基于显著性信息和视点合成预测的3D-HEVC 编码方法
2019-10-31严徐乐
余 芳,安 平,严徐乐
(上海大学新型显示技术及应用集成教育部重点实验室,上海200444)
信息化时代的今天,视频压缩技术的日益更新带动了3D视频编码技术的持续发展.随着高效率视频编码(high eきciency video coding,HEVC)标准的研发,高分辨率视频和大尺寸显示设备逐渐走进人们的日常生活,在给人们带来身临其境的高逼真度视觉体验的同时,其视频编码的效率也将面临挑战.
HEVC作为目前最先进的编码标准,相较于H.264/AVC,在保证同等视频质量的前提下节省了近一半的比特率[1].HEVC的发展推动了3D视频技术的发展,JCT-3V工作组于2012年成立,着手开展3D视频编码标准的研究.3D-HEVC的提出旨在HEVC基础上改进编码技术,以高效压缩多视点视频加深度(multi-view video plus depth,MVD)数据,提高了3D视频编解码的效率.与HEVC相比,3D-HEVC增加了视点的数量和对应的深度图,侧重利用视点间相关性来提高3D视频编码效率.但是,由于增加了新的视点和新的编码工具,相较于2D视频,3D视频的编码复杂度急剧增大,难以满足实时性需求.
近些年,基于人眼感知的视频编码越来越受到重视.人类视觉系统(human visual system,HVS)对视频场景及图像的感知具有选择性,对不同区域或不同对象都具有不同的感知能力.为了提高HEVC的编码效率,国内外学者已经提出了一些HEVC的改进算法.Shen等[2]根据编码块之间的紧密关系减少了编码单元(coding unit,CU)的划分深度;Lin等[3]根据深度距离将视频内容划分了3个区间,提出了快速模式选择算法;Sanchez等[4]针对3D-HEVC提出了一种基于梯度的低复杂度帧内模式选择算法;Lee等[5]根据相邻帧的相关性进行编码块的自适应深度划分,并对编码块计算运动活跃度来分配编码模式;马然等[6]提出了针对3D-HEVC帧间模式的低复杂度算法,但是该算法只作用于纹理视频上,没有考虑人眼视觉特性及深度视频对整体编码结果的影响.3D视频庞大的数据中存在着大量的视觉冗余,上述传统的编码算法几乎都是着重从减少信息冗余来提高率失真性能,而忽视了HVS感知多样性对视频编码的影响.Li等[7]和Xu等[8]创新地利用显著性信息指导编码,虽然节省了编码所用比特率,但是并没有考虑显著性信息对深度序列的影响,也没有讨论绘制生成的虚拟视点的主观质量;Noor等[9]在深度序列中运用显著性提取处理,但是虚拟视点的客观质量跟原始平台质量有较大差异;Yu等[10]提出了一种基于显著性信息的3D-HEVC编码方法,由于没有考虑深度图对显著性信息的影响,仅利用2维显著性模型获取相关信息,因此并不能更好地贴近人眼视觉特性;另外由于没有对视点合成预测算法进行改进,导致绘制生成的新视点的质量有所欠缺.
本工作在此基础上作进一步改进,重新建立3D显著性信息提取模型,并对分区域编码模式和视点合成预测算法进行了改进.
1 人眼视觉特性与显著性信息
视觉是人类认知一切事物的重要方式.对于3D视频,人类一直致力于追求一种逼真自然且身临其境的视觉感受.了解人类的视觉感知原理,对于发展图像、视频的编码理论与方法有着重要的意义.
1.1 人类视觉感知系统
HVS是人类获取外部信息的主要手段之一,能够感知自然场景中存在的亮度、颜色、纹理、方向、运动、空间频率等初级视觉信息[11].人眼通常对运动剧烈的对象或者纹理丰富的区域具有更高的感知灵敏度,并认为这些区域为感兴趣区域,即显著性区域[12-14].事实上,由于人眼具有掩蔽效应,故对于引入有损量化的失真编码有不同的感知,因此利用人眼的感知特征改善视频编码算法,在保证观看质量的前提下,有效提高视频编码的效率是非常重要的.已经有很多学者在显著物体提取、视觉感知及低复杂度编码等领域做了大量的工作.1890年,James首次提出了人类视觉注意的理论[15].视觉注意具有2种不同的工作方式:一种是自底向上(bottom-up)的处理过程,属于低级视觉研究范围,这也是显著性的核心模型;而另外一种是自上而下(top-down)的处理过程,主要涉及高级视觉研究范围.视觉注意模型(computational model of visual attention)是利用计算机来模拟人类视觉系统的模型[16].Itti等[17]对视觉注意中的选择和转移工作机制进行了开创性的研究,提出了可计算视觉注意模型的框架(见图1).该模型首先对输入图像进行初级视觉特征提取;然后,通过并行方式来构建出多种视觉信息的特征图;最后,采用特征融合的方式计算出显著性图(saliency map),以此来表示图像中每个位置的视觉显著性.以图1的视觉注意力模型为基础,本工作建立了3D显著性提取模型.

图1 视觉注意力模型Fig.1 Visual attention model
1.2 3D显著性信息的获取
显著性区域代表人眼注视一个场景时最有可能关注的区域.这里没有用著名的GBVS[18]算法,而是用SDSP(saliency detection method by combining simple priors)[19]来获得2D显著图,因其提取的显著性信息有更好的显著性预测性能,能跟人的评价高度相关,并且相较于本工作未使用的基于图像的视觉显著性(graph based visual saliency,GBVS)算法其计算复杂度更低.SDSP是通过结合3个简单先验信息获取图像的显著性,包括频率、颜色和位置.对于频率先验,该算法认为人眼视觉特性检测显著区域可以用带通滤波器来模拟;对于颜色先验,人们对暖色相较于冷色更感兴趣;对于位置先验,图像的中间区域更引人注意.图2为不同原始图像的显著性图,其中第一行是原始图像,第二行和第三行分别是通过SDSP和GBVS算法获得的显著图,可以看到通过SDSP算法提取的显著性图效果优于GBVS算法的显著性图.
然而,SDSP算法在提取显著性信息的时候并没有考虑人眼的深度感知对提取结果的影响.在3D-HEVC编码标准中,深度视频对整体的编码和绘制结果都有着不可忽视的影响.因此,在目前2D显著性提取模型的基础上,增加视频图像的深度信息具有非常重要的意义.建立3D显著性提取模型的步骤如下.
(1)将原始深度序列的深度图D进行归一化处理,得到深度权重ω.由于深度像素值为0~255,数值的大小代表对象离摄像机的远近,数值越大表示离摄像机距离越近,因此

图2 不同原始图像的显著性图Fig.2 Saliency maps of different original images
(2)利用SDSP算法获得纹理视频的显著图SC,并将纹理显著图与深度权重相乘,得到3D显著图SDC,即SDC=ωSC.
这样通过改进的SDSP算法获得的3D显著图SDC,在2D纹理显著图的基础上增加了深度信息,更加符合人眼视觉注意力机制,达到了越接近中间的对象其显著度越高的目的.
23 D-HEVC编码
2.1 3D-HEVC编码框架
3D-HEVC的编码结构是对HEVC的扩展,每个视点的纹理及深度图编码的主框架仍采用HEVC的编码框架,但在其基础上增加了一些新的编码技术,使其更有利于深度图和多视点的编码(见图3).图中的纹理图和深度图是摄像机在同一时刻从不同位置拍摄的图像,这些图像放在一个存取层中.当开始编码时,编码器会先从一个存取层中的独立视点(图3中视点0)的纹理图开始编码,然后编码该视点的深度图,最后再编码其他视点(视点1~N)的纹理图和深度图.虽然从技术实现上来看,每个视点的纹理图和深度图都能用原始的HEVC编码框架,但是这样并不能充分适应3D视频的特点.因此,编码器利用没有改进的HEVC编码框架来编码独立视点,由于独立视点不依赖于其他视点,故可以提取出其相应的比特流来形成2D比特流,经解码可以形成2D视频,通过这种方式兼容了2维视频的编解码.对于其他非独立视点,其纹理图和深度图采用改进后的HEVC编码框架进行编码,这样可以进一步提高3D视频的编码效率.
图3中,3D-HEVC在编码视点0时,使用的是非扩展的HEVC编码器;而在编码视点1到视点N时,一方面使用了编码视点0时的编码技术,另一方面还采用了HEVC关于多视点扩展的编码技术,使其能够适应多视点视频加深度的编码.
2.2 显著性信息在编码中的应用
在HEVC中,每一帧被分成若干个CU,对于每个利用HEVC框架的视点图像,输入的显著性信息可以用于决定当前编码块的量化参数(quantization parameter,QP)和模式选择.QP的大小,不仅影响编码所用的码率,而且还会影响编码块的尺寸.如果增大量化步长比特率就会下降,图像的失真也增大了.在编码过程中,对平坦区域(如背景区域),分配更大的QP且采用大尺寸块进行编码,可以减少运动矢量、参考帧索引和比特数;对复杂区域(比如人眼关注的显著性区域),往往分配的QP更小,同时采用小尺寸块进行编码,就会提高视频编码的效果.

图3 3D-HEVC编码结构Fig.3 Coding structure of 3D-HEVC
2.2.1 基于显著性信息的区域划分
传统的编码方式并没有考虑人眼的视觉特性来对图像进行分区域编码,而是给不同的CU选择相同的QP,这样不同的区域就具有相同的编码质量.实际上,人眼往往不能兼顾所有区域,只能注意一个场景中的某些区域,而人眼特别关注的这些区域就是显著性区域.因此,可以通过调整显著区域CU的QP来提高编码的感知质量.将3D显著性信息运用到3D-HEVC编码平台中的步骤如下.
(1)对通过3D显著性提取模型获得的3D显著图SDC进行二值化处理得到Sb,即

式中,T为通过Ostu法[20]求得的自适应阈值,通过调用Graythresh函数可以根据视频内容和不同的背景,自动调整T值,从而得到最优的二值划分结果.对于给定的图像,设其前景像素个数为α,且前景加权平均值为μ0,背景像素个数为β,背景加权平均值为μ1,则此时整幅图像的均值为

建立目标函数g(t),即有
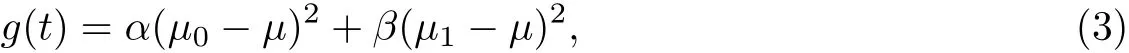
其中,当g(t)为最大时,其对应的t即为最佳阈值T.这样,二值化之后的显著性图Sb拥有更加清晰分明的轮廓,图像中像素值为1的高亮处即为人眼的感兴趣区域,像素为0的高亮处即为背景区域.
(2)计算当前编码块的平均显著度,即

式中:ST为当前编码块中二值化显著图的像素值总和;H,W分别表示当前编码块的高度和宽度;SAve为当前编码块的平均显著度.
(3)通过计算当前块的平均显著度,即可对当前块进行区域划分:

对于中间区域,又可以分为2种情况:

根据平均显著度,将视频中的编码块分成了4种不同类型的区域;然后进行分区域编码,使人眼关注的显著性区域的质量更精细,从而更符合人眼视觉特性.
2.2.2 基于显著性信息的编码策略
已有的编码研究显示[21],自然序列中skip模式是占比最大的预测模式,平均可达80%.在传统编码平台中,编码块需要遍历所有帧间、帧内预测模式,最终通过比较率失真性能确定最佳预测模式,这种全遍历的方法计算复杂度较高.因此利用当前编码块与邻近块时间和空间上的相关性,对3D-HEVC编码进行提前终止skip模式和分区域划分预测模式的处理尤为重要.Shen等[22]分析了空间邻近块与当前块的相关性(见图4),给出了当前CU和其空间、时间上邻近块的示意图,其中参考块0既可以是相同视点内前一帧对应位置块,也可以是相邻视点同一时刻对应块.依据编码标准的参考帧设置策略,选取参考帧列表中首选位置的参考帧.

图4参考CU示意图Fig.4 Temporal and spatial correlations of CUs
图4 中,如果当前编码块处于非显著性区域时,0~4这5个邻块中有3个或3个以上选择skip作为最佳模式,即认定当前块的最佳预测模式为skip,否则选择skip和Inter 2N×2N作为帧间候选模式;当前编码块处于显著性区域时,如果5个邻块全部选择skip模式,则将当前块选择skip设为最佳预测模式,否则对当前块遍历所有的帧间模式;当前编码块处于中间区域,有4个或4个以上邻块选择skip时,则认定当前块最佳模式为skip,否则遍历所有帧间预测模式.
现存的多视点视频编码方法主要是在数字信号处理理论和香农信息论的基础上,通过减少时间和视点间的冗余来提高率失真性能,但是忽略了HVS对视频场景感知的多样性.基于显著性信息的多视点视频编码方法可以根据视频内容的不同有效改善比特的分布,且能在不影响视频主观质量的前提下提高编码效率.本工作对不同区域块分配不同的量化参数QP,基于显著性信息,显著区域分配较小的QP,非显著区域分配较大的QP:

式中,QP0是指平台中最初的量化参数.以此,通过调整显著区域CU的QP来提高编码的感知质量.
2.3 3D-HEVC视点合成预测的改进
为了进一步提高3D视频编码性能,视点合成预测(view synthesis prediction,VSP)已经被加入到3D-HEVC编码框架中,即利用深度信息对纹理进行更好的预测编码.VSP是一种视点间预测编码方法,其算法思想是在参考视点中,利用深度信息合成为当前编码块得到一个预测块.VSP分为前向视点合成预测(forward VSP,FVSP)和后向视点合成预测(backward VSP,BVSP),其中FVSP适用于先编码纹理后编码深度的模式,利用参考视点的深度图,将参考图像中所有的像素点合成到虚拟图像中;BVSP适用于先编码深度后编码纹理的模式,利用当前视点的深度图,在参考图像中找到当前编码块中的对应像素点,得到当前块的预测块.
由于FVSP的解码复杂度很高,故3D-HEVC采用的是改进型的BVSP.当前编码块参考的纹理是不同视点间已编码图像,参考的深度是已编码图像对应的深度图,其目的是为当前编码的预测单元(prediction unit,PU)块寻找一个预测块以减少视点间冗余.目前HTM-15.0的平台采用基于最大深度值的视点合成预测算法,该算法比较整个编码PU块的左上和右下、右上和左下的深度值,如果左上大于右下且右上大于左下,则将所有8×8块分成2个8×4块,然后比较每个8×4块4个角的深度值,取其中的最大值作为此8×4块的深度值;反之,则将所有8×8块分成2个4×8块,然后将每个8×4或者4×8小块中的最大深度值转化的视差进行存储.由于3D-HEVC不对深度块做去块滤波,因此产生的深度图有比较明显的块效应,而VSP原始算法中取子PU块4个角深度值中的最大值,如果该子块正好处在块效应的边界上,则取的最大深度值就可能不准确,从而影响编码结果.因此,需要改进算法来避免子块位于块效应边界的情况发生.
本工作比较整个编码PU块的左上和右下、右上和左下的深度值(见图5).在原始编码平台中,默认用标志位vspSize来表示分割尺寸,当左上深度大于右下且右上深度大于左下时,vspSize为1;反之为0.如果vspSize=1,则将所有8×8块分成2个相同的8×4块;如果vspSize=0,则将所有8×8块分成2个相同的4×8块(见图6).
为了避免边界的块效应,将原平台中对比每个8×4或者4×8块4个角(左上、右下、右上、左下)的深度值改为将原始4个角位置分别内缩一个像素,即横、纵坐标分别向里平移一个像素单位,如图7中深色方块所示;然后,取经过内缩后的4个角中深度值的最大值作为此块要存储的深度值.

图5 PU块4个角深度值比较Fig.5 Comparison of PU's four corners depth values
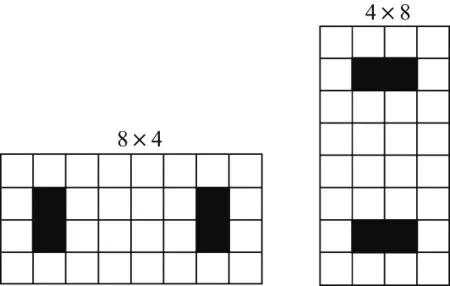
图7 最大深度内缩一个像素Fig.7 Maximum depth inside shrink
这样的改进算法避免了视点合成预测中当子PU块处在块效应边界上时,所得最大深度值不准确的情况,对选取最大深度值比较位置作了相应的处理,能有效减小块效应的影响,选取的最大深度值转化的视差向量(disparity vector,DV)信息更准确,从而更好地预测当前块.
2.4 整体算法
为了提高3D-HEVC的编码效率,且保证绘制合成新视点的质量,本工作建立了3D显著性提取模型,并将2.2节和2.3节中提出的算法用于原始平台的编码中(见图8).
3 实验结果
为验证本算法的有效性,采用3D-HEVC编码标准平台HTM-15.0版本进行测试,实验中使用3view+3depth配置文件,输入左-中-右3个视点的纹理和对应深度图进行编码测试.实验中总共测试了8个视频序列,不同序列具有不同的编码参数.表1和2分别给出了测试条件和编码序列的参数信息.

图8 整体算法流程图Fig.8 Flow chart of the whole algorithm

表1 测试条件Table 1 Test conditions
本工作应用HTM平台中自带的绘制工具进行新视点的绘制,即利用重建的纹理和深度视频生成新的虚拟视点视频.虚拟视点视频的客观质量可以通过编码压缩视频的BD-rate和生成视点的峰值信噪比(peak signal to noise ratio,PSNR)进行评估.目前,将显著性信息运用到3D-HEVC视频编码平台中的文献尚较少,而文献[7]率先利用显著性信息指导编码为本工作提供了启发.因此,本工作将提出算法的BD-rate节省量跟原始平台和文献[7]的结果进行对比,实验结果如表3所示.同时,将不同QP下虚拟视点的PSNR与原始算法进行比较,并将PSNR的增减量分别同文献[7]和文献[10]的结果进行对比,结果如表4所示.

表2 编码序列参数Table 2 Parameters of sequences

表3 整体算法BD-rate实验结果Table 3 BD-rate experimental results of the whole algorithm %
通过实验结果可以发现,跟原始平台相比,本算法通过融入人眼视觉特性的显著性信息使得BD-rate最大可下降10%,平均下降8.73%;绘制生成的新视点PSNR与原平台相比最多提高0.1 dB,不同QP下的平均值可高提升0.07 dB左右,一定程度上提高了3D-HEVC原始平台的编码效率.同时,相较于文献[7]的算法,从BD-rate节省率和虚拟视点绘制质量2个方面来看,本算法都具有更好的性能;跟文献[10]相比,本算法优化了虚拟视点的合成,提高了虚拟视点的客观质量.利用平台自带的绘制工具所产生的虚拟视点图像如图9所示,与原始序列绘制出的虚拟视点相比并没有肉眼可见的差异,本算法在一些图像的细节上的处理结果亦更优于文献[7]和文献[10]的算法结果.
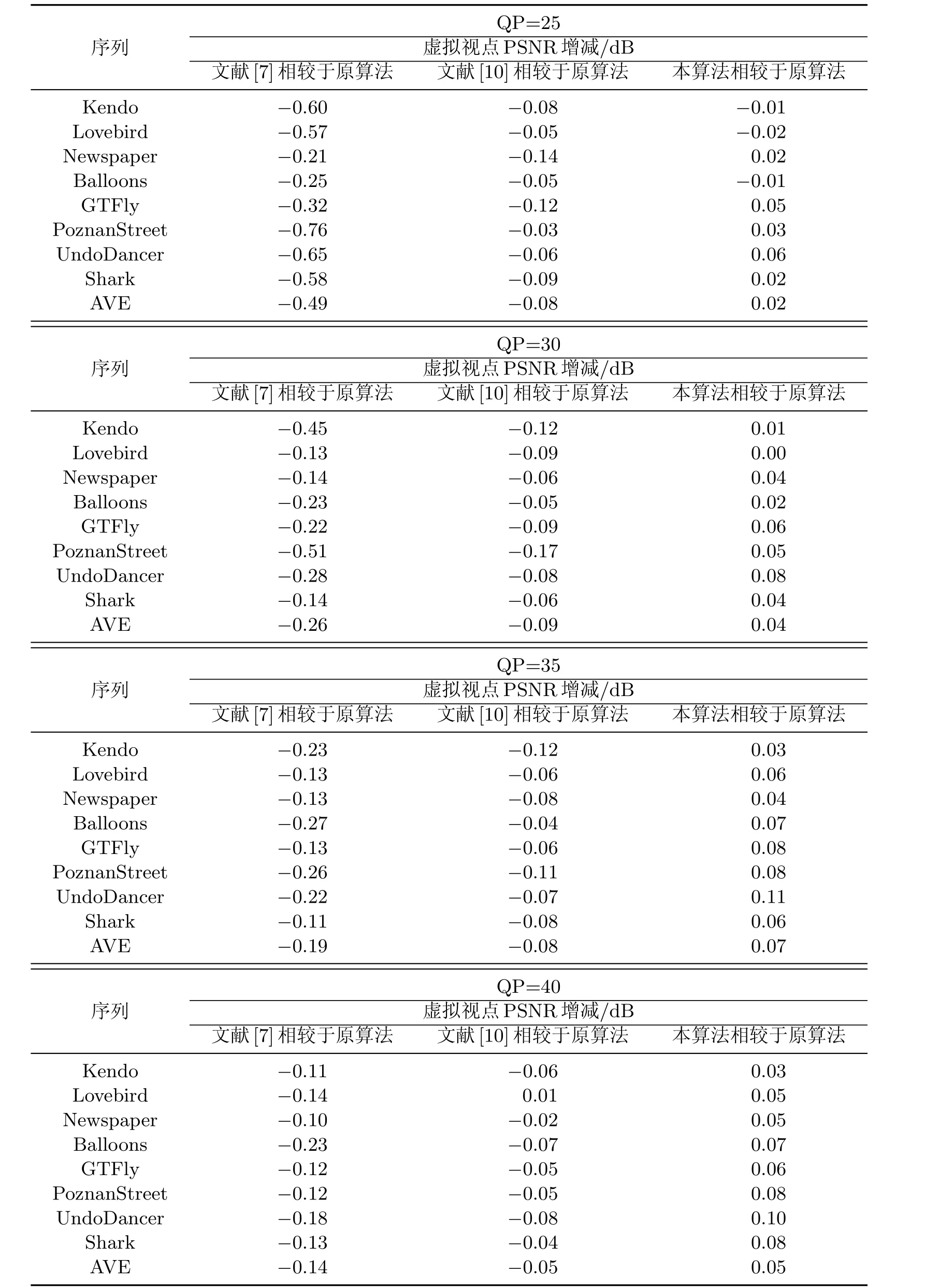
表4 整体算法虚拟视点PSNR实验结果Table 4 Virtual view's PSNR experimental results of the whole algorithm

图9 虚拟视点主观质量比较Fig.9 Comparisons of the subjective qualities of the virtual view
4 结束语
本工作在HEVC编码中融入人眼视觉特性,提出了一种基于3D显著性信息和视点合成预测的3D-HEVC编码算法.本算法一方面根据编码块的时间和空间相关性对当前块进行提前终止SKIP操作;另一方面基于人眼视觉的显著性信息,对编码块进行分区域的模式选择和编码,同时改进原始的视点合成预测算法以提高虚拟视点的质量.本算法在一定程度上提高了3D-HEVC的编码效率,适用于多视点视频加深度的编码平台,并能提高编码效率和绘制质量.
