基于Hadoop的电力用户地址数据结构化及存储技术研究
2019-10-21谢辉陈超许卓
谢辉 陈超 许卓


摘 要:随着我国电力客户服务系统业务的快速增长,用户地址数据量不断提升。由于传统的电力用户地址的输入比较随意,导致地址数据多源、格式不一致等问题的出现。因此我们需要对数据进行结构化改造。随着我国电网信息化、智能化进程的不断推进,电力企业如何实现电力用户地址的结构化与统一化成为了当前首要解决的问题。本文着重从电力用户地址优化的方向出发,对传统的电力用户地址如何进行结构化的改造进行了分析,并提出了大数据存储的方法。
关键词:电力用户;地址优化;数据结构化;存储技术
中图分类号:TP311.13;TP274.2 文献标识码:A 文章编号:2096-4706(2019)20-0115-04
Abstract:With the rapid growth of Chinas power customer service system business,the amount of user address data continues to increase. Since the input of the traditional power user address is relatively random. This has led to problems such as multiple sources of address data and different formats. So we need to make structured changes. With the continuous advancement of informationization and intelligentization of Chinas power grid,how to realize the structure and unification of power user addresses has become the primary problem to be solved. This paper focuses on the direction of power user address optimization,analyzes how traditional power user addresses are structured,and proposes a method of big data storage.
Keywords:power users;address optimization;data structuring;storage technology
0 引 言
用户地址信息是描述电力用户具体地理位置的一项基础信息,是南方电网很多业务系统所必需的一项很重要的基础属性。电力系统由于其特殊性,信息化的发展是循序渐进的,现存很多传统的用户地址数据的表现形式都是很单一的、非结构化的文本信息。這种传统地址数据存储方式,在基层主要通过人工识别的一般应用场景中尚能应付。但是,随着电网信息化智能化的推进,电力用户地址的结构化与统一化将是必然趋势。
南方电网覆盖五个省区,并与香港、澳门地区以及东南亚国家的电网相联,供电面积100万平方公里。截至2017年底,供电人口2.52亿,供电客户8497万户,而每个客户都对应着一个地址信息。如何存储并管理这一庞大的电力用户基础信息,为各类电力业务系统提供基础服务,则成为一个重要的问题。随着南方电网智能电网信息化的快速发展,尤其是配电管理系统和客户服务系统业务的快速增长,导致用户地址数据量迅速攀升。由于以往不同部门不同系统可能在数据存储结构与方式上存在不同,极易形成所谓的“信息孤岛”,导致出现数据多源、格式不一致等各种数据问题。用户地址的统一、完整与规范,是南方电网智能化尤其是客户服务系统智能化的基础条件。
本文以南方电网建设智能电网的发展方向作为契机,从电力用户地址优化的角度,研究了传统的电力用户地址如何进行结构化的改造和大数据存储的方法。
1 地址的结构化
传统的电力用户地址的输入非常具有随意性。比如,可能没有市区信息而只有街道及以下的信息;或者区县的信息是错误的。这些电力用户地址都是不规范和不统一的,是需要进行结构化改造的数据。根据《数字城市地理信息公共平台地名/地址编码规则》的定义,数字城市地理信息公共平台是指依托基础地理信息标准数据,通过在线地理信息服务满足城市政府部门、企事业单位和社会公众的基本需求,具备实现个性化应用的二次开发接口和可扩展空间。它是各种专业信息空间定位、集成交换和互联互通的基础。我们可以借鉴该标准来对南方电网电力用户地址进行结构化改造。
1.1 地址的结构化的方向
南方电网电力用户地址的结构化改造要求新的地址数据格式必须要有规范的层次,符合中国常用地名的描述要求。通常,一个规范的地址应该包括以下三个层次:行政区域地名、街巷名或小区名和门(楼)址或标志物名。
行政区域地名描述包括四种类型。省级行政区域地名(省、自治区、直辖市、特别行政区),比如:广东省;市级行政区域地名(市、地区、自治州、盟),比如广东省深圳市;县级行政区域地名(县、自治县、县级市、旗、自治旗、市辖区、林区、特区),比如:广东省深圳市龙岗区;乡级行政区域地名(乡、民族乡、苏木、镇、街道、政企合一单位),比如:广东省深圳市龙岗区坪地街道。
街巷名或小区名包含两种类型。行政区域地名|街巷名,比如:广东省深圳市龙岗区坪地街道同心中路;行政区域地名|小区名,比如:广东省深圳市龙岗区坪地街道中航鼎尚华庭。
门(楼)址或标志物名描述包括几种类型。行政区域地名|街巷名|门(楼)址,比如:广东省深圳市龙岗区坪地街道同心中路3号;行政区域地名|街巷名|标志物名,比如:广东省深圳市龙岗区坪地街道同心中路西湖塘商住楼;行政区域地名|小区名|门(楼)址,比如:广东省深圳市龙岗区坪地街道中航鼎尚华庭3号楼。
1.2 地址结构化的方法
对于地址结构化的具体方法则一般主要有两种。一种是基于规则的,也就是利用此表匹配对电力用户地址进行分词,然后根据地址的结构利用类似状态机的方法识别地址的各个层次上的关键要素。这种方法的好处是它是利用此表和地址的构词规则进行地址匹配,这样在实际的应用中准确率会比较高,但是缺点则是比较依赖于词表建设的规模。另一种则是基于统计的方法,这种方法则是将地址解析看作是命名实体识别的过程。这种方法的优点在于它可以从训练数据中自动学习地址和地址要素的构成特征,但缺点是构建训练数据工作量大,模型对数据依赖性较强。
刘婷婷等综合上面两种方法的优缺点,提出了基于地址知识库的中文地址解析和规范化的方法,这种方法的特点是从人类理解地址的角度出发,借助互联网生成一个涵盖地名、别名、地址空间关系以及地址構词特征的知识库,在此基础上对地址进行解析、更新等操作。经过多方研究对比,建议采用这种基于地址知识库的中文地址解析和规范化的方法。
按照如此规则对南网电力用户地址数据进行结构体化改造。改造前后的数据格式如图1、图2所示。
2 地址大数据的存储
随着南方电网信息系统的逐渐完善,系统间集成度的不断提高,信息系统呈现出数据增长加速化、数据类型多样化、业务融合深度化的发展趋势,对数据存储、处理、价值挖掘提出更好的要求,传统数据库工具已经无法满足大数据时代下的数据挖掘需求了。当前,最为流行和稳定的大数据技术生态圈就是Hadoop生态系统。
2.1 Hadoop大数据框架
Hadoop由Apache Software Foundation公司于2005年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由Google Lab发表的Map/Reduce、Google File System(GFS)和BigTable三篇论文的启发。这三篇论文依次对大数据的分布式计算框架、分布式的文件系统以及基于GFS的数据存储系统进行了阐述,这三大组件构成了整个Hadoop分布式大数据体系。随后Yahoo对其进行了开源实现,即Hadoop,并根据GFS开发了HDFS,根据BigTable开发了HBase。同时其他众多开源项目如Hive、Pig等围绕Hadoop构成了完整的生态系统,如图3所示。
Hadoop系统结构结构中的主要模块及其功能如下:
HDFS:为海量数据提供基础的分布式文件系统。
YARN:提供作业调度与集群资源管理功能的分布式计算框架。
MapReduce:海量数据分布式计算处理系统。
Ambari:Web工具,通过可视化的方式,管理并监控Hadoop集群。
HBase:基于HDFS的一种分布式NoSQL数据库。
Hive:数据仓库平台,可提供查询与数据汇总的功能。
Pig:可提供基于MapReduce的一种类SQL查询功能。
Spark:基于内存的一种分布式计算框架。
ZooKeeper:是一个分布式的,开放源码的分布式应用程序协调服务。
2.2 HDFS分布式文件系统
Hadoop作为一种分布式存储与计算框架,通常都是以集群部署模式存在。HSFS是一个分布式文件系统,采用主从结构,在Hadoop集群中通常包括三种节点。这三种节点分别为客户端节点、Master节点和Slave节点。客户端节点实际上是Hadoop为用户提供的一个简易操作控制台,其中包含了Hadoop的Java实现脚本,能够提供类似Linux的命令供用户操纵。在Hadoop的客户端,可以像操作Linux文件命令一样操作Hadoop文件系统。在Linux系统中,查看一个文件夹的内容使用“ls”命令即可,而在Hadoop的客户端则使用“Hadoop fs-ls”即可。
在HDFS系统中,只能有一个NameNode,即上面提到的Master节点。NameNode只是负责保存和管理所有的HDFS元数据,实际上用户数据的读写不需要通过NameNode,而是直接读写在DataNode之上。HDFS将需要存储的文件分割成固定大小的数据块(通常是64MB)。DataNode则负责将数据库以Linux文件的形式保存在磁盘上,并且根据指定的数据块标识和字节范围来读写数据。根据分布式存储系统对于安全可靠性的要求,每个数据块都会被复制存储到多个DataNode节点上。NameNode管理所有的文件系统元数据,这些元数据包括名称空间、访问控制信息、文件和数据块的映射信息。NameNode在系统运行过程中,定期与每个DataNode节点进行通信,发送指令到每个DataNode节点并接收DataNode节点所反馈的数据块的状态信息。整个HDFS分布式文件存储系统的架构设计示意图如图4所示。
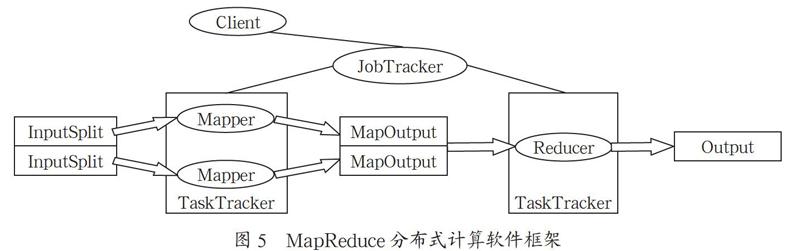
2.3 MapReduce分布式计算软件框架
MapReduce是Hadoop体系之下的一个分布式计算软件编程框架,负责大规模数据集的并行计算功能(如图5所示)。MapReduce采用数据分块处理的思想,把对大规模数据集的操作的处理,通过分发给一个主节点管理下的各个分节点分别处理这样的方式来共同完成,然后通过Master节点整合各个分节点的中间结果,通过计算处理得到最终结果。在这种分布式计算中,MapReduce框架主要负责处理在并行编程中分布式的存储、工作任务的调度、负载均衡处理、容错均衡、容错处理和网络通信等复杂问题。
上面提到,MapReduce实际上主要就是两个任务过程,顾名思义就是Map和Reduce。现在简单介绍下这两个任务的实现过程。
Map任务处理的流程:首先,按行读取HDFS系统中文件,每一行读取成为一个键值对
Reduce任务处理的流程:多个Map任务的输出,按照不同的分区通过网络传输到不同的reduce节点上,对多个Map过程产生的输出进行合并和排序,然后覆盖reduce函数,接收分组后的数据,并在其中实现自己的业务逻辑,处理之后产生新的
2.4 HBase数据库
HBase是基于Hadoop的面向列的数据库系统,是一种典型的NoSQL数据库。HBase是采用主机/从机的架构模式进行数据管理和存储。HBase系统基本上由如下几类节点组成:一个数据库总控节点HMaster、数个数据服务节点HRegionServer、以及ZooKeeper分布式协同服务集群。下面将分别介绍这几类节点所负责的功能。
HMaster是HBase的主服务器程序,尽管HBase支持启动多个HMaster,但是ZooKeeper的Master机器使同一时刻始终只能有一个HMaster节点处于运行状态。HMaster节点负责将region任务分配给region服务器,并对region服务器的负载状态与运行状态进行监控和维护。HMaster节点并不直接对外提供数据服务器,所有的数据读写请求和操作均由region服务器来负责。
HRegionServer作为HBase的核心模块,主要负责具体的数据读取任务。所有的HDFS数据读写请求,用户I/O请求最终实际上都由HRegionServer来完成。HRegionServer节点的具体工作有如下三种:与客户端直接进行通信和数据读写;直接操作HDFS,并对数据库表进行管理;存放并管理当前节点的HRegion。HRegion是HBase系統中的重要模块,每一个HRegion就对应着数据库表中的一个Region,所以HRegion分布在所有的HRegionServer中,而HRegion又是由多个列族对应的HStore组成。HStore是实际负责数据读写的模块,而且其数据写入采用了缓存模式,具体实现方式是,首先将要写入的数据缓存在内存的MemStore中,当MemStore的数据量累计到一定的参数值之后才会实际写入StoreFile中,如果StoreFile的大小以及个数达到一定的参数值之后,HBase又会将StoreFile进行合并。HLog也是与HRegionServer对应的模块,也就是说一个HLog对应了多个HRegion。如果分布式环境中因为系统出错或者其他原因导致HRegionServer意外停止并导致MemStore的数据丢失了,这个时候就需要使用HLog来处理了。由于HLog是在将数据写入MemStore之前就写入了HLog文件的,所以如果MemStore中丢失的数据是可能在HLog中找到的,这也是为什么HLog可以处理数据丢失问题的原因。
整个HBase的工作架构大致如图6所示。
3 结 论
基于Hadoop的电力用户地址结构化与存储技术的重点在于首先需要将非规范化的随意的地址信息进行结构化的改造,然后将其进行大数据的存储处理,以便后续各种应用系统的查询与使用。
结构化的关键则首先在于如何定义标准,即什么样的地址形式被认为是结构化。在这个问题上,我们借鉴了《数字城市地理信息公共平台地名/地址编码规则》标准。随后就是结构化的方法了,我们建议采用基于地址知识库的中文地址解析和规范化的方法。
对于结构化之后的大规模地址数据的存储,则可以使用Hadoop大数据存储系统。HDFS、MapReduce和HBase组成的Hadoop集群分工各司其职,为大规模地址数据的存储利用提供基础。
参考文献:
[1] 孔旭锋,俞成彪,林士勇.电力用户地址结构化管理 [J].农村电气化,2016(2):34-35.
[2] 陈宁,龙致远,罗雁,等.基于大数据的用户地址规范化存储与电力营销设计初探 [J].电子测试,2019(2):79-81.
[3] 王健,周若璇,陆野.省级电力企业采购多维数据结构化与集成化应用研究 [J].现代国企研究,2017(22):75+77.
[4] 刘婷婷,朱文东,陆海兵,等.电力大数据中文地址解析和规范化方法研究 [J].电力信息与通信技术,2017(5):5-11.
作者简介:谢辉(1983.09-),男,汉族,广东兴宁人,本科,研究方向:电网企业营销管理。
