AI安防芯片的发展现状与前景分析
2019-10-23北京比特大陆科技有限公司汤炜伟李晓松
■ 文/北京比特大陆科技有限公司 汤炜伟 李晓松
关键字:ASIC NPU CNN RNN DNN

1 引言
从2015年以来,随着深度学习而掀起的人工智能的第三次浪潮是由技术驱动。但进行到现在,人工智能的产业发展关键在于商业化。商业化仅仅依靠技术本身是无以为继的,AI市场容量、应用的深度、数据的规模决定了人工智能在某个具体行业的发展速度。就这一点而言,得益于平安城市十几年的建设,安防行业的智能化走在了前面。
根据美国信息服务社的数字,截至 2015 年末,全球已安装了超过 2.45 亿个视频监控摄像头,我国已安装的监控摄像头也已超过 3000 万个,而同时全球和国内监控摄像头销售市场仍在逐年扩张,每年仅仅我国就产生数万PB的数据量。与数据量同步增长的,是巨大的市场规模。国内安防市场在近十年来飞速发展,市场总产值从2012年的3240亿,增长到了2017年的6480亿,研究机构预计到2022年会达到万亿规模。
海量数据决定了智能化的发展速度,市场规模决定了商业化的潜力。人工智能+安防成为各大公司追逐的“香饽饽”,则是必然的。本文将从市场格局、技术方案、AI芯片三个方面,由大到小分析AI安防芯片的行业面貌,及其发展现状与前景。
2 市场格局
根据相关调研报告,从产业构成来看,在安防行业总收入中,2016年中国安防工程产值约3100亿元,安防产品产值约1900亿元,报警运营服务及其他产值约410亿元。按照产品分类来看,视频监控市场占比最大,占所有安防产品的三分之二,市场规模已达1000亿元以上,其次为安检排爆、防盗报警、出入口控制和实体防护市场。从安防应用角度分析,2016年安防产品行业应用中,平安城市、智能交通和智能楼宇所占比例最高,分别达到24%、18%和16%,占据整个应用市场份额过半。此外,安防产品还应用在文教卫、金融和能源、司法等多个领域,应用范围十分广泛。
目前,我国各类安防企业达到2.34万家,从业人数达166万人。安防企业中,集成与工程类企业约1.19万家,占比51%,安防产品类企业近1万家,占比41%,运营和其他类企业近2000家,占比约8%。各类企业的所占比例近三年呈现出一定规律,其中安防设备类企业占比呈逐年下滑趋势,与此同时,安防工程类企业和运营服务类企业占比小幅增加。AI技术火爆之后,在近几年又冒出了众多基于人工智能的软硬件提供商,例如依图、商汤、旷视、云从、比特大陆等。
安防行业中企业集中度大幅提高,行业竞争加剧,资源向龙头企业集中趋势愈发明显。随着安防龙头企业快速崛起,大型企业与中小企业之间的差距逐渐拉大,再加上产业链延伸、横向跨界、行业深耕方面的优势,强者越强、赢者通吃的趋势已经显现。国内安防行业价格竞争日趋激烈,导致传统产品毛利率略有下滑,具有技术壁垒的安防龙头公司占据优势。行业长尾效应明显,洗牌加剧,龙头企业依托技术、资源和规模优势仍能保持高速增长,而位于长尾尾端的众多中小企业已逐渐处于盈亏平衡状态,生存艰难。
安防行业发展多年,企业在规模上明显形成了梯度,海康威视、大华、宇视等公司占据了绝大部分市场份额,并且都在积极拥抱AI技术。国内安防领域整体的集中程度也逐年攀升,形成了“两超多强”的格局,海康威视和大华股份领跑市场,东方网力、佳都、苏州科达、汉王等第二梯队企业奋起直追。当有了新技术的支持,尤其在AI应用正式落地安防之后,投资或收购AI技术公司成为传统安防企业最有效创新升级的方式。
3 技术方案
多年的发展,使得安防行业不仅形成了比较完整的市场格局和产业链。在市场格局方面,视频监控占据了近50% 的市场份额,这其中又分为前端(摄像头)和后端(主控/云端)两部分。
前端产品的核心功能是为后端提供高质量、初步结构化的图像数据,其主要作用有两点:提升部分智能分析应用的实时性;节省带宽和后端计算资源。
典型的前端智能摄像头内置深度学习算法,一方面可以在前端完成人脸定位检测和质量判断,有效解决漏抓误报问题,同时拥有较好的图像效果,即使周围环境光线不佳,人员戴帽子或一定角度下低头、侧脸,仍然可以做到准确检测,并自动截取视频中的人脸输出给后端;另一方面可以输出编码后的网络视频,还支持输出非压缩、无损无延时的视频流图像,这样可以为大型用户节省服务器成本和带宽,在同等服务器数量和计算能力的情况下能够接入更多路摄像头。
后端产品的核心功能是利用计算能力对视频数据进行结构化分析,一般包括智能 NVR、高密度 GPU服务器。前者是基于深度学习算法推出的智能存储和分析产品,兼顾传统 NVR 优势的同时增加了视频结构化分析功能;后者集成了基于深度学习的智能算法,每秒可实现数百张人脸图片的分析、建模,可支持数十万人脸黑名单布控,人脸 1V1 比对、以脸搜脸等多项实用功能,满足各行业的人脸智能分析需求。
从前后端智能化模块来看,目前的解决方案有两种思路,一种是智能前置,一种是后置智能,这一直是行业备受争议的两个方向。
由于前端设备内的空间有限,再加上功耗、成本等因素的限制,智能前置会受硬件计算资源限制,只能运行相对简单的、对实时性要求很高的算法,但算法升级、运维较难;后端智能分析通常可以根据需求配置足够强大的硬件资源,能够运行更复杂的、允许有一定延时的算法,另外,在后端算法升级、运维都会比较方便。
前后端产品不是对立与竞争的关系,根据实际应用的不同,将长期同时存在。
4 AI芯片的发展前景
无论是前端产品,还是后端产品,其底层能力都是芯片赋予的。对于智能前端产品目前有两种芯片解决方案。
一种是较为通用的视觉处理器(半定制芯片),如movidius 、英伟达的 Jetson 系列芯片,NVIDIA 的Jetson TX 芯片,主要针对终端市场。此外,海康、大华、宇视科技、苏州科达、格灵深瞳、商汤科技等大部分公司的前端智能产品在 2016 年正式推出。另一种是将较为通用的智能识别类算法直接固化为 IP ,嵌入到视频监控 SOC 芯片中(全定制芯片),优点是量产后功耗、价格等都极具优势,但功能拓展性有限。
在后端芯片方面,英伟达的GPU被采用最多,应用场景通用,但是昂贵,相比而言专用定制的、高性价比的ASIC 芯片的优势越来越明显。
行业内厂商之所以寄希望于 ASIC 芯片,主要原因还在于 GPU 芯片的弱点。不得不承认,在安防监控领域,GPU依然是最主流的深度学习方案,但GPU在成本、效率、功耗三方面存在明显缺陷:
(1)成本方面,嵌入式端GPU为数百美金,后端高性能GPU高达数千美金。在嵌入式端,市场上已量产的IPC Soc 芯片价格已经降到几美金,可以说是很好的替代品,但后端需要做大规模数据处理时,还是离不开GPU。高昂的芯片成本,推高了前后端设备的价格,阻碍了大范围应用。
(2)效率方面,GPU擅长深度学习算法训练,但却拙于推理。在推理阶段,一次只能处理一张输入图像,并行优势不能完全发挥。
(3)功耗方面,GPU在深度学习计算上,比CPU节省10倍能耗,但作为通用型芯片,在处理大量视频数据时功耗依然不容小觑,用电及散热成本也是一个大问题。
而经过专门设计优化的ASIC 芯片,则有着更高性价比、更容易大规模部署的优势。相比 GPU 的通用性,ASIC 芯片是一种为实现特定要求设计的集成电路,这意味着该芯片无法扩展,但除此之外,无论功耗、可靠性,还是体积、成本均远低于GPU。
鉴于 ASIC 芯片的诸多特质,业界普遍认为将会成为未来人工智能领域的核心,越来越多的算法企业也在基于ASIC 优化算法,而安防也成为主要的应用场景。
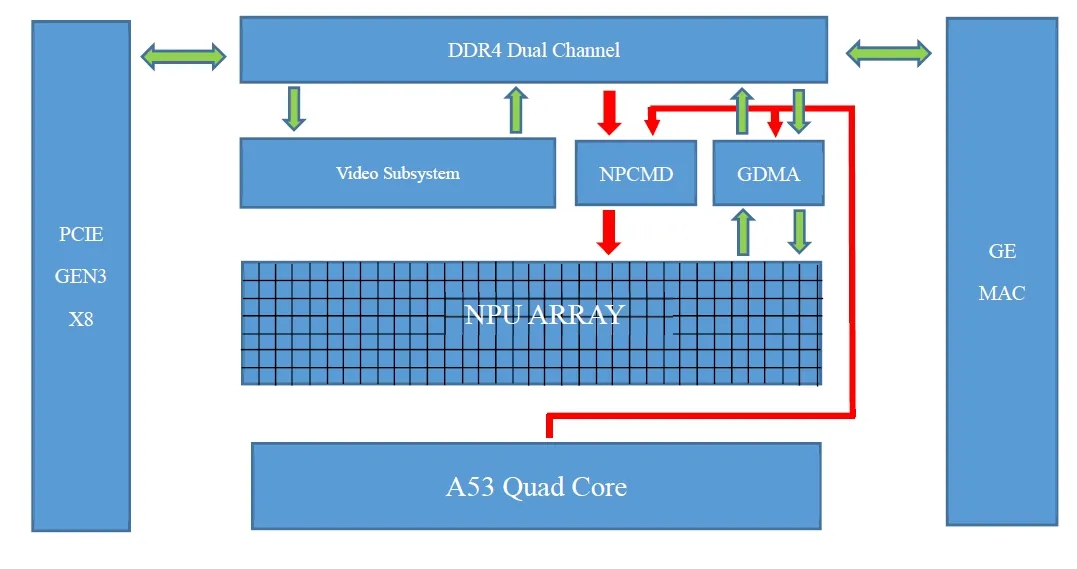
图1 ASIC芯片架构图
ASIC芯片架构如图1所示,典型ASIC芯片的基本业务流程如下:
应用程序运行于主机ARM上,通过NPU操作指令模块(NPCMD)和数据访问通道(GDMA)以及对DDR4内存单元的数据搬运操作,来对驱动NPU矩阵进行卷积运算。
来自文件或者网络的视频流通过FFMPEG传输到Video System进行解码,解码结果存放于DDR内存内。
DDR内存里的视频解码结果作为CV的输入进行图像处理,处理后的数据同样存放于DDR内。
经过CV处理后的数据经过编译器编译后的神经网络模型文件做上下文处理,处理结果放到DDR内存中,作为NPU的输入,系统加载后进行网络卷积等计算。
计算结果通过PCIE接口或者GE接口读取回应用程序进行结果展示或者上报。
所有数据都在DDR内存中处理和交换,并且DDR内存和NPU矩阵有专门的DMA通道,这样设计的好处是大幅提高数据处理效率。
例如BM 1680、BM1682、BM1684系列SoC芯片 ,就是一系列面向深度学习应用的 ASIC 芯片,其加速核采用改造型脉动阵列架构技术,具备多个并行执行单元,适用于CNN/RNN/DNN 等神经网络的预测和训练。第四代芯片BM1686将于2020年推出。
基于以上系列芯片,针对视频和图像分析,还可研发智能视频分析服务器、深度学习加速卡和人工智能迷你机等产品,预装Linux操作系统,预装包括固件、驱动、BMDNN计算库、Runtime库等软件环境,以及目标检测和目标识别的样例模型和测试程序,适用于人脸检测、人体检测、人脸识别、机非人检测分类等安防场景。
Sophon SA3系列AI加速计算服务器,采用低功耗的ARM CPU作为主控制芯片,在提供超强算力的同时,降低了整机的功耗,提供了更高能效比的服务器产品;主要面向数据中心及中小型局/所边缘节点,提供超强的视频结构化处理能力,满足中小站点的智能化改造诉求及数据中心的分布式部署要求。
5 BM1682芯片技术
BM1682芯片可脱离 X86 CPU 单独存在,其架构图如图2所示。支持客户二次开发,拥有单芯片八路H.264/H.265解码能力,支持视频图像后处理硬件加速,相比第一代拥有更低功耗、更高密度的特点,实际性能提升5倍以上。此外支持以太网,PCIE的多芯片互联,易于横向扩展,支持大规模数据中心。
BM1682高达3TFLOPs的FP32浮点运算能力,16MB片内SRAM,可以极大的减少模型运算时的数据搬运,提升性能;推理加速性能相当于同等算力GPU的160%。
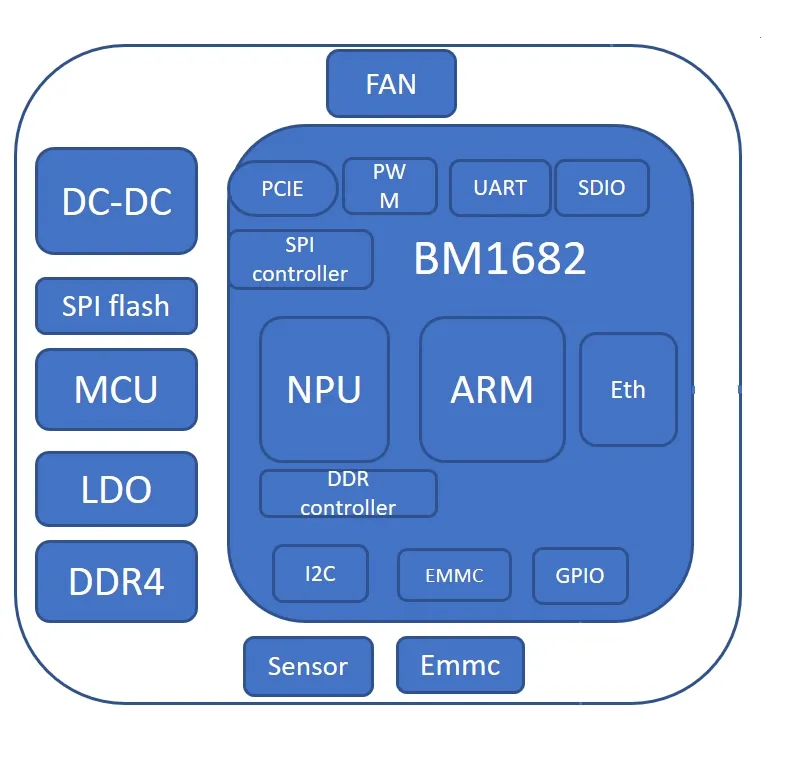
图2 BM1682架构图
完善易用的SDK支持:完善的神经网络编译器,支持多种网络;接口丰富,方便快速迁移,支持各类图像算法。
在高密度服务器中,BM1682运行在SoC模式,每颗芯片包含4核Cortex-A53处理器,运行独立的Linux操作系统,提供SDK控制NPU神经网络加速单元,H.264/H.265/Jpeg硬件解码单元和视频后处理硬件单元,芯片间通过网络连接形成集群。
每颗BM1682的NPU矩阵包含64颗NPU单元,每颗NPU包含32个EU单元,每个EU单元在每个时钟周期可做2次运算(1次乘和1次加),如果NPU的频率是750MHz,则此款芯片的额定算力=64*32*2*750=3072000M=3TFLOPS。
应用程序运行于主机CPU上,链接BMDNN(深度学习层layer级别的加速库接口)和BMCV(使用TPU和VPU进行CV处理的加速库接口)以及FFMPEG动态库,运行时通过PCIE驱动访问BM1682。
BMCVSDK(BITMAIN Computer Vision SDK)是基于自主研发的BM1682芯片所定制的视频加速工具包,涵盖了定制版本的FFMPEG和用户开发接口以及基于NPU的图像处理加速API,用于高效处理视频数据,提升基于神经网络视频应用的图像处理速度。
BMCVSDK由驱动、用户态SDK以及FFMPEG定制版开源软件组成,典型场景下的框架关系如图3所示。
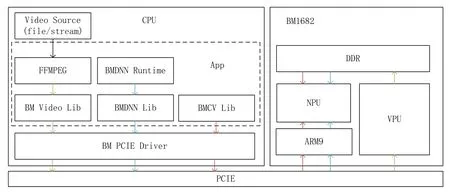
图3 BM1682业务流程图(PCIE模式)
来自文件或者网络的视频流通过FFMPEG传输到VPU(视频处理单元)进行解码,解码结果存放于PCIE板卡上的DDR内存内。
视频解码结果作为BMCV(使用TPU和VPU进行CV处理的加速库接口)的输入进行图像处理,结果存放于PCIE板卡的DDR内。
经过BMNETC(面向Caffe model的BMCompiler前端)或者BMNETT(面向TensorFlow model的BMCompiler前端)等编译器编译的神经网络文件上下文经过BMRUNTIME和BMLIB通过驱动加载到PCIE板卡的DDR内存中,并将BMCV处理过的数据作为NPU的输入,进行网络计算。
计算结果通过PCIE读取回应用程序进行结果展示或者上报。
从以上典型的应用场景可以看到,BMCV库和FFMPEG提供了对视频的流水线式处理,以源视频流的形式传输到BM1682 PCIE板卡上进行解码后,每帧图像数据将留存于PCIE板卡的内存中,在后续图像处理和神经网络计算中复用,达到零拷贝的效果,在计算机/服务器安装多块板卡的高密度计算场景中可以充分利用板卡的硬件资源,大大减少PCIE总线上的数据吞吐量。
6 结语
相信在未来,AI 势必将彻底改造安防这个传统的行业,赋予安防系统以人工智能,自动化的处理视频、图片等非结构化数据和结构化数据,提升信息搜索的精准程度,极大提高警务效率,让整个社会更安全、更有秩序,而这有赖于行业上下游的通力配合。
但需要注意的是,在这个耗资巨大、耗时很长的行业中,寻找具有创新性的、性价比高、可大规模部署的方案,是最务实也最接近成功的道路。在产业链方面,处在上游的芯片行业的产品和方案在很大程度上决定着安防系统的整体功能、技术、成本等核心指标,同时也是影响安防行业未来的关键因素。
