基于XGBoost和LSTM加权组合模型在销售预测的应用①
2019-10-18陈志德福建师范大学数学与信息学院福州350007
冯 晨,陈志德(福建师范大学 数学与信息学院,福州 350007)
2(福建省网络安全与密码技术重点实验室(福建师范大学)福州 350007)
3(福建省网络与信息安全行业技术开发基地,福州 350007)
随着经济全球化的发展,企业面临着生产成本不断增加,市场销售疲软等考验.企业要想赢得市场竞争就需要对市场具有敏锐的嗅觉以及精准的决策,从而控制成本,降低损耗.这使得企业借助精准高效的销售预测,进而做出可靠的决策,成为现代企业成功的重要手段[1].而对时变数据建模是数据科学中的一个基本问题,应用于医学,金融,经济学,气象学和客户支持中心操作等各个领域.使用在时间序列数据上训练的模型来预测未来值是一个值得充分研究的领域,其中应用了诸如ARIMA之类的传统线性统计模型[2].最近较为流行的是RNN模型的应用,特别是在处理时间序列预测的问题上,LSTM模型的选择记忆功能有着独特的优势[3,4].Xgboost是“极端梯度上升”的简称,该算法既具有线性模型求解器和树学习算法的能力,同时也有着可以在单机上并行计算的能力,能够自动利用CPU的多线程进行并行计算,同时精度也得到提升,相比于其他提升树方法更为优越[5].目前在商品销售预测上的方法很多,如果只用传统的线性回归方法来预测,就忽视了非线性因素的影响,近年来,随着深度学习的不断研究与发展,深度学习的模型被用于时间序列的预测,例如循环神经网络(RNN)将时序的概念引入到网络结构中,但RNN模型也有着几点关键性的不足,梯度的消失和梯度爆炸问题,长期记忆能力不足等问题,进而提出了长短期记忆网络模型[6],基于此,可以采用不同层次的模型进行组合来提高模型的优越性和泛化性[7].
本文针对商品销售的预测进行研究,销售预测是一个分析和报告信息的过程,它能够为管理者提供信息分析和市场研究数据,在此基础上进行经营决策,用来解决一些特定的市场问题,在当代市场竞争中发挥着重要的作用.中国市场野蛮生长的红利期已经过去,经济已从速度向质量转变,企业竞争回归到成本、效率的问题上来.这更需要利用数据以实现精细化运营,然而销售预测需以具体产品为预测对象,在实际场景中更存在着诸多重要的影响销售的因素.因此,为提高预测精度,本文将销售策略量,天气,节假日等加入特征变量中,建立包含相关预测特征条件的多变量模型,结合ARIMA对平稳序列的较好的预测能力以及LSTM对序列非线性部分的出色拟合性能,采用基于XGBoost和LSTM的加权组合模型进行预测,提高预测的精度.
1 相关理论
1.1 ARIMA模型
ARMA模型,即差分自回归移动平均模型,如下结构可以简记为ARMA(p,q):

当p=0时,是AR(p)模型:
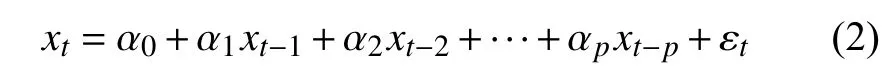
当q=0时,是MA(q)模型:

本文中p,q的取值原则是采用最小信息准则法.通过该方法来识别平稳和可逆的ARMA过程[8].求解p,q在m以内的BIC矩阵,寻找矩阵中BIC信息量最小的位置,从而确定合适的p,q的值,得到ARIMA (p,n,q).
1.2 XGBoost模型
XGBoost是一种在梯度提升决策树算法的基础上进行改进而来的集成学习算法[9-11].其预测原理如下:
预测值为各样本与其权值乘积的累加和,即:

其中,为j样本数,wj为权值,xij为样本数据.XGBoost在做回归时,每棵树是依次加入模型中,进而提升模型的效果,这个集成可以表示为:


其中,γT为惩罚力度,为惩罚项.γ为叶子节点数T的系数.目标函数由自身的损失函数和正则化惩罚项构成,定义如下:

其中,obj为结构分数,表示当选定一个树的结构后,目标减少量的最大值.
1.3 LSTM模型
LSTM Networks是递归神经网络(RNNs)的一种.后经过不断改进,在处理和预测时间序列相关的数据时会比一般的RNNs表现的更好[12].
对于原始的m×n维 数据,记作:

对于多变量的数据需要转化为监督学习的序列,即新的数据表示为如下:

LSTM的模型中采用门的结构来解决了长期依赖问题[13],其具体的神经网络的细胞结构如图1所示.

图1 LSTM记忆细胞结构
图1中每个Sigmoid层产生的数字在0和1的范围内.每个LSTM通过3种类型的门[14]来控制每个单元的状态:遗忘门决定了上一时刻的单元状态ct−1有多少保留到当前时刻ct;输入门决定了当前时刻网络的输入xt有多少保存到单元状态ct.输出门控制单元状态ct有多少输出到LSTM的当前输出值ht.每一步的状态更新满足以下的步骤:

这里 σ 是逻辑Sigmoid函数,◦表示按元素相乘;Wi,Wf,Wo,Wc是权重矩阵;bi,bf,bo,bc是偏移量.
2 基于XGBoost和LSTM的加权组合预测模型
对于实际销售数据中,数据存在周期性,季节性的变化,通常为非平稳的时间序列.通过差分平稳化后,
虽然在ARIMA模型中表现的较好,但却丢失了周期性和季节性特征,并且平稳的数据无法表现出现实销售增量变化,ARIMA模型只依靠内生变量,模型过于简单,无法捕捉序列中的非线性因素.神经网络算法在处理非线性问题具有独特的优势,LSTM模型的加入可以解决以下几个问题,首先是销售数据的连续性,通过特殊的数据输入结构使得模型在预测时结合了历史的状态,其次对比与传统的RNNs解决了输入变长的问题,再者实际销量的影响因素较多,而节假日,策略量的变化会带来销售量的异常变化,通过多变量的模型可以提升拟合的精度.此时特征较多,需要经过处理再放入神经网络的模型中,本文中使用XGBoost算法进行特征的抓取,充分利用多维变量中的潜在的特征.
在ARIMA,XGBoost,LST模型3种模型预测的传递过程会出现误差累计的问题,对此本文对3种模型的预测测结果进行加权处理来减小误差累计对预测结果精度的影响.具体实验过程如图2所示.

图2 XGBoost和LSTM加权组合模型预测结构
对于收集的原始销售序列A={x1,x2,···,xn}进行可视化并观察数据的基本趋势,然后采用增广迪基-福勒检验(Augmented Dickey-Fuller test,ADF),以及JUNG-BOX白噪声检验来检验时间序列的平稳性,对于线性趋势的非平稳时间序列,通过差分变换将其变为平稳序列.收集影响销售的特征值,特征值1,特征2···特征值n,分别记为T1,T2,···,Tn,假设A经 过ARIMA模型后所得到的预测序列Tn+1,则有:

其中,Φ表示ARIAM模型,A(m)为前m个销售数据,A(k)为后d个数据.
将由ARIAM模型所得的预测序列Tn+1加入到特征序列中构建多维数组M={A,T1,···,Tn,Tn+1},经过处理及标准化后放入到XGBoost模型中,得到销量的预测序列Tn+2,则有:

其中,Θ表示XGBoost模型,Ti(m)表示第i个特征序列的前m行,Ti(k)表示第i个特征序列的后k行.
此时再将新的销售预测序列Tn+2加入到多维数组M中得到新的数组M′={A,T1,···,Tn+1,Tn+2},然后加入到LSTM模型中得到销量预测序列Tn+3,则有:

其中,Ψ表示LSTM模型.
最后结合3个模型的商品销量预测量Tn+1(k),Tn+2(k),Tn+3(k),给予相对应的权值,通过多次实验得出最佳的组合权值,进而得到最终的预测值T,记为:

其中,di为各个模型的的预测值的权值.实验步骤如下:
步骤1.ARIAM预测:单变量预测实验,取出原数据中的实际销售数据列X={X1,X2,···,Xn},将 {Xn}放入ARIMA的模型中,对数据列进行ADF平稳性检验及JUNG-BOX白噪声值检测,通过ADF检验可以得到单位根检验统计量对应的p值,此值显著小于0.05,则该序列平稳,通过不断实验后发现,p,q的取值通常在8以内,因此通过循环求解8以内的BIC矩阵,找出矩阵中的最小信息量所对应的p,q的值为1,0,得出预测模型ARIMA (1,0,0),为了使结果更加贴近现实情况,采滚动预测,每预测一周的销售数据后,加入该周的实际的销售数据来预测下一周的销量,最后整理预测值序列,得到销售值序列的样本的预测序列T8.
步骤2.XGBoost预测.将T8序列合并到特征序列中,分成训练集和测试集两部分,然后放入到XGBoost模型中作预测,将预测值记作T9.
步骤3.多维时间序列预处理.将T9合并到M中组成新的数组M1,接着对所有的特征归一化处理,然后利用series_to_supervised函数对数据进行处理,该函数将单变量或多变量时间序列转换为监督学习数据集,使用Pandas的Shift函数,将原始列向后移动k位后添加成新的列,同时将当前时刻的除去销售值的特征移除.
步骤4.LSTM神经网搭建.LSTM模型中,搭建2个隐藏层,第一隐藏层有128个神经元,第二隐藏层有256个神经元,输出层为1维的列向量,即销售预测值,输入变量是一个时间步(t-1)的特征,损失函数采用Mean Absolute Error (MAE),优化算法采用Adam,激活函数采用Sigmoid,模型采用500个epochs并且每个batch的大小为15.
步骤5.数据预测.经过多次的实验,发现当d1=0.2,d2=0.4,d3=0.4时,即

其中,T为最终的销量预测值,Tn+1为ARIMA模型的预测值,Tn+2为XGBoost模型的预测值,Tn+3为LSTM模型的预测值,最后将最终的加权预测值作为后13周的销售预测值.
3 实验分析
3.1 实验环境
实验所使用计算机的配置如下:处理器为英特尔酷睿Duo CPU i5-6500,CPU频率为2.20 GHz;内存为8 GB;操作系统为Windows 10 (64位);基于Python 3.6编程;集成开发环境为PyCharm Community Edition 2016.LSTM的实验使用的是keras深度学习框架.
3.2 实验数据
以某地的从2018年4月2号到11月4号的某商品销量数据为研究对象,数据集中主要包含7个特征,分别是节假日因素,气温,主要策略规格的策略量以及实订量等,如表1所示.

表1 数据特征
对于节假日因素,本文采用虚拟变量来进行量化处理,记作T1,取每周最高气温的平均值及最低气温的平均值,分别记作T2,T3,主要策略量的实订量记作T4,年月日分别记作T5,T6,T7,然后构建多维数组M=(X,T1,T2,T3,T4,T5,T6,T7),划分数据.将数据的前0.67作为训练集,后0.33作为测试集,对未来13周的销售量进行预测.
3.3 参数选择
在LSTM模型中,n_1为series_to_supervised函数中设置的滞后观察数为1,即使用上一时刻的销售量来预测当前时刻的销售值,设置两个隐藏层,第一层的神经元个数设为128,第二层的神经元个数设置为256,dropout随机删除一些隐层神经元,通过不断的调整这两个参数来解决预测过程中的过拟合的问题.具体参数设置见表2.

表2 神经网络参数
在XGBoost模型中,subsimple为训练的实例样本占整体实例样本的比例.max-depth为每棵树的最大深度.booster为设置需要使用的上升模型.objective定义学习任务及相应的学习目标,本文选的目标函数为“reg:linear”-线性回归.具体参数设置见表3.

表3 XGBoost参数
3.4 实验结果及分析
为了更好的体现模型的优越性和实用性,本文主要采用两个指标来进行模型的评估,第一个是均方根误差(Root Mean Square Error,RMSE),以及一个平均准确率(Mean Accuracy,MA),定义如下:
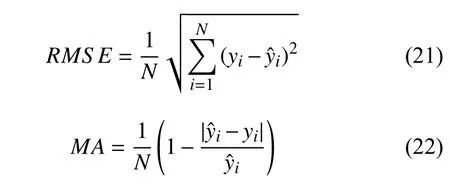
使用四种模型分别预测出后13周的销售值,导出组合模型的预测值,图3为组合模型预测值和实际销售值的对比,销量变化的趋势得到较好的拟合,预测平均准确率为0.968,预测误差很好的控制在了0.05以内,预测相对准确.

图3 预测值与实际值对比
图4反映的是单个模型及组合在每周的预测的精度对比,从图中可以看出,不同模型预测时的表现的具有一定的差异性,也存在个别异常时间点在单个模型预测中效果不佳.首先对比3个模型的预测情况,ARIMA模型预测效果是较弱的,对于波动的灵敏度较低,XGBoost和LSTM预测效果相对接近,因此本文主要采用简单平均法来分配权重.对比每周的预测结果,LSTM比XGBoost模型在预测精度表现较好,但稳定性相对较差,因此在分配权重时既要保留XGBoost模型预测稳定的特点,同时也能提高模型的精度,因此对于这两种方法赋予相同的权值.对于数据内生变量的影响通过分配ARIAM模型相对较小的比重进行模型的预测值的调整.基于该想法进行预测结果的加权分析,通过计算不同比重下预测结果的平均精度和RMSE的值,发现在XGBoost和LSTM所占都为0.4时,ARIMA占0.2时,组合模型整体预测效果表现最佳,对于非线性部分拟合的效果明显的体现除了加权组合的优势,对比单个模型出现准确率在0.8附近的异常点,组合模型的预测准确率都在0.9以上,对比单独模型预测良好的部分,组合模型保持了良好的预测精度,预测结果的精度对比单一模型有很大的提高,对于其他特征(策略量,温度,节假日,日期)实行了一次复制,即这些变量会在每个模型行的训练中出现两次,而结果证明训练集误差几乎一致,但是验证集误差更小,表明通过特征的重复训练,能够减小组合模型的过拟合程度,模型的泛化性得以提升,预测效果更佳.

图4 不同模型预测精度对比
观察不同模型的指标数值,由导出的预测值和实际值求解出各个预测模型的RMSE指标值和MA指标值.通过对比不模型的RMSE和MA的值,来评估各个模型的整体的预测效果.通过表4不同模型参数的对比,组合模型的平均预测值达到了96.84%的水平,相比于ARIAM预测提高了3.28%,相比于XGBoost的预测提高了1.99%,相比于LSTM模型提高了2.28%,综上所述,组合模型在商品销售的预测中展现了优于其他单一模型的预测效果,通过加权组合提高了模型的泛化性和有效性.

表4 不同模型预测结果对比
研究主要策略量对于模型的影响,在本文的实验中,结合了主要规格的策略实订量这一特征值,而在实验前通过观察不难发现,这一主要策略量跟销售序列有着较为紧密的联系,首先策略量序列总是小于对应的销售值,其次,通过数据可视化可以发现,当销售增大时,策略量也增大,销售量减少时,策略量也明显的减少,在此基础上检验策略量的实订量的有无对预测的影响,通过设计对比实验来验证.实验结果如表5所示,在加入了策略量后,对比于未加入策略量实订量的实验结果相比,预测的准确率提高了4.05%,RMSE降低了0.64,说明在其他条件不变的情况下,策略量对于销售预测的影响较为显著,可以通过加入该特征来辅助预测.

表5 策略量对预测结果的影响对比
4 结论与展望
本文提出的基于XGBoost和LSTM加权多变量的加权组合预测模型,用来解决商品销售的预测,通过加入天气,主策略量实订量,节假日,日期(年月日)诸多因素来辅助预测,提高预测的准确率,提高模型的有效性,ARIMA在处理线性模型效果较好,LSTM神经网络可以通过学习来拟合非线性问题,XGBoost模型则可以挖掘多维变量中不同维度的属性,通过不同层面的模型的组合,大大的提高了模型的泛化能力,不仅针对商品销售的预测,还可以应用于其他相关的多变量时间序列的预测领域,提高预测的精度,解决不同的实际问题.但在对于该模型中的神经网络来说,过多的属性存在过拟合的风险,因此模型还可以在该方面优化.
