高噪声环境下的生成对抗网络人机语音增强技术
2019-10-18张敬敏程倩倩李立欣岳晓奎
张敬敏 程倩倩 李立欣 岳晓奎
【摘 要】在复杂环境下,传统的语音增强技术存在泛化能力弱、性能表现不足等缺点。近年来,生成对抗网络技术在语音信号处理领域有着重大突破。通过改进传统的生成对抗网络模型,提出了基于深度完全卷积生成对抗网络的高噪声环境下人机语音增强方法。该方法将语音信号语谱图作为生成器输入,判别器根据纯净语音信号指导生成器生成高质量的语音信号,滤除噪声信号。实验表明,通过语谱图和客观质量评分评估,可以发现所提方法可以明显改善语音质量,减少语音失真,增强系统的鲁棒性。
【关键词】生成对抗网络;深度全连接卷积神经网络;语音增强
doi:10.3969/j.issn.1006-1010.2019.08.003 中图分类号:TN929.5
文献标志码:A 文章编号:1006-1010(2019)08-0014-07
引用格式:张敬敏,程倩倩,李立欣,等. 高噪声环境下的生成对抗网络人机语音增强技术[J]. 移动通信, 2019,43(8): 14-20.
The traditional speech enhancement technologies have the disadvantages of weak generalization ability and insufficient performance in complex environments. In recent years, generative adversarial networks (GAN) have a very promising future in the field of speech enhancement. Therefore, this paper proposes a human-machine speech enhancement technology based on deep full convolutional generative adversarial networks (DFCNN-GAN) by significantly improving the traditional GAN model. Specifically, the proposed method uses the speech spectrum of the speech signals as an input of the generator, and the discriminator guides the generator to generate a high-quality speech signal according to clean speech signal. Through evaluating the spectrogram and objective quality score, experiments show that the proposed method can improve the speech quality significantly, reduce the speech distortion, and enhance the robustness of the system.
generative adversarial networks; deep full connected convolutional neural networks; speech enhancement
1 引言
人机交互语音信号会受到周围环境的影响,从而混杂有各种各样的干扰噪声,尤其是在高噪声环境下,人机语音信号的可读性与可懂性将严重受到影响,大大降低了智能语音系统的性能。因此,需要对含噪语音信号进行增强处理,方便后续的语音识别技术处理。语音增强的目的就是最大化地去掉信号中含有的干扰噪声,改善含噪语音质量。现如今,语音增强的应用范围十分广泛,比如军事通信、窃听技术和语音识别等[1]。然而,由于噪声具有随机性、多样性和不稳定性,找到适用于多种环境的语音增强技术是十分困难的。如何提高语音信号增强模型的泛化能力,是现如今的工作重点之一。
本文提出了一种基于深度完全卷积生成对抗网络
(Deep Fully Convolutional Neural Network - Generative Adversarial Networks, DFCNN-GAN)框架来增强高噪声环境下的语音信号。具體地说,用DFCNN结构代替卷积神经网络(Convolutional Neural Networks, CNN)作为GAN的生成器(Generator, G)结构,提高了CNN表达能力。该框架不需要任何前端处理,采用端到端结构自动提取语音特征,可以简化整个系统结构。
2 研究背景
2.1 语音增强方法
在传统的语音增强方法中,通常需要对信号进行频域或时域变换,估计噪声信号的能量信息,然后预测有用信号的分布。经典的语音增强方法有谱减法[2]、维纳滤波[3]、小波变换[4]等。具体而言,谱减法是假设含噪语音信号中只有假性噪声,然后从含噪语音信号的功率谱中减去估计噪声的功率谱,从而得到纯净语音信号。然而,该方法也有着显著的缺点,如被称之为“音乐噪声”的残余噪声存在,在功率谱上呈现出一个个的小尖峰,影响着语音信号的质量。维纳滤波法(Wiener Filtering)是指设计一个最优数字滤波器,根据均方误差最小准则,最小化输出期望的均方误差,滤除噪声等无用信号。但是维纳滤波法不适用于噪声为非平稳随机信号的情形,因此,维纳滤波法很难在实际中得到广泛应用。小波变换法是根据有用信号与噪声信号对应的小波系数的不同来达到语音增强的目的。有用信号对应的小波系数是含有所需信息的,具有幅值大、数目少的特点,而噪声信号具有幅值小、数目多的特点,这样可以确定哪些是有用信号,哪些是噪声信号,从而滤除噪声信号,得到较为理想的语音信号。然而,小波变换的阈值选择是一个难题,同时还存在着冗余大的缺点。
以上方法在语音信号稳定的情况下可以取得良好的效果,然而却都有着很大的局限性。近年来,随着机器学习技术的迅速发展,深度网络[5]、卷积网络[6]和长短时记忆神经网络[7]被应用于语音信号的增强,可以取得令人满意的效果。
2.2 生成对抗网络
生成式对抗网络(Generative Adversarial Networks, GAN)[8]最初被用于计算机视觉和图像领域,引起了巨大的反响。目前,GAN已经逐渐地被用于语音合成、增强、分离和识别等方面,均取得了不错的效果。在文献[9]中,条件生成對抗网络(Condition Generative Adversarial Networks, CGAN)[9]最早被提出用于语音领域,为模型加入监督信息,指导生成器G生成数据,但同时也存在模型结构较为单一、训练困难的问题。文献[10]在GAN的基础上额外增加了声学模型(Acoustic Model, AM)构成的分类器,生成器G、判别器D和分类器构成深度联合对抗网络,以此来提高系统的鲁棒性[10]。文献[11]提出了语音增强生成对抗网络(Speech Enhancement Generative Adversarial Networks, SEGAN)[10],它使用端到端结构,不需要直接处理音频信号,但是在试验过程中,发现在高噪声环境下,SEGAN增强后的语音信号靠近纯净语音信号的能力并不高。
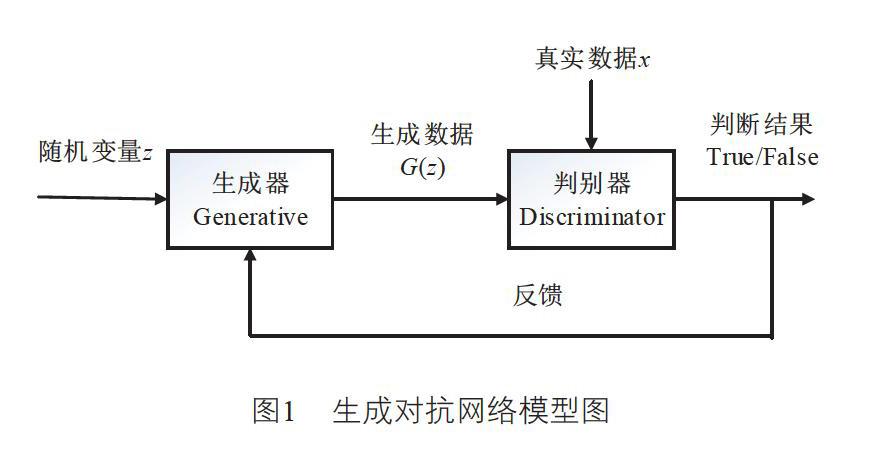
GAN根据二人零和博弈思想而建模,包括生成器G和判别器D这两个部分。生成器G通过学习真实数据中的特征信息生成新的数据样本,判别器D用来比较G生成的新数据与真实数据之间的差异,从而做出判断。事实上,D是一个二元分类器,生成器G的任务是尽可能去“欺骗”判别器D,D则是要尽量区别出来,两者为了达到自己的目的,会不断优化自己的能力,最终达到平衡。
如图1所示,根据GAN的模型结构可以了解到,随机变量z经过生成器模型G,得到生成样本G(z)。生成样本G(z)和真实数据样本x作为鉴别器D的输入,判别器D判断输入数据是真实样本还是虚假样本,将判断结果反馈给生成器G,从而不断优化生成器的输出结果,得到良好的学习效果。生成器G和判别器D之间的极小-极大博弈问题可以通过优化以下目标函数而得到:
V(G,D)=Ex~pdata(x)[logD(x)]+Ez~pz(z)[log(1-D(G(z)))] (1)
其中,pdata(x)表示真实数据的概率分布表示pz(z)输入噪声变量z的概率分布。
但是由于在GAN训练过程中,容易出现梯度消失的问题,这严重影响了实验结果。很多学者都针对此问题进行改进,如较为流行的深度卷积生成对抗网络(Deep Convolutional GAN, DCGAN)[12]也只是对生成器G和判别器D的网络结构进行改进,并没有从根本上解决问题。文献[13]中,Wasserstein生成对抗网络(Wasserstein GAN, WGAN)[13]被提出,它从理论上阐述了GAN训练困难的原因,并引入了Wasserstein距离,提出了解决方法。WGAN是在基础模型上添加了Lipschitz限制,其优势是可以修复模型梯度消失问题,使得模型训练更稳定,目标函数如下:
L=Ex~pdata(x)[D(x)]-Ez~pz(z)[D(G(z))] (2)
2.3 卷积神经网络
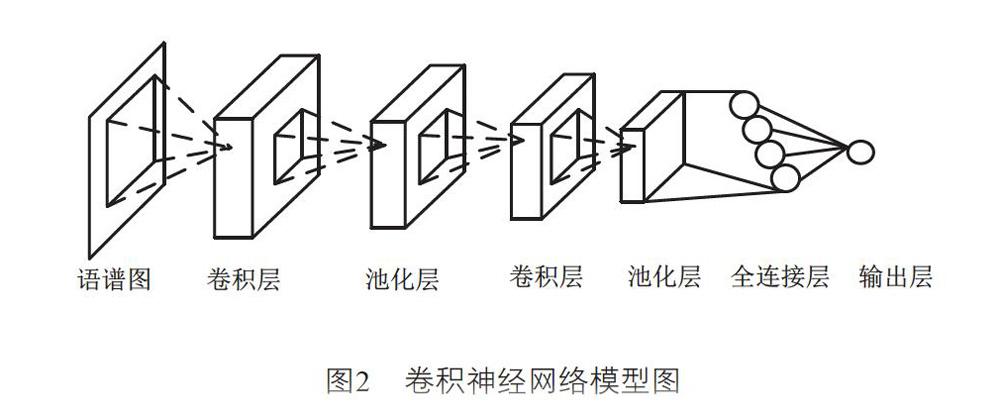
本文所提方法是将生成的对抗网络与深度完全卷积神经网络相结合。其中,卷积神经网络是目前使用最多且应用最为广泛的神经网络结构之一,它是一种可以表征输入信息潜在特征的前馈神经网络,由卷积层、池化层、全连接层构成,常用于图像处理、语音识别等方面。如图2所示,在语音信号处理领域,语音信号的语谱图可以当成二维图像作为卷积神经网络的输入,避免传统方法繁杂的特征提取等操作。下一层卷积层连接其视野内的像素,而不是连接全部语谱图的每个像素,进行卷积操作,提取语谱图的局部特征,之后卷积层的滤波器选择一定的步长滑动,直至处理完全部语谱图的分析。卷积运算可以在一定程度上提高信号的部分特征,同时降低干扰信息。同理,之后每一层的神经元的输入都连接上一层的局部感受野。由于滤波器在滑动时,部分像素会重叠,因此会产生冗余信息,池化层的主要工作是将某个点的值转化为相邻区域的值,减少冗余信息,同时使得参数的数量减少,防止发生过拟合的情形。
3 基于深度完全卷积生成对抗网络的语
音增强方法
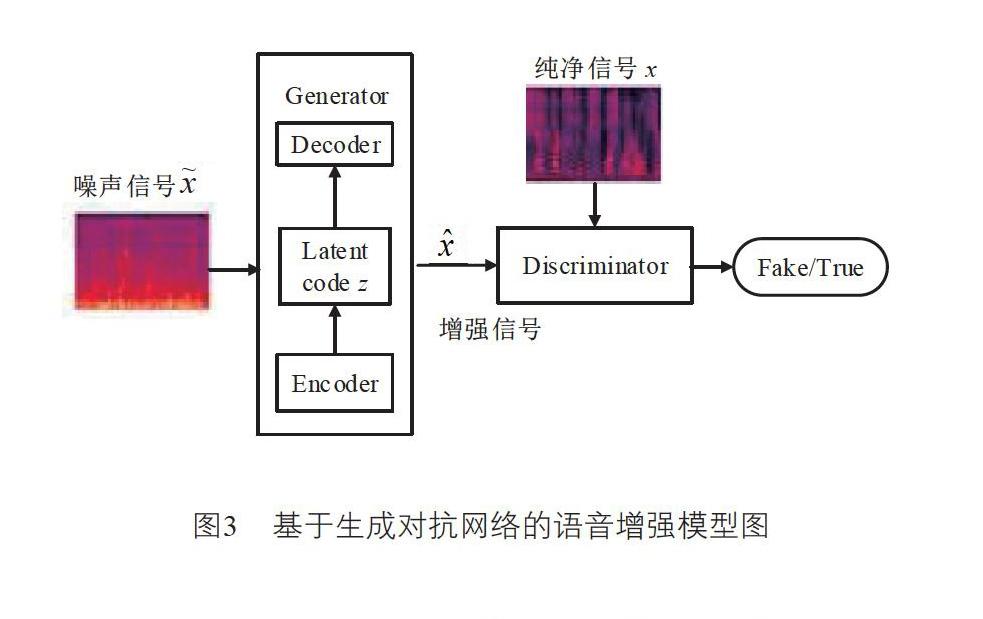
如图3所示,对于语音增强来说,GAN实际上是一个学习过程,其中生成器G输入噪声信号x~,判别器D输入纯净的语音信息x,判别器D指导生成器G生成增强的语音信号。D的任务是区分干净的语音信号和增强的语音信号之间的差异,哪些是真实样本,哪些是虚假样本。
本文所提方法中,生成器G网络是一种编码-译码器框架。在编码阶段,直接将语音转换为图像数据作为输入,对每帧语音进行傅里叶变换,然后将时间和频率作为图像的二维输入,通过组合许多卷积层和池化层,对语音信号自动进行特征提取来代替传统的人为提取语音特征方式。在多个卷积层之后添加池化层,累积大量的卷积-池化层对,通过一系列卷积层来压缩语音信息。每个卷积层使用小卷积核而不是大卷积核,并且使用均方根误差(Root Mean Square prop, RMSprop)激活函数用于获得卷积结果。在编码器编码之后,获得状态向量z,然后输入转置的卷积(有时称为去卷积)。解码器阶段,在多个卷积层之后添加转置卷积层,对应于编码器阶段。在非线性变换之后,获得的增强语音信号如图4所示:
在本文中,為每两个卷积层添加一个汇聚层,导致卷积池层对的积累,从而有效减少信息丢失并提高系统模型表示能力。另外,在保证相同感知视野的条件下,使用小卷积核代替大卷积核可以提高网络深度,并且在一定程度上可以提高神经网络的有效性。
GAN语音增强可以概括为最小-最大问题。使用增强的WGAN[14]可以获得良好的结果,即基于WGAN添加惩罚项,其具有比原始WGAN更快的收敛速度,并且可以生成更高质量的样本。在WGAN中,判别器的损失函数是:
4 训练及仿真结果
4.1 训练细节
为了系统地评估DFCNN-GAN模型的有效性,本文选择开源数据集进行训练分析[15]。数据集中有来自语音库的30名英语母语者,这些语音信号包含有多种类型噪音。语音库中测试集包含两个英语母语者,每人约有400句纯净和噪音测试语音信号,共有824个语音。训练集包括28名英语母语者,每人400句纯净和噪声训练语音信号,共计11 572个语音。在噪声训练集中,有40种不同条件,包括10种噪声(2种人工噪声和8种来自需求数据集[18]的噪声),分别有4种不同的信噪比(15 dB、10 dB、5 dB和0 dB)。在测试集中,有20种不同的条件,包括5种类型的噪声(均来自需求数据库),其中有4种不同的信噪比(17.5 dB、12.5 dB、7.5 dB和2.5 dB)。
DFCNN-GAN模型采用RMSprop算法,在86个时期内进行训练。在训练过程中,学习率设置为0.000 2,批量训练大小为256。为了满足波形产生的要求,实验时将原始声音从48 kHz降到16 kHz。预加重系数设置为0.95。
生成器网络是由卷积层和转置卷积层实现的编码器-解码器结构。为了在边界处得到卷积结果,本文选择了“same”填充方法。为了避免梯度消失,每个卷积层和反卷积层后面都有一个预激活函数。在编码器部分,每两个卷积层添加一个池化层,池窗口设置为2。在解码器部分,每两层添加一个反池化层,池窗口设置为2。
判别器D由卷积层实现,采用“same”零填充策略。为了激活所有的神经元,使用了带泄露修正线性单元(Leaky ReLU)。在所有卷积层和Leaky ReLU激活层之间都有一个批处理规范化层。同时,为了确保后一层的输入数据,选择批量规范化层。
4.2 仿真结果
为了全面系统评价增强后语音信号的效果,本文将所提算法与GAN、Wiener、SEGAN以及原始的含噪语音信号相比较,对比表现DFCNN-GAN性能。为了评估增强语音的质量,本文计算了以下参数。
(1)语音质量感知评价(Perceptual Evaluation of Speech Quality, PESQ):利用语音信号客观特性去模拟人主观意识,从而对语音质量进行感知评估,评分范围是[-0.5~4.5]。
(2)平均意见分(Mean Opinion Score, MOS):对语音信号的主观感知根据评判标准来评分,是一种主观评价,也是使用最为广泛的一种语音质量评价方法。
(3)分段信噪比(Segmented Signal to Noise Ratio, SSNR):一种常用的语音信号质量的评判标准,反映了某一段范围内语音信号的信噪比,评分范围是[0~∞]。
表1显示了不同语音增强方法的度量分数,可以得出基于深度全连接卷积生成对抗网络的语音增强方法具有更加优良的去噪效果。与Wiener滤波和SEGAN相比,DFCNN-GAN各项指标都有一定程度的改进。而且,SEGAN的PESQ指标较差,但DFCNN-GAN可以在一定程度上弥补其缺陷。
为了便于直观理解,本文分别获得传统GAN、Wiener、SEGAN和DFCNN-GAN生成的语音信号频谱图。图5列出了频谱图的比较图,从图中可以发现,传统的生成对抗网络的效果最为不好,这是因为它具有训练不稳定、易发生梯度爆炸等缺点。DFCNN-GAN的训练效果最好,更为接近纯净语音信号的频谱图,与其他信号相比,可以有效滤除噪声信号,提高语音质量。
5 结束语
本文提出了一种新颖的DFCNN-GAN算法来增强含噪语音信号,该算法使用编码器-解码器作为G的结构,并将其与DFCNN结合以加深卷积层的特征提取能力。同时,本文使用增强WGAN算法在目标函数中添加梯度惩罚项以实现语音增强。仿真结果表明,该模型能够有效降低噪声,提高语音信号质量,同时该模型更加稳定,可以提高收敛速度,为高噪声环境下人机语音增强技术的研究提供了新的解决思路。
参考文献:
[1] P C Loizou. Speech Enhancement: Theory and Practice[M]. Boca Raton: CRC Press, 2007.
[2] M Berouti, R Schwartz, J Makhoul. Enhancement of Speech Corrupted by Acoustic Noise[C]//IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 1979: 208-211.
[3] J S Lim, A V Oppenheim. All-pole Modeling of Degraded Speech[J]. IEEE Transactions on Acoustics Speech and Signal Processing, 1978,26(3): 197-210.
[4] S Jaikaran, A Rajeev. Noise Reduction of Speech Signal Using Wavelet Transform with Modified Universal Threshold[J]. International Journal of Computer Applications, 2011,20(5): 14-19.
[5] J Yi, R Liu. Binaural Deep Neural Network for Robust Speech Enhancement[C]//IEEE International Conference on Signal Processing. Guilin, 2014: 692-695.
[6] P Guzewich, S Zahorian. Speech Enhancement and Speaker Verification with Convolutional Neural Networks[J]. Journal of the Acoustical Society of America, 2018(3): 1956.
[7] F Weninger, H Erdogan, S Watanabe, et al. Speech Enhancement with LSTM Recurrent Neural Networks and its Application to Noise-Robust ASR[C]//International Conference on Latent Variable Analysis and Signal Separation. Springer International Publishing. San Diego, 2015: 305-311.
[8] I J Goodfellow, J P Abadie, M Mirza, et al. Generative Adversarial Nets[C]//International Conference on Neural Information Processing Systems. MIT Press, Kuching, Malaysia, 2014.
[9] M Mirza, S Osindero. Conditional Generative Adversarial Nets[J]. Computer Science, 2014: 2672-2680.
[10] LIU B, NIE S, ZHANG Y, et al. Boosting Noise Robustness of Acoustic Model via Deep Adversarial Training[C]//IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Calgary, Alberta, Canada, 2018: 5034-5038.
[11] S Pascual, A Bonafonte, J Serrà. SEGAN: Speech Enhancement Generative Adversarial Network[C]//Interspeech, Stockholm, Sweden, 2017: 3642-3646.
[12] A Radford, L Metz, S Chintala. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks[J]. Computer Science, 2015: 1-6.
[13] M Arjovsky, S Chintala, L Bottou. Wasserstein GAN[EB/OL]. [2019-07-10]. http://arxiv.org/pdf/1701.07875.
[14] I Gulrajani, F Ahmed, M Arjovsky, et al. Improved Training of Wasserstein GANs[EB/OL]. [2019-07-10]. http://arxiv.org/pdf/1704.00028.
[15] C V Botinhao, X Wang, S Takaki, et al. Investigating RNN-based Speech Enhancement Methods for Noise-Robust Text-to-Speech[C]//ISCA Speech Synthesis Workshop. Seoul, Korea, 2016: 146-152.★
