10年代的最终乐章 即将来临的平台大升级
2019-10-30
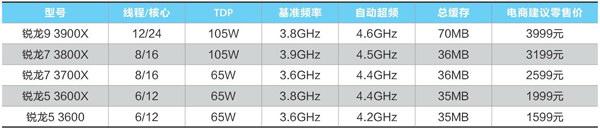
AMD第三代锐龙 性能为王
在整个市场即将迎来的巨大变化中,如果说产品、市场是厂商“玩家”们手里的一副牌(图1),那么牌面应该就是产品的能力、价格等因素,而在牌面之下,真正决定了牌面大小的,却是一些核心技术,其中最突出的就是制程和架构。
2019年下半年,“制程”将是新产品们特别吸引眼球的特性。AMD的CPU与GPU全面进入7nm时代,而英特尔的10nm制程也终于成熟,相关产品都会在下半年逐步进入市场。在同样的架构下,更精细的制程工艺可以让晶体管更小巧,芯片面积、成本、功耗等都会随之降低。
当然,要想获得更好的表现,还需要用更适合制程进步的架构设计。例如AMD的7nm CPU和GPU就分别采用了新的Zen 2和RDNA架构,Intel也在首批10nm工艺CPU中使用新的Sunny Cove微内核架构,不过它在很长时间内将是移动平台的独享。
借助新制程与新架构,PC中最重要的两个核心芯片——CPU和GPU都将在2019年下半年实现一次跨代。与之前的产品相比,这些引领我们进入20年代的新产品,究竟有着怎样的实力呢?
在进入Zen架构时代后,AMD CPU又一次有了与英特尔争夺性能皇冠的实力,近几年也屡次夺得了最强消费级CPU的桂冠,虽然英特尔也屡次迅速反应,重返性能宝座,但比Zen老得多的酷睿架构却逐渐露出了疲态。这一次的新架构锐龙将更加难以应对,甚至已经展现出了长期霸占王座的能力。


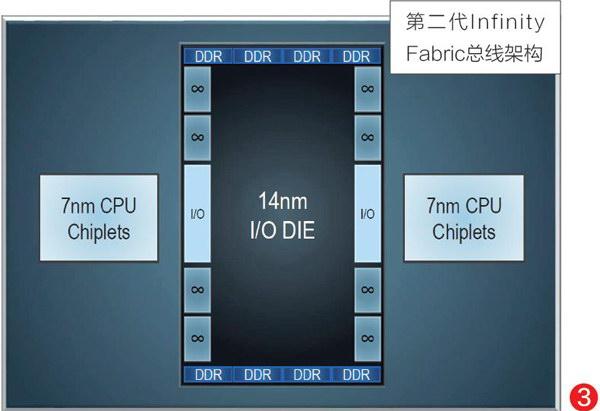
在第二代锐龙推出时,很多人就在质疑为何不采用改进更大的Zen 2架构,而是渐改架构Zen+。而在第三代锐龙现身后,这一问题终于有了答案。很明显,Zen 2在设计时就已经考虑到使用更先进的7nm制程,不仅提升核心效率,而且还结合新一代InfinityFabric互联总线技术,实现了更灵活的模块化配置。
针对核心效率,Zen 2架构的主要改进包括分支预测改进、整数吞吐提升、浮点模块翻番、内存延迟降低、三级缓存容量翻番、频率大幅提高等,将代表核心效率的IPC(每时钟周期指令数)再次提升了15%,单线程性能提升了多达21%。在消费级市场中,核心效率的提升主要表现在游戏能力方面,同样是8核心16线程,锐龙73800X相比于锐龙7 2700X,在主流游戏大作的帧速中可以提升少则10%、多则34%以上。而在之前的Zen、Zen+核心效率已经接近英特尔酷睿的情况下,这一次的效率提升实际上也让锐龙的单核性能达到了与酷睿并驾齐驱的水平。在已经公布的很多测试中,第三代锐龙从单核到多核,也都确实表现出了与对手同等甚至更高的能力。
不过作为通用性极高的计算单元,它是否能在很多针对英特尔优化的软件中有更好的表现,或者获得厂商的承认,同样进行足够的优化,我们尚未可知,而在这方面,近期的一个例子就是最新版的Windows10终于修正了一个针对锐龙CPU的Bug,使得锐龙CPU的效率,特别是多核效率有了明显提升。虽然这一示例对用户来说是积極的,但在初代锐龙已经上市两年多之后才修正了这样的Bug,也说明AMD的厂商优化之路仍然很长。
除了核心效率的提升之外,Zen 2的多芯片设计也更加灵活。毋庸讳言的是,7nm制程在目前仍然是比较困难的,而且对很多芯片来说也是并无必要的技术,所以第三代锐龙采用了I/O部分与CPU分开的设计(图2),在I/O部分中仍然使用12nm制造工艺,也就是所谓的hiplet多芯片设计,或者说是俗称的“胶水”芯片。不过这一设计还是相当实用的,除了降低核心规模、提升良品率外,还可以更加灵活地组合CPU模块,构成更多核心,甚至升级为超多核心的霄龙(EPYC)CPU。
为了保证这样的多芯片设计不会影响整体性能,AMD还使用了第二代InfinityFabric总线,提升模块之间的通信带宽,降低响应延迟。它提升了带宽,采用总线频率、内存频率分离式设计,单位功耗降低了27%,可支持PCle 4.0标准,特别是为消费级CPU应用进行了优化(图3)。
第三代锐龙的基础模块仍然是合有4个物理核心的CCX(CPU Complex),两个CCX组成一个CCD (CPU ComplexDie)独立芯片。其中每个CCX的共用三级缓存增加至16MB,比第二代锐龙翻番,一级缓存也进行了调整以提高效率。不过在大幅度增加缓存的情况下,得益于新架构和新工艺,三代锐龙的每个CCX模块面积却从二代锐龙的60平方毫米缩小为31.3平方毫米,有利于在同样封装下集成更多核心(图4)。

单独的I/O Die集成了输入输出控制中心、一体化内存控制器。每个CCD有各自的InfinityFabric PHY物理层,可直连I/O Die芯片内的数据总线( Data Fabric)。不过各个CCD芯片之间没有直接通道,通信必须经过I/O Die,这样可以保证不同核心、缓存之间的延迟是一致的,让多线程性能提升几乎达到了完全的线性。
Zen架构的内存延迟是比较明显的,也一直是为人诟病且影响性能提升的问题。在第三代锐龙中,内存延迟大幅降低,加上支持更高的DDR4内存频率、翻倍的三级缓存、更准确的分支预测能力,使其性能有了明显提升。
此外第三代锐龙在计算单元的设置、微指令、操作方式等方面也进行了改进,并且支持单操作AVX-256、更快的虚拟化安全、硬件增强安全防御等等,CPU模块设计和操作方式上进行了全面强化和革新。最后,Zen 2作为新的架构,在设计中就已经考虑到从硬件层面避免Meltdown、Spectre等CPU架構漏洞,所以基于这一架构的第三代锐龙也就成了一款相对安全且无需任何底层系统补丁,不会因此造成性能损失的CPU。
在市场方面,第三代锐龙的出现在高低两方面对市场的推动最为明显。低端方面将主流平台的起始标准拉到了6核心12线程,这已经超过了数年前的高端CPU,让主流机型的应用能力大幅提升。而在高端CPU中,它提供的12核心24线程配置则达到了之前专业级CPU的水平,在消费级电脑中运行专业软件会成为很平常的事。
当然,这样的设计会进一步推动对手的CPU不断增加核心/线程,同时消费级应用软件的多线程利用率也必须提升,才能适应CPU的发展趋势。
AMD Navi核心 意料之外的新架构
基于7nm新工艺的AMD Navi核心一直被认为仍继承GCN架构,因此很多人对其性能也就不太看好。不过随着它的正式公布,全新的RDNA架构(图5)突然出现在世人面前,随之而来的还有出乎很多人预料的性能。

要知道,随着GPU架构日益复杂,现在设计一个新的GPU架构甚至要比设计一个新的CPU架构还要难,本次的RDNA架构就花费了长达四年的时间进行研发。它仍采用统一着色器方式,但标量和矢量单元走向融合,支持SIMT(单指令多线程)、ILP(指令集并行)、SlMD(单指令多数据流),使得单线程性能和指令集执行效率都大大提升。它同时集成了GCN架构的指令以保持向下兼容,所以很多基于GCN的技术和优化设计在RDNA架构上也可以得到支持。

已经公布的Radeon R×5700/5700XT(图6)采用的是Navi10核心,集成了103亿个晶体管,比Vega 64的125亿个少了大约18%,核心面积更是小了近一半,只有251平方毫米,但性能却比Vega 64提升了14%,同时功耗降低了23%,因此单位面积性能提升了足足1.3倍,能效比则提升了50%(图7)。
除了RDNA新架构,Navi核心还有支持GDDR6显存、PCle 4.0总线、Radeon媒体引擎、Radeon显示引擎等全新特性。不过它却没有内置硬件光线追踪引擎,这也说明了GPU开发的复杂性,毕竟在4年前预测现在的游戏引擎需求是非常困难的事情。
RDNA架构的设计理念主要有四个方面,性能上要满足现代游戏的需求,能效上要充分优化功耗和带宽利用率,功能上要壮大生态,扩展性上要从移动到桌面到云端通吃。为实现上述目标,RDNA架构主要从CU计算单元、缓存、流水线三大方面进行了变革。
以目前已经公布的Navi10核心为例,它拥有40组新型计算单元,每组有2个标量处理器、64个流处理器、4个64位双线性过滤单元。虽然每一组的流处理器数量没有变化,但执行延迟更低,单线程性能更强,缓存效率更高,整体计算能效比GCN架构有着巨大的提升。从实际游戏测试看,RX 5700(图8)和RX5700 XT(图9)相对于类似价位的对手,在游戏性能方面都拥有比较明显的优势。

RDNA的整个图形引擎也作了重新调整,更加顺畅高效,包括几何引擎、64个纹理单元、4个异步计算引擎(ACE),负载分配更加均衡,可以在更低的功耗下达成更高的频率,能效比更高。它带有位于不同模块的多个零级缓存、512KB一级缓存、4MB二级缓存。多级缓存一致性可以带来更低的延迟、更高的带宽、更低的功耗。
RDNA支持Delta数据压缩,可提高传输率。它还对色彩压缩算法进行了改进,不仅可供显示引擎直接读取,也能被着色器直接读写而无需解压和重新压缩。
最后,它在AMD着力推广的异步计算能力方面也有加强,可以在DX12、Vulkan API下表现更好,更精准地实时控制其他模块。它还借鉴了Zen架构设计的一些先进理念,比如在时钟门控方面提升效率和能效比,同时减少了逻辑层级以达到更高的频率。
在集成显示输出和多媒体处理核心方面,它支持HDMI 2.0/DisplayPortl.4,只需一根数据线即可输出最高4K@240Hz、8K@60Hz的画面。同时它也优化了VR头显显示输出,提供了标准HDR和FreeSync 2 HDR画面输出能力,并针对高分辨率HR显示器进行了优化。
RDNA架构集成的Radeon多媒体引擎大大改进了视频编解码,增加了新的H.265 HDR/WCG编码器,全面支持H.264 1080P@600Hz、4K@150Hz、8K@30Hz解码和1 080P@360Hz、4K@90Hz编码,H.2651080P@360Hz、4K@90Hz、8K@24Hz解码和1080P@360Hz、4K@60Hz编码,VP9 4K@90Hz、8K@24Hz解码,整体编码速度加快40%。
虽然目前的第一代RDNA架构没有专门的硬件光线追踪加速能力,不过AMD面向专业应用的ProRender早就提供了RadeonRays光线追踪功能(图10),面向内容创作渲染和游戏开发,将其转移到消费级产品中应该并非不可能。据称在下一代RDNA架构上,AMD就会通过硬件单元支持光线追踪效果,不过AMD认为将其全部交给本地硬件处理的效率低下,未来会更多借助云计算来实现全场景的光线追踪,这一点与英伟达的DLSS抗锯齿技术有几分相似。

除了基于產品自身能力的性能、能耗、功能方面改进之外,RDNA架构还扩展到了移动市场上,授权给三星移动CPU使用,这一新兴的市场也许会让AMD显示技术获得更大的发展。同时AMD GPU也被新一代游戏主机继续采用,作为在PC之外的市场获得了广泛支持的显示架构,AMDGPU在未来的跨平台游戏、云游戏等应用模式中应该能取得一定的先机。
虽然从功耗、特效支持等角度看,第一代RDNA还算不上成熟,但作为第一款使用7nm制程的消费级GPU,它还是给我们带来了不少新体验,例如超高的图像输出、视频处理能力等。而对玩家来说,细看其游戏测试就会发现,这是一款已经完全为1440P(2K分辨率)游戏优化的GPU和显卡,会推动这一分辨率成为新的游戏主流设置。这一趋势也影响到了对手的产品,随后推出的英伟达RTXSuper系列GPU中,面向最主流用户的RTX 2060Super就将显存增加到了更适合1440P分辨率的8GB。
英特尔Ice Lake 管窥未来架构
与前面提到的另外两款产品不同,英特尔新制程、新架构的lce Lake CPU,或者说是第十代酷睿是面向移动平台的产品,不仅推出时间更晚,也很可能不会有相应的桌面级产品。所以我们对它的了解,只能说是对英特尔未来架构的一种管窥,希望能够窥一斑而知全豹,但免不了有所遗漏。
在各种场合介绍lce Lake的同时,英特尔特别强调的一点就是改变定位,它不是独立的CPU产品,而是英特尔六大技术支柱综合战略的一部分。而六大支柱则指的是制程和封装、架构、内存和存储、互联、安全、软件(图11),它们将帮助英特尔从晶体管为中心转型到数据为中心,并且成为未来发展的基础。


尽管CPU作为一款产品,在新战略中的地位有所下降,但它却仍然是综合了六大支柱的能力的典型代表。以lce Lake为例,它采用全新的Sunny Cove架构及Gen11核显(图12)、10nm制程、支持高达3733MHz的LPDDR4内存和傲腾技术、集成雷电3和Wi-Fi 6,并且进行了安全及软件优化,几乎涵盖了六大支柱的所有方面,是一款可以综合反映英特尔未来战略的产品。

首先是制程和封装,仅从14nm再到1 0nm的提升,就使得晶体管密度提升了2.7倍,达到了1亿个晶体管/平方毫米,为提升计算能力打下了基础。而在封装方面,lceLake也是用了更灵活的I/O控制模块与CPU模块分离的设计,并使用了钌等新材料(图13)。英特尔未来还将引入3D封装技术Foveros,让设计人员可以在同一封装内“混搭”不同的计算单元、存储芯片和I/O配置功能模块,甚至其他各种功能模块,让芯片架构从二维走向三维,将带来指数级的性能和功能增长。
对英特尔来说,架构创新仍然是整体战略的主要驱动力,其中当然也包括lce Lake使用的SunnyCove架构。在内部计算能力的增强方面,其做法与AMD的Zen 2架构有异曲同工之妙,同样调整了缓存,将L1缓存增加了50%,L2缓存翻倍,同样提高了分支预测精度,降低了延迟,也大幅提升了支持的内存频率。此外Sunny Cove架构的寻址单元从4个增加到5个,执行单元接口从8个增加到10个,提高了微架构的并行性能,这显然也是针对核心规模不断增长作出的调整。除此之外,它还提升了一些特定应用的能力,比如通过增加新的AES、SHA-NI指令提高了加解密性能等。所有这些调整的综合效果使IPC效能增长达到了18%,是自第六代酷睿推出以来最大的性能提升。
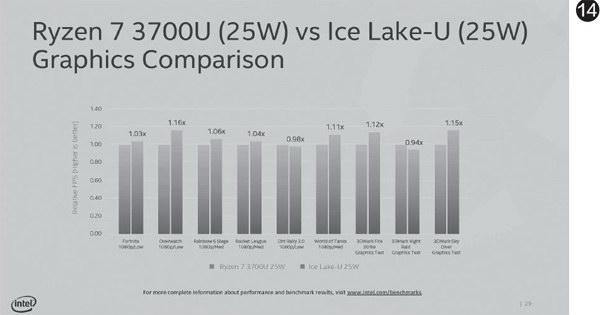
不过lce Lake的通用计算能力增长与其核显的能力增长相比就不算什么了,它采用的核显升级到了Gen11架构,EU单元从目前Gen 9/10的最高24个提升至64个,在1.1GHz频率下,浮点性能高达1.12TFLOPS,FP16半精度更是高达2.25TFOPS。在游戏能力方面,它已经可以达到甚至超过锐龙7 3500U内置显示单元的水平(图14),可以在全高清分辨率下保证主流网游流畅运行,甚至运行3A大作时也可以达到30FPS以上的速度。
此外,Gen 11核显在解码、视频输出、垂直同步技术上大幅升级,双解码单元支持HEVC、VP9硬解,可使用DPl.4、HDMI 2.Ob接口进行三屏独立输出,最高可输出8K@30Hz、5K@60Hz、4K@120Hz的10-bit画面,而且还支持AdaptiveSync自适应垂直同步技术,防止高速画面出现撕裂的问题。
至于存储方面,LPDDR4-3733MHz内存以及DDR4-3200内存可大幅提升外部数据交换能力,并且一举改变英特尔CPU在内存频率支持方面的短板。傲腾内存则拥有远高于一般SSD,更接近DDR4内存的读写性能,可以弥补内存与SSD之间的性能鸿沟。
在lce Lake平台中,40Gbps速率的雷电3接口、近10Gbps的Wi-Fi6无线标准都会成为内置标配。在这个数据为王的时代,更快速地连接海量数据也将带给lce Lake巨大的优势。关于这两个技术及其应用、产品我们已经进行过比较详细的介绍,这里就不赘述了。
至于软件优化、安全性等方面的表现,lceLake及其配套芯片的表现同样会更加优秀。为了简化开发者的难度,Intel将推出One API的战略,可以简化跨CPU、GPU、FPGA、人工智能加速器等各种计算引擎的编程。该项目包括一个全面、统一的开发工具组合,以将软件匹配到能最大限度加速软件代码的硬件上。以Al加速为例,使用新的高效率Al指令后,lce LakeCPU的AI性能相比八代酷睿可提升2-2.5倍。
其他
尽管除了CPU平台和显卡之外的各种产品,在2019年甚至2020年中并不会有形态方面的巨大改变,不过一些相关技术、产品却已经呼之欲出了。在这些新平台中,PCle 4.0标准、雷电3、USB 4、Wi-Fi 6等技术将会造就更多强大的产品,虽然这些产品进入主流可能尚需时日,但它们对PC使用体验的提升将是非常巨大的,甚至可能会改变很多PC的传统应用模式。

以PCle 4.0为例,AMD的第三代锐龙及其X570芯片组将提供带宽倍增的PCle 4.0通道,同时基于Navi GPU的显卡也将支持这一标准。虽然从目前来看,主流独立显卡对外部带宽的需求远没有达到PCle30的极限,只有目前最强的旗舰级显卡在组建多显卡模式(PCle 3.0 x8通道)的时候,才会有外部带宽不足的问题。不过在显卡之外,目前另一个PCle通道的主要用户——M.2 SSD却已经迫切地呼唤着带宽的突破了,支持PCle 4.0的SSD主控芯片和相关产品(图15)已经进行了展示,而传输速度则突破了5GB/s,将彻底改变目前数据存储作为PC中最主要“瓶颈”的尴尬地位。
解决目前的瓶颈之后,我们会发现基于PCle 4.0×4通道的SSD速度已经非常接近内存,那么存储系统只作为一个数据存储的空间使用就有些浪费了,一些新的应用方式将出现在新的PC中。比如可以将高速SSD融入CPU-内存体系中,让一些原先易失性的数据在SSD上获得半永久的保存,关機后内存数据并不会丢失,下次开机后就能直接进入关机前的运行状态,例如QQ直接在线、所有工作可继续进行等。而在笔记本电脑耗尽电力、台式机突然断电的情况下,这一能力更会为用户带来前所未有的便利与安全。
这样的愿景还远非这次平台升级带来的最大变化,因为我们即将迎来的这次PC平台升级影响将极为深远,很可能会在20年代带给我们完全不一样的PC设计和使用体验,让大家进入一个全新的PC时代。