基于SSDKmeans算法的微博热点话题发现研究
2019-10-18李海明
李海明

摘 要:为及时从海量微博信息中迅捷有效提取出微博热点话题、事件,提出基于频繁集的聚类SSDKmeans算法,在有限空间下统计分词的近似频数,并在此基础上构建文本向量空间模型,在聚类生成的每个话题簇中提炼话题关键词。通过对2万条微博数据进行有效性验证,结果表明,基于SSDKmeans算法的话题发现有较高的召回率和精准率,分别为91.3%、92.1%。SSDKmeans算法能够有效提高微博热点话题发现率,进而及时了解社会热点话题与舆论趋势。
关键词:话题发现;文本聚类;微博短文本;频繁集
DOI:10. 11907/rjdk. 192006 开放科学(资源服务)标识码(OSID):
中图分类号:TP391文献标识码:A 文章编号:1672-7800(2019)009-0173-03
Research on Hot Topic Discovery of Microblog Based on SSDKmeans Algorithms
LI Hai-ming
(College of Computer Science and Engineering,Shandong University of Science and Technology,Qingdao 266590,China)
Abstract: In order to quickly and effectively generate hot topics and events from the massive micro-blog information, in this paper, a clustering algorithm based on SSDKmeans of frequent sets is proposed to calculate the approximate frequency of word segmentation in finite space, and on this basis, a text vector space model is constructed to extract topic keywords in each topic cluster generated by clustering. The validity of 20 000 real microblog data is verified. The experimental results show that topic discovery based on SSDKmeans algorithm has higher recall rate and precision rate, 91.3% and 92.1% respectively. SSDKmeans algorithm can effectively improve the discovery of hot topics in Microblog, and then more timely understand the social hot topics, public opinion trends.
Key Words: topic discovery; text clustering; microblog short text; frequent sets
0 引言
據《第 42 次中国互联网络发展状况统计报告》,截至 2018 年 6 月,微博注册人数约 3.5 亿,中国网民占比达42.13%。微博平台每天发布海量数据,数据涵盖许多热点话题及事件描述[1]。如何高效处理海量微博数据、快速发现热点话题是研究热点。
微博通常以短文本形式呈现,其特点是短文本、噪声大、网络用语多。微博用户通过不同方式传发信息,如网页页面转发、点赞等;支持客户端设备也有多种,如平板电脑、台式电脑及笔记本等。一方面,对于流传的热点话题用户很在意,并且会主动了解信息的动态;另一方面,微博平台的特征决定了事件、热点话题在其上流传极为迅速 [2-3]。
有研究者通过采集微博数据得出解决问题方案,从而解决社会实际问题。2016年美国总统大选时,推特(twitter)用户发表了许多包含情感及态度的词条,国外有研究人员从中挖掘并分析人们的情感倾向,得到的结果与实际较为相符。
国内微博平台发展晚于国外,目前主要有新浪微博、腾讯微博等。郑斐然等 [4]用算法 Apriori 进行微博热点话题发现,能够迅速找到热点话题。虽然话题发现能力有很大提高,但执行效率还有较大提升空间;杨亮等 [5]基于时间有效性研究话题、事件,微博用户发布信息中包含表达用户的态度词,这些词条有较大的情感倾向,能够较快发现热点话题;文献[6]研究用户之间的相互关系及用户特征,提出基于用户特征的热点话题发现方法 Topic-User,该方法虽然改善了话题词选择,但不具普适性。
以上方法都未考虑将有效频繁项作为微博热点话题词[7]。本文提出SSDkmeans算法,对微博热点话题提取进行深入研究。通过研究微博信息的频繁集词条、微博文本聚类等相关技术,了解最新社会热点话题,实时追踪舆论动向。
1 相关理论
1.1 文本聚类
不同组别的文档类型相似性低,相同组别的文档类型相似性大,这是文本聚类的主要假设依据[8]。之所以文本聚类具备非人工处理能力和较好的可伸缩性,并成为文本信息加工的主要技术手段,是因为聚类不需要机器监测,无须大量模拟训练过程,以及文档分类标注不需要人工干预。
对采集到的微博数据集进行预处理是文本聚类的第一要务,将数学矩阵应用到文本内容并加工整合,即文本数学化、数字化,以特征项表征目标微博文本信息[8]。利用文本信息建立特征项模型最具代表性的是向量空间模型(Vector Space Model,VSM) [9]。1969年Gerard Salton提出了构建文本的VSM模型,是对文档构建的一种统计模型。将每个文档构造为由一个同属性集合词条向量空间中所对应的一个“点”,这是VSM模型的重要思想,数学表征定义见式(1)。
其中,f是一条微博文本,ti表示特征词条,wi 为特征词条的权重值(其中i=1,2,3,…,n)。因为微博文本内容通常很短,单个词条大多出现次数为0或1,能够很好地筛选出频繁出现的词条;而布尔权重法具有操作简单、易于理解的特性,所以本文采用布尔权重法对特征值加权[10]。
布尔标识微博文本,包含对应的特征项权重为 1,否则为 0。
式(2)中,[wij]为微博权重,[tfij]为微博特征项的权重值(其中i,j=1,2,3,…,n)。
建立文本特征向量过程:对文本信息进行预加工 (降噪) ,对微博文本进行词条划割,频繁项集挖掘,构造微博文本向量空间。本文通过将微博短文本映射为VSM所对应的向量空间中的点,使计算机在处理微博文本时更快速、更具有针对性。
1.2 SSDKmeans算法
Kmeans算法[11-13]依据各个类别簇的初始中心点进行分组,再对初始类别进行聚类调整。Kmeans算法的核心问题是初始中心点的选择,如果中心选择不好,聚类结果将会很差。因此,该算法需要反复多次优化调整、重新计算每次优化后的聚类中心,这导致处理巨量数据时算法性能很低。
1.2.1 Kmeans算法中的距离度量
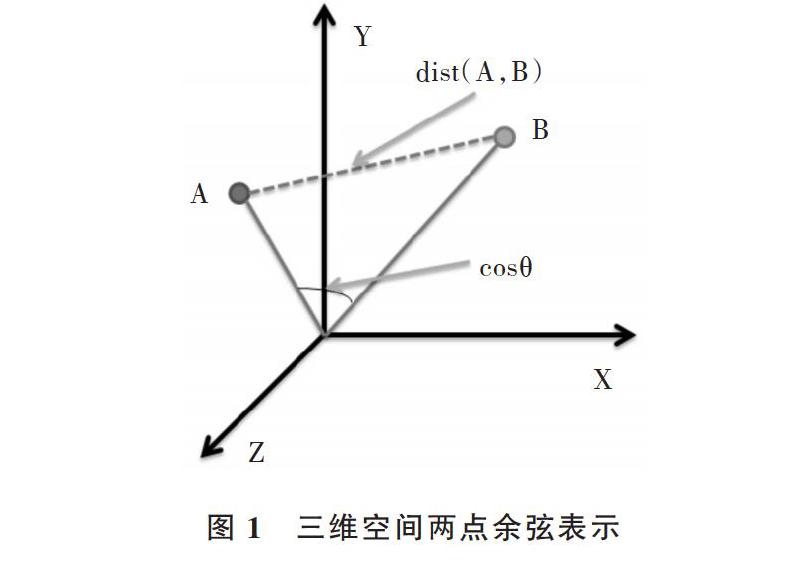
余弦相似度,指向量空间中的向量夹角的余弦值[11]。余弦相似度相对于距离衡量,更关注向量在方向上的区别。如图1所示,空间坐标形象表示了余弦相似度,在三维空间中两个空间向量A、B之间夹角越小就越相似,反之越不相似。
1.2.2 SSDKmeans算法设计
数据流是基于时间排序的一种特殊序列[14]。目前,各种网络平台都应用了数据流技术,如京东、淘宝用户在浏览物品时的图片加载过程、NBA直播等。
频繁项指在数据集合中项的出现次数达到某一阈值[14],如某一数据集合中含有N个数据项,支持度设定为s∈(0,1),那么数据项频数达到sN或者超过sN就归并为频繁项。频繁项广泛应用于领域分析和研究,本文提出结合频繁项挖掘ss(space saving,ss)算法[14]和基于距离改进的Kmeans算法[15-18]即space saving distance kmeans(SSDKmeans)算法处理微博文本。ss算法主要用于数据流计算,其思想是:有N个数据,如果一个新的数据项ei在N里面,则对应的计数加1;如果不在则判断空间是否已经满了,满了则替换计数最小的em,否则直接添加到数据集合D中。
SSDKmeans算法描述如下(其中,输入是微博数据流,输出是微博聚类簇):
①数据集D有N个微博记录词条,每个词条的计数为ci,输入微博词条;
②判断ei是否在D中;
③如果在,fi = fi + ci作为ei的统计频数;
④如果不在,再判断D 空间是否满了;
⑤D空间没满,将
⑥否则查找D中计数值fm最小的数据项em ,将其替换掉;
⑦对步骤⑥频繁项的数据集进行VSM建模;
⑧基于最大最小距离初始m个中心点;
⑨对W[i][j]的每一条微博,分别计算它们与m个聚类中心的距离(通过余弦距離)distance(i,m);
⑩对W[i][j]的每一条微博,计算最近聚类的中心near(i) = mi;
11评判W[i][j]每一条微博,如果所有的微博文本集都属于最近的near(i)这一类别,那么终止。如果不是就继续执行;
12near(i),把i归并到m中,重新计算各个中心(即各条微博的平均值),再循环从步骤⑩开始执行。
2 实验结果与分析
2.1 实验环境
对基于SSD-Kmeans算法的微博文本聚类算法效果进行分析、验证和说明。实验环境为windows7系统,Microsoft Visual Studio2013开发软件,SqlServer2012数据库服务器,算法由 C#语言实现。实验过程中使用的分词工具是中国科学院的NLPIR汉语分词系统[19]。
2.2 数据集介绍
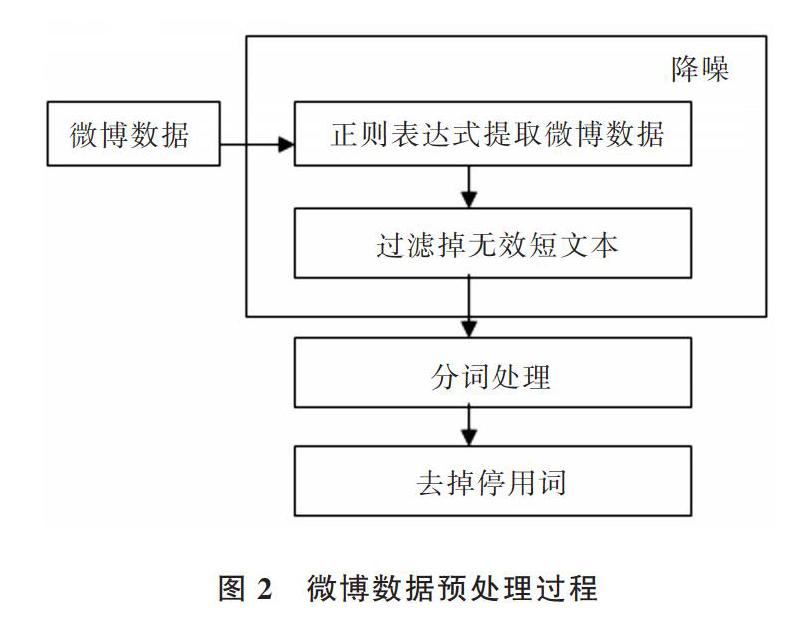
实验使用的数据集来自微博开发者官方平台。通过预处理获取到的微博数据集包含约2万条有效微博文本,处理过程如图2所示。
2.3 实验方法
对微博短文本聚类相似性结果采用召回率和精准率评判[20],召回率指SSDKmeans算法找到的频繁项与实际存在的频繁项之比,数学公式定义为:
2.4 实验结果与分析
对2万多条关于某时间段用户发表的微博文本信息进行实验,部分实验结果如图3所示,其中“||”前面为每条微博的id号(即每条微博的唯一标识号),后面是微博文本信息。抽取的话题词为失联、女童、章子欣、回家。根据新浪微博官方网站提供的热点话题列表进行对照,实际存在的话题如图4所示。
本文进行若干次实验,分别取各自评测指标的平均值进行对比,如表1所示。从表1可以看出,SSDKmeans算法明显优于传统Kmeans算法以及基于距离改进的Kmeans算法。
本文对采集的微博数据预处理后使用SSDKmeans算法聚类,然后通过NLPIR汉语分词系统提供的提取关键词方法抽取话题,最后根据每个话题包含的微博簇进行统计,某段时间话题热度排序结果如表 2所示。
3 结语
微博作为特殊的网络社交平台,正在影响着人们的生活习惯以及信息传播形式。基于SSDKmeans算法的微博文本聚类研究发现,本方案能够较好地发现微博热点话题。未来要研究如何结合深度学习进一步提高微博热点话题发现以及提高自然语言处理的精准性。
参考文献:
[1] 周炜翔,张仰森,张良. 面向微博热点事件的话题检测及表述方法研究[J] . 计算机应用研究,2019,36(12):69-75.
[2] 宋莉娜,冯旭鹏,刘利军. 基于SOM聚类的微博话题发现[J]. 计算机应用研究,2018, 35(3):671-674.
[3] 马哲坤,涂艳. 基于知识图谱的网络舆情突发话题内容监测研究[J]. 情报科学,2019, V37(2):33-39.
[4] 郑斐然,苗夺谦, 张志飞,等. 一种中文微博新闻话题检测的方法[J] . 计算机科学,2012,39(1):138-141.
[5] 杨亮,林原,林鸿飞. 基于情感分布的微博热点事件发现[J] . 中文信息学报,2012,26(1):84-90.
[6] 朱少龙. 基于微博的社会化媒体分析系统的设计与实现[D]. 哈尔滨:哈尔滨工业大学,2011.
[7] TAN P N.Introduction to data mining [M]. 范明,譯. 北京:人民邮电出版社,2006.
[8] 李慧,王丽婷. 基于词项热度的微博热点话题发现研究[J] . 情报科学,2018,36(4):45-50.
[9] 夏云庆,杨莹,张鹏洲. 基于情感向量空间模型的歌词情感分析[J]. 中文信息学报,2010, 24(1):99-104.
[10] 谢婧. 文微博的话题检测及微博预警[D]. 上海:上海交通大学,2012.
[11] HONG L. Internet public opinion hotspot detection and analysis based on k-means and SVM algorithm[C]. Information Science & Management Engineering, 2010:257-261.
[12] MAO D. Improved canopy-Kmeans algorithm based on Mapreduce[J]. Computer Engineering & Applications,2012,48(27):22-26.
[13] DUNDAR M, QIANG K, ZHANG B, et al. Simplicity of Kmeans versus deepness of deep learning: a case of unsupervised feature learning with limited data[C]. IEEE International Conference on Machine Learning & Applications. 2016:456-461.
[14] METWALLY A,AGRAWAL D,ABBADI A E. Efficient computation of frequent and top-k elements in data streams[C]. 10th International Conference, Database Theory - ICDT, 2005:398-412.
[15] 赵将. 基于改进K-means聚类的推荐方法研究[D]. 武汉:华中科技大学,2016.
[16] 郑飞,张蕾. 基于分类的中文微博热点话题发现方法研究[C]. 第29次全国计算机安全学术交流会论文集,2014: 127-131.
[17] KAI P,LEUNG V,HUANG Q. Clustering approach based on mini batch Kmeans for intrusion detection system over big data[J]. IEEE Access, 2018, 6(99):11897-11906.
[18] BOUKHDHIR A,LACHIHEB O,GOUIDER. An improved Mapreduce design of Kmeans for clustering very large datasets[C]. IEEE International Conference on Computer Systems & Applications,2016:233-238.
[19] 中科院计算所. NLPIR汉语分词系统[EB/OL]. http://ictclas.nlpir.org.
[20] MIN L S, TIAN C. Mongolian information retrieval method based on LDA model[C]. IEEE International Conference on Software Engineering & Service Science,2015:162-165.
(责任编辑:杜能钢)
