多特征相似度计算在考试评阅系统中的应用探索
2019-11-03穆炜炜刘其琛
穆炜炜 刘其琛
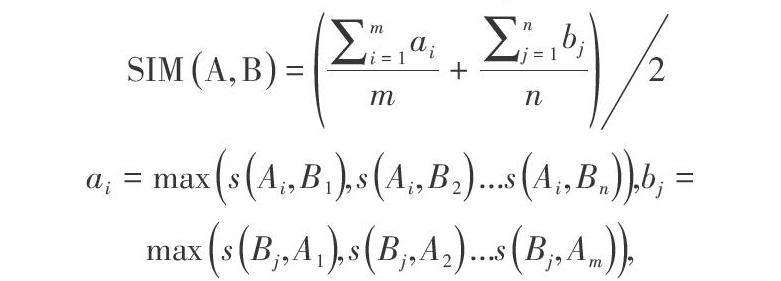


摘要:在信息化考试的主观题自动评阅中,文本相似度计算是一个较为复杂的系统,包括词语、句子相似度计算等。其中,詞语是构成语言体系的基本单位,计算其相似度往往是计算句子相似度的基础,而句子相似度计算则是文本相似度计算的前提。只有通过词语、句子等多特征的相似度计算,才能得出文本的相似度。
关键词:多特征;文本;相似度;计算
中图分类号:TP391.6 文献标识码:A
文章编号:1009-3044(2019)24-0080-02
开放科学(资源服务)标识码(OSID):
1 背景
随着信息技术的不断发展和互联网进入日常教育教学,“互联网+教学”已经成为教育现代化进程中的重要改革方式,智慧课堂、智慧教学、智能化考试的理念日趋发展成为实践,越来越多的教师和学生通过信息网络完成日常的教学,这种打破传统的学习方式,使得学习不再拘束于时间与空间,实现了人人、处处、时时地泛在学习,更加强了教师之间、师生之间和学生之间的交流沟通,实现了优质资源的共享与应用。特别是信息化教学中考试系统的应用,为教师和学生的教学评价带来全新的改变。但考试系统的普遍应用还有待改进,尤其是主观题的自动评阅难以达到人工评阅的准确度,本文采用文本语句相似度、词语相似度和语义相似度等多个特征相似度计算的方式创新自动评阅算法,达到科学、准确评阅的目的,提升考试系统的公平公正性。
2 多特征相似度计算概念
在现在的各类考试系统中,针对选择题、判断题和填空题等客观题的自动评阅技术已经非常成熟,计算机根据固定的答案验证其匹配度即可判断是否正确。但主观题自动评阅一直难以广泛应用,其主要原因是汉语言表达的多样性和复杂性导致系统很难准确把握答案的正确性,特别是对中文的处理技术等一些关键的核心技术还在研发试验阶段,如,自然语言的理解、模式识别、人工智能等一些技术还未完全成熟。计算机要实现对主观题的自动评阅,首先要把自然语言处理成机器能理解的形式,然后进行答案的相似度比较计算,才能进行科学评阅。传统的人工评阅主观题时,教师是根据评分细则将学生的答案表述进行理解,再查看学生答案和标准答案的相似程度进行打分,包括同义词汇及同义语句的关键词汇判别等,再分为不同的分数档次,进行打分和统计。根据人工阅卷规律,本文采用词语语义相似度、句子语义相似度和句长相似度[1]等相结合的多特征方式对主观题文本进行相似度计算。
词语的语义相似度是指两个词语或多个词语在不一样的语言表述中可以相互替换而使其核心要义不发生变化,类似于近义词。目前,词语语义相似度计算主要有基于统计和基于规则的两种方法[2],其中,基于统计的方法主要是对大量的词语库进行统计分析,并将词语在上下文中的概率分布作为相似度的计算参考依据;而基于规则的方法主要是采用词语结构中层次关系组织的语义词典,如,同义词词林、知网[3]、概念图等概念间的同位关系及上下位关系计算语义相似度。
句子语义相似度计算主要有基于语法分析和不基于语法分析两种分析计算方法。基于语法分析的相似度计算方法,国内外均有应用,如杨思春等[4]提出根据句子的语法句型模式来判断相似度等,但由于汉语言表达的多样性和不规则性,特别是不同的专业有其固定的术语或表达方式,采用不基于语法分析的句子语义相似度计算方法有利于降低系统计算复杂性,提高适应性。
句长相似度主要是指两个句子在形态上的相似情况,即两个句子词语个数的多少,根据相似度比较,两个句子的长度越接近,两个语句就越相似。
3 多特征相似度计算原理
3.1 词语语义相似度计算
本文采用基于同义词词林的词语相似度计算方法,同义词词林不仅比较词语的词义相似性还涉及词语的相关联程度,如“上班”与“劳动”词义相似度较低,但是却有很强的相关性。《同义词词林》是梅家驹等人于1983年编纂而成的。目前,在改进的《哈工大同义词词林扩展版》中分为5层树状结构,随着层次级别的增加,词义越来越细分,在第五层,每个分类中词语只有一个并已不可再细分,即称为原子词群或原子节点。如图1所示:
根据上图形成了8位的5层词义编码体系如表1所示[5]。
表中的编码位是按照从左到右的顺序排列。第八位的标记有3 种,“=”表示“相等”或“同义”,“#”表示“不相等”或是“同类”是相关词语,“@”代表示“独立”,既没有同义词,也没有相关词。由上图可看出,不同层级的分类结果可以提供不同的语言处理服务,进一步改善和加强信息检索、文本分类等方面的性能。
3.2 句子语义相似度计算
句子相似度指两个有待比较的句子在语义上的匹配程度,如,设定值为a=[0,1]之间的实数,值越小说明两个句子的相似度越小,当a=0时,说明两个句子意义无关联;值越大说明相似度越高,当a=1时,说明两个句子意义相同。由于汉语言表达方式的多样性和灵活性,本文通过矩阵计算词语相似度,首先计算出相关词语的相似度,并以此为数据构建句子相似度矩阵,然后通过相应算法计算出句子相似度。假设有两个句子A和B,A={A1,A2,…Am} B={B1,B2,…Bn} Ai是组成A的词,Bj是组成B的词,1≤i≤m, 1≤j≤n。则词Ai词的相似度表示为S(Ai,Bj) ;句子A和B的相似度为表示为SIM(A,B)。
[ SIM A,B=i=1maim+j=1nbjn2]
[ai=maxsAi,B1,sAi,B2...sAi,Bn,][bj=maxsBj,A1,sBj,A2...sBj,Am,]
3.3 句长相似度计算
句长的相似度可以表示两个句子在形态上的相似情况,设有两个句子分别为X和Y,句子X中有len(X)个词语、句子Y中有len(Y)个词语,则句子X和Y的相似度为表示为Lensim(X,Y),计算如下所示:
[LensimX,Y=1-lenX-len(Y)lenX+len(Y)]
从而得出了两个句长X和Y的相似度。
4 多特征相似度计算在考试系统自动评阅中的应用
由于中文主观题答案的表示往往是由字构成词、词形成句。要判断已做答案和标准答案两段文本的相似度,可以将其逐级分成子项,如分句、分词、词语相似度及句子相似度等多特征进行计算,并引用决策树分类器,将关键词的相似度、句子的相似度及句长相似度作为决策树的文本属性,通过决策树分类器进行分类计算,从而实现自动评阅。
例如:一个试题为10分,可生成如下决策树。其中SIMi是决策树属性。枝节点为各个属性的值,叶子节点是对应的答案分值。如图2所示
主观题自动评阅主要是基于人工智能和大数据分析的自然语言处理技术。虽然汉语言识别与处理具有很大的难度,但是从人工智能及大数据等技术的发展趋势来看,实现考试系统中的主观题自动评阅是智慧教育的必然。一方面,计算机自动评阅能避免在高强度、高密度的阅卷工作中造成的人为误差和纰漏,能够更客观地反映出考试结果,保证了阅卷的客观公正性。另一方面,计算机自动评阅提高了工作效率,并能对学生的得分点和失分点进行大数据分析,对教学成效进行科学诊断,有利于教学工作的不断改进。
参考文献:
[1] 吕学强, 任飞亮. 句子相似模型和最相似句子查找方法[J]. 东北大学学报: 自然科学版, 2003, 24(6): 531-534.
[2] 于江生, 俞士汶. 中文概念词典的结构[J]. 中文信息学报, 2002, 16(4): 13-21.
[3] 张承立, 陈剑波, 齐开悦. 基于语义网的语义相似度算法改进[J]. 计算机工程与应用, 2006, 42(17): 165-179.
[4] 杨思春. 一种改进的句子相似度计算模型[J]. 电子科技大学学报, 2006(35): 956-959.
[5] 郑家恒. 中文分词中歧义切分处理策略[J]. 山西大学学报: 自然科学版, 2007(2).
【通联编辑:谢媛媛】
