实现对教育课件关键信息的提取
2019-10-11谢志庆张晓天闫秋艳胡妍高淑娟
谢志庆 张晓天 闫秋艳 胡妍 高淑娟

摘 要:目前,雨课堂的使用产生了大量学生观看演示文稿的数据,如何更加高效地利用这些数据成了文章的研究起点。为此,需要按页提取演示文稿中的关键信息。文章通过分析演示文稿文件的设计特点,建立一个评价体系,对演示文稿中的文本内容依据文本特征(颜色、字号、字体、粗体、斜体)进行分析从而估计重要指数。结合重要指数的评分,选取最大的k个_Run对象提取关键词或是结合TF-IDF算法,根据词频提取关键词,以实现对教学课件按页提取关键信息。借助Python的pptx模块和jieba模块,实现教学课件关键词的提取。最后,以“数据库原理”课程为例,进行关键词的提取,以此进行有效性的检验。结果表明,文章所提出的基于演示文稿文本屬性的关键词提取算法准确率可以达到82.32%。
关键词:教学课件;关键词提取;文本特征;Python;雨课堂
1 问题的提出
随着多媒体技术的发展,传统课堂模式渐渐发生了改变,PPT教学应运而生。PPT以简单明了、重点突出的特点,已经成为教师课堂教学和学生课下学习必不可少的工具。从小学到中学,再到高等院校,都可以看到PPT的应用。
目前,雨课堂所能提供的只是简单的数据信息,比如观看时长。然而,这些数据并不能直观地展示学生的问题所在,如何按页识别教学课件中的关键信息成为本文的研究要点与亮点。
江婷等[1]依据演示文稿中文本框的位置,提取关键词。但是,演示文稿设计的灵活性意味着仅依靠文本框的相对位置提取关键词存在局限性。设计者并非按照固定的格式进行制作,这也是PPT文本挖掘的难点所在。
希望在未来可以通过提取教学课件的关键词,配合教学课件的阅读记录,精准定位学生在学习过程中的隐藏问题,加以因人而异的辅导,学生可以进行个性化学习,实现学业减负,质量提升。
本文借助Python第三方库pptx的使用,根据文本的属性信息,采用加权算法得到关键词。如果属性无差异,则使用词频—逆文本频率指数(Term Frequency-Inverse Document Frequency,TF-IDF)算法,实现对教学课件按页提取关键词。PPT文档结构如图1所示。
2 文档结构的分析
Office系列软件自2007版本之后采用了一种以可扩展标记语言(Extensible Markup Language,XML)为基础并以ZIP格式压缩的电子文档规范[2]—开放式办公室软件(Open Office XML,OOXML)格式存储文件[3],现已成为国际文档标准,于2006年12月成为欧洲计算机制造联合会标准。
OOXML是将演示文稿文件另存为后缀ZIP的文件,进行压缩。解压后,以演示文稿的名字为名的文件夹中包含4项内容,即3个文件夹:_rels,docProps,ppt和一个文件:[Content_Types].xml。
(1)_rels文件夹:存放rels.xml文件,是解析整个演示文稿文档的入口文件。
(2)docProps文件夹:存放App.xml,Core.xml和一个jpeg图片。其中,App.xml描述的是文档的属性,包括演示文档的各个属性,例如字体、版本等。
(3)PPT文件夹:包含若干个文件夹,_rels,media,slideLayouts,slides和theme等,存放演示文稿的主要信息。
(4)[Content_Types].xml文件:描述整个演示文稿文档内容的类型,将各个XML文件进行整合。
在XML文件中,块级元素的段落标志为a:p,次级元素标志为a:r,表示连续的一段文本,字体属性信息元素标志为a:rPr,一段采用字体样式等属性相同的连续文本则用更次一级的元素a:t将其内容包含进来[4],如图2所示。
3 对象模型
为了能够获取PPT文本及文本属性,需要建立相关的属性。本文依据参考复合文档提取文本信息的流程[5],建立了PPT文本提取的对象模型,如图3所示。
(1)Presentation对象是演示文稿文档的标志部件,代表一个PowerPoint演示文稿。
(2)Slides对象代表演示文稿的页面序列,即当前演示文档的全部页面。
(3)Slide对象代表当前访问的PPT页面。
(4)SlideShapes对象代表当前页面的所有形状shape对象的序列。
(5)Shape对象代表当前访问PPT页面的某一形状。
(6)TextFrame对象代表当前访问Shape对象的文本框,PPT中的文本信息储存在文本框中。
(7)_Paragraph对象代表当前文本框中的段落。
(8)_Run对象代表字体样式等属性相同的连续文本。
(9)Font对象代表文本中文字属性,包含字体大小、名称、粗体、斜体等属性信息。
基于以上所建立的演示文稿对象模型,可以看到,_Run对象是演示文稿信息提取的基本单元,Font对象反映_Run对象的文本属性信息。
4 算法设计与分析
4.1 设计思路
通过大规模地分析教学课件的结构特点,总结出了教学课件设计的两个主要特点:(1)重点突出:演示文稿作为课堂教学的主要形式,重点突出是其最大的特点。一般都会从颜色、字体、字号、粗体、斜体或者下划线等突出重点内容。(2)简明扼要:PPT的主要功能是为了演讲,以最直观、明了的形式表达演讲者的意图。在内容设计上,设计者会直截了当地表达自己的意图。
依据教学课件的特点,采用一种参考文本属性为_Run对象打分的方法,实现对教学课件关键词的提取。
4.2 关键词提取的主要算法
首先,本文通过Font对象衡量演示文稿_Run对象的差异性,若全部_Run对象的差异性相同,则采取基于字频的TF-IDF算法提取关键词;否则直接选取差异性最大的k个_Run对象提取关键词。
4.2.1 算法设计
为了计算颜色、字体、字号、粗体、斜体和下划线6个属性在每一张Slide上的重要性Zij,定义为:
(1)
式中,Xijk为第i页中第j个_Run对象的某一文字属性分量相同时,所有_Run对象的数量。显然,wijk是一个在0到1取值的数,为某一属性的权值。
显然,对于一张演示文档中某个_Run对象而言,其自身某个属性出现的频率越小,其权值越大,其包含的文本越有可能成为关键词。
那么,在第i个页面中,第j个_Run对象的重要性Zij为:
(2)
式中,n为PPT文字中属性的个数。mk(k=1,2,…n)为每个属性的影响系数,本文中取1,即每个属性的影响系数是相等的。
如果所有的Zij值都是一样的,则直接采用TF-IDF算法进行关键词提取。反之,对Zij(j=1,2,3……jmax)进行排序,选择最大的k个Zij。根据下标j寻找Tij,即该_Run对象的文本内容。
之后,将文本内容进行词语选择处理[6],对于重要性Zij得分较大的对象提取其文本,使用Python的jieba模块进行分词,分词后提取規则如下。
(1)去除停用词,即一些常见的形容词、动词、介词等。
(2)优先筛选名词、形容词。
(3)至少选取一个词。
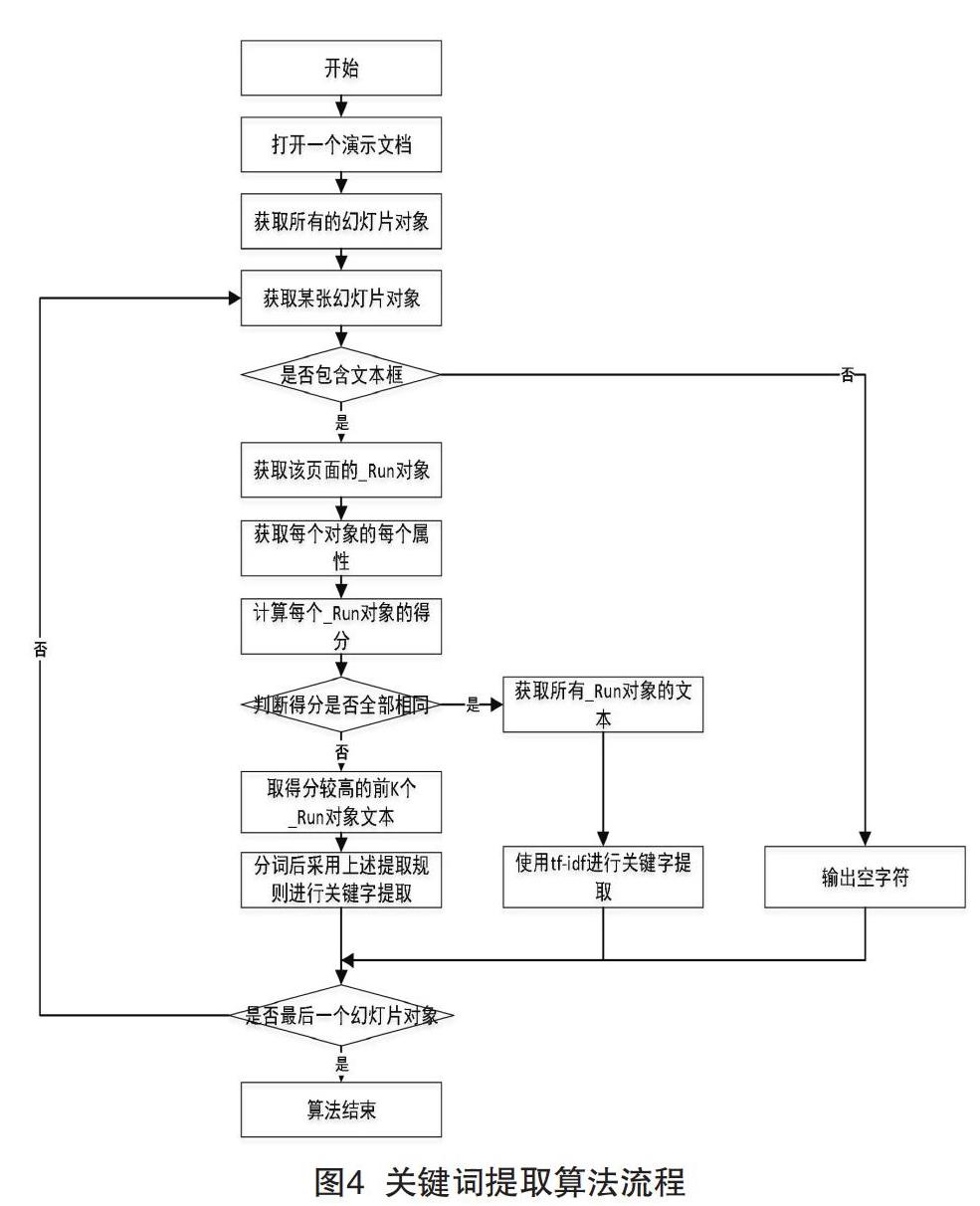
4.2.2 算法流程
本文关键词提取算法流程如图4所示。
(1)通过Presentation(path_to_file)方法获取演示文稿文件,将其转为Presentation对象。
(2)通过Presentation(path_to_file).slides()方法获取当前演示文稿的Slide对象序列。
(3)通过索引index1指示Slide对象的编号,对index1指示下的演示文稿进行分析。
①通过Presentation(path_to_file).slides()[index1].shapes获取索引index1指向页面的Shape对象序列。
②通过index2指示当前Slide对象中Shape对象的编号, 通过Presentation(path_to_file).slides()[index1].shapes[index2] 获取索引index2指向的Shape对象。通过has_text_frame()方法判断是否含有文本框,若不存在TextFrame对象则输出空字符,进行下一个页面的获取;否则进行下一步。
③通过Shape对象的text_frame()方法获取当前Shape对象的文本框对象TextFrame。
④通过TextFrame对象的paragraphs()方法获取当前TextFrame对象的所有段落对象_Paragraph。
⑤通过_Paragragh对象的runs()方法,获取当前_Paragragh对象的_Run对象。
⑥通过_Run对象中的text()方法得到文本框中文本信息;通过font()方法得到字符属性对象Font,得到字符属性信息。
(4)Index2指向下一个Shape对象,如果还有未被检查的文本框,则跳转到第2步,否则进行第5步。
(5)Index1指向下一个页面,如果还有页面,则跳转到第1步,否则进行第6步。
(6)根据公式(2),计算重要性Zij。
(7)将_Run对象依据差异性Zij倒序排序,若差异性一致,获取该页_Run对象的全部文本,使用TF-IDF算法提取关键词;否则选取差异性Zij前k大的_Run对象,使用text()方法得到该_Run对象对应的文本,进行词语选择处理,提取关键词。
5 系统实现
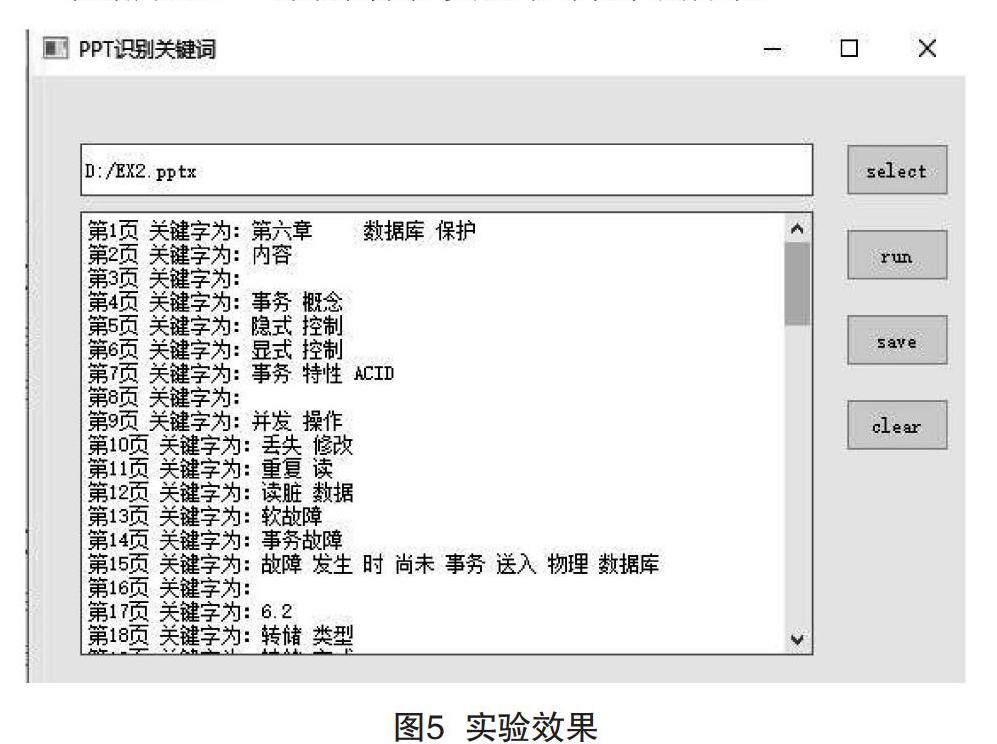
本文借助Python提供的pptx,jieba,collection模块,在windows10操作系统、Python3.6编译环境下进行实验。以“数据库原理”课程为例,实验效果如图5所示。
可以看出,若某一页不存在文本框时,输出信息为空。而对于没有任何重点标记的页面,采用TF-IDF算法提取关键词,效果一般。对于文字属性突出的页面,提取效果非常好。例如打开第7页演示文稿,如图6所示,可以看到,第7页的重点是事务特性。在图5中可以看到第7页对应的关键词是“事务”“特性”“ACID”,如图6所示。
本文实验教育课件数目:7个;总计实验页数:464张;经过此算法提取的关键词与人工标记比较,有效识别PPT页数:382页;成功率为82.32%。结果表明,本文的算法可以被采纳。
6 未来展望
本文依据文字属性按页提取教学课件中的关键信息,充分利用演示文稿的简洁明了、重点突出等优势。本算法从PPT设计者的角度去提取文本中的关键词,结合各个属性值,提取出来关键词的准确度与设计者的习惯有着较大的关系,如果设计者习惯标注演示文稿中的关键信息,则此算法有着很大的参考价值,这也是本文最大的创新点。若设计者无意突出重点,则此算法退化到普通的TF-IDF算法,丧失其优越性。此外,由于设计者的风格一般都是固定的,可以根据不同设计者的风格,不再选取相同的mk值,调整合适的mk值以达到更好的效果,是下一步的优化目标。
7 结语
演示文稿以其简单明了、重点突出的优势,已然成为现在课堂教学中重要的辅助工具。本文依靠Python的第三方库,实现了一个可以依据文字属性按页提取关键词的系统,可以帮助读者快速了解教学课件的重点信息。在未来,希望可以配合教学课件浏览记录,快速定位学生在学习过程中的隐藏问题,进而可以提供个性化的解决方案。在信息化时代的今天,希望可以借助科技的力量帮助教学更加智能、更加个性化。
[参考文献]
[1]江婷,赵呈领,谈国栋.PowerPoint课件文本信息提取研究[J].中国远程教育(综合版),2011(2):69-72.
[2]罗文华,王燕燕,刘晓丽.基于OOXML的演示文稿溯源及编辑过程恢复方法研究[J].中国司法鉴定,2017(5):52-57.
[3]ISO/IEC. Information technology-document description and processing languages-Office Open XML File Formats[Z].ISO/IEC259500,2008.
[4]张武.损坏或分片OOXML文档的文本内容恢复技术研究[D].杭州:杭州电子科技大学,2014.
[5]牛永洁,薛苏琴.基于PDFBox抽取学术论文信息的实现[J].计算机技术与发展,2014(12):61-63,68.
[6]刘永平.基于PPT文檔的信息隐藏技术研究[D].长沙:湖南大学,2009.
Realization of the key information of the education courseware:
taking the “Database Principle” course as an example
Xie Zhiqing, Zhang Xiaotian, Yan Qiuyan, Hu Yan, Gao Shujuan
(School of Computer Science and Technology, China University of Mining and Technology, Xuzhou 221116, China)
Abstract:At present, the use of rain classroom has produced a large number of students to watch the data of the presentation, and how to make more efficient use of these data becomes the starting point of this paper. It needs to extract key information from the presentation by page to do this. By analyzing the design features of the presentation file, the article sets up an evaluation system, and the text content in the presentation is analyzed according to the text features (color, font size, font, bold, italic) to estimate the important index. Combining the scores of the important indexes, selecting the largest k _ Run object to extract keywords or combining the TF-IDF algorithm, extracting the keywords according to the word frequency, In this paper, the key information is extracted by page for the teaching courseware. With the help of pptx module and jieba module of Python, the keyword extraction of teaching courseware is realized. Finally, taking the “Database Principle”course as an example, the keyword extraction is carried out to test the effectiveness. The results show that the accuracy of the keyword extraction algorithm based on presentation text attributes can reach 82.32%.
Key words:teaching courseware; keyword extraction; text features; Python; rain class
