给DNA甲基化检测装上GPS,看肿瘤细胞如何变花样
2019-10-30徐鹏于文强
徐鹏,于文强†
①上海市公共卫生临床中心,上海 201508; ②复旦大学 生物医学研究院,上海 200032
2019年1月22日,复旦大学于文强实验室历时8年研发的全基因组DNA甲基化检测新方法“导向定位测序(guide positioning sequencing,GPS)”在线发表[1],揭示了很多我们不曾想到的规律。开发全新的技术困难重重,个中辛酸难以言表。借着文章发表的契机,我们系统回顾了文章从想法到实现的历程以及GPS所揭示的重要规律,希望为大家提供借鉴。
1 全基因组DNA甲基化检测说起来容易做起来难
随着人类基因组计划的完成,生命科学研究进入了“后基因组时代”,而表观遗传学是“后基因组时代”的重要方向。DNA甲基化是表观遗传学的核心组成部分,对于正常细胞功能维持、胚胎发育等生命过程至关重要,堪称人类基因组的“另外一套密码”。
对个体中的每种组织细胞而言,DNA几乎相同,表观基因组却差异巨大,而且随着时间的变化而不同。典型的例子就是通过检测外周血中特定位置的DNA甲基化竟然可预测一个人的年龄[2]。异常的DNA甲基化与人类许多疾病,尤其是肿瘤的发生发展具有密切关系。因此,进行全基因组DNA甲基化的精准检测和分析无疑对探索肿瘤的发生、发展、转移以及开发新的抗肿瘤策略具有重要意义。
各国科学家纷纷行动。2008年,美国NIH启动了“表观基因组学路线图计划(Roadmap Epigenomics Project)”,计划绘制正常细胞、人类胚胎干细胞等多种细胞的表观基因组。2010年,国际人类表观基因组联盟(International Human Epigenome Consortium,IHEC)建立,旨在检测250种细胞类型中的至少1 000个表观基因组。
全基因组DNA甲基化测序是表观遗传领域公认的“烧钱游戏”,而且由于比对率不够高,造成大量的费用浪费。生物体基因组由A、T、C、G四种碱基构成,当DNA被重亚硫酸盐处理后,未甲基化的C转变为T,构成DNA的碱基只剩下A、T、G,其复杂度大幅度降低。测序完成后,大部分序列无法与人类参考基因组比对(map),DNA甲基化计算无从谈起,而确定重复序列区域的DNA甲基化状态更是全基因组DNA甲基化检测者的噩梦。早期的全基因组DNA甲基化检测的比对率不到30 %[3]。以30 %为例,可以理解为花费的100元中只有30元有用,另外70元测到的序列因无法比对而被白白浪费。与此同时,那70元检测的序列其实是细胞内真实存在的,只是因为技术的限制被人为地忽略掉了,因此这种检测最大的风险可能是“舍本逐末”。考虑到那70 %的真实信息可能也很重要,而当只用30 %的DNA甲基化信息分析时,所得结论难免偏颇。
科学的进步是循序渐进的。2011年通过检测大猩猩和人类各4份精子样本的全基因组DNA甲基化即可以登上《细胞》杂志[4]。可想而知,全基因组DNA甲基化检测是多少人的梦想,同时你也会觉察到,全基因组DNA甲基化检测是“富人游戏”。因此,开发出人人可以负担的全基因组DNA 甲基化检测方法就显得尤为重要。
2 GPS “因运”而生
GPS方法开发纯属偶然。2009年的一天,于文强教授在寻找线粒体DNA甲基化信息时,发现几乎无信息可用。线粒体DNA仅16 kb左右,而当时已进入二代测序时代,如果连一个16 kb的DNA都没有甲基化信息,并不是因为线粒体DNA甲基化不重要,可能是全基因组DNA甲基化检测存在问题,而这些问题无疑会阻碍该领域的发展。合理质疑是解决问题的前提,而要解决一个问题,首先要弄清楚导致这个问题的根本原因。已经有文献报道,WGBS测序最主要的问题是序列比对率低和比对准确性差。如果解决了这两个问题,就很容易突破DNA甲基化检测的瓶颈。
于文强教授在实验室下达了开展 DNA甲基化检测召集令。首先,于文强教授将目前DNA甲基化检测所有方法的优缺点一一罗列,以供参考;然后,他提出如果有谁能够提出全新的解决方案,实验室就会给予不同程度的奖励。为了攻克这个难题,同学们绞尽脑汁。既然DNA甲基化核心问题是比对率低,我们就将重心放在如何提高比对率和准确性上。含有四个碱基的基因组比对没有问题,我们何不借用双端测序的优势,让双端测序的一端是基因组原序列,另一端是转化后的表观序列,那问题不就迎刃而解了!我们将这种全基因组 DNA 甲基化检测方法命名为GPS,即“导向定位测序”(图1)。该方法目前已经获得国内和国际专利。
策略一旦制定,就需要考虑如何实现这一设想。我们想到了T4 DNA聚合酶:在反应体系中没有dNTP的情况下,可发挥3' →5'外切酶的活性;当有反应体系中存在dNTP时,可发挥5' →3'聚合酶活性。不过在反应体系中,我们将dCTP换成甲基化的dmCTP就可以了。这样一来,所有的DNA片段3'端在重亚硫酸盐处理后依然保持基因组序列,可用来定位,而5'端就可用来计算甲基化。我们大约用了一个月的时间证明这种策略可行,从而使复杂的全基因组DNA甲基化检测两大难题迎刃而解。
做研究的人都知道,要创建一个全新方法并让它高效工作,谈何容易。我们要确定酶的用量、酶切的时间、酶切的温度,进而对酶的活性进行精准把控。如果把握不好,要么就将DNA全切完了,要么切得很短,3'端无法定位。这期间我们想了好多办法,难以把握一个精准的度,实验结果反复无常,时好时坏。历经艰辛把所有实验条件稳定下来后,实验数据的分析又成了大问题。由于没有现成的软件可以用,我们只好根据实验设计自己编制分析软件。大约用了3个月的时间,我们编制出第一版的软件。可当比对测序数据时,我们发现200 G的数据需要计算机运行3周,一般的实验室肯定吃不消。后来又编制了一版基于全新分析策略且需借助超级计算机的计算分析软件,200 G的数据大约运行3天,这解决了数据分析的大问题。但我们的本意是开发人人可用的技术,又有多少实验室可用超级计算机来分析DNA甲基化呢?于是我们再次编制了一版全新的软件,目前在普通计算机上,200 G的数据运行时间为3天左右。至此,GPS的实验条件和生物信息学分析软件已全部优化好了。在GPS方法优化过程中,不难看出一个全新方法的产生和成熟确实需要花费很多的心思和精力,而这些难题我们都留给了自己。
3 GPS优势想得到,看得见
GPS 检测全基因组DNA甲基化理论上简单,操作上易行,其优势不仅想得到,也看得见。
3.1 GPS检测 DNA甲基化的精确性
我们从人类参考基因组中随机生成了100 万个双端测序读长并进行相应的改变,以模拟双端测序结果。由于已知这些片段确切的基因组位置,我们可以通过GPS策略计算它们精确比对的概率,进而评估GPS检测DNA甲基化的准确性。如果使用BSMAP进行序列比对,其比对率仅为66.2 %,而GPS 的比对率高达82.3 %,接近于用Bowtie2进行基因组的比对率——86.3 %。在后续具体的实际测序和分析中,我们用焦磷酸测序实验也证明GPS具有极高的准确性,证明GPS具有精准检测的先天优势(图2)。
3.2 GPS 具有较高的比对率
在对肝细胞实际检测中,GPS比对率为 80.9 %,比WGBS 的比对率高15 %~20 %,这主要是WGBS数据的原理上的复杂度降低所致。在人类参考基因组中DNA双链中有1 170 378 405个胞嘧啶(C)位点,以及56 434 896个CpG位点。以目前常用的基因芯片检测方法为例,如450 K或850 K芯片,能够检测到的甲基化位点仅为45万个或85万个,占到人体基因组全部CpG的0.8 %~1.5 %,占全部胞嘧啶的0.04 %~0.07 %,而RRBS能够检测的CpG位点约为1 %。WGBS通常能够覆盖全部CpG位点的90 %左右,认为可以用来准确评估样本的DNA甲基化状态。在肝细胞中,GPS覆盖到了54 853 393个CpG位点,覆盖率高达97 %,同时也覆盖到了1 123 233 333个胞嘧啶位点,覆盖率为96 %。从严格意义上来讲,只有全部确定了人体基因组中每一个胞嘧啶位点的甲基化状态才能算是绘制了人体细胞的表观基因组完整图谱,我们认为,GPS为我们绘制了第一张人类肝细胞的表观基因组图谱(至少是最接近)。
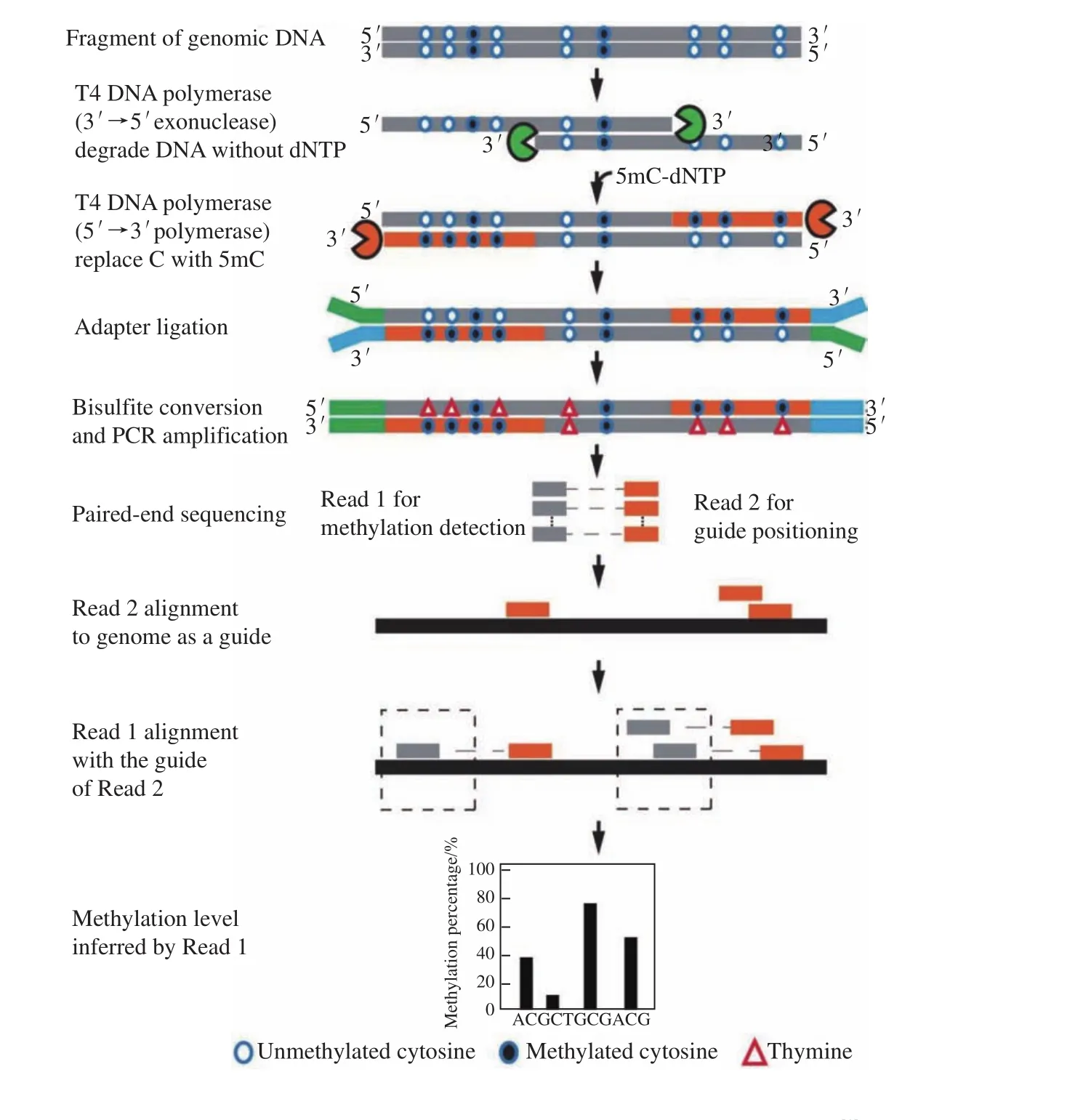
图1 导向定位测序(guide positioning sequencing,GPS)工作原理[1]
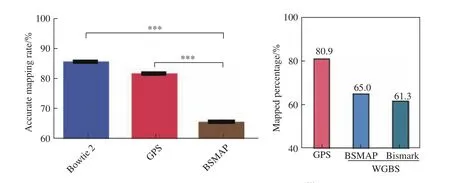
图2 GPS比WGBS具有更高的比对率[1]
3.3 GPS甲基化检测成本低
GPS甲基化检测成本低主要基于GPS的高比对率,同时GPS测序数据比对只要超过5层就能够比较精准地计算出DNA甲基化。而WGBS精准检测甲基化一般情况下需要超过30层。目前GPS对一个样本的检测大约需要200 G的测序数据,在10×Genomics测序平台上大约相当于两条lane的测序数据,测序成本在1.5万元左右,况且可以同时获得基因组和表观基因组数据。
3.4 GPS 检测甲基化没有序列偏好性
通过比较GPS测序和人类基因组功能区的分布情况,很清楚地看到,GPS 检测到的DNA甲基化位点在启动子区域和功能基因组元件上没有分布偏好性。与WGBS相比,GPS对于重复序列、CpG岛以及富含GC(GC-rich)区域(如启动子区域)的检测具有更高的效率(图3)。这些优势对全基因组的DNA甲基化精准检测非常重要,可有效避免测序偏差导致结论的不确定性。例如,肿瘤细胞存在全基因组的DNA低甲基化现象,而偏偏WGBS倾向于检测DNA的高甲基化区域,因此依靠WGBS来评估肿瘤细胞的全基因组DNA甲基化状态就会高估肿瘤细胞DNA实际的甲基化水平。我们的结果也证明了这一点(图3)。
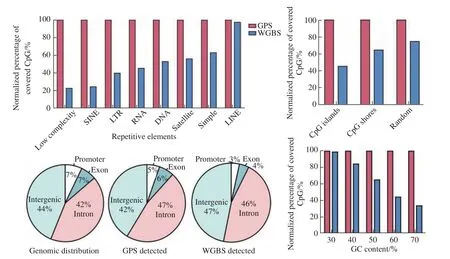
图3 GPS在全基因组范围的覆盖无偏好性,可覆盖重复序列和富含GC区域[1]
3.5 GPS 可以同时检测表观基因组和基因组学变异
GPS特别适用于精准检测等位基因特异性的甲基化(allele-specific methylation,ASM),而ASM检测有助于回答许多表观遗传调控的关键的基础问题。例如,使用相同的数据量,GPS鉴定了1 820个ASM,而WGBS只鉴定了135个。我们也验证了97 L细胞系中的两个ASM,它们定位于CCDC97和TOP1MT基因,这些区域富含转录因子和DNaseI高敏感位点。因此, GPS更适用于研究基因组和表观基因组之间的交互作用(crosstalk),而以前这些问题很难研究清楚。
4 MeGDP:DNA甲基化调控“相反相成”
众所周知,DNA甲基化与基因表达调控密切相关。基因启动子区域的甲基化高,基因表达降低;启动子区域的甲基化低,则基因表达升高。这种调控规律深入人心。但如果将一种特定组织细胞中所有启动子区域的甲基化状态与全部表达基因进行相关分析,发现二者并没有显著相关性,这意味着局部的规律性并不能代表整体的规律性。此外,某些基因的启动子区域高甲基化并不意味着该基因表达一定降低,即有些基因启动子区域的高甲基化,这个基因反而高表达。由此可见,DNA甲基化与基因表达调控并非我们想象的那么简单。后来,全基因组DNA甲基化的检测分析发现,基因体的甲基化与启动子区域正好相反,即基因体的高甲基化与基因的高表达有关,反之亦反(图4)。GPS检测分析发现,这种规律也并不总是对的。例如,基因表达FPKM值超过20时,基因体DNA甲基化不再与基因表达正相关。结果显示,FPKM值超过20的基因,其基因体甲基化程度更低,长度更短,更为保守,而且主要富集在代谢通路上。
那么问题随之而来,启动子和基因体DNA甲基化为何会有截然相反的调控规律,它们之间是否存在内在的联系并共同调控基因的表达?能否仅仅通过DNA甲基化检测来精准预测基因的表达情况,而这一点对于评估某些感兴趣的基因在特殊样本(如石蜡样本)中的表达具有重要意义。
鉴于GPS检测每一个CpG位点甲基化的精准性,当我们用基因体和启动子区域的DNA甲基化差值(MeGDP, methylation of genebody difference to promoter)与基因的表达进行相关性分析时,惊喜地发现MeGDP与基因表达之间的相关性高达0.67,提示MeGDP可以用来预测基因表达的情况(图5)。如果利用WGBS测到的数据进行计算,得到相关系数仅为0.33。在其他样本中应用GPS,也能得到类似的结果,而WGBS结果则毫无规律性可言。由此可见,MeGDP的发现得益于GPS对甲基化的精准检测。
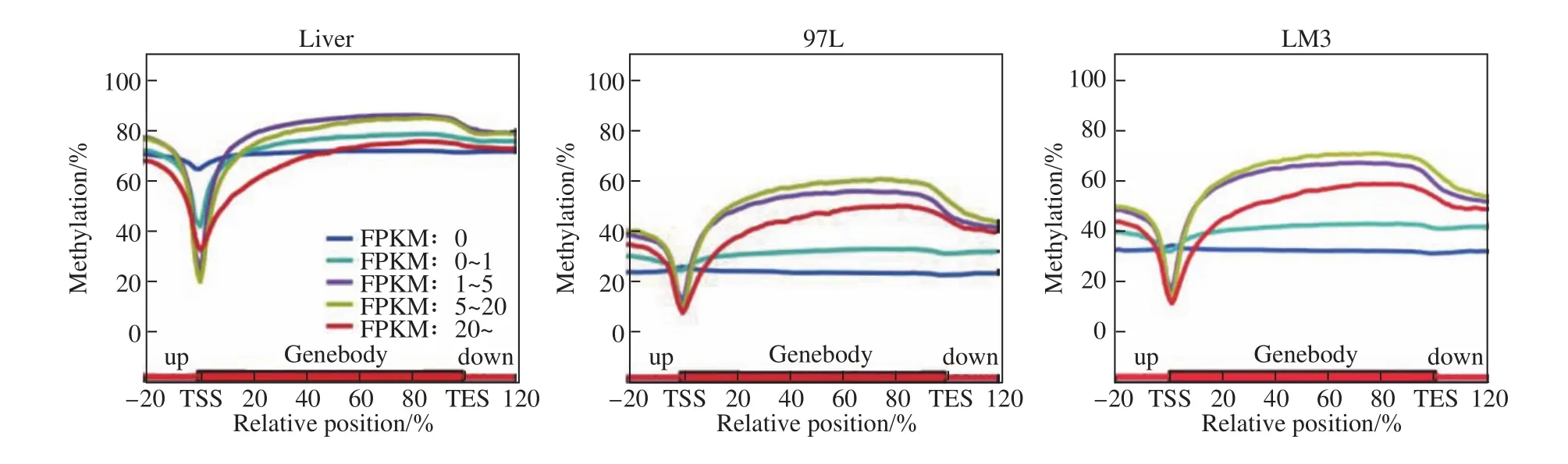
图4 基因表达与启动子区域以及基因体DNA甲基化有关[1]
5 MeGDP:肿瘤免疫新框架和新靶标
切勿低估MeGDP,除了用于特殊样本中基因表达的预测,其重要性远不止于此。肿瘤的发生与免疫功能紊乱以及代谢异常密切相关,但表观遗传因素发挥了什么作用还有待探究。在肝癌细胞中,因MeGDP降低导致表达下调的基因主要富集在免疫与刺激反应以及代谢途径相关基因,而且P值非常低。由此可见,MeGDP可以更好地用来研究肿瘤相关基因的表达调控与肿瘤各种生物学行为的关系。
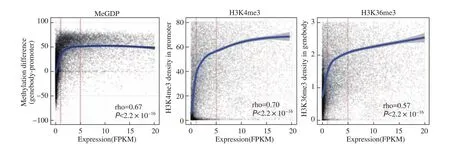
图5 MeGDP、H3K4me3和H3K36me3与基因表达均存在很强相关性
众所周知,肿瘤发生与免疫系统紊乱有极大的关系,免疫监视系统失衡是肿瘤发生的重要原因。肿瘤与免疫监视系统的相互作用(tumorimmune surveillance network)包含两层意思:其一是肿瘤细胞自身,其二是人体的免疫系统。但目前为止肿瘤如何逃避免疫系统还是一个谜。一般认为,肿瘤与免疫监视系统相互作用的重点是免疫系统,即肿瘤中的各种淋巴细胞异常,如火热的免疫治疗正是针对这些“不作为”的免疫细胞。近来有些研究去寻找肿瘤新生抗原(如Neoantigen),理论众多,但实际应用的并不多。因此有必要重新认识并深入理解肿瘤免疫,尤其是从肿瘤细胞自身来重新诠释肿瘤免疫。从表观遗传的角度,任何细胞都可能具有免疫细胞的特性,因此肿瘤细胞自身免疫相关基因的调控也是肿瘤免疫调控的重要组成部分。换言之,对于肿瘤免疫,我们不仅要关注免疫系统,更需要关注肿瘤细胞内在的天然免疫系统基因的调控,而肿瘤细胞中内在的免疫相关基因的甲基化异常导致的基因沉默也许是肿瘤免疫逃逸的重要原因。
我们的研究结果表明,由于MeGDP导致的甲基化异常,肿瘤细胞中内源性的免疫相关基因被异常甲基化所沉默,使得肿瘤细胞对外界的各种治疗或免疫治疗没有反应。据此,我们推测,肿瘤的免疫耐受与免疫系统中的淋巴细胞可能没有必然的关系,而由肿瘤细胞自身的表观遗传学异常这个内因决定。在这个新的肿瘤免疫框架下,寻找预测肿瘤免疫治疗的新靶标可能会出现新的转机。
目前PD-1/PD-L1抗体治疗的大量肿瘤患者没有显著效果,没有人愿意成为其中的一员。摆在临床医生和广大患者面前的一个重要且迫切的需求就是找出一个能够预测PD-1治疗有效性的标志物。现在已经存在一些标志物,比如PD-L1的表达量[5],可是在临床的验证中发现它并不好用。有研究认为肿瘤突变负荷(tumor mutation burden,TMB)不错[6],但TMB并不是免疫治疗特有预测标志物,也可以预测其他治疗方案的效果。总之,目前的预测免疫治疗的有效标志物并不理想。在黑色素瘤病人中,免疫监控相关的干扰素IFNG通路基因的突变或拷贝数丢失使得抗-CALA4反应失效[7]。遗憾的是,IFN通路上60多个基因突变的概率太低,虽然很有意义,但临床应用十分困难。借助GPS,我们对IFN 通路60多个基因的MeGDP与基因表达分析,发现MeGDP异常在肝癌细胞中确实可以导致 IFN 通路中的大多数基因表达下调,进而可能用于PD-1治疗效果的预测。如果想进一步破解PD-1治疗不佳的魔咒,我们认为DNA甲基化抑制剂可能派得上用场,而且已有研究证明,5-AZA(5-氮杂-2'-脱氧胞嘧啶,一种DNA甲基化转移酶抑制剂)确实与肿瘤细胞自身的免疫激活有关。我们也发现,在5-AZA处理后,免疫相关基因EDNRB、ACP5以及BST2都上调2~75倍。此外,我们也有理由推测肝癌细胞中的MeGDP的异常模式导致的免疫相关基因沉默是目前肝癌药物和其他疗法不佳的重要因素。
6 MBS:DNA甲基化调控不仅需要高度,更需要广度
MBS的发现和定义纯属偶然。MBS即methylation boundary shift,意为甲基化边界漂移。谈到DNA甲基化对基因的调控,我们大多关注DNA甲基化高和低,因为这直接决定了基因表达的低与高。然而,当我们将正常肝细胞和肝癌细胞的甲基化测序数据比对到参考基因组后,在UCSC genome browser站点上发现,与正常肝细胞相比,肝癌细胞中以TSS为中心的启动子区域DNA低甲基化范围在大多数情况下总是显示出更广阔的“V”字形模式(wider opening)。这是巧合还是规律?我们发现肿瘤细胞中启动子区域确实存在甲基化边界的漂移(图6左)。如图所示,MBS现象在肿瘤细胞中非常清楚。MBS在肿瘤细胞中的出现,会有怎样的生物学功能呢?
6.1 MBS与组蛋白修饰的关系
MBS所在区域与H3K4me3高度重叠,但MBS与H3K36me3富集是互斥的(图6右)。

图6 97L细胞中MBS、H3K4me3和H3K36me3的分布[1]
6.2 MBS与基因表达有关
我们的结果表明MBS向基因体方向的漂移与基因的高表达密切关联(图7左)。MYC基因就是一个典型的例子。肿瘤细胞中MYC基因高表达,但其调控机制很多,而在这里清楚地看到MYC基因的启动子区域存在显著的甲基化边界漂移(图7中),而且这种甲基化边界漂移模式与H3K4me3的峰长相一致(图7右),说明MBS至少在一定程度上与肿瘤细胞中MYC基因的表达上调有关。
既然MBS与基因表达有关,那么MBS是否与肿瘤的发生相关呢?通过对肝癌细胞中异常的MBS模式及相关基因表达进行分析发现,这些基因富集在核糖体和细胞周期相关的通路。白血病细胞与正常造血祖细胞的形态学鉴定,很重要的一条标准就是细胞核中核仁的数量。核仁数量越多,是白血病细胞的可能性就越高,而核仁的增多离不开核糖体相关基因的高表达。如果按照传统的甲基化调控理论,可能会认为rRNA基因不受表观遗传学调控,因为所有rRNA基因的启动子均是低甲基化。而MBS揭示,DNA甲基化的边界漂移与肿瘤中rRNA的高表达有关。进一步分析发现,在60多个核糖体相关基因中,有48个核糖体基因的表达调控与MBS相关,而应用WGBS只发现了7个,再一次印证了GPS检测甲基化的精准性。可以想象,如果甲基化的检测准确性存疑,甲基化边界的漂移鉴定就变成了一项不可能完成的任务。哪怕比较幸运,偶尔在WGBS数据中发现了MBS,但因为在下一个样本中没法重复,也很难得到规律性的结论。我们在两个乳腺细胞系MCF-10A以及MCF-10A-1H中进行GPS测序,同样发现MBS及相似的调控规律,说明MBS调控具有普遍性。
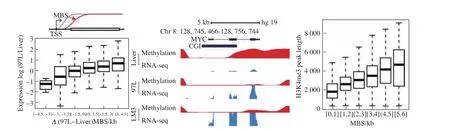
图7 MBS与基因表达的相关性[1]
7 MBS:增强子与细胞身份“得”与“失”
人类基因组中有数百万的增强子元件,其中H3K27ac是活性增强子的标签。既然启动子区域存在明显的MBS,我们自然会想到,作为与启动子类似的顺式调控元件,增强子是否也受到MBS的调控。我们的答案是肯定的。在肝细胞和肝癌细胞中,H3K27ac的峰宽也与MBS高度重叠(图8左),提示MBS与H3K27ac具有相关性,进而对基因表达产生影响。与正常肝细胞相比,肝癌细胞的MBS发生了显著的变化,进而引起增强子活性的选择性丢失或重新获得,这些增强子变化可导致相应的基因表达发生变化。我们惊讶地看到许多基因与细胞的身份相关,如肺发育、免疫细胞激活或其他组织特异性的基因。因此有理由相信,正是由于MBS异常模式导致肿瘤细胞增强子边界和活性变化,进而促使组织特异性基因表达上调或下调,引起细胞身份的得与失,而这一切也许在肿瘤发生和转移过程中与肿瘤细胞特性的形成密切相关。
8 肿瘤转移,也许就是肿瘤细胞身份转变
转移是晚期肿瘤的显著特征,关于肿瘤转移的假说层出不穷,主要包含肿瘤干细胞理论、肿瘤微环境理论、上皮-间质转化理论、“种子—土壤”学说等10种。经验告诉我们,对于绝大多数肿瘤而言,一旦转移,留给患者的时间就不多了。到目前为止,肿瘤转移的研究还停留在“假说”阶段。换句话说,假说依然是“假”的,并没有被证实,所以我们对于肿瘤转移依然束手无策。
“同化共生”(assimilated symbiosis),是我们基于我们的研究结果提出的有关肿瘤转移的一个新概念。肿瘤细胞通过改变身份与特异性转移的器官相互适应,进而在转移的组织器官中与新的环境“同化共生”,可能是肿瘤转移的新机制。物以类聚,人以群分,肿瘤的发生和转移也一样。肿瘤转移是肿瘤治疗失败的重要原因之一,而肿瘤特异性的器官转移机制并不清楚。例如,肝癌容易发生肺转移,通过分析肝癌细胞97L和肝癌特异性转移到肺的LM3细胞的DNA甲基化模式和基因表达情况,发现肝细胞特异性的基因表达显著降低(图9左),而肺细胞特异性的基因表达上调(图9中)。我们认为肝细胞身份丢失和肺细胞身份的获得是肝癌发生肺转移的重要原因。在肝癌发生和转移过程中,伴随异常的DNA甲基化介导的细胞身份的丢失和获得,使肺特异性基因表达增加,从而使肝癌细胞获得了肺细胞的身份,这有助于肝癌细胞在肺的环境中适应和生存,而这也许是肿瘤转移最重要的原因。简单地说,就是细胞换了个“马甲”,从而实现了“同化共生”。
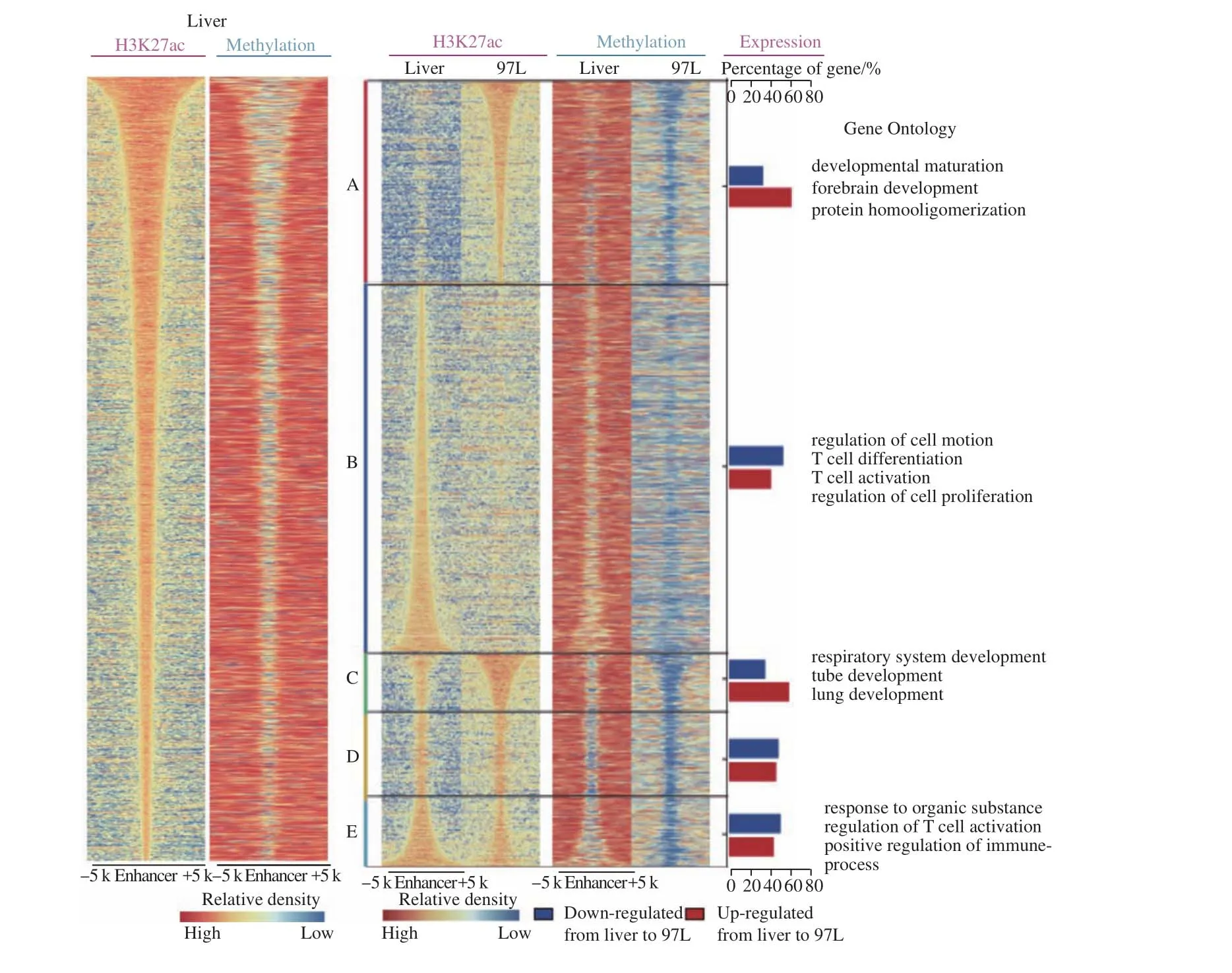
图8 增强子与MBS具有一致性
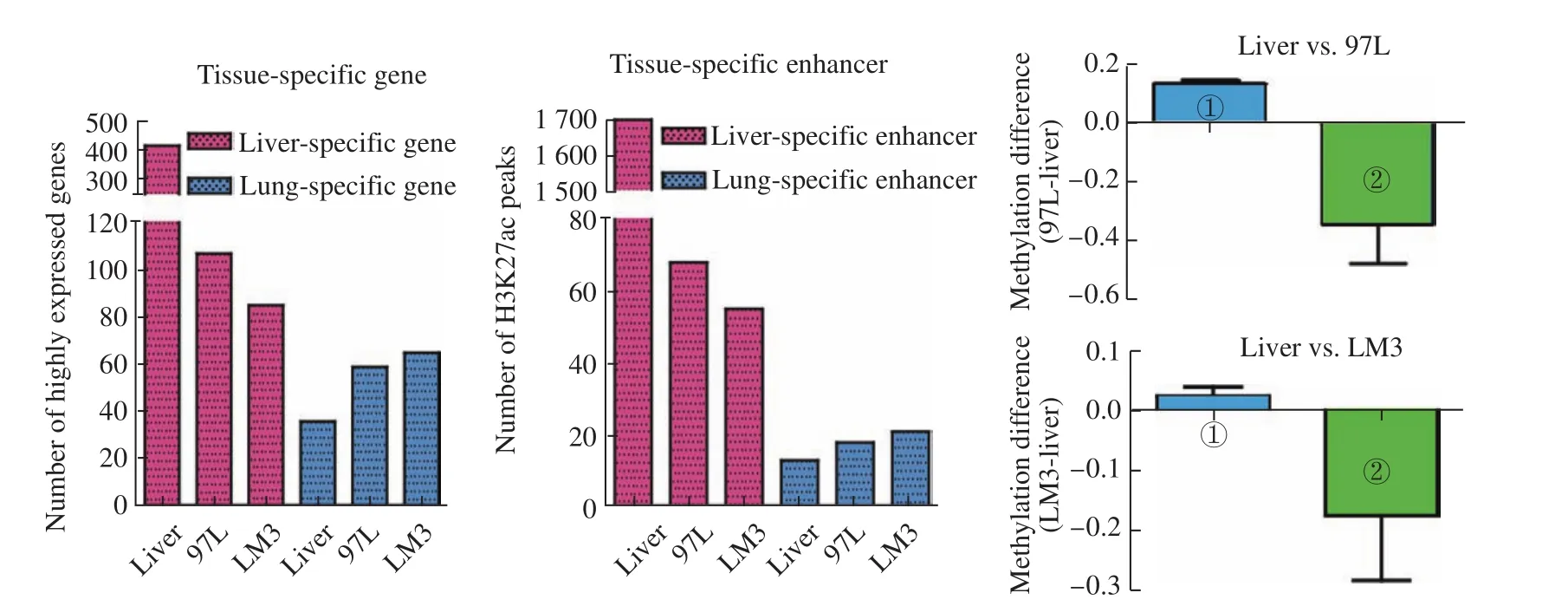
图9 肝癌发生过程中细胞身份的丢失[1]
和我们预想的一样,在97L和LM3肝癌细胞系中,肝特异性高表达的基因的数目分别降低了74 %和80 %。例如:一方面,在97L和LM3细胞中,肝特异性基因ONECUT2表达沉默,这与H3K27ac峰的丢失以及肝特异性增强子区域DNA甲基化的增加相一致(图10左);另一方面,在97L和LM3中观察到肺特异性基因CKS2的表达升高,这与H3K27ac峰的升高以及肺特异性增强子中DNA甲基化的降低相一致(图10右)。在LM3中肺特异性的基因的表达可以帮助它们更好地在肺环境中适应和生存,即实现了“同化共生”,而肿瘤细胞身份的丢失以及其他细胞身份的获得是肿瘤发生转移的前提条件和重要转折点。
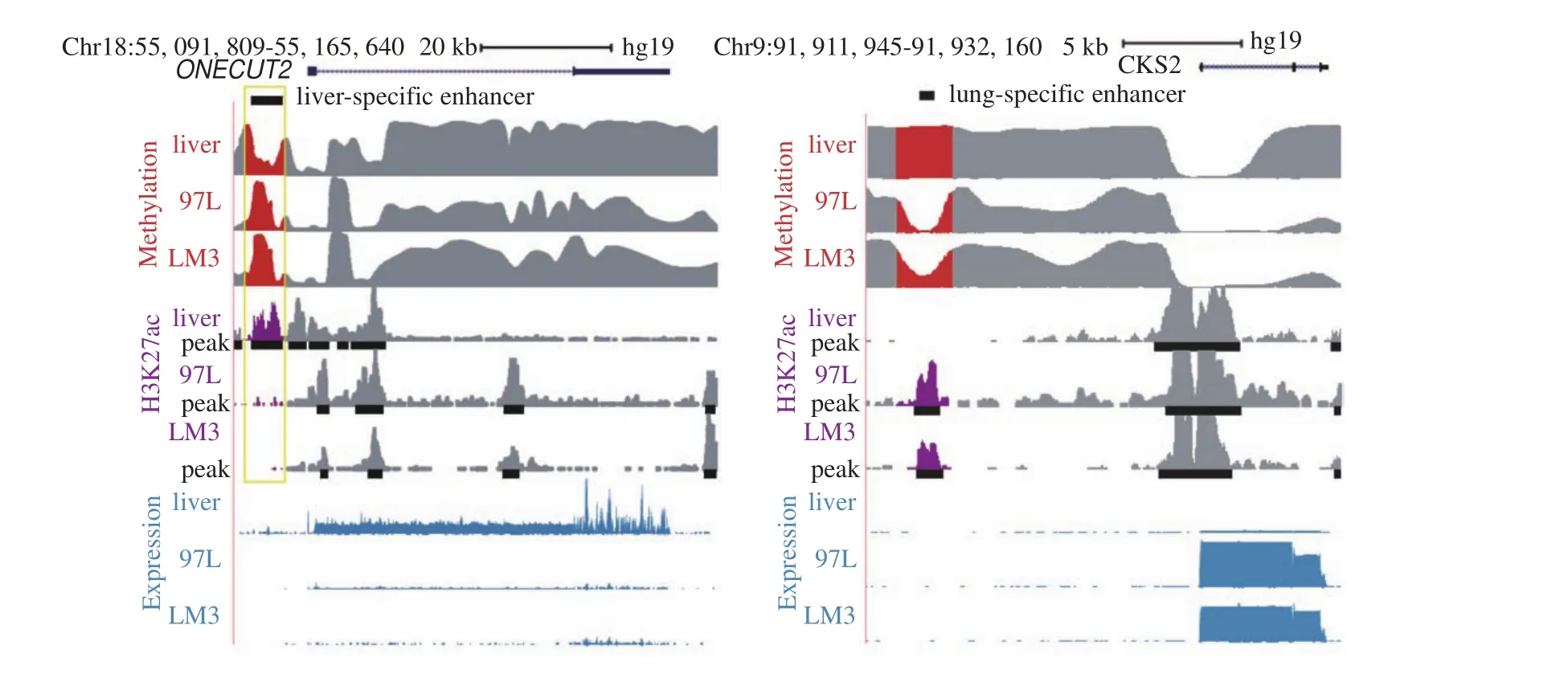
图10 肝癌发生和转移过程中肝/肺特异性基因的表达变化[1]
“同化共生”背后的表观遗传因素可能是肿瘤发生特异性器官转移的重要分子机制,这为我们理解肿瘤转移提供了全新的视角。
