面向高并发实时交易数据的分布式快速汇总统计
2019-10-21王颖卓郭开卫王亚雄
王颖卓 郭开卫 王亚雄
摘 要:本案涉及计算机数据统计领域的一种数据统计方法和装置,具体来说,首先根据预先设定的过滤规则,对原始交易数据进行过滤处理,得到第一交易数据;然后根据第一交易数据中的关键字信息,确定第一交易数据所对应的计算服务器;最后将第一交易数据发送至计算服务器,以使计算服务器将根据预先设定的统计维度对第一交易数据进行统计得到的第二交易数据发送给查询服务器使用,关键字相同的第一交易数据将会发送至同一计算服务器,而计算服务器可将第二交易数据给查询服务器使用。因此,可通过增加计算服务器的数量的方式水平扩展计算统计的能力,从而提高将数据写入数据库的速度,进而提升数据的查询效率。
关键词:交易数据;实时查询;计算服务器
中图分类号:TP333 文献标识码:A 文章编号:2096-4706(2019)12-0023-03
Abstract:This case relates to a data statistics method and device in the field of computer data statistics,including:firstly filtering the original transaction data according to a preset filtering rule to obtain the first transaction data,and then according to the first transaction data Key information,determining a computing server corresponding to the first transaction data,and finally sending the first transaction data to the computing server,so that the computing server will perform the second transaction obtained by counting the first transaction data according to a preset statistical dimension. The data is sent to the query server for use. The first transaction data with the same keyword will be sent to the same computing server,and the computing server can use the second transaction data for the query server. Therefore,the ability to calculate statistics can be horizontally expanded by increasing the number of computing servers,thereby increasing the speed at which data is written into the database,thereby improving data query efficiency.
Keywords:transaction data;real-time query;computing server
0 引 言
目前行業内普遍采用的实时统计方法是接收实时交易数据,以事务方式计算后写入数据库供用户查询,这种方法的时效性较低,而且支持大并发量的成本要求非常高。
1 技术背景
数据统计在各行各业中都有应用,尤其是在银行业务中使用较为频繁。目前,普遍采用的数据统计方法是在接收交易数据并针对接收到的交易数据进行计算后,再以事务的方式将计算后的交易数据写入数据库,以供用户查询。然而,通过事务的方式将交易数据写入数据库的时效性较低,并且由于通过事务的方式将交易数据写入数据库的速度取决于服务器的CPU(Central Processing Unit,中央处理器)、内存以及数据库的写入性能,难以水平扩展,从而无法提高将交易数据写入数据库的速度,降低了数据的查询效率。
2 实现方式
2.1 数据统计流程
数据统计通过以下3步完成:(1)根据预先设定的过滤规则,对原始交易数据进行过滤处理,得到第一交易数据,其中,所述过滤规则包括所述原始交易数据中的至少一个字段信息。(2)根据第一交易数据中的关键字信息,确定第一交易数据所对应的计算服务器。(3)将第一交易数据发送至所述计算服务器,以使所述计算服务器能够将根据预先设定的统计维度对第一交易数据进行统计得到的第二交易数据发送给查询服务器使用。
过滤规则是由各计算服务器的统计维度确定的。
上述步骤(2)中,可预先将所有的计算服务器的标识信息放置在一致性哈希算法的闭合环中,根据第一交易数据中的关键字信息,确定数据所对应的计算服务器,可通过将第一交易数据中的关键字信息作为一致性哈希算法的输入参数进行运算后,得到对应的计算服务器的标识信息,然后确定第一交易数据所对应的计算服务器。
因此,具有相同关键字的交易数据将会被路由到标识信息相同的计算服务器中,即具有相同关键字的交易数据将会被路由到同一计算服务器中。
上述步骤(3)中,可通过RPC(Remote Procedure Call Protocol,远程过程调用协议)的方式将第一交易数据发送至计算服务器。
需要说明的是,如果第一交易数据中包含多个关键字,则第一交易数据可根据关键字的不同被路由到多个计算服务器。为了减少网络传输次数,可在计算服务器中设置计时器,用于统计一段时间内接收的交易数据。例如,当计算服务器中的计时器设置的计时时间为1分钟时,表示计算服务器在接收的交易数据持续的时间为1分钟,然后计算服务器根据自身的统计维度对1分钟之内接收的交易数据进行统计处理。
在计算服务器中设置计时器后,为了提升系统处理能力,还可在计算服务器中设置缓冲队列。
2.2 计算服务处理
当在计算服务器中设置了计时器和缓冲队列后,计算服务器的处理流程如下:(1)接收有效的第一交易数据。(2)判断计时器是否已归零,若是,则转至步骤(3);否则,转至步骤(6)。(3)读取自身的统计规则。(4)根据读取的自身的统计规则,对缓冲队列中的第一交易数据进行统计处理,得到第二交易数据。(5)将第二交易数据发送给查询服务器使用。(6)将接收的有效的第一交易数据存储至缓冲队列中。
此外,为了减少网络传输次数,还可通过在计算服务器中设置阈值的方式控制第一交易数据的数量。例如,当计算服务器中的阈值设置为50时,表示计算服务器在接收到50条第一交易数据后,可根据自身的统计维度对上述接收到的50条交易数据进行统计处理。
当计算服务器中设置了阈值和缓冲队列后,计算服务器的处理流程如下:(1)接收有效的第一交易数据。(2)判断接收的有效的第一交易数据的条数是否达到阈值,若是,则转至步骤(3);否则,转至步骤(6)。(3)读取自身的统计规则。(4)根据读取的自身的统计规则,对缓冲队列中的第一交易数据进行统计处理,得到第二交易数据。(5)将第二交易数据发送给查询服务器使用。(6)将接收的有效的第一交易数据存储至缓冲队列中。
需要说明的是,无论是通过在计算服务器中设置计时器的方式,还是通过在计算服务器中设置阈值的方式,當计算服务器空闲时,均可以清空自身的缓存,从而确保计算服务器的处理实时性。
2.3 计算服务检测
为了确保计算服务器的处理实时性,还可通过心跳机制对计算服务器进行检测,在检测到计算服务器发生故障时,将发生故障的计算服务器的标识信息从一致性哈希算法的闭合环中删除。通过心跳机制,对计算服务器进行检测的具体流程如下:(1)定期接收计算服务器的存活消息。(2)判断在预设的时间段内,是否接收到计算服务器发送的存活消息,若是,则转至步骤(3);否则,转至步骤(4)。(3)判定所述计算服务器处于正常状态。(4)判定所述计算服务器发生故障。(5)将发生故障的计算服务器的标识信息从一致性哈希算法的闭合环中删除。
本发明实施例中的查询服务器还可通过Redis集群的方式,从而提供高效的读写服务,即查询服务器可通过Redis集群的方式对计算服务器提供高效的写服务,同时,查询服务器还可通过Redis集群的方式提供高效的查询服务。查询服务器在收集所有计算服务器发送的第二交易数据后,可将第二交易数据写入Redis集群中,因此,在使用查询服务器查询交易数据时,可从查询服务器管理的Redis集群中查询出统计结果数据。为了避免在查询服务器发生故障时,影响到数据的查询,还可设置一个备用的查询服务器。当设置备用的查询服务器以后,计算服务器除了将第二交易数据发送给主查询服务器外,还需要将第二交易数据同时发送给备用服务器。
本案例中的过滤规则以及计算服务器中的统计维度,可基于用户的需求进行更改。当存在多个过滤规则以及对应的计算服务器中的统计维度时,还可采用订阅的方式供用户选择合适的过滤规则和统计维度,从而统计出用户需要的统计结果数据。
下面通过一个具体的例子,对上述方法流程进行详细的解释说明。在该例子中,假设存在两个计算服务器,分别为计算服务器1和计算服务器2,并假设计算服务器1的标识信息为“1”,计算服务器2的标识信息为“2”,并且预先将计算服务器1的标识信息“1”和计算服务器2的标识信息“2”设置在一致性哈希算法的闭合环中,进一步假设计算服务器1和计算服务器2对接收的交易数据统计的时间窗为3分钟。
继续假设,计算服务器1的统计维度X包括字段“商户”“金额”“日期”,计算服务器2的统计维度Y包括“卡号”“商户”“金额”,则根据计算服务器1的统计维度X和计算服务器2的统计维度Y,可确定过滤规则Z包括的字段有“商户”“金额”“日期”“卡号”,并假设存在两个关键字,分别为“东方航空”和“123”。
继续假设用户A使用卡号123的信用卡于2019年6月1日10:50分在东方航空上购买了一张机票,则原始交易信息为“用户:A,卡号:123,商户:东方航空,金额:500元,购买渠道:东方航空APP,日期:2019年6月1日”。
过滤规则Z包括“商户”“金额”“日期”“卡号”,交易数据在使用过滤规则Z后,得到的交易数据为“卡号:123,商户:东方航空,金额:500元,日期:2019年6月1日”。
由于字段“东方航空”为关键字,因此可将关键字商户字段“东方航空”作为输入参数采用一致性哈希算法进行运算,并假设将关键字商户字段“东方航空”作为输入参数采用一致性哈希算法进行运算后,得到的计算服务器标识信息为“1”,即用户A的交易数据对应的计算服务器为计算服务器1,因此,可将用户A的交易数据路由到计算服务器1中。
基于用户A的交易数据,由于字段“123”为关键字,因此可将关键字卡号字段“123”作为输入参数采用一致性哈希算法进行运算,并假设将关键字卡号字段“123”作为输入参数采用一致性哈希算法进行运算后,得到的计算服务器标识信息为“2”,即用户A的交易数据对应的计算服务器为计算服务器2,因此,也可将用户A的交易数据路由到计算服务器2中。
继续假设用户A使用卡号123的信用卡于2019年6月1日10:51分在星巴克购买了一杯咖啡,则原始交易信息为“用户:A,卡号:123,商户:星巴克,金额:25元,购买渠道:POS机刷卡,日期:2019年6月1日”。
过滤规则Z包括“商户”“金额”“日期”“卡号”,交易数据在使用过滤规则Z后,得到的交易数据为“卡号:123,商户:星巴克,金额:25元,日期:2019年6月1日”。
基于用户A的交易数据,由于字段“123”为关键字,因此将关键字卡号字段“123”作为输入参数采用一致性哈希算法进行运算后,得到的计算服务器标识信息为“2”,即用户A的交易数据对应的计算服务器为计算服务器2,因此,也可将用户A的交易数据路由到计算服务器2中。
继续假设用户B使用卡号456的信用卡于2019年6月1日10:52分在东方航空上购买了一张机票,则原始交易信息为“用户:B,卡号:456,商户:东方航空,金额:1000元,购买渠道:东方航空APP,日期:2019年6月1日”。
过滤规则Z包括“商户”“金额”“日期”“卡号”,交易数据在使用过滤规则Z后,得到的交易数据为“卡号:456,商户:东方航空,金额:1000元,日期:2019年6月1日”。
基于用户B的交易数据,由于字段“东方航空”为关键字,因此将关键字商户字段“东方航空”作为输入参数采用一致性哈希算法进行运算后,得到的计算服务器标识信息为“1”,因此,也可将用户B的交易数据路由到计算服务器1中。
至此,路由至计算服务器1根据统计维度X对交易数据做统计处理后的交易数据,可参见表1所示。
在具体实施时,计算服务器1可将基于统计维度X对表格二和表格六中的交易数据做统计处理后的交易数据发送给汇总服务器,由汇总服务器将接收到的交易数据分发给下面的Redis集群,查询服务器通过访问汇总服务器下面的Redis集群查询到东方航空公司的销售额信息以及销售日期。
作为一种实施方式,在通过查询服务器查询到东方航空公司的销售额信息以及销售日期后,可基于查询到统计数据,统计出机票的淡季和旺季。
路由至计算服务器2中的交易数据根据统计维度Y对交易数据做统计处理后的交易数据,可参见表2所示。
在具体实施时,计算服务器2可将基于统计维度Y对交易数据做统计处理后的交易数据发送给汇总服务器,由汇总服务器将接收到的交易数据分发给下面的Redis集群,查询服务器通过访问汇总服务器下面的Redis集群查询到卡号123的消费信息,该消费信息中包括卡号123经常光顾的商家信息以及卡号123的消费能力。
根据以上内容可以看出,由于在得到第一交易数据后,可借助关键字确定第一交易数据所对应的计算服务器,因此关键字相同的第一交易数据将会发送至同一计算服务器,而计算服务器可根据预先设定的统计维度在对第一交易数据进行统计处理后得到第二交易数据,并将第二交易数据发送给查询服务器使用,因此,可通过增加计算服务器的数量的方式,水平扩展计算统计的能力,从而提高将数据写入数据库的速度,进而提升数据的查询效率。
2.4 数据统计
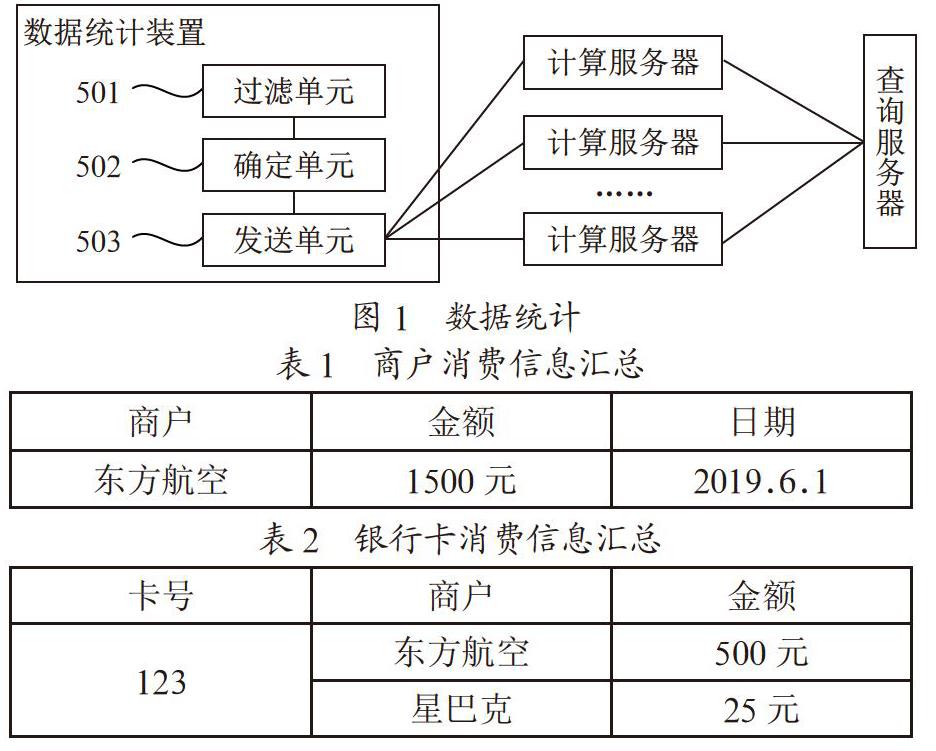
基于相同的技术构思,本案例提供一种数据统计装置,如图1所示。
该装置可包括:过滤单元501,用于根据预先设定的过滤规则,对原始交易数据进行过滤处理,得到第一交易数据,所述过滤规则包括所述原始交易数据的至少一个字段信息;确定单元502,用于根据所述第一交易数据中的关键字信息,确定所述第一交易数据所对应的计算服务器;发送单元503,用于将所述第一交易数据发送至所述计算服务器,以使所述计算服务器将根据预先设定的统计维度对所述第一交易数据进行统计得到的第二交易数据发送给查询服务器使用。所述过滤规则是由各计算服务器的统计维度确定的。
确定单元502,具体用于:将所述第一交易数据中的关键字信息作为一致性哈希算法的输入参数进行运算后,得到所述第一交易数据所对应的计算服务器的标识信息;根据得到的所述标识信息确定所述第一交易数据所对应的计算服务器;其中,所述一致性哈希算法的闭合环中包括至少一个计算服服务器的标识信息。
用于通过心跳机制对所述计算服务器进行检测,在检测到计算服务器发生故障时,将发生故障的计算服务器的标识信息从所述一致性哈希算法的闭合环中删除。此外,还定期接收所述计算服务器的存活消息;若在预设的时间段内,未接收到所述计算服务器的存活消息,则判定所述计算服务器发生故障。
从以上内容可以看出,由于在得到第一交易数据后,可借助关键字确定第一交易数据所对应的计算服务器,因此关键字相同的第一交易数据将会发送至同一计算服务器,而计算服务器可根据预先设定的统计维度将对第一交易数据进行统计处理后得到第二交易数据,并将第二交易数据发送给查询服务器使用,因此,可通过增加计算服务器的数量的方式水平扩展计算统计的能力,从而提高将数据写入数据库的速度,进而提升数据的查询效率。
3 结 论
本案例提供了一些思路和方法,或者为研究计算机程序产品提供灵感。因此,本案例可采用完全硬件实施例、完全软件实施例,或者结合软件和硬件方面的实施例的形式。而且,可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
参考文献:
[1] 陆承涛.存储系统性能管理问题的研究 [D].武汉:华中科技大学,2010.
[2] 罗东健.大规模存储系统高可靠性关键技术研究 [D].武汉:华中科技大学,2011.
作者簡介:王颖卓(1978.05-),男,汉族,江西赣州人,架构师,硕士,研究方向:大数据开发。
