基于Word2vec和LDA的卷积神经网络文本分类模型
2019-10-31吴龙峰
吴龙峰

摘要:针对短文本的文本分类出现的特征维度高和数据稀疏性的问题,本文提出了一种结合神经网络语言模型word2vec和文档主题模型LDA的文本特征表示模型,并使用表示矩阵模型,矩阵模型不仅可以有效地表示单词的语义特征,还可以表达上下文特征,增强模型的特征表达能力。将特征矩阵输入卷积神经网络(CNN)进行卷积池化,并进行文本分类实验。
关键词:文本分类;Word2vec;LDA;CNN
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2019)22-0203-02
开放科学(资源服务)标识码(OSID):
1 引言
近年来,随着互联网技术的飞速发展,主流社交平台不断产生大量的文本信息。其中,短文占据着很大比例,短文分类作为自然语言处理领域的基本任务,受到研究人员的密切关注。因此,有效和准确的文本分类方法对于数据挖掘,信息处理和网络维护具有重要意义。文本的特征表示和分类算法是文本分类工作的重要组成部分,它直接影响文本分类效果。传统的机器学习分类算法包括朴素贝叶斯,支持向量机(SVM),K近邻算法等。这些分类算法通常使用人工设计的特征选择算法,如TF-IDF,信息增益(IG),卡方统计(CHI)等等。这些特征选择算法存在诸多问题,比如特征表示不足、容易忽略类别之间的关系。
深度学习是机器学习研究领域的热门话题。卷积神经网络(CNN)最初应用于计算机视觉领域[1]。目前,CNN在自然语言处理领域也取得了很好的成绩,Kim将单词向量与CNN结合起来,并将其应用于主题分类和语义分析,以取得良好的效果[2]。CNN输入矩阵仅提取单词粒度级别的单词向量矩阵,忽略文本粒度级别的整体语义特征表达,导致文本特征表示的不准确,影响文本分类的准确性。本文试图将word2vec模型与LDA模型相结合,形成一个新的文本特征表示矩阵,然后传递给CNN进行文本分类,取得了良好的分类效果。
2 相关工作
2.1 文本预处理
文本預处理的过程一般包括以下步骤:将从互联网上爬取的文本数据进行统一编码;然后利用分词程序进行将文本切分成一个个单词[3];最后利用停用词表去除对文本分类无用的词语。
2.2 文本表示
文本通常是一种非结构的信息,由文字和符号共同组成。利用计算机进行文本分类时,必须将文本转换成结构化的信息才能被计算机识别和处理。常用的文本表示模型有空间向量模型、LDA模型等,其中,LDA模型包含单词、主题和文档结构,通过简要描述文档并保留基本特征信息[4]。Word2vec模型可以快速有效地训练单词向量,训练之后,Word2vec模型可用于将每个单词映射到向量以表示单词和单词之间的关系。
2.3 文本分类
文本分类模型一般分为两类:机器学习模型和深度学习模型[5]。由于CNN卷积神经网络模型对文本分类任务有很好的适应性,文本表示特征提取方法的应用比较成熟,但很容易导致高维数据和不完整的特征表达。LDA模型提取语义特征并忽略语义特征。Word2vec模型训练单词矢量模型并忽略语义特征。如果将这两个表示特征用作CNN的输入矩阵,则分类效果将令人满意。
3 Word2vec和LDA组合模型
3.1 构建CNN输入矩阵
(1)训练词向量
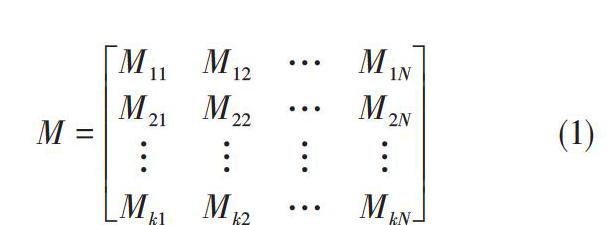
Word2vec主要包含两个重要的模型,连续词袋(CBOW)模型和Skip-gram模型。两种模型都包括输入层,隐藏层和输出层。本文使用Skip-gram模型进行训练词向量,文档的N维向量表示如下:
[M=M11M12…M1NM21M22…M2N????Mk1Mk2…MkN] (1)
其中:M是数据集的任一文档,[MkN]是词的权重。
(2)训练主题向量
LDA模型将文档视为单词向量的集合。该过程如下:对于文档,文档和主题满足多项式分布,并且主题和词汇中的单词也满足多项式分布。两个多项式分别是具有超参数α和β的Dirichlet先验分布。因此,文档d处理流程为:从文档主题分布θ中提取主题,然后从与提取的主题相对应的单词分布φ中提取单词,重复以上步骤,形成包含N个字的文章。完成LDA模型后,数据集的任意数据的主题分布矩阵如下:
[Z=Z11Z12…Z1NZ21Z22…Z2N????Zk1Zk2…ZkN] (2)
其中:[ZMN]是对应于文本M的主题概率向量,N是语料库大小,k是向量维度,并且数字与单词向量维度相同。
(3)矢量拼接
改进的文本表示方法是叠加通过训练上述两个模型得到的矩阵,形成一个新的特征矩阵。
[Mnew=M⊕Z=M11M12…M1NM21M22…M2N??…?Mk1Mk2…MkNZl1Zl2…ZlN] (3)
其中:⊕是矢量拼接操作,完成拼接后获得新的矩阵[Mnew],用于CNN的输入矩阵。
3.2 卷积神经网络模型
CNN是一种优化的卷积神经网络,核心在于输入矩阵和不同卷积核之间的卷积运算。卷积神经网络主要由卷积层,池化层和分类层组成。
输入层是句子中单词的单词矢量矩阵。假设有n个单词且单词向量维度是d,则输入矩阵的大小为n[×]d。在训练模型期间,可以固定或优化单词矢量的值作为参数。
隐藏层包括卷积层和池化层。卷积本质是输入信号的加权叠加,它是卷积内核(滤波器)的不同大小的文本体积h[×]d(h是卷积内核窗口中包含的字数,d代表每个单词的向量维度)。实验卷积核设计为三种尺寸,即3[×]d,4[×]d,5[×]d,CNN卷积运算公式如下所示:
[ci=f(W1?Xi:i+h-1+b1)] (4)
其中[ci]表示卷积运算的结果,即输出矩阵和卷积核的点乘以及偏移后的激活输出。h是窗口大小,[Xi:i+h-1]是输入的i到i+h-1窗口中的字向量矩阵,[W1]是卷积核或权重矩阵,[b1]是偏移量,f是激活函数。在通过卷积获得特征之后提取特征以简化网络的计算复杂性,在池化层处压缩特征。池化操作有两种类型:平均池和最大池。文本分类通常使用最大池来选择最重要的信息。池化操作如下:
[c=max{c1,c2…cn-h+1}] (5)
其中:[c]是最大合并操作的结果,并且[ci(i=1,2…,n-h+1}]是卷积操作的结果。
输出层将池化层作为输入,并通过Softmax函数执行分类计算。分类计算公式如下:
[f(x)ρ=11+exp(-ρTx)] (6)
exp表示以e为基数的指数函数,[ρ]是评估参数,该值由最小成本函数J([ρ])估计。公式如下:
[J(ρ)=i=1My(i)logfρ(x(i))] (7)
函数的返回值是C分量的概率值,并且每个分量对应于输出类别的概率,从而划分文本的类型信息并完成分类。
4 实验
4.1 实验环境和数据
实验环境:CPU:I7,内存:8G,实验编程语言为Python3.6,开发工具为Pycharm,深度学习框架为Tensor flow1.0.0。实验数据来源于搜狗实验室的文本语料库。包含体育,军事,旅游,金融,IT,房地产,教育,娱乐等八個类别,每个类别选取1000篇文档共8000篇文档,将该数据集的80%作为训练集,20%作为测试集。数据通过十折交叉验证进行验证。
4.2 实验设置
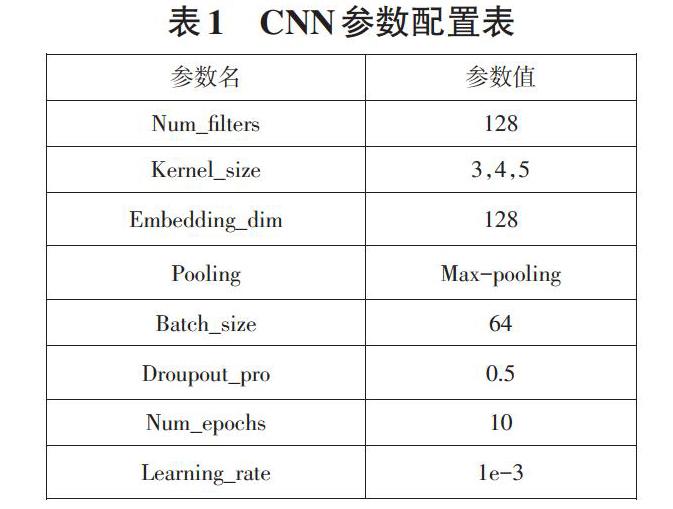
本文中的数据以UTF-8编码格式统一,用Python调用Jieba分词组件进行分词,并使用哈尔滨工业大学的停用词表来停用单词。创建文本要素表示矩阵并输入CNN进行文本分类。CNN模型参数的具体设置如表1所示:
4.3 评估指标
对于分类结果,采用国际公认的评估指标:精确率P,召回率R和F1值。其计算公式如下:
[P=XX+Y] (8)
[R=XX+Z] (9)
[F1=2PRP+R] (10)
其中X表示某种类型的文本被正确识别为类的样本数,Y表示某种类型的文本被识别为其他类别的样本数,Z表示其他类别的文本是被确认为该类别的样本数。为了验证改进的输入特征矩阵的有效性,将基于word2vec的CNN文本分类方法与本文的实验进行了比较。 比较精确度P和召回率R和F1值。
实验数据如表2所示:从表中可以看出,传统的基于CNN的word2vec文本分类方法的平均准确度、召回率和F1分别为:0.835、0833和0.834。本文的方法是:0.920、0.922和0.921。相比之下,改进的方法具有更好的分类效果,原因在于改进的文本表示矩阵具有很强的特征表示能力,更具代表性,可以为文本分类提供更多的类别信息。
5 结论
本文改进的文本分类方法解决了传统CNN输入矩阵特征未充分表示并影响文本分类效果的问题。提出了一种基于词粒度的单词向量和一种基于语义粒度的特定改进方法。单词矢量矩阵和主题矢量矩阵被叠加以形成可以反映词性特征和语义特征的新矩阵。卷积神经网络的输入矩阵特征使其更好地用于文本表示并提高分类性能。
参考文献:
[1] Luong, M., Pham, H., Manning, C.D.: Effective approaches to attention-based neural machine translation[C]. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing,2015: 1412–1421.
[2] Kim, Y.: Convolutional neural networks for sentence classi?cation[C].The 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014:1746–1751.
[3] 梁喜涛,顾磊.中文分词与词性标注研究[J].计算机技术与发展,2015,25(2):175-180.
[4]杨萌萌,黄浩,程露红,等.基于LDA主题模型的短文本分类[J].计算机工程与设计,2016,37(12):3371-3377.
[5] 周飞燕,金林鹏,董军.卷积神经网络研究综述[J].计算机学报,2017,40(6):1229-1251.
【通联编辑:梁书】
