图书馆馆藏借阅与网络口碑关系实证研究
2019-10-23
图书馆馆藏借阅与线上书店图书消费均为图书用户行为,借阅数据和网络销售口碑是图书用户行为的客观描述。网上书店提供的图书信息是图书馆图书采访的重要信息源,包括基本信息、内容信息、作者信息、推荐信息、评价信息、市场信息等6方面[1],是图书馆图书采访的重要参考。在这6类信息中,评价信息是比较特殊的图书信息。图书网络销售产生的口碑数据,既不属于图书的客观描述信息也不属于图书经营主体所产生的推介信息,而是由消费者的消费行为和阅读行为产生的,是图书用户行为的客观描述。
经文献调研发现,国内普遍重视图书借阅量和馆藏利用率研究[2-4],而关于图书网络口碑的研究都集中在图书出版题材选择、销量预测、推荐购买等方面[5-7]。有研究将网络口碑在网上书店荐购服务中的应用延伸到图书馆借阅推荐中[8],但关于图书馆馆藏借阅与图书网络口碑之间关系的研究仍处于空白状态,网络口碑只是作为图书馆选购畅销书的一个参考指标[9]。本文以中国石油大学(华东)图书馆(以下简称“我馆”)馆藏中2016年出版的图书为样本,研究图书馆馆藏借阅与图书网络口碑之间的关系,为图书馆图书采访和馆藏结构优化提供参考。
1 数据与变量
以我馆馆藏中2016年出版图书为样本,收集图书自出版之日至2018年4月30日的借阅数据和网络口碑数据。首先通过我馆汇文Libsys系统的报表功能获取馆藏中2016年出版图书的基本信息,共25 030种,然后抓取样本网络口碑数据。为了数据格式的规范和统一,优先选择自营业务占主体的当当网和京东网。由于京东网不提供准确的书评数量数据,并对每种图书只提供1 000条非自动回复评论,因此选择当当网作为信息源。以图书国际标准书号(ISBN)为依据,获取当当网上截至2018年4月30日的图书评论信息。如果书目出版信息与当当网不符,则以当当网为准。数据优先选择当当自营,如果并非自营,则选择销售量最多的第三方商家数据。在25 030种馆藏图书中获得有效图书口碑数据的图书共20 205种。为保证研究的有效性,剔除借阅量为0(12 508种)或评论数量为0(847种)的样本[5],有效样本共计7 528种。将这7 528种图书的定价、出版天数、当当网口碑信息等特征数据与总体样本进行单样本t检验,结果表明样本数据除出版天数、复本量以外大部分数据无显著差异,因此可以认为样本与总体样本不存在明显差异。对于每种图书,我们收集了以下相关数据。
1.1 借阅数据
通过汇文Libsys系统的报表功能获得每种图书不同复本的借阅次数,然后求和计算每种图书的总借阅次数。
1.2 网络口碑数据
当当网评论机制是注册用户购买图书后才可发表书评,评论包括对图书进行星级评分和文字评论。星级评论1星为差评,2~3星为中评,4~5星为好评。如果购买后15天没有发表评价,则自动生成无文字评论的用户默认好评。当当网在每种商品页面上实时显示平均星级评分、全部评论数和各种评价的数量。因此,获取的数据包括每本书的平均星级评分、总评论量、好评数、中评数、差评数、自动评论数,然后根据相关数据计算好评、中评、差评在总评论中所占比例。
1.3 其他控制变量
收集其他相关变量来控制不同种类和特征的图书潜在的异质性影响,包括以下几方面。为了控制价格因素对图书借阅和销售的影响,收集了图书的定价;为了控制不同类别图书借阅评论的区别,收集图书的《中国图书馆分类法》(以下简称“中图法”)分类号,并按中图法分为22个大类;为了控制不同复本数量对图书借阅的影响,收集了图书的馆藏复本数。由于我馆保存在单本库、教材样本库及小语种阅览室的部分图书复本不能外借,为避免不可流通复本对分析结果的影响,只将可流通复本数作为研究对象。
表1为样本类目分布情况。从表1可看出样本类目分布非常不均衡,占比最高的两个类目为文学I类和工业技术T类,合计占比超过五成;而部分类目仅为几十种,S类和V类的样本数为0。

表1 图书类目分布
表2展示了样本数据描述性统计结果。从表2可看出不同样本在定价、出版天数、可流通复本上具有较大差异,说明样本具有良好的代表性。借阅量和评论数量的平均数和中位数存在较大差异,说明只有少部分图书获得大量的借阅和线上评论。消费者对图书星级评论普遍较高,中值和平均数均接近满分5分。
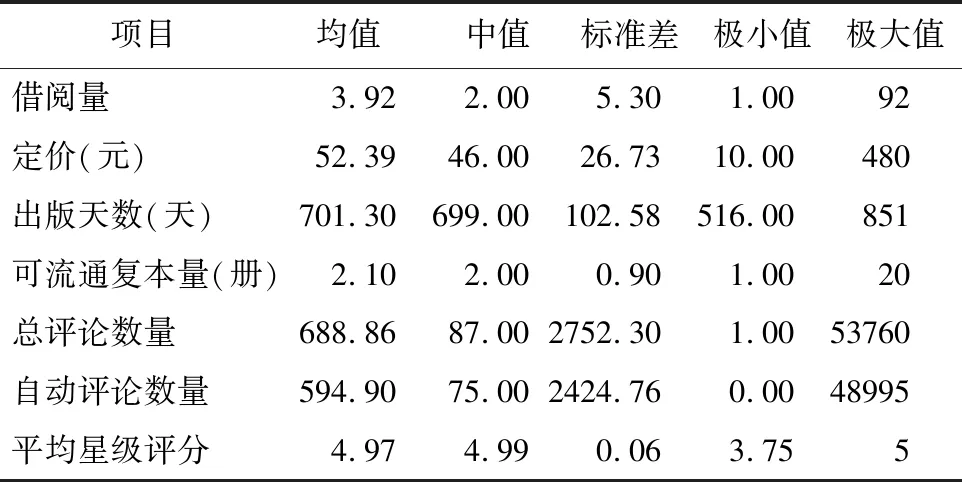
表2 数据描述性统计
其他口碑评论数据中,好评占总体评论量的比例高达99.52%,中评和差评占总体评论的比例分别为0.34%和0.14%。
分析中所涉及的变量信息见表3。由于数据存在较大的量级差距,有的图书评论数有几万条,而有的仅几条。为了压缩变量的量纲,同时将潜在的非线性关系转化为线性关系,以增强回归结果的稳健性,我们对所有连续性变量进行对数化处理,包括借阅量、复本量、定价、出版天数、总评论数、自动评论数、平均评分。好评比例、中评比例、差评比例等百分比数据不需要对数转换,类目为哑变量,同样不需要对数转换。
注:类目为哑变量,样本按照中图法分为22个大类,由于S和V类样本数为0,所以共20类
2 网络口碑数据对借阅量的影响
2.1 相关性分析
表4为主要变量相关关系矩阵。从表4可看出借阅量与网络口碑中的总评论数、自动评论数存在显著的正相关,而与平均评分、好评比例、中评比例、差评比例无明显的相关关系;与复本量、出版天数存在显著的正相关,需要在模型中控制其影响;与定价存在显著的负相关,同时定价与大多数网络口碑数据存在显著的负相关,只与中评比例和差评比例存在显著的正向关系;出版天数与借阅量及大多数网络口碑数据存在显著的正相关,与差评比例存在显著的负相关,说明随着出版天数的增加,借阅和图书销售都会增加,差评比例也会显著下降。此外,总评论数与自动评论数的相关性高达0.998,说明用户默认好评在总评论数量中占主要部分,具有文字的用户主动评论非常少。为了避免多重共线性,我们剔除自动评论数,以意义更全面的总评论数代表总评论量。
此外,类目作为无序多分类变量,以哑变量的形式进行相关性分析,可以注意到20个类目哑变量与其他变量的相关性并不一致,大部分哑变量与借阅量、复本量显著负相关,与总评论数、自动评论数显著正相关,与定价、出版天数显著相关但正负向不一致,与平均评分、好评比例、中评比例和差评比例无明显相关。I类和T类两个哑变量比较特殊,它们与几乎全部变量存在显著的相关关系。结合样本类目分布(表1)认为具体分类样本数量影响了分析结果,需要在模型中控制其影响。
2.2 线性回归分析
根据相关性分析结果,建立3个独立的线性模型进行回归分析。3个模型的不同之处在于模型(1)使用总评论数来解释借阅量,而模型(2)在模型(1)的基础上添加平均星级评分、模型(3)用好评比例和差评比例替换星级评论数。通过上述模型,我们能够分析网络口碑数据中不同变量对借阅量的影响。
借阅量i=α0+α1定价i+α2出版天数i+α3复本量i+α4-22类目i+β0总评论数i+ε
(1)
借阅量i=α0+α1定价i+α2出版天数i+α3复本量i+α4-22类目i+β0总评论数i+β1平均评分i+ε
(2)
借阅量i=α0+α1定价i+α2出版天数i+α3复本量i+α4-22类目i+β0总评论数i+β2好评比例i+β3差评比例i+ε
(3)
因变量均为借阅量,模型中用下标i来表示第i本图书。在控制变量中,类目表示图书按中图法分类的哑变量(中图法类目共22大类,由于S和V类中没有样本,所以共20个类目,加入19个哑变量)。总评论数、平均评分、好评比例和差评比例是我们关注的网络口碑数据。平均评分表示图书i的总体评分,好评比例和差评比例分别从正负两方面说明用户评论的影响。由于平均评分与好评比例、中评比例、差评比例均存在高度的相关关系,为了避免多重共线性,分别分析它们对借阅量的影响,模型(2)在模型(1)基础上加入平均评分,在模型(3)中将平均评分替换为好评比例和差评比例。通过计算模型的方差膨胀因子(VIF),所有VIF值均在3以下,表明所有模型的多重共线性均在可接受范围内。 表5为回归分析结果汇总。模型(0)为基准模型,包含与借阅量有关的其他控制变量,没有加入网络口碑数据。模型(0)的作用主要是对比加入网络口碑数据后模型的拟合度是否有明显的提升,以此判断网络口碑数据对借阅量的影响。从表5可知,模型(1)、模型(2)和模型(3)加入网络口碑数据后,调整R方均由0.141增加到0.228,说明在加入网络口碑变量后,模型的拟合度明显提高了。但是模型(2)和模型(3)在模型(1)基础上新加入变量后的调整R方相同,并未有效提高模型拟合度,F值反下降,由此可以推导出网络口碑数据对借阅量的解释主要来自模型(1)中加入的总评论数。
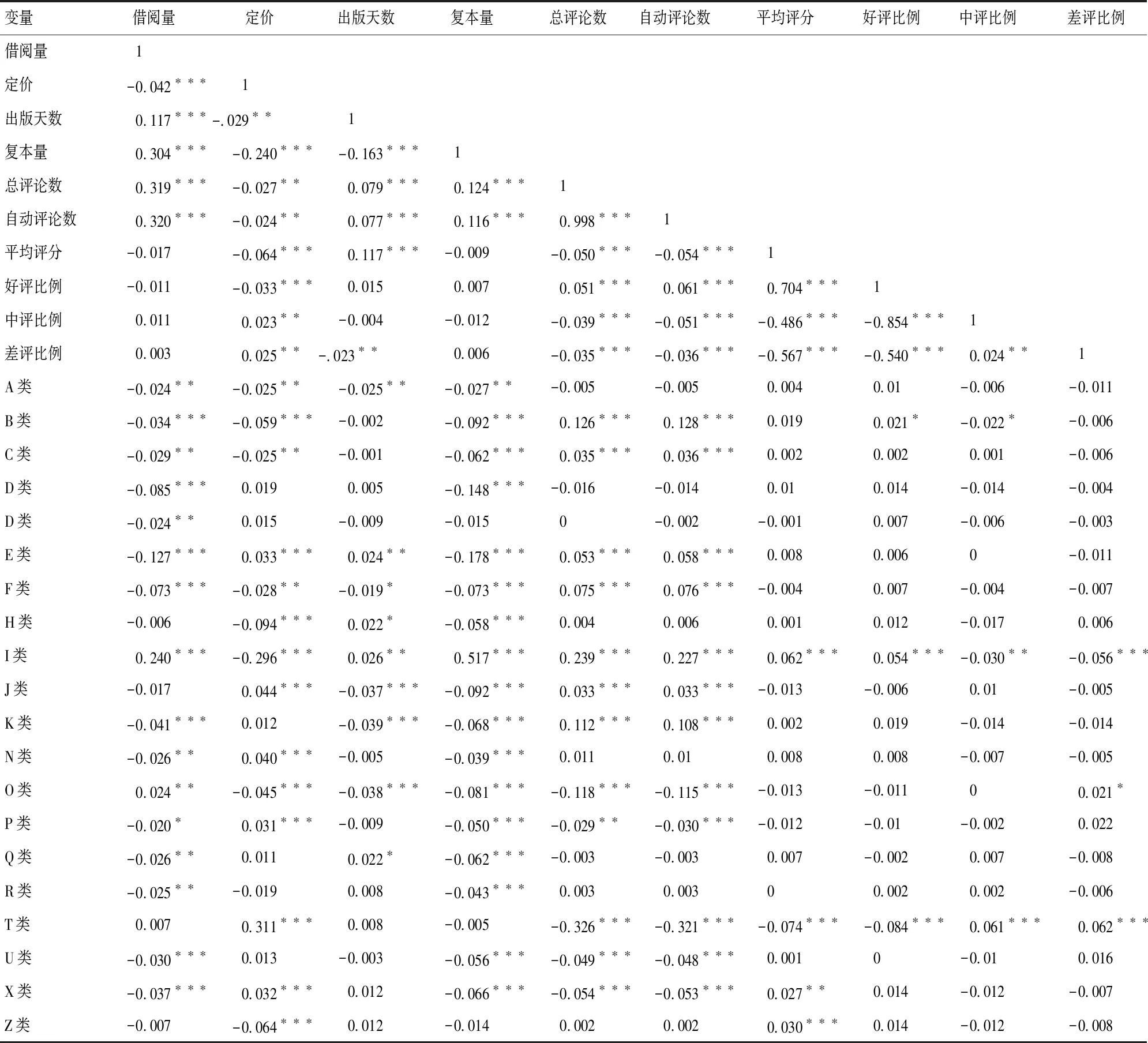
表4 变量相关关系矩阵
注:*代表P<0.10 ;**代表P<0.05 ;***代表P<0.01
在所有模型中,出版天数和复本量是最重要的控制变量。如在模型(1)中,出版天数的系数为显著的正向相关(α2=0.763,P<0.01),说明图书出版时间越长,其借阅量越大;而复本量同样显著正向相关(α3=0.492,P<0.01),说明复本量越大,其借阅量越高,均符合对图书借阅的常识认知。
在模型(1)中,我们主要关注总评论数对借阅量的影响。总评论数的系数呈显著正相关(β0=0.145,P<0.01),说明图书借阅量随总评论数增加而增加,总评论数每增加1%,借阅量增加约0.15%。在模型(2)和模型(3)中,我们主要关注平均评分、好评比例和差评比例对借阅量的影响。首先,从显著水平上来看,平均评分和差评比例的P值均大于0.1,只有好评比例的显著性(P=0.053)具有统计意义,说明用户平均星级评分和差评对借阅量没有显著的影响,只有好评对借阅量存在统计关系。但好评比例的系数(β2=-1.257)为负,说明好评比例越高,借阅量越小。参考前面相关性分析中总评论数与平均评分、好评比例的显著的负相关系数,不符合常识认知。原因在于用户主动评论比例非常小,随着图书的总评论量变大,差评数量同步增长,导致平均评分和好评比例反而低于总评论量低的图书。
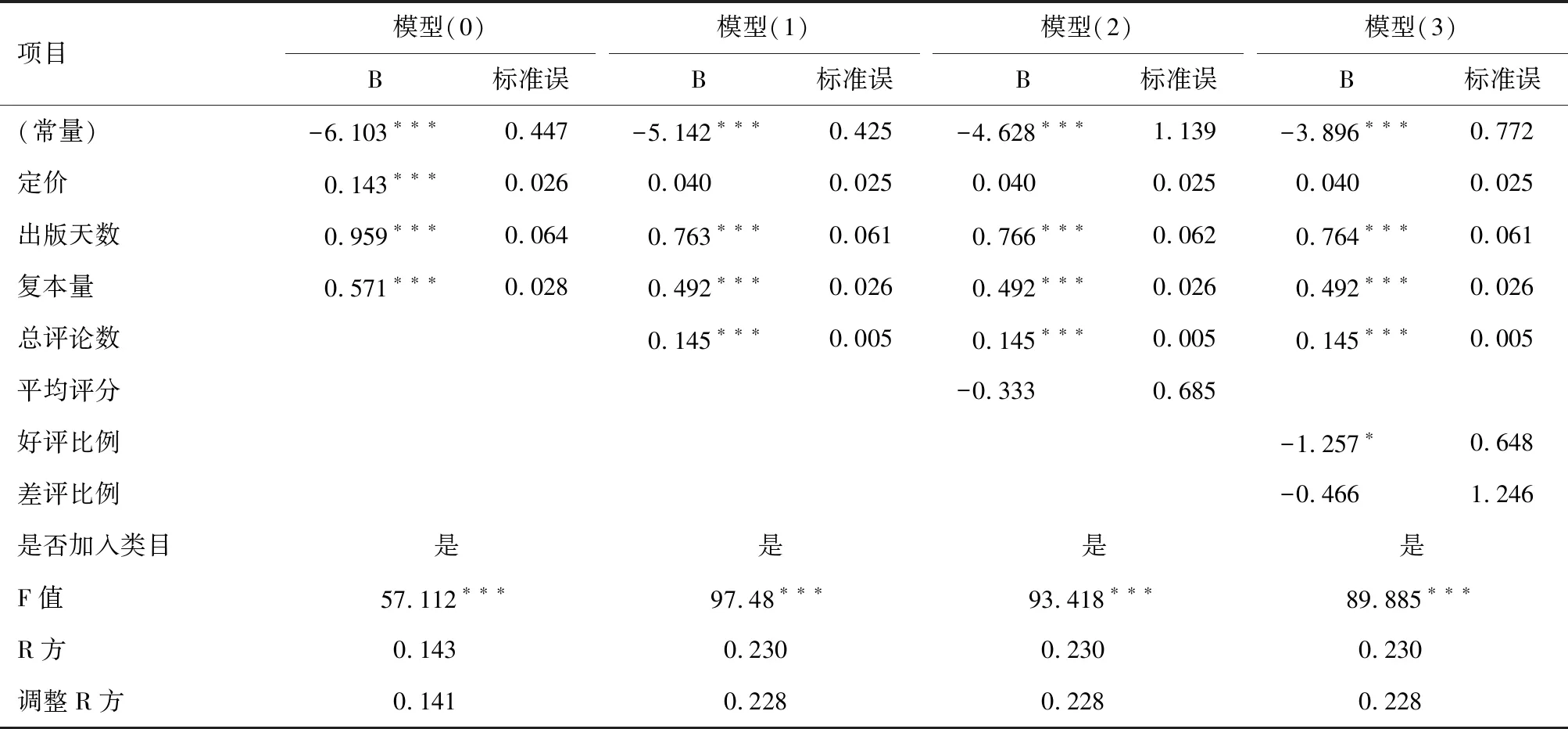
表5 图书借阅变量回归分析汇总
注 :*代表P<0.10 ;**代表P<0.05 ;***代表P<0.01
3 结论及启示
提高图书借阅率,避免零借阅现象是图书馆目前工作的重中之重。本文对图书馆图书借阅量与网络口碑数据之间的关系进行了实证分析,结果显示在网络口碑数据中总评论数与图书借阅量有显著的正向相关。由于网络书店克服了传统书店的空间、地域和种类数量等因素限制,能够满足社会总需求中的长尾部分,反映了全社会读者对图书的总体需求情况。而图书借阅量则受到图书馆内外因素共同限制,内部因素包括复本数量、借阅规则、入藏时间等,限制了读者图书借阅,文中对可流通复本量的分析证明了这一点;外部因素包括专业分布、学生规模、教学科研特点、研究领域等,这些因素与图书馆馆藏情况无关,只与读者群体的自身差异有关,即学校个体需求与社会总需求是不同的。图书馆应分析用户信息需求,明确自身限制借阅因素,提高馆藏利用率,减少零借阅现象。
本文对图书馆管理实践提供了启示。图书馆可以以网络书店销售类目分布特征优化馆藏图书类目结构,以网络书店销售评论的类目特征为依据建立一个以借阅率为导向的最优馆藏类目结构和新书采购类目结构,提高借阅量和馆藏借阅率。如以2016年大学征订图书目录为样本,获取图书在当当网销售一年的评论数量,然后以评论数量中位数以上的图书统计类目分布比例。它可以作为面向公众的公共图书馆的馆藏建设类目标准,高校图书馆可以参考自身专业设置和教学科研需求等因素,对其做相应调整。其次,图书采访应覆盖类目高书评图书。高书评图书是指评论量超过所在类目同期出版图书的评论量平均数的图书,根据当当网数据计算一般不超过所在类目同年出版种数的20%。具体平均数指标可以使用上一年度或近两年的类目总评论数均值作为参考。覆盖高评论图书可以以最少的资源覆盖借阅量最高的图书,实现经济效益最大化。高书评书目可以参考网络书店的销售排行榜,如当当网以日、周、月、年等周期,按44个大类544个小类提供每一类销量最高的前500种图书,基本覆盖了高评论图书。我馆已经开发相应的爬虫软件用于高评论数量书目抓取。同时,高评论数图书应该配置高复本,以防止供应不足。我们可以通过书评数量计算借阅量,从而得出合适的复本数量。
