特定用户群体关系挖掘与分析研究
2019-10-18陈志扬曹金璇聂世民
陈志扬 曹金璇 聂世民
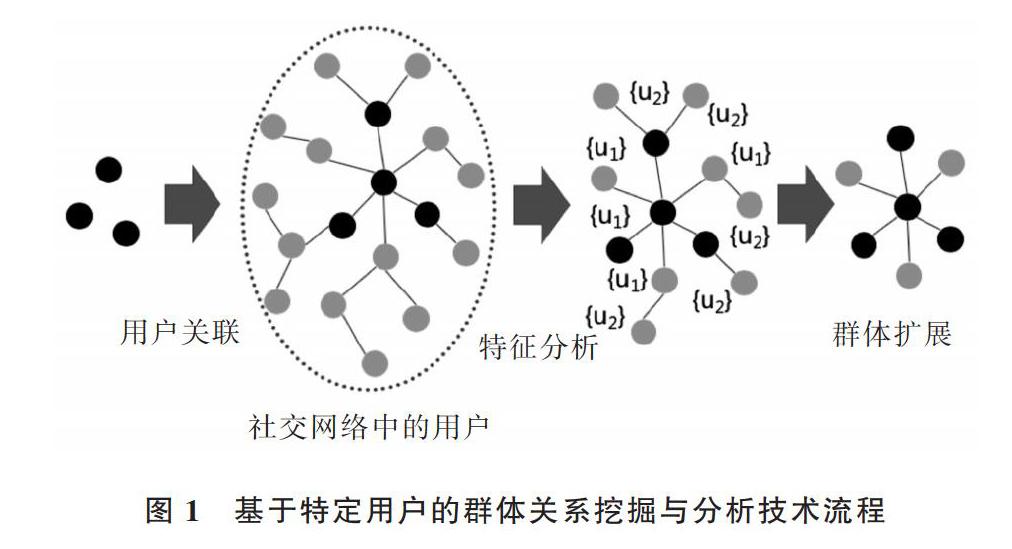
摘 要:为挖掘当前社交网络中具有相同内在因素、特定组织结构的群体,提出一种基于特定用户的群体关系挖掘与分析方法。首先,以特定用户为切入点,改进基于最短路径的图聚类算法,以此关联它们之间的关系,构建初级群体;然后,构造初级群体属性特征比对集合,利用动态权重相似性对其进行扩展,挖掘它们所处的群体;最后,对挖掘出的群体进行聚类效果评估。实验结果表明,该方法聚类效果良好,能够有效挖掘相关群体,为社交网络中的群体发现提供了新思路。
关键词:群体发现;图聚类;最短路径算法;特定用户
DOI:10. 11907/rjdk. 191909 开放科学(资源服务)标识码(OSID):
中图分类号:TP393文献标识码:A 文章编号:1672-7800(2019)009-0183-05
Research on Group Relationship Mining and Analyzing Based on Specific Users
CHEN Zhi-yang1, CAO Jin-xuan1,2, NIE Shi-min1
(1. Information Technology & Network Security Institute, Peoples Public Security University of China;
2. CIC of Security & Law for Cyberspace, Peoples Public Security University of China, Beijing 100038, China)
Abstract: In order to mine the groups with the same internal factors and specific organizational structure in the current social network, a method of mining and analyzing group relationships based on specific users is proposed. Firstly, with the specific user as the entry point, the graph clustering algorithm based on the shortest path is improved, and the relationship between them is established to construct the primary group. Then, the primary group attribute feature comparison set is constructed, and the dynamic weight similarity is utilized. It is extended to mine the groups in which they are located; finally, the clustering effect is evaluated on the excavated population. The experimental results show that the method has good clustering effect and can effectively mine relevant groups, which provides a new idea for group discovery in social networks.
Key Words: group discovery; graph clustering; shortest path distance; specific users
0 引言
社会成员通过在互联网上进行日常交流、信息发布以及互动交友,逐渐形成了某种稳定关系,进而形成社交网络[1]。社交网络群体是一个抽象概念,群体可理解为由许多个体,由于一些相同的兴趣、目的与利益等内在因素有组织地聚集在一起形成的集合。群體内用户相互交流、传递信息[2]。
社交网络群体关系挖掘具有重要意义[3]。一方面,群体关系挖掘结果具有最直接的影响价值,能在信息检索、好友推荐、新闻传播控制等许多方面有效应用。另一方面,当前社交网络存在一些特殊群体[2],这些群体基于特定的原因聚集,进行恶意有害行为,如网络传销群体、网络谣言群体和网络诈骗群体等,这些群体行为常常对社交网络环境造成巨大危害。将这些特殊群体进行合理管控的基础便是对其进行有效挖掘。所以,群体关系挖掘对于促进社交网络发展和网络空间安全都具有重要的研究价值[4]。
社交网络群体性问题,往往最先发现于某些特定用户,这些用户之间也许并不存在直接联系,但由于他们进行的是相同活动,则必定会通过没有被发现的所在群体的其它成员进行勾连,若能找出他们之间的关系并利用群体属性特征进行分析,即可得到较为完整的目标群体。
本文首先介绍了当前社交网络中基于结构特征和属性特征的群体挖掘方法,提出一种基于特定用户的群体关系挖掘与分析方法。改进了基于最短路径的图聚类算法,以此对特定用户进行关系关联;针对群体扩展,提出一种基于节点属性动态权重的群体相似性度量方法,构造了初级群体属性比对集合,用集合与扩展节点属性进行比较,以此进行群体关系扩展;最后,采用Silhouett指数进行聚类效果评估,为社交网络群体发现提供新方法。
1 社交网络群体发现方法
社交网络群体发现就是把群体作为检索目标,利用群体在关系结构或者个体属性上的可挖掘特征作为发现基础,对具有特定组织结构或属性特征的用户子集进行挖掘的过程。通常把社交网络群体发现方法分为基于群体结构的图聚类算法和基于属性特征相似度两类。
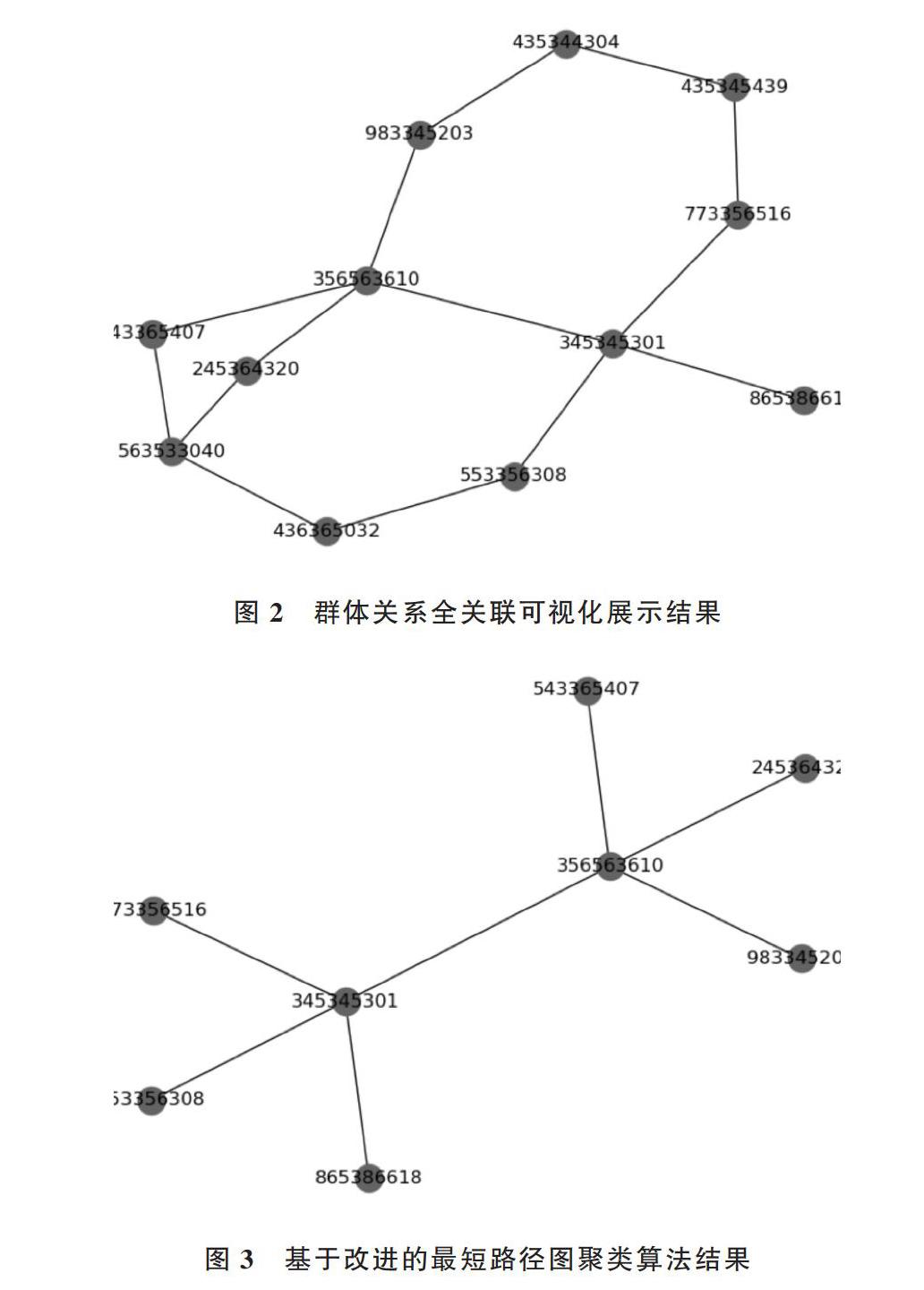
图2是对6个特定用户(‘773356516,‘865386618,‘553356308,‘983345203,‘543365407,‘245364320)进行群体关系全关联的可视化展示结果,图3是基于改进的最短路径图聚类算法可视化展示结果。可以看出图3是对图2使用最短路径距离计算的结果,群体呈现树状结构。
2.4 初级群体特定用户节点属性特征分析
特定用户组成的初级群体不仅仅从结构上有联系,在进行群体活动时,它们还具有相同或相似的属性特征,基于此,对特定用户組成的初级群体拓扑图利用关系与属性特征相似度进行扩展。
特定用户构成初级群体时,它们中的相同特征越多,出现次数最多的那个特征权值也越大。结合初级群体关系拓扑图与特定用户属性特征分析,本文提出基于初级群体特定用户节点属性动态权重的群体扩展算法。
初级群体中的特定用户个体属性信息在某种程度上反映了用户特征。同一群体必然有相同的特征,特定用户之间相似度最高的特征必然也是完整群体所包含的特征,基于此,利用这些特征进行扩群。本文采用对特定用户打标签的方式,将标签作为关键字并对关键字进行分类,关键字分属于不同的属性[15]。首先对初级群体中的用户进行分析,找出它们的相似特征,建立初级群体属性比对集合,在与扩展群体个体用户属性对比时,对同一种属性的关键字出现的次数进行统计,把出现次数最多的前n个属性关键字作为该属性占总值的比例,作为节点属性的具体数值。本文根据群体聚类的不同目的对属性权值进行设置,依据不同群体的划分目的,对属性权重大小进行分配,以此达到更加有效扩展群体的目的。
算法步骤如下:
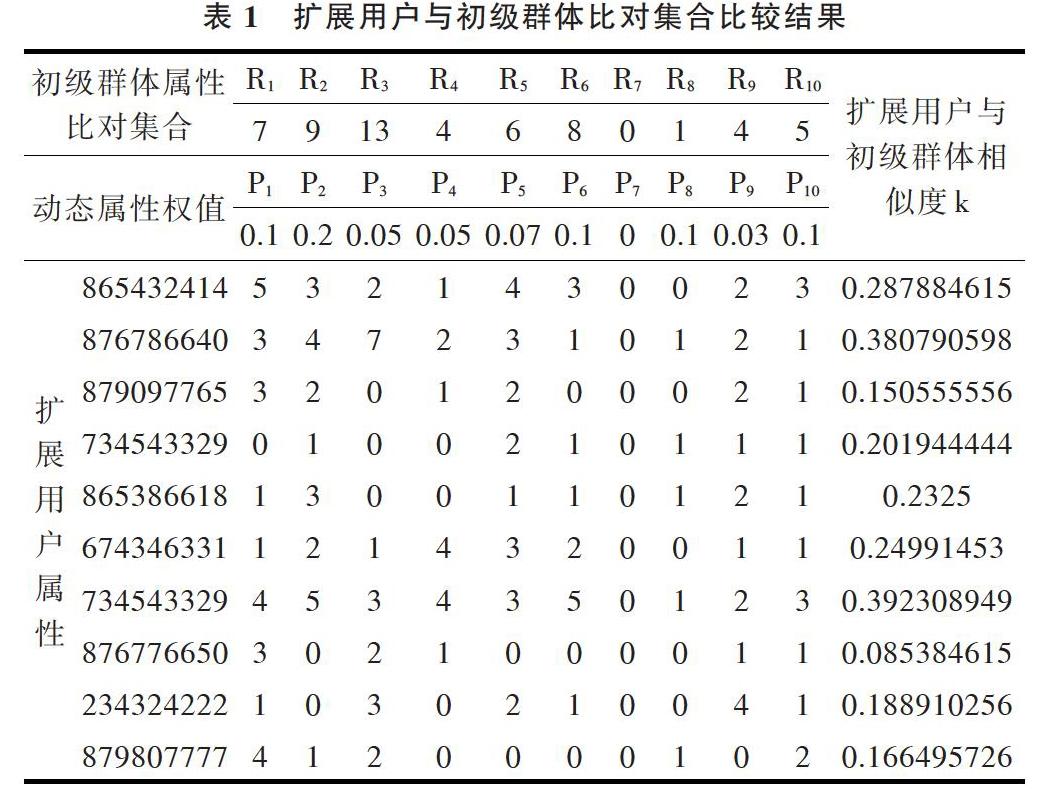
(1)在特定用户组成的网络关系拓扑结构(即初级群体)中,每个节点代表一个用户,用户存在若干属性。假设存在n个属性(Q1,Q2…Qn),统计初级群体各个用户n个属性分别出现的次数,依此建立初级群体特征属性比对集合(R1,R2…Rn)。
(2)对初级群体进行扩展,将扩展群体中的个体用户属性与比对集合进行比较,各个属性出现的次数设为属性值集合为(O1,O2…On)。
(3)基于各个属性的重要程度不同,为属性集(O1,O2…On)每个元素分配权值P1,P2…Pn,Pi的取值,根据不同的群体特征以及属性的相关程度动态分配权值,P1,P2…Pn需要满足P1+P2…Pn=1。
(4)设置扩展用户与初级群体相似度k,k的取值范围为(0,1)。k值计算公式如下:
[ki=1nj=1nQjRjOjPj,0k1] (1)
其中,[QjRj]是各个属性与初级群体比对集合的比值,[OjPj]是属性集进行权值分配后的结果。
表1为扩展用户与初级群体比对集合的比较列表。
2.5 基于节点属性动态权重的群体扩展算法设计
接下来依照初级群体起始节点与初级群体属性特征对初级群体进行扩展。由于社交网络交错复杂,在网络数据理想的情况下,初级群体可以无限扩展[16],但无限扩展并无意义。因此,设定扩展阈值,一次扩展代表扩展用户的直接好友。扩展算法如下:
(1)以初级群体起始点为起始,按照初级群体特征表对比结果中的相似度k1进行第一次扩展,其中k1根据实际群体特点设定。
(2)把第一次扩展的结果设为起始节点,计算扩展节点与初级群体属性比对集合相似度k2。按照相似度k2进行第二次扩展,其中k2根据实际群体特点设定。
(3)设置扩展阈值n,相应的节点与初级群体属性比对集合相似度为kn,既可逐次扩展,也可一次完成多级扩展,结合目标群体特征进行扩展阈值设置。
对‘873567812节点进行5级好友关系扩展结果如图4所示,扩展结果显示了以该节点为起始点的5级好友关系路径,图5则是所有路径结果的图形可视化展示。
3 聚类效果评估
3.1 群体挖掘评价标准
对群体挖掘效果进行评估,通常采用内聚系数、SD指数、DB指数和Silhoueete指数这几个评价标准。
内聚系数指聚类好的簇的标准差,标准差越小,簇内各个节点越聚集,簇中节点与质心的距离越小,聚类效果越准确。SD指数[17]是基于簇的平均离散度和簇间总体离散度的有效评价方法。DB指数[18]用来表示簇内分离度及簇间相似度,DB指数越小说明聚类效果越好,它是聚类指标中最为常用的有效性指标。Silhoueete指数[19]结合了内聚度和离散度两种因素,既考虑了簇内各个节点的内聚性,也考虑了簇与簇之间质心的离散性。对于节点i来说,定义其Silhouett指数为:
其中A(i)指计算节点到所属簇中所有其它节点的平均距离,B(i)指计算节点到各个非本身所在簇的所有节点的平均距离。Silhouett指数取值范围在-1到1之间,指数越接近1,则群体关系图聚类结果越明显。
3.2 实验结果与分析
实验所用数据来自某单位经过脱密处理的社交网络数据,节点数为5 790个,边数为2 407条。对于本实验数据结果,由于内聚系数、SD指数、DB指数没有统一的归一化处理[20],所以采用Silhouett指数进行评估即可。
为避免标准数据集单一,本文抽取两个数据集,选取6组属性相异度较大的特定用户进行实验。表2是数据集与群体挖掘结果Silhouett指数对比。
实验结果显示:6组特定用户的挖掘结果中,Silhouett指数有5组大于原数据集Silhouett指数。其中第5组人为选定特定用户时,对用户特征的判断出现偏差,因此出现Silhouett指数略低于原数据集的情况。基于第一个数据集中3组挖掘结果(即第1、2、3组)与第二个数据集中2组挖掘结果(即第4、6组)Silhouett指数与原数据集相比,都相当接近于1,说明本方法聚类效果良好,聚类结果具有较高的参考价值。
