改进随机森林算法综述
2019-10-21孙明喆毕瑶家孙驰
孙明喆 毕瑶家 孙驰

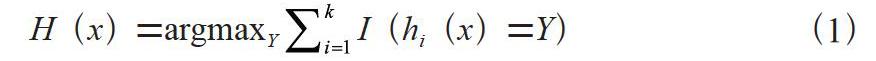
摘 要:随机森林是一种灵活且易于使用的机器学习算法,因为它很简易,既可用于分类也能用于回归任务。在医学、生物信息、环境预测检测等领域有着广泛的应用。为此,本文介绍了随机森林原理及其相关性质,以及它的改进情况及应用,并讨论了以后的改进趋势和方向。
关键词:随机森林;决策树;集成学习;机器学习
中图分类号:TP311.13;TP181 文献标识码:A 文章编号:2096-4706(2019)20-0028-03
Abstract:Random forest is a flexible and easy-to-use machine learning algorithm,because it is very simple and can be used for both classification and regression tasks. It has been widely used in the fields of medicine,bioinformatics,environmental prediction and detection. In this paper,the principle of random forest and its related properties,its improvement and application are introduced,and the future improvement trend and direction are discussed.
Keywords:random forest;decision tree;integrated learning;machine learning
0 引 言
随机森林(Random Forest)是一种比较新的机器学习模型。近十几年来,随机森林得到了迅速的发展,在生物信息领域,Chen等[1]利用随机森林算法蛋白质的相互作用进行了研究;Smith等[2]利用判别分析法与随机森林算法对细菌源追踪数据进行了对比研究。在经济管理领域,Ying等以银行客户的数据为例,运用随机森林算法研究了客户流失情况。此外,随机森林在生态学、经济学[3]、医学领域[4]、刑侦领域[5]和模式识别领域取得了较好的效果。
随机森林算法存在先天性不足主要表现在对数据分类的性能不足。黄衍等人[6]对比随机森林和支持向量机在处理非平衡数据时的性能之后,得出了随机森林算法在处理非平衡分类数据时其性能显著逊色于支持向量机的结论。目前,中国对随机森林的改进研究还是非常少,因此,系统的整理总结随机森林最新的改进与应用情况对接下来的改进很有意义。
1 随机森林原理与性质
1.1 原理
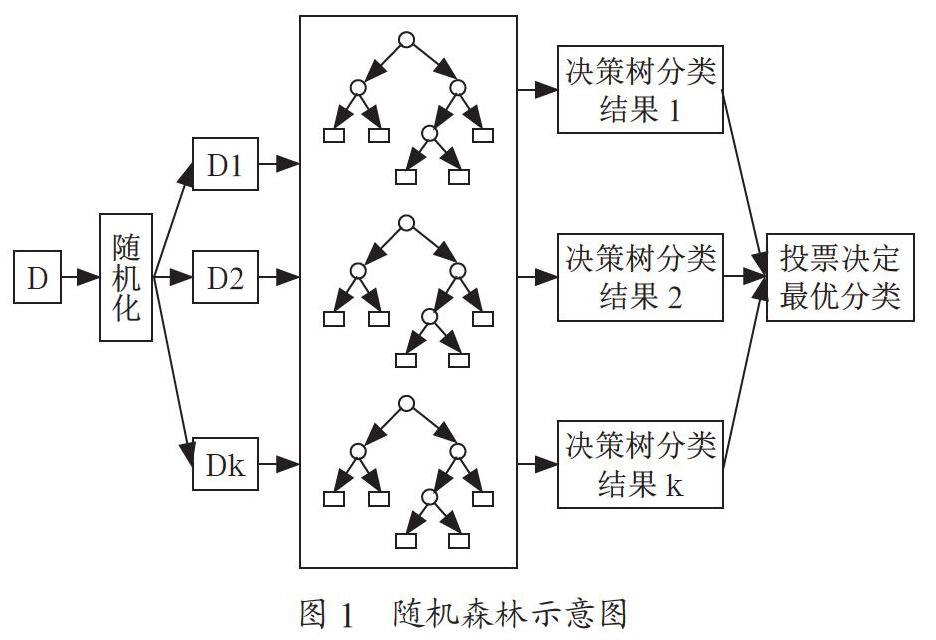
随机森林通过Bootstrap技术,从原始训练集样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,根据样本集生成k個决策树,并且随机组合得到随机森林,新数据的分类结果按决策树投票多少形成的分数而定;D是样本集,D1,D2,Dk分别是每次随机抽样后生成的决策树。随机森林示意图如图1所示。
随机森林算法的实质是对决策树算法的一种改进,将多棵决策树排列组合,每棵树依赖于一个独立抽取的样品来建立,森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力以及各棵树之间的相关性。采用随机的方法分裂每一个节点,比较各种分裂情况下产生的误差。少量的决策树的分类能力有限,只有产生大量的决策树才有可能得到有效的分类效果。
提高组合分类模型的外推预测能力对最终的结果至关重要,因此需要生成不同的训练集来增加分类模型间的差异,通过k轮的训练,得到一个序列{h1(X),h2(X),h3(X), …,hk(X)},再经过简单的多数投票法,最终的分类决策:
其中,H(x)表示组合分类的模型,hi是单个决策树的分类结果,Y表示输出目标变量,I(·)是示性函数。余量函数用于度量平均正确分类数超过平均错误分类数的程度。式(1)说明了使用多数投票决策的方式来决定最终的分类。
1.2 计算变量的重要性
随机森林有一个特点,可以在训练过程中输出变量的重要性,即哪个特征分量对分类更有用。实现的方法是置换法。它的原理是如果某个特征分量对分类很重要,那么改变样本的该特征分量的值,样本的预测结果就容易出现错误。也就是说这个特征值对分类结果很敏感。反之,如果一个特征对分类不重要,随便改变它对分类结果没多大影响。
对于分类问题,训练某决策树时,在包外样本集中随机挑选两个样本,如果要计算某一变量的重要性,则置换这两个样本的这个特征值。统计置换前和置换后的分类准确率。变量重要性的计算公式为:
OOB样本为原始样本集中接近37%没出现在Bootstrap样本中的数据,上面定义的是单棵决策树的变量重要性,计算出每棵树的变量重要性之后,对该值取平均就得到随机森林的变量重要性。计算出每个变量的重要性之后,将该值归一化得到最终的重要性值。
2 随机森林的改进及应用
许多学者提出了一些随机森林的改进方法,现有国内外对随机森林算法的改进可以分为3类,如下所述。
2.1 将新的理论引入随机森林
由于随机森林算法本身就是Bagging算法与Random Subaspace算法结合而得到的新的算法,因此在随机森林的基础上再增加新的算法一直是许多专家学者研究的重点。谢晓龙等利用梯度提升算法对随机森林进行了模型的提升,提出了梯度提升随机森林模型及其在日前出清电价预测中的应用[7],使用集成学习的方法,在随机森林的基础上应用梯度提升算法,有效结合Bagging与Boosting两种集成算法策略的优势,从而提高模型预测的准确性。
邢江宽[8]等基于大量已发表的生物质热解实验数据,采用数值方法拟合全局反应热解模型的动力学参数,建立生物质热解的训练和验证数据库,利用随机森林算法研究生物质热解动力学参数与生物质种类和各种加热条件之间的非线性关系,提出了预测生物质热解动力学参数的随机森林模型,训练结果表明,随机森林模型能够较好地预测不同加热条件下生物质热解的动力学参数。
2.2 数据预处理与随机森林相结合
数据的好坏决定了分类的结果,因此将数据预处理之后再利用随机森林进行分类。可以有效提升随机森林对非平衡数据的敏感度。魏正韬[9]等在基于非平衡数据的随机森林算法的改进中,通过对抽样结果增加约束条件来改进Bootstrap重抽样方法,削弱抽样对非平衡性的影响,并且尽可能保证算法的随机性,之后再利用生成的非平衡系数给每个决策树进行加权处理,提高对非平衡数据敏感的决策树在投票环节的话语权,从而加强了整个算法对非平衡数据的分类能力。
孙悦等针对基于单机的经典随机森林算法无法满足海量数据处理需求的问题,采用Spark分布式存储计算技术设计并实现了改进随机森林算法,提出基于Spark的改进随机森林算法[10],首先计算特征的重要程度,将特征分为公共特征、独有特征和非重要特征;然后按顺序和比例分别在各个特征子空间中随机选择特征;最后通过Spark集群进行实验,分析改进的随机森林算法的分类性能、加速比和效率。结果证实,改进的算法提高了随机森林构建效率,可以用来解决海量数据挖掘问题,具有良好的可扩展性。
为了提高育种领域选种的准确率,同时缩短品种培育年限,邹永潘等利用改进的随机森林算法根据小麦育种历史数据构建评价模型,提出了随机森林算法在小麦育种辅助评价中的应用[11],在训练分类器之前,利用改进的SMOTE算法来改善训练样本集中的非平衡现象;在基分类器训练完成后,测试单个分类器的性能并剔除性能较差的基分类器,实现随机森林中基分类器的筛选。实验结果表明,文中提出的算法在小麦种质评价方面取得了不错的效果,可以辅助育种工作者进行品种选育。
2.3 对随机森林构建过程进行优化
在区域泥石流易发性研究中,科学确定泥石流易发性主控因子及其贡献率既是关键科学问题,也是区域泥石流预警预报和风险管理的重要基础。刘永垚等提出了基于随机森林模型的泥石流易发性评价——以汶川地震重灾区为例[12],初选了63项评价指标,以模型AUC值变化为基础,筛选出35项指标构成易发性评价指标体系,并用于区域内泥石流易发性主控因子的识别,引入随机森林算法,以小流域为评价单元,集合多元因子指标体系,建立泥石流易发性评价模型,定量分析了汶川地震重灾区内泥石流关键影响因子及贡献率,并探讨了研究区泥石流易发性的空间分布特征。结果表明机器学习算法结合小流域为单元的方法对区域泥石流易发性评价有良好的效果,可為区域尺度灾害易发性及风险评估提供更为有效的方法参考。
受特征重要性不平衡的影响,随机森林可能随机抽取到弱特征子集,从而生成“弱决策树”,进而导致模型的收敛速度降低、模型的性能下降。李欢等在融合因子分析的随机森林研究[13]中提出融合因子分析的随机森林模型,主要创新在于采用因子分析法构建特征组,再按特征个数比随机抽取特征形成每个分裂节点的候选子集。提高了模型的准确率和收敛速度,泛化性更强,更加有利于处理高维大数据。
针对线性红外光谱建模方法会导致模型的泛化能力受限,而非线性方法随着光谱特征数目增多会导致模型预测准确度下降的问题,王凯等基于改进特征选择RF算法的红外光谱建模方法[14],对随机森林标准算法的特征选择方法进行改进,据红外光谱与待测组分的相关性对光谱特征重要性进行度量,采用K-均值聚类算法划分光谱特征区,按特定比例从各特征区采样并建立决策树,最终构造随机森林,改后的算法建立较少的决策树就可以达到较高的精准度,也能够降低模型的复杂度。
3 结 论
综上所述,随机森林是一种判别模型,既支持分类问题,也支持回归问题,并且支持多分类问题。它是一种非线性模型,其预测函数为分段常数函数。近几年来,随机森林在理论和方法上都越来越成熟,并被广泛地应用到各个学科之中。研究结果表明,随机森林与其他算法相比确实有较大的优势,结合其他的算法,可以得到更好的结果。在之后的改进方案中,可以更多地将新的理论引入随机森林,结合不同的算法提升算法的性能。随机森林存在的缺点:(1)在噪音比较大的样本集上,该模型容易陷入过拟合;(2)划分比较多的特征容易对随机森林的决策产生更大的影响。针对随机森林存在的缺点,可以考虑在结合不同算法的基础上,优化数据预处理或者对随机森林模型进行重建,或许可以达到更好的效果。在即将到来的5G时代,引入随机森林模型对于建立驾驶人驾驶习性辨识策略,或者自动驾驶技术都会是很好的提升。在接下来的改进中,应更多地依靠应用的需求来设计可实行性高的方案,让随机森林算法得到更好的优化。
参考文献:
[1] CHEN X-W,LIU M. Prediction of protein-protein interactions using random decision forest framework [J].Bioinformatics,2005,21(24):4394-4400.
[2] Smith A,Sterba-Boatwright B,Mott J. Novel application of a statistical technique,Random Forests,in a bacterial source tracking study [J].Water Research,2010,44(14):4067-4076.
[3] 程玉胜,邹欢.基于随机森林的RFM模型对银行信用风险的评估 [J].安庆师范大学学报(自然科学版),2018,24(3):34-37.
[4] 叶雷.机器学习算法在医疗数据分析中的应用 [D].武汉:华中师范大学,2017.
[5] 卢睿,李林瑛.基于随机森林的犯罪预测模型 [J].中国刑警学院学报,2019(3):108-112.
[6] 黄衍,查伟雄.随机森林与支持向量机分类性能比较 [J].软件,2012,33(6):107-110.
[7] 谢晓龙,叶笑冬,董亚明.梯度提升随机森林模型及其 在日前出清电价预测中的应用 [J].计算机应用与软件,2018,35(9):327-333.
[8] 邢江宽,王海鸥,罗坤,等.预测生物质热解动力学参数的随机森林模型 [J].浙江大学学报(工学版),2019,53(3):605-612.
[9] 魏正韬.基于非平衡数据的随机森林算法研究 [D].西安:西安电子科技大学,2017.
[10] 孙悦,袁健.基于Spark的改进随机森林算法 [J].电子科技,2019,32(4):60-63+67.
[11] 邹永潘,王儒敬,李伟.随机森林算法在小麦育种辅助评价中的应用 [J].计算机系统应用,2017,26(12):181-185.
[12] 刘永垚,第宝锋,詹宇,等.Constantine A.Stama-topoulos.基于随机森林模型的泥石流易发性评价——以汶川地震重灾区为例 [J].山地学报,2018,36(5):765-773.
[13] 李欢,熊梦莹,聂斌,等.融合因子分析的随机森林研究 [J/OL].计算机工程与应用:1-10.[2019-07-27].http://kns.cnki.net/kcms/detail/11.2127.TP.20190121.1757.009.html.
[14] 王凯,王菊香,邢志娜,等.基于改进特征选择RF算法的红外光谱建模方法 [J].计算机应用研究,2018,35(10):3000-3002.
作者简介:孙明喆(1997-),男,汉族,山东寿光人,本科,研究方向:信息工程。
