短文本语义相似度计算研究
2019-10-23张敏
张敏
(西安翻译学院 工程技术学院, 西安 710105)
0 引言
文本相似度计算方法在文本分类、信息检索、提取摘要、机器翻译自动评估方法、文本摘要等大型文档或同义词测试等自然语言处理和相关领域的应用中已有很长的历史,文本相似度的度量方法也被发现对文本一致性的评价有帮助[1]。在网络信息呈爆炸性增长的互联网时代,如何高效利用网络信息,对自然语言处理领域的研究有着更高的要求。
在文本相似度计算方面,AGI RREE[2]等人通过计算在WordNet中词节点之间上下位关系构成的最短路径来计算词语之间的相似度。许多学者也考虑到其他因素对语义距离的影响,如SU J等人[3]根据两个词的公共祖先节点的最大信息量来衡量两个词的语义相似度; Dekang Lin[4]等人在计算词语的语义相似度时,除了节点间的路径长度外,还考虑到概念层次树的深度和区域密度的影响。王斌[5]利用《同义词词林》作为语义词典计算汉语词汇的相似度;在语义相似度计算领域中,刘群[6]等对“知网”的知识描述语言进行了研究。该方法采用了“整体的相似度等于部分相似度加权平均”的做法,充分利用了“知网”中对每个概念进行描述时的丰富的语义信息,得到的结果与人的直觉比较符合。但该方法对于相关性词语(如法院和警察)的相似度计算方面与人的直觉比较不符合,影响在文本分类,文本聚类,文档自动文摘等领域的应用。此外江敏[7]等人又在刘群的基础上,加入义原间的反义、对义关系来计算词语的相似度。吴健[8]等人提出了一种基于本体论的词汇相似度计算方法。
本文提出了一种利用成分词的相似性信息来度量文本语义相似性的度量方法。我们描述了单词语义相似度度量,并展示了如何使用它们来推导一个文本到文本的相似度度量。通过对释义识别任务的评估,我们证明了这种文本语义相似度的度量方法优于现有的相似度方法。
1 短文本语义相似度
给定两个输入文本段,我们希望自动得出一个分数,表明它们在语义级别上的相似性,从而超越了传统上用于此任务的简单词汇匹配方法。虽然我们承认一个综合的文本语义相似度指标也应该考虑到文本的结构,但我们首先分析了这个问题,并试图将文本的语义相似度作为组成词的语义相似度的函数来建模。我们通过将词与词之间的相似性和词的特异性指标结合到一个公式中来实现这一点。给定输入的两个文本段T1和T2,用公式(1)计算两个文本段之间的相似性,如式(1)。
(1)
给定一个词与词之间的相似性度量和一个词的特异性度量,我们使用一个度量来定义两个文本段T1和T2的语义相似性,该度量依次结合了每个文本段相对于另一个文本段的语义相似性。首先,对于T1段中的每个单词w,我们尝试根据下一节描述的单词间相似性度量方法之一,识别T2段中语义相似度最高的单词(max(sim(w,T2)))。接下来,同样的过程被应用于确定T1中最相似的单词,从T2中的单词开始,然后,用对应的词的特异性对词的相似性进行加权,求和,并根据每个文本段的长度进行标准化,最后,使用平均值将得到的相似度评分组合在一起。注意,只有开放类单词和基数可以参与这个语义匹配过程。正如前面使用基于向量的模型对文本相似性所做的工作一样,所有虚词都被丢弃。
这样我们可以给两个特定词汇之间的语义匹配识别以更高的权重(例如,警察和特警),并给通用概念之间的相似性测量以较低的权重(例如,成为)。虽然单词的特异性已经在一定程度上由它们在语义层次中的深度来衡量,但是我们使用基于语料库的单词特异性度量来加强这一因素,该度量基于从大型语料库中学习到的分布信息。
这个相似度得分在0和1之间,1表示相同的文本段,0表示两个段之间没有语义重叠。除了相似的单词,我们也考虑到词语特异性, 单词的特异性是由Sparck-Jones[9]引入的逆文档频率(idf)确定的,它的定义是语料库中的文档总数除以包含该单词的文档总数,然后将得到的商取对数,计算公式如式(2)。
(2)
|D|:语料库中的文件总数,|{j:wi∈dj}|:包含词语wi的文件数目(即ni,j≠0的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用1+|{j:wi∈dj}|
2 实验
通过实例说明文本相似性度量的应用。给定两个文本段,如下所示,我们想要确定一个反映它们语义相似性的评分。为了便于说明,我们将注意力限制在一个基于语体的度量上,我们还通过在数据集[10]上找到它们的覆盖范围,来获得语义相似度度量的适用性。
文本段1:When secretary and other employees entered the office for investment intention, some functionary and investors ignored them.
文本段2: When secretary and clerks walked into the office together with investment project, civil servants and holders showed contempt for them.
从两个文本段中的每一个开始,对于每个开放类单词,确定另一个文本段中最相似的单词。如前所述,语义相似性只在词性相同的词之间存在。从第一个文本段开始的单词相似性评分和单词特异性(idf),如表1所示。
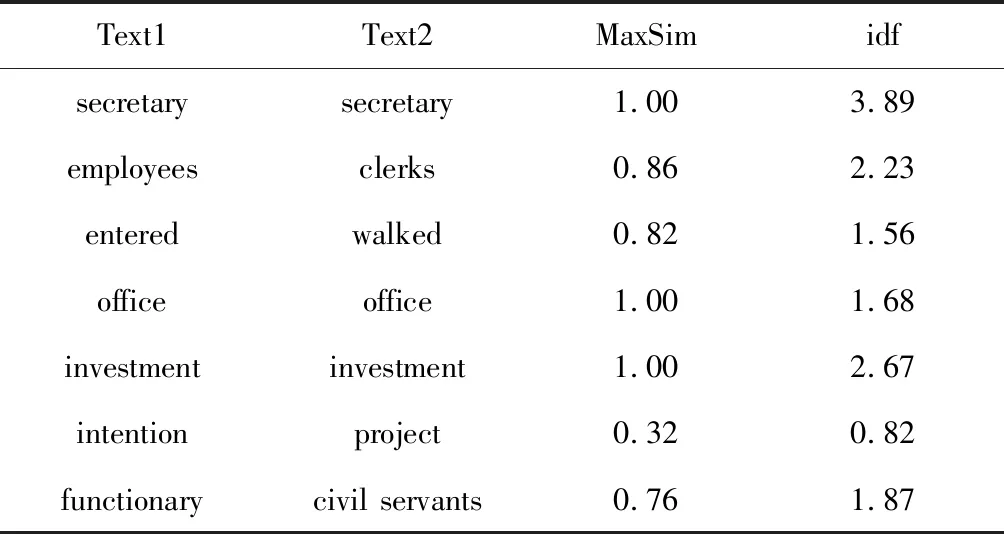
表1 短文本中词语相似度值和单词特异性idf值
利用式(1),将单词相似性及其对应的特异性结合起来,确定两篇文章的语义相似性为0.79。这个相似度评分正确地识别了两个文本段之间的释义关系。尽管有一些词同时出现在两个句子中(如secretary,investment),但也有一些词是不相同的,但却紧密相关的(如: functionary,civil servants)。与传统的基于词汇匹配的相似度度量方法不同,我们的度量方法考虑了这些单词的语义相似度,从而实现了更精确的文本相似度度量。
3 总结
实验证明,将语义信息纳入文本相似度的测量中,大大增加了对随机基线和基于向量余弦相似度基线的识别的可能性,余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小,更加注重两个向量在方向上的差异,而不是位置,适合于网络短文本相似度计算。基于向量的余弦相似基线,使用一种将几个相似度指标结合在一起的方法来达到最佳的性能,在数据集上进行的实验表明,语义相似度方法优于基于简单词汇匹配的方法,其整体精确度提高,误差率显著降低。
