One-Hot编码在学生选课数据分析中的应用研究
2019-10-15◆张戈
◆张 戈
One-Hot编码在学生选课数据分析中的应用研究
◆张 戈
(中国社会科学院大学 北京 102488)
学生选课系统是当前所有高校都会用到的应用系统,学生在选课时系统会获取大量的选课数据,通过对这些数据的分析,我们可以获取很多有意义有价值的信息,可以更有效地帮助教师提高教学质量。本研究根据学生选课数据,基于机器学习的回归模型建立了数据分析功能模块,重点对原始数据的不合理、不可用进行了论证分析,提出并详细设计了使用One-Hot编码解决这一问题的数据预处理方案,取得了良好的实验效果。
One-Hot;数据异常;数据预处理;岭回归
学生选课系统是当前高校都会用到的应用系统,除了用它进行选课活动之外,系统逐年地积累了大量的选课数据,对于这些数据,我们可以从中获取很多更有意义更有价值的信息,比如可以分析出不同专业的学生更喜欢哪些课程、他们对各类课程的需求、对哪些老师的课程比较偏爱,甚至可以预测下一届的学生选课方向等等。本研究收集了以往历届学生的选课数据,按我们的研究目标方向,对数据进行了筛选,并在此基础上分类出训练集和测试集,建立起回归模型,旨在分析出各个专业的学生对不同类型课程的偏好,预测下一次该专业的选课方向,并为学生提供课程推荐建议。
1 问题的提出
在选课系统中,选课数据量庞大而复杂,它包含“学生信息”、“课程信息”、“教师信息”、“院系信息”、“教学楼信息”,每个信息中又包含很多小类。我们的模块功能目标是分析出各个专业的学生更偏重哪类或哪些课程,并对下一次的选课方向进行预测。因此,我们更关心那些可以帮助我们进行分析和预测的数据,包括“学生院系”、“学生专业”、“学生所选课程编号”等。在机器学习工具中我们采用岭回归模型进行分析和预测,但是这些原始数据是无法直接使用的,即使对文本数据转换成数值数据,也存在诸多问题,依据此类数据训练出的模型分析和预测的准确度非常低。因此研究的重点是分析数据存在哪些问题,并给出解决方案。
(1)文本数据不可用。比如“学生院系”、“学生专业”,这些数据是以中文字符呈现的。在机器学习中,训练集的数据是数值型,因此我们首先需要将文本数据转换成数值数据,才能被机器识别,并进行训练。
(2)如何转换数据。在将文本数据转换成数值数据时,如何用数值表征一个特征向量的值呢。比如用1还是2来表示选课同学的院系和专业呢?目前比较通用的做法是按院系编号,比如“中文系”用数字1、“经管系”用数字2来表示。结果如图1。

可以看到“院系”的数据取值范围在1到6之间,各个专业的取值范围在1到9之间,对于“选课课程编号”,它的取值范围就更大了,一所大学通常会有上百们的课程,取值范围在1到300之间。这样会衍生出两个问题,特征向量值差异过大引起的小数值特征向量被大数值特征向量“吞吃”的结果。另外,在“院系”和“专业”两个特征向量中,数据范围从1到6或从1到9,会造成模型中距离公式计算结果不合理的情况。
综上所述,我们需要设计一套解决上述问题的方案,才能让回归模型得分更高,分析和预测结果更准确。
2 岭回归模型的应用
针对以上问题,本研究在分析了各种回归模型的适用范围和模型特点之后,采用岭回归模型来解决我们遇到“特征向量值差异过大”问题。在分析了数据特点之后,我们采用One-Hot编码解决“距离计算不合理”问题。
2.1 分析数据
前面分析了数据存在的特征向量值差异过大引起的小数值特征向量被大数值特征向量“吞吃”的问题。比如“学生所选课程编码”的取值范围是1到300,而“专业”特征的取值范围是1到9,那么在机器学习模型中,计算各特征点距离时,取值范围小的特征(专业)其对结果的影响远比取值范围大(学生所选课程编号)的特征要小的多,所以这就会造成计算精度的损失,模型分析和预测准确度远远不够。因此,我们在模型上采用岭回归模型,它可以将每个特征向量的系数变小,在一定程度上减小所有特征的影响力以达到统一化特征向量的目标。
2.2 岭回归模型
岭回归(ridge regression,)是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法[1]。它可以有效防止模型的过拟合现象。在岭回归中,模型的各个特征变量没有发生改变,它不像套索回归去自动选择去除不重要的特征向量。但是岭回归会减小每个特征变量的系数值,通过这种方法来防止模型的过拟合现象,这种方法被称为L2正则化。L2 正则化公式直接在原来的损失函数基础上加上权重参数的平方和:

其中,E是训练样本误差,是正则化参数。正则化的目的是限制特征向量过多,避免模型更加复杂[2]。
由此看来使用岭回归模型可以解决我们遇到的“特征向量值差异过大”问题。
3 One-Hot编码的应用
3.1 One-Hot编码
在机器学习中,我们经常会遇到像“性别”、“政治面貌”这样的特征,它们的取值范围分别是【‘男’,’女’】和【‘党员’,’团员’,’群众’】。假设有“张三”这个人他的特征为“男、党员”,“李四”这个人的特征为“女、群众”,如果使用通常转化方法,那么“张三”的特征值为【0,0】,“李四”的特征值为【1,2】。在模型中使用计算特征参数距离时,就会产生不合理的情况。以特征“政治面貌”为例,“党员”是0,“团员”是1,“群众”是2,那么各个特征参数之间的距离d为:d(“党员”,“团员”)=1,d(“团员”,“群众”)=1,d(“党员”,“群众”)=2,这样就会得到一个结论,“党员”和“团员”的近似度等于“团员”和“群众”的近似度,但是“党员”和“群众”之间就不那么近似了。但实际上三个参数相互之间的近似程度是一样的。这样一来,模型的训练集数据就是不合理的,那训练出来的模型又怎么会准确呢?
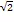
3.2 预处理实现
在实验中,我们采用python3语言编写代码,使用Jupiter notebook编程环境,调用sklearn库中的预处理工具实现One-Hot编码的数据预处理,python代码及运行结果如图2所示。

图2 One-Hot编码预处理数据代码及结果
从图中可以看到,我们使用One-Hot编码预处理了训练集数据,并依此训练模型,得到了新数据点【3,4,48】(法学系,法学专业,课程编号为48)对应的One-Hot编码。同时获得了岭回归模型的拟合函数方程。
4 总结
本研究在对原始选课系统数据进行剖析之后,决定采用One-Hot编码对数据进行预处理。首先实现了将文本类型数据转换为机器学习可用的数字类型数据。同时,使用One-Hot编码解决了训练集数据距离计算不合理的问题,使训练集的得分达到0.88的好成绩。针对数据特征值差异过大的问题,本研究经过分析采用了岭回归模型进行数据拟合,结果证明岭回归模型可以在一定程度上缓解特征差异,但是该问题没有得到根本解决。在今后的工作中本研究会继续探讨如何采用数据归一化和标准化的方法根治特征差异过大问题,使系统可以得到最理想的预测结果。
[1]肖玲玲,郑华,林烁烁,陈晓文.基于岭回归的四带图像偏色校正算法[J].计算机系统应用,2019,28(08):129-135.
[2]红色石头的专栏.https://blog.csdn.net/red_stone1/article/details/80755144
[3]Yuchen Qiao,Xu Yang,Enhong Wu. The research of BP Neural Network based on One-Hot Encoding and Principle Component Analysis in determining the therapeuticeffect of diabetes mellitus[J]. IOP Conference Series: Earth and Environmental Science,2019,267(4).
[4]Jia Li,Yujuan Si,Tao Xu,Saibiao Jiang,Volodymyr Ponomaryov. Deep Convolutional Neural Network Based ECG Classification System Using Information Fusion and One-Hot Encoding Techniques[J]. Mathematical Problems in Engineering,2018,2018.
[5] Chandan Gautam,Aruna Tiwari,M. Tanveer. KOC+: Kernel ridge regression based one-class classification using privileged information[J]. Information Sciences,2019,504.
中国社会科学院大学校级科研项目。
