360. [9] Niu Y F,Zou D S,Niu Y D,et al. A breakthrough in speech emotion recognition using deep retinal convolution neural networks. Comput. Sci. 2017, arXiv:1707.09917. [10] DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus. Available online: https://catalog.ldc.upenn. edu/ldc93s1 (accessed on 25 December 2017). 【通联编辑:唐一东】
