中国水土流失研究热点区的空间分布制图
2019-10-14胡云锋韩月琪张云芝
胡云锋, 韩月琪, 曹 巍, 张云芝
1 中国科学院地理科学与资源研究所,资源与环境信息系统国家重点实验室,北京 100101 2 中国科学院大学,资源与环境学院,北京 100049
中国是全世界水土流失最为严重的国家之一。严重的水土流失是引发区域生态系统退化、水域环境质量恶化、经济社会严重受损的重要过程[1]。据第一次全国水利普查水土保持情况公报显示,我国土壤侵蚀总面积294.91万km2,占普查范围总面积的31.12%;其中,水力侵蚀129.32万 km2,风力侵蚀165.59万km2[2]。研究人员针对水土流失的空间分布格局、水土流失强度、水土流失的防范治理和生态恢复等问题展开了广泛和深入的研究,积累了丰富的研究成果,具体包括专题报告、图册、研究论文、专利技术、应用系统等在内的多种知识展现形式。其中,公开出版的期刊研究论文是理解和掌握水土流失研究方向、研究地点、研究内容、研究方法和主要结论的最重要的信息载体。进入信息化时代,这些研究论文被进一步数字化,形成了结构化或者半结构化的文献数据库或者知识库(如中国知网、万方数据库、WoS(Web of Science)等),并可以方便地为读者通过国际互联网进行检索和下载。
随着上述数据库和网络搜索技术的广泛普及和深入使用,传统的、依赖于人工阅读纸质文献的信息检索和知识提取方法逐渐演变为基于网络爬虫、数据挖掘、机器学习、数据建模等技术,对文本信息进行检索、专题信息抽取及时空分析的阶段[3]。已经有许多研究人员针对互联网文本开展地理信息的抽取和分析工作。如Sadilek等人通过有明确位置标记的推特(Twitter)数据对个体疾病情况进行分析,探测了疾病传播过程[4];Dredze等对推特文本中隐性的地理信息进行抽取,开发了可对流感发病情况进行追踪的Carmen系统[5]。Cameron等人开发了ESA-AWTM系统,用于监测社交网络中隐含的社会公共危机事件信息[6]。在国内,也有一些研究从微博消息或者互联网文本中检测地名信息,进而开展一些简单的面向事件的空间制图研究[7-9]。此外,还有一些基于已发表论文成果、应用统计方法开展再分析、再确认“元分析”研究[10-11]。总的来看,目前的研究大多是应用社交媒体数据或者一般性的互联网文本数据,针对特定事件或突发事件开展空间制图和过程重绘的研究。基于海量的科技期刊论文,从论文中提取地理空间信息和论文研究主题信息,进而对特定自然、生态过程的空间分布规律、时间演化特征以及知识图谱凝练研究[12-13],这一类的研究在国内外都还比较少见。在这一研究方向,重点需要解决地名信息的自动化提取和空间匹配、基于位置的自然地理和生态环境问题建模与分析、以及针对上述时空分析结果的知识凝练和应用实践。
本文以水土流失为研究对象,基于中国知网学术期刊数据库,通过网络爬取、中文分词、地名识别、空间关联等技术方法,对1980—2017年间的中国水土流失研究论文中的摘要文本进行了行政区地名提取和研究热点建模分析。进一步,基于同期历史气象观测数据和自然地理背景数据,应用经典的RUSLE模型对中国水土流失进行模拟和分析。作者最后针对水土研究热点地区制图成果与水土流失强度模拟制图成果的空间耦合关系开展了讨论。希望解决如下科学和技术问题:
(1)建立一套从中文科技期刊论文提取行政区地名信息的方法,构建一个科学合理的研究热度模型以及空间制图流程;
(2)分析1980年代以来中国水土流失研究热点地区的空间分布格局,阐明研究热点地区随时代演变的动态过程;
(3)对比分析水土流失研究热点地区空间分布与土壤侵蚀强度空间分布地图,对典型的空间耦合模式或空间差异进行机制解释。
1 数据来源及预处理
研究中用于提取研究地区、分析研究热度的文本数据来自于中国知网学术期刊数据库(China Academic Journal Network Publishing Database,CAJD)。作者首先应用Java语言开发了CAJD爬虫系统;而后以“水土流失”、“水力侵蚀”以及“水蚀”作为关键词,对CAJD文献库进行了全面检索,共获得1980—2017年间相关文献170301篇;最后,提取了文献标题、摘要、关键词、作者姓名等关键信息,并存储于本地的SQLite数据库中。
为了将文献数据中的行政区地名正确匹配和关联到空间数据库中,首先依据中国地图出版社提供的中国县级行政区划数据(2012年版)建立标准地名。而后,考虑到行政区划名称的历史演变,依据国家基础地理信息中心提供的1∶25万基础地理数据、科技部地球系统科学数据共享平台提供的中国历史时期县级行政区划数据,对部分地名进行了别名补充。
为应用RUSLE模型开展土壤侵蚀强度模拟,研究中还使用了如下长时序气象数据和相关的自然环境背景数据。具体包括:(1)基于日降雨量拟合模型[14]及ANUSPLIN插值方法[15]计算得到的降雨侵蚀力空间数据集。其中,日降雨量等数据来自于中国气象科学数据共享服务网(http://cdc.cma.gov.cn);(2)基于Nomo图法[16]计算得到土壤可蚀性因子数据。其中,土壤数据为中国科学院南京土壤研究所提供的1∶100 万中国土壤数据库;(3)全国1 km分辨率数字高程模型(DEM)。由此计算得到坡长、坡度因子;(4)基于MODIS NDVI产品,应用像元二分模型计算得到全国植被盖度产品[17]。由植被盖度数据,可以进一步确定RUSLE模拟所需的土地管理因子[18];
为了分析导致研究水土流失研究热点空间分布格局与土壤侵蚀强度空间分布格局之间空间差异的机制,还使用了基于第五次人口普查数据的2010年中国公里网格人口分布数据[19],以及基于1∶25万基础地理数据库得到的中国县道及县道以上等级道路的路网密度数据。
2 研究方法
2.1 水土流失研究热点建模
对于从CAJD中检索和下载得到的170301篇文献,首先调用自然语言处理开源平台(HanLP)中的分词模块对文章题目、摘要及关键词等文本内容进行分词处理[20];接着应用实体词识别模块对全部分词结果进行分析、遴选得到其中的地名词汇[21];然后对上述地名词汇中的行政区地名进行标准化,并对全部行政区地名出现的频次进行统计分析。研究中,将标准行政区地名数据库中的地名划分为省域、市域、县域三级,并构建了一个基于“逐级覆盖、累加统计”原则的地名匹配算法,从而将不同级别的行政区地名、或者同一地名的不同表达形式(全称、简称、别称)进行准确识别、合理统计。
在定量评估研究热点时,简单地采用研究论文中的特定地名出现的绝对数量(Nwe)来表征水土流失研究的热烈程度,这并不合理。中国作为一个幅员辽阔的大国,各省区市之间的经济社会和科技发展水平并不相同,不同地区针对同一事物、过程的关注数量会存在较大的、甚至是数量级上的差异。类似的道理,采用某一地名在特定研究方向论文中出现频次占其在全部研究方向论文中出现频次的比例指标(Pwe)来表征研究热度,则会由于相同或者相似经济社会和科技发展水平的地区针对同一事物、过程具有大致相似的测度水平,因而同样无法有效刻画地区差异。为避免上述问题,本文作者将绝对数值指标与相对比率指标相结合,构建了如下的地区研究热度模型:
(1)
式中,Q是水土流失研究热度指数。Nwe为某一地名在水土流失主题论文中出现的频次;Pwe为某一地名在水土流失主题论文中出现的频次占该地区在全部主题论文中出现频次的比值;Nall为某一地区不限定主题所得全部论文的数量。
本文研究中,为了方便在全国范围内开展对比分析,作者还对公式(1)中的Q值进行了归一化,并将归一化计算所得结果用于后续的制图和结果分析。其中,研究热度分级方法采用自然分级法。
2.2 基于RUSLE模型的模拟
RUSLE 模型 (Revised Universal Soil Loss Equation),是对通用土壤流失模型USLE(Universal Soil Loss Equation)的改进和优化[22]。与USLE模型相比,RUSLE扩展了模型模拟所需的输入数据的丰富程度,纠正了USLE模型中存在的少量错误,增加了模型的灵活性。自20世纪80年代以来,研究人员使用RUSLE 模型对不同气候带、不同地形地貌、不同耕作管理措施、以及不同空间尺度下的区域水土流失进行了广泛、深入地模拟评估[23-25]。研究结果表明,RUSLE是一种适用于流域和区域尺度的、通用性很强的水土流失定量评价方法。RUSLE 模型基本方程是:
A=R×K×L×S×C×P
(2)
式中,A为土壤侵蚀模数,R为降雨侵蚀力因子、K为土壤可蚀性因子、L为坡长因子、S为坡度因子、C为覆盖和管理因子,P为水土保持措施因子。
3 结果与分析
3.1 研究热点区域
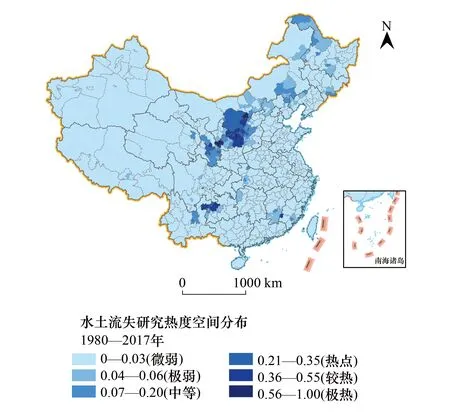
图1 1980—2017年全国水土流失研究热度空间分布图 Fig.1 The spatial distribution of water erosion research hotness during 1980—2017
1980—2017年期间,中国水土流失研究热点的空间分布如图1所示。水土流失研究热点区域主要分布在黄土高原及贵州高原,涉及陕西、宁夏、内蒙古、甘肃、贵州等省区。此外,在黑龙江大兴安岭北部、内蒙古东部的西辽河流域也有轻微的研究热度。
统计表明:中等及以上热度的县(区、市)共171个,面积达到50.55万km2,占全国国土总面积的5.33%。其中,研究热度达到“较热”及以上的区域主要分布在黄土高原和西南喀斯特地区,如:宁夏固原,陕西延安、榆林,内蒙古鄂尔多斯市,贵州毕节等地。研究热度为“中等”的区域主要分布在大兴安岭地区、黄土高原周边地区、西南喀斯特地区,具体为:内蒙古的呼伦贝尔、赤峰,甘肃的兰州、天水、陇南、庆阳,青海的西宁,云南的昆明等地区。
针对1980—2017年各个年代水土流失研究热度空间分布格局的时间变化过程(图2)研究表明:1980—1989年间,中国水土流失研究的热点集中分布在黄土高原区;1990—1999年间,黄土高原研究热度持续上升;与此同时,贵州西部、内蒙古东部也逐步成为研究热点;2000—2009年间,学者们关注的水土流失区域进一步扩大,内蒙古中部鄂尔多斯、乌兰察布,黑龙江大兴安岭北部的部分县(区、市),也逐步成为水土流失研究热点区域;进入2010年后,水土流失研究热点区域有所收缩,学者们的研究热点区重新回到黄土高原及云贵高原。
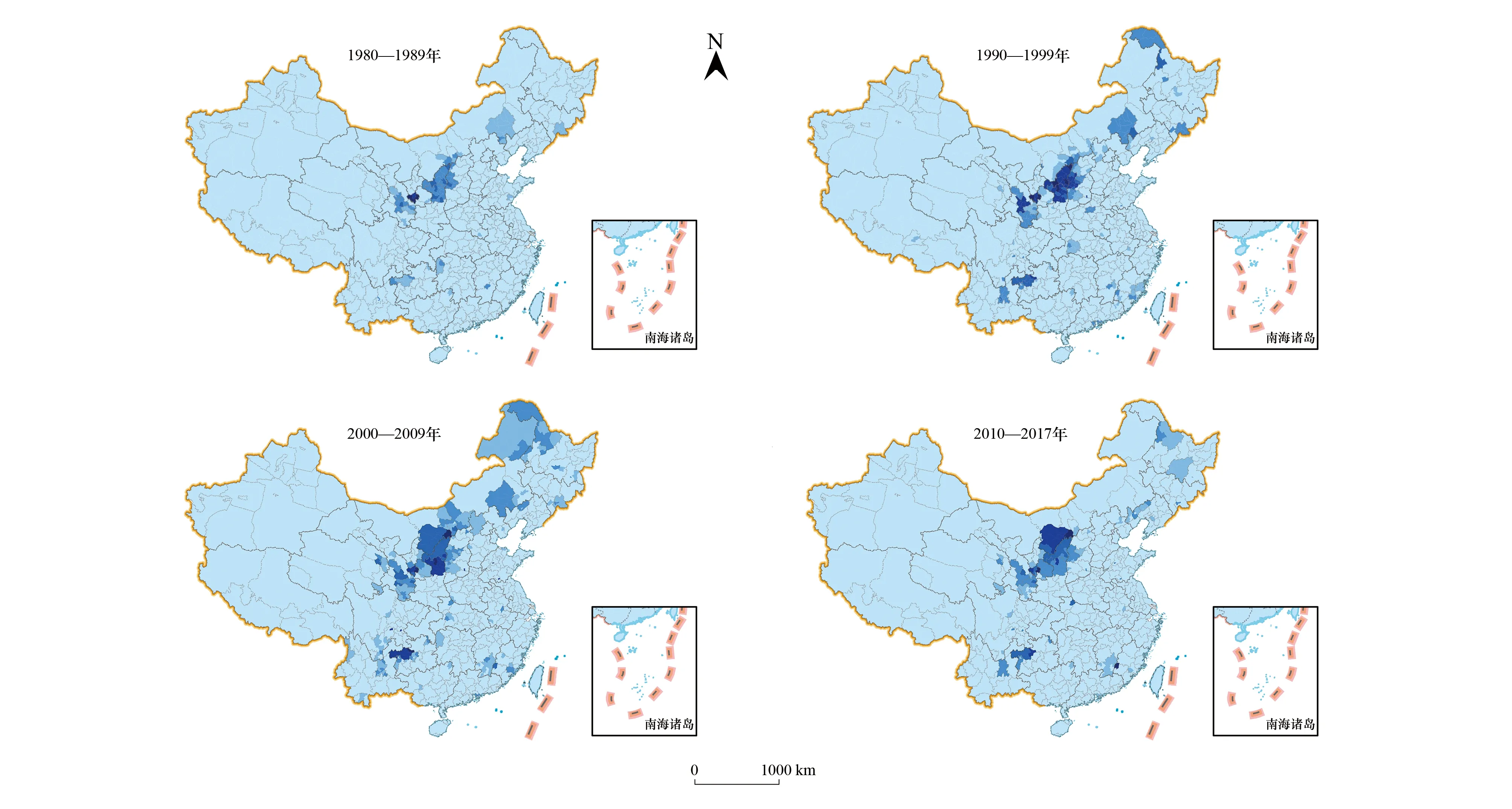
图2 不同时代的全国水土流失研究热度空间分布图Fig.2 The spatial distribution of water erosion research hotness in 4 Eras
3.2 土壤侵蚀强度

图3 基于RUSLE模拟的土壤侵蚀模数空间分布图 Fig.3 The Spatial Distribution of Water Erosion Modulus Simulated by RUSLE ModelRUSLE(Revised Universal Soil Loss Equation):通用土壤流失模型
基于2000—2015年多年气象数据、植被数据以及地形、土壤数据等,应用RUSLE模型,可以模拟得到我国土壤侵蚀强度的空间分布(图3)。模拟结果表明:严重的土壤侵蚀主要分布在黄土高原及云贵高原,涉及陕西、宁夏、甘肃、山西、贵州、云南、四川等省区;此外,辽宁、山东、重庆、湖南、江西等省区也有中、轻度的土壤侵蚀。
统计显示:全国土壤侵蚀模数大于20 t hm-2a-1的县(区、市)共251个,面积达66.78万km2,占全国国土总面积的7.04%。其中,土壤侵蚀量在30 t hm-2a-1以上的区域主要位于在黄土高原核心区的陕西榆林东南部、延安北部,甘肃庆阳北部,以及位于云贵高原西部的云南迪庆藏族自治州、怒江傈僳族自治州、大理白族自治州、保山的部分县(区、市)。在上述县(区、市)的外围地区,以及宁夏固原、中卫,甘肃平凉、定西,云南省临沧、普洱、红河哈尼族彝族自治州、楚雄彝族自治州,四川凉山彝族自治州、攀枝花以及西藏昌都地区南部,土壤侵蚀量也都超过了20 t hm-2a-1。
4 讨论
4.1 空间耦合的模式及应用
对比水土流失研究热点图(图2)与土壤侵蚀强度空间分布图(图3),两者存在4种空间耦合模式,即:高研究热度-高侵蚀强度(如黄土高原)、高研究热度-低侵蚀强度(如云贵高原)、低研究热度-高侵蚀强度(如滇西横断山区)、低研究热度-低侵蚀强度(如中国东部广大地区、青藏高原等)。对于上述典型空间耦合的形成机制,可以结合区域自然地理和经济社会发展背景等予以解释。
黄土高原是长期以来被公认为我国水土流失最为严重的区域。对该地区开展长期的水土流失观测实验、研究其治理和恢复措施,探讨区域经济-社会的可持续发展,这是政府主管部门和研究人员长期关注的重点问题[26-27]。黄土高原地区呈现的“高研究热度-高侵蚀强度”组合,体现了科研界对我国水土流失重点地区判断准确、研究重点突出的实际情况。但是,在云贵高原区与滇西横断山区,存在研究热度与侵蚀强度等级“脱钩”的情况。就云贵高原而言:一方面,云贵高原作为喀斯特岩溶地貌的典型区,由于水土流失导致的石漠化研究一直得到学界的重视[28-29];但另一方面,这一地区作为我国南方热带、亚热带气候区,自2000年以来,在国家相关生态治理工程(如天然林保护工程、退耕还林还草)治理下,该地区陆地植被容易恢复、植被盖度提升较快,土壤侵蚀状况已经大为好转[30]。因此,云贵高原地区所形成了“高研究热度-低侵蚀强度”的格局也可以得到合理解释的。在滇西横断山区,则呈现为 “低研究热度-高侵蚀强度”的空间耦合模式。究其原因,是因为滇西横断山区地处偏远,人口稀少,山脉与河谷依次贯列,人员也难以进入。因此,RUSLE模拟表明该区虽然存在较为严重水土流失,但由于水土流失对本地区经济社会的危害性较小,因此这一地区的水土流失过程并没有得到科研界的重视和深入研究。
在应用自然地理和经济社会发展因子对上述空间耦合模式的形成机制予以解释的同时,还可以针对不同的这种空间耦合模式评估研究项目投入、研究重点地区选择的合理性、有效性。科学史研究已经表明,科学研究中总是存在追逐热点的趋势。其结果是科学研究会在领域方向上、研究地域上出现“富者愈富”的情况[31]。具体到本研究中,水土流失研究热度与水力侵蚀强度等级“脱钩”的地区,极有可能表明出现了一些研究人员盲目追求热点、忽视重大问题区域的情况。因此政府和科研界需要采取必要的措施,将资金和人员优先投入到更加严重、更加关键的区域上。要做到这一点,一方面必须运用卫星遥感和模型模拟的方法,对水土流失强度及其空间分布有着更加准确、快速的量算;另一方面,也需要深化既有的互联网文献大数据绘制知识图谱的研究方法,开展更全面、更精准、更快速的地名识别(包括行政区地名和非行政区地名)、专题信息建模等关键研究。
4.2 数据和模型的不确定性
在本文研究中,作者从特定主题的科技期刊论文中提取了行政区地名信息,进而用地名构造了研究热度指标模型;继而以研究热度指标为基础,进一步分析了水土流失研究热点的空间分布格局和动态演变规律。总的来看,基于文献大数据的科研热点地区制图方法能够很好地展示科研工作者长期以来在水土保持研究领域研究的重点地带和重点区域;文献大数据科研热点地区空间分布格局的动态演变过程,也体现了在不同历史发展时期,水土流失研究在研究范围、研究强度上的变化规律。
但需要指出的是:目前的技术路线和技术实现过程中,依然存在一些值得改进的地方。首先,目前提取的地名信息均为行政区地名(省、市、县、区等)。对于论文中广泛存在的自然地理区域地名(如秦岭、太行山、淮河、塔里木河,等)、方位词(南部、以西、上游、北麓,等)等,作者目前尚不能准确地在空间上予以标注和定位。毫无疑问,这种地名信息的漏提和不精确标注,将会影响研究热点区域制图的精确性。其次,在研究热度建模中,本文作者虽然构建了一个综合了绝对数值指标和相对比例指标优点的热度指数模型。但毫无疑问,目前的热度模型仍然是粗糙、不精确和缺乏严格数理统计学基础的。从文献大数据提取专题信息,并根据地学专业研究的性质和特点,构建科学合理、严谨可靠的测度模型、分析模型,依然是未来基于文献大数据开展知识图谱研究的一个关键环节。
5 结论
本文主要基于CAJD提供的文献大数据,运用自然语言处理技术,对海量中文科技期刊论文所刻画的1980年代以来中国水土流失研究热点进行了信息提取和建模分析,并将相关结果与基于RUSLE模型的得到全国土壤侵蚀强度空间分布成果进行了对比和讨论。主要结论有:(1)应用网络爬虫、文本解析、地名识别、空间关联、热度建模等方法,可以快速、有效地从海量期刊文献数据中提取和标识全国水土流失研究的热点区域,完成中国水土流失研究热点区制图。(2)1980年以来,我国的水土流失研究热点地区主要分布在黄土高原、西南喀斯特地区,主要涉及宁夏南部、陕西北部、甘肃南部、内蒙古中部、贵州西部与云南东部等地,尤以宁夏固原、陕西延安、榆林的部分县(区、市)、内蒙古鄂尔多斯、贵州毕节等地最为突出。(3)研究热点地图与水土流失强度模型模拟地图之间存在差异。对于这些特定的空间耦合模式,不仅可以从自然地理和经济社会发展背景等方面予以解释,还可以用于评估科技资源投入的合理性和有效性。
