基于大数据的未到达货票清算预测平台研究
2019-10-23谢大锋霍鹏敏
谢大锋,安 腾,霍鹏敏
(北京经纬信息技术有限公司, 北京 100081)
随着铁路大提速的实施以及货运组织和服务水平的提升,运输企业对货运分析内容的多样性、实时性和准确性提出了更高的要求。为了满足分析需求,2018年铁路货物运输承运制清算正式实施。铁路货物运输建立了收入来自市场、服务定价补偿、公正透明的清算体系,明晰运输企业之间的经济利益关系[1-2]。
铁路货运承运制清算中工作量数据与收入数据采用制票日期与货票号码进行匹配,匹配成功货票直接进行清算,未匹配成功货票则认定为未到达货票,即收入部门已核算收入,但货物仍在运输途中的货票。现行的货运清算系统只能实现对已到达货票的清算,而未到达货票由于缺失实际径路和工作量信息,无法实现对其的清算。由于铁路货物承运制清算刚刚起步,针对未到达货票的承运制清算预测研究尚少。为促进大数据在我国铁路行业的落地生效,充分展现货运数据价值[3-4],对未到达货票的分析和预测已成为整个货运承运清算工作必不可少的一环。
本文旨在构建基于大数据的未到达货票清算预测平台,通过对货票历史数据的分析建模,结合专家经验和人工处理,对未到达货票进行承运制清算预测,使得运输企业可较为精确掌握本月本企业营收情况,为后续业务开展和经营决策及时提供数据基础和决策支持[5-6]。
1 预测算法模型研究
1.1 k近邻算法模型
k近邻(k-NN ,k-Nearest Neighbor)算法是1967年由Cover T和Hart P提出的一种基本分类与回归方法,工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后提取样本最相似数据(最近邻)的分类标签。一般只选择样本数据集中前k个最相似的数据作为分类参考,这就是k-NN算法中k的出处,通常k是不大于20的整数。
新数据分类过程如图1所示,其中绿色圆圈为未知类的新数据,若设定k=3,由于红色三角形所占比例为2/3,则新数据被赋予红色三角形类;若k=5,由于蓝色四方形所占比率为3/5,则新数据被赋予蓝色四方形类。

图1 k-NN算法分类示意图
(2)设计1个数据结构,使算法能够以线性的时间查找1个点的最邻近点集。在1个样本个数为n的有序序列中二分查找1个元素,理论上只需要进行log n次查找,故此二分查找的时间复杂度为O(logn)。因此若将已到达货票历史数据样本点构建成1颗二叉树,则查询时间可控制在O(log n)。
如图2所示,在数据空间中随机选择2个样本点,以这2个节点为初始中心节点,执行聚类数为2的k均值聚类算法,最终产生收敛后的2个聚类中心点。这2个聚类中心点之间连1条线段(灰色短线),建立1条垂直于这条灰线,并且通过灰线中心点的线(黑色粗线)。这条黑色粗线把数据空间分成2部分,在多维空间中这条黑色粗线就是超平面。
在进行货运承运制清算未到达货票预测时,采用已到达货票的历史数据作为训练样本集。将未到达货票中的收入信息与货票信息相结合,并选择制票站、发车站、到达站、运输类别、货物品类、货物重量等信息作为标签,进行新数据和样本集中数据对应特征的匹配。本文选取10作为k-NN算法中的k值,将10个最相似数据中出现次数最多的分类,作为新数据的分类[7]
1.2 构建模型
k-NN算法模型构建的目的是要在一个空间内找到一个已知点的最近邻集合。算法模型构建的过程如下。
(1)构建一个具有大量数据样本的多维空间,本文中已到达货票历史数据就是多维空间的构建基础。

图2 数据空间划分示意图
(3)按照步骤(2)在每个子集上进行迭代划分,直到每个节点最多剩下k个样本点,形成完整二叉树结构,如图3所示。

图3 k-NN算法的完整二叉树示意图
(4)遍历二叉树,查找邻近点。
二叉树的每个中间节点(图3中方形节点)用超平面来定义,因此能够计算出该节点的遍历方向。搜索一个节点能够在logn时间内完成,正好是二叉树的高度,节点查找过程如图4所示。

图4 k-NN算法节点查找示意图
2 未到达货票清算预测平台搭建与应用
Hadoop目前已成为公认的大数据处理领域的标准,可满足大数据的各种技术需求[8]。本文通过建立基于大数据的未到达货票清算预测平台,达到分析、预测未到达货票数据的目的。
2.1 大数据平台架构
大数据平台的技术架构分为3层:数据层、模型层和展示层,如图5所示。
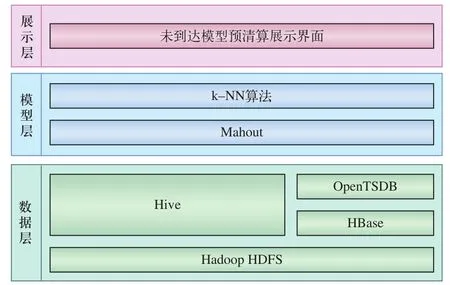
图5 平台技术架构图
其中,数据层主要建立用户行为分析数据模型,需要用到铁路货票系统和铁路货物运输承运制清算系统2部分数据,具体内容如下:
(1)历史数据:历史到达货票数据包括货票票根、机车牵引、线路使用、车辆服务、接触网使用及电费、长交路轮乘和特殊运价;
(2)未到达货票数据:未到达货票的票根数据等;
(3)未到达货票收入数据:未到达货票的收入信息。
通过Hive工具保存关系型数据库转换的数据,通过Open TSDB工具保存准实时数据,为模型层分布式计算提供数据条件。
2.2 预测模型
未到达货票清算预测模型的流程如图6所示。
(1)通过对铁路货票历史数据进行一系列预处理,归纳出不同运输企业的同类货票的特征和规律,提取历史货票相关的特征变量。通过分析匹配未到达货票与历史货票特征的区别,提取未到达货票的特征属性,利用Hadoop分布式特点存储数据。
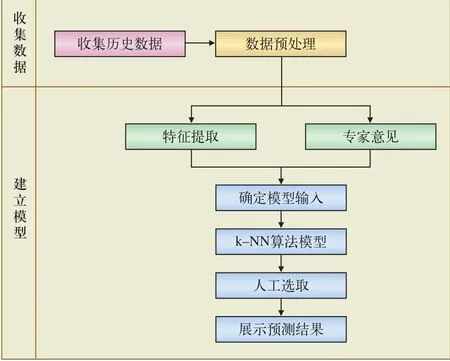
图6 预测模型流程图
(2)整合业务专家的输入特征建议,利用k-NN算法建立未到达货票预测及分析模型,计算出每张未到达货票的最相似历史货票集合,并根据系数(相似程度)进行排序。
(3)业务人员可以根据系数(相似程度),将适合纳入预测的货票批量纳入清算预测范围,形成完整货票信息并进行清算预测。
2.3 应用效果
应用该平台对2018年5月产生的18万张未到达货票进行清算预测,涉及100余家运输企业。通过与2018年6月实际数据进行对比,各项预测应付金额与实际应付金额误差率在10%以内,具体数值如表1所示。通过预测使运输企业能及时掌握本企业每月实时整体经营情况,便于其及时调整经营策略。

表1 预测应付金额与实际金额对比列表
3 结束语
未到达货票清算预测问题,对各运输企业预判经营效益影响巨大,关系到各运输企业的后续业务开展和经营决策。伴随货运承运制清算的深入推进,未到达货票清算预测平台作为铁路货物运输承运制清算系统的重要组成部分,会逐步积累大量的货运承运制生产数据,为预测运输企业的运输行为提供更精准的数据模型,更好的让中国国家铁路集团有限公司资金清算中心及时掌握全路货运情况、发挥宏观调控作用,为防范与化解货运金融风险提供决策依据。
