基于时序Landsat遥感数据的新疆开孔河流域农作物类型识别
2019-10-10汪小钦邱鹏勋李娅丽茶明星
汪小钦,邱鹏勋,李娅丽,茶明星
基于时序Landsat遥感数据的新疆开孔河流域农作物类型识别
汪小钦,邱鹏勋,李娅丽,茶明星
(1. 福州大学空间数据挖掘与信息共享教育部重点实验室,福州 350108;2. 卫星空间信息技术综合应用国家地方联合工程研究中心,福州 350108; 3.数字中国研究院(福建),福州 350108)
快速、准确地获取农作物类别信息对农业部门的生产管理、政策制定具有重要作用。目前基于时间序列数据进行农作物分类主要是采用长时间序列的中低分辨率影像,大量的混合像元限制了农作物的分类精度。在农作物分类的特征选择方面主要是采用归一化植被指数(normalized differential vegetation index, NDVI),而其他特征量的应用还相对较少。该文以新疆开孔河农业区为研究区域,利用2016年的Landsat7 ETM+、Landsat8 OLI影像数据集,基于时间加权的动态时间规整(time weighted dynamic time warping,TWDTW)方法开展农作物类型识别研究,主要包括香梨、小麦、辣椒、棉花等。根据野外采集的样本点构建主要农作物的NDVI和第一主成分(principal component analysis 1,PCA1)时间序列,以反映不同农作物间的物候差异。基于NDVI数据分别利用DTW和TWDTW算法计算各未知像元序列与标准序列间的相似性程度,得到农作物的分类结果,2种方法的分类精度分别为65.69%、82.68%,表明时间权重的加入提高了DTW算法识别不同农作物的能力。结合NDVI与PCA1后,TWDTW的分类精度又提高了2.61个百分点,部分农作物的误分现象明显减少,说明PCA1能够进一步扩大作物间的差异性,提高分类精度。同时,还通过选取有限时相的影像组合进行分类,试验结果表明TWDTW算法在中高分辨率数据较少的情况下能够得到较为满意的分类结果,说明TWDTW算法在中高分辨率影像越来越丰富的时代具有应用潜力。
遥感;作物;分类;时间加权的动态时间规整(TWDTW);时间序列;归一化植被指数;主成分变换
0 引 言
农作物种植结构信息对农业部门的生产管理、政策制定具有重要意义[1]。及时、准确地获取农作物的种植结构信息不仅是农情遥感的重要内容,也是调整种植结构、预估农作物产量的主要依据[2-3]。遥感技术由于具有感测范围广、信息获取快、宏观性强等特点,广泛应用于农作物分类识别和作物面积估算的研究中[4]。
早期,研究者主要利用单一时相的高分辨率影像或者时间序列的中低分辨率影像进行农作物种植信息的提取[5-6]。基于单一影像的种植结构提取方法操作简单,但往往难以获取种植结构“最佳识别期”的遥感影像,存在“同物异谱、异物同谱”的现象,分类精度难以得到保障[7]。基于时间序列的中低分辨率影像在提取农作物的过程中,由于不同作物对适宜生长的气候条件要求不同,许多学者选用归一化植被指数(normalized differential vegetation index, NDVI)作为信息提取的常用指标来反映不同作物长势随季节变化的差异性,增大作物间的可分性,但受限于影像分辨率,大量的混合像元导致分类的精度难以提升[8-9]。目前利用时序数据进行农作物分类识别的主要方法包括支持向量机、决策树等传统的监督分类方法[10-11],但这些方法对于时间序列信息的利用都不够充分。杨闫君等[12]基于GF-1/WFV数据构建时间序列的NDVI数据,提出冬小麦识别矢量模型,矢量的大小和方向能够充分描述曲线的动态变化特征,进而达到准确识别冬小麦的目的。动态时间规整(Dynamic time warping, DTW)作为时间序列相似性度量算法中的一种,能够充分利用作物的物候特征对其进行分类,近年来已被广泛应用于农作物遥感信息提取中[13-15]。管续栋等[16]基于46期的时间序列Modis数据采用DTW方法对泰国水稻种植信息进行提取,能够降低该地区云雨天气以及水稻种植时间的灵活性对提取精度的影响,但是该算法对于匹配节点时间跨度的无限制性容易导致严重的畸形匹配现象,造成农作物的误分和漏分,而且对于水稻阈值的确定需要不断尝试,无法实现目标作物的自动化提取。Maus等[17]在DTW算法的基础上引入了时间权重因子,能够一定程度地限制序列节点间的畸形匹配,选取多种农作物的样本点,通过比较各作物间的距离值确定像元类型,不需要设定阈值,实现农作物的自动分类。
然而,当前在时间序列DTW方法的农作物识别方面,主要采用的是长时间序列的低分辨率数据源,而对于数据量越发丰富的中高分辨率的影像,DTW方法基于该数据的应用还少有涉及[18]。在特征量的选择上,主要采用的是NDVI,其他特征指标的的应用对于能否提高农作物识别精度还需进一步研究。本文采用时间序列的Landsat数据,以新疆开孔河农业区为例,利用时间加权的动态时间规整(timeweighted dynamic time warping, TWDTW)进行农作物分类识别,探索利用中高分辨率时间序列影像和DTW方法对不同农作物的识别能力,通过试验分析时间权重的引入以及NDVI与第一主成分(principal component analysis 1,PCA1)结合对农作物分类结果的影响,提出一种基于时间序列中高分辨率遥感影像的农作物识别方法,以提高农作物的识别精度。
1 研究区概况与数据源
1.1 研究区概况
研究区位于新疆巴音郭楞蒙古自治州(82°38′~93°45′E,35°38′~43°36′N)的开孔河农业区,如图1所示,包括焉耆盆地农业区和博斯腾湖西南部库尔勒、尉犁农业区。东临博斯腾湖,水资源相对于新疆其他地区较为丰富,南接塔克拉玛干沙漠。该地区日照时间长,光热资源丰富,昼夜温差大,适合各类瓜果生长以及农作物和经济作物的种植。流经该地区的主要河流为塔里木河和孔雀河,都为季节性河流。主要的农作物有棉花、辣椒、小麦等,其中,在库尔勒市和尉犁县种有大面积的棉花,库尔勒香梨也闻名全国[19],而且香梨种植面积呈现逐年递增的趋势,截止2017年种植面积已经超过6万hm2。焉耆盆地北部是新疆重要的辣椒生产基地,辣椒种植面积达到3.4万hm2。研究区内所有的农作物都为一年一季,其中小麦在2月底开始种植,7月份收获,是研究区内种植时间最早的农作物。棉花的种植时间为4月中旬,9月中旬收获,生长时间大概为5个月。辣椒的种植时间与棉花大致相同,收获期在9月底。
1.2 数据源
1.2.1 遥感数据
从美国地质勘探局(USGS)网站上下载研究区2016年作物生长季无云或少云的Landsat7、Landsat8(level1)影像,空间分辨率为30 m,其中Landsat7数据4景,Landsat8数据8景,共12景影像构成研究区2016年时间序列数据集,数据获取的具体情况如表1所示。由于Landsat7与Landsat8影像的幅宽大小不一,覆盖的区域也不完全相同,需要提取公共区域进行影像裁剪,生成大小为5 259 × 4 862像元的影像数据集。其他处理还包括辐射定标和大气校正,对于Landsat7影像,由于存在条带的现象,采用ENVI的扩展工具Tm_destipe对影像进行条带修复。

图1 研究区在新疆的地理位置及野外样本点分布示意图

表1 数据获取情况
数据预处理完成后,计算生成NDVI数据集。由于Landsat数据中的可见光、近红外波段具有高度的相关性,为了更好的保留光谱特征,降低数据维度,减少数据冗余,对红光、绿光、蓝光以及近红外这4个波段进行主成分变换[20-21],将第一主成分(PCA1)与时序NDVI数据作为不同农作物类型的分类特征。
1.2.1 样本数据
2018年7月对研究区内的农作物种植情况进行了实地调察,共收集到样本点127个,其中棉花24个,香梨8个,辣椒25个,小麦40个,芦苇9个以及非耕地样本点21个。通过与当地农户的沟通了解到研究区除小麦外,其他作物年际间的种植模式较稳定,基本保持不变,通过对比2018年和2016年研究区内的Google Earth影像和2 m的GF-1影像,根据采集样本点在影像上的色彩、纹理和点位分布等信息,确定未变化的点位,在此基础上再增加256个样本点,包括49个棉花样本点,65个香梨样本点,52个辣椒样本点,5个小麦样本点,65个芦苇样本点和非耕地样本点52个,总共383个样本点建立样本数据集。从样本集中随机选取每类样本的20%作为分类训练样本,剩余80%的样本用于结果精度验证。各类样本点分布情况如图1所示。
2 研究方法
2.1 时间加权的动态时间规整匹配算法
时间序列相似性匹配是指在给定标准序列的基础上匹配相似性程度最高的序列[22]。动态时间规整(DTW)算法是基于动态规划思想,寻找一条最小累计距离的路径,匹配的序列不要求匹配点一一对应,只需使匹配的两序列间的累积距离最小即可[23-24]。
设有两长度分别为和的时间序列为



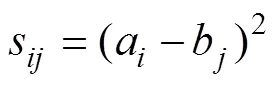

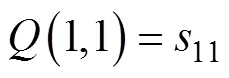
在寻找最小累积距离路径时,应满足:

时间加权的动态时间规整(TWDTW)算法[24]中序列间的基距离是在DTW基距离的基础上乘上匹配点之间的时间权重
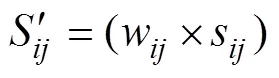

式中wij为权重值,g为增益因子,值越大则对匹配点间隔差异的惩罚越大,根据前人的研究成果[17,25-26],本文将g设为0.1,c=|i−j|为距离因子,mc一般为时间序列的中间节点,本文所使用的影像数据集的时间跨度约为250 d,因此将mc设为125。TWDTW可解决DTW中的畸形匹配现象,如图2所示为长度是40的两序列间的DTW算法节点匹配结果,从图2a可以看出对于波形相似但宽幅差异较大的两序列,DTW算法为了得到最小的累计距离,会出现匹配点时间跨度较大的情况,这在基于物候信息的农作物分类中将产生较大的误差。为了减少这些畸形匹配现象,加入时间权重进行约束,序列间匹配点的时间跨度越大则惩罚值越大,使得匹配时间跨度在较小的范围内(图2b)。时间权重的加入不仅保留了算法的灵活性,还使节点匹配更加整齐,提高了序列间匹配的相似性。
2.2 试验设计
除NDVI能够反映植被的生长变化以外,笔者发现不同作物在遥感影像上的亮度值也存在不同的变化规律,为了综合农作物在可见光和近红外波段的亮度信息,采用主成分分析的方法,在降低数据维度的同时尽可能保留影像的光谱信息,而PCA1是主成分变换后含信息量最多的分量。为了探讨时间权重因子和光谱特征的加入对试验结果的影响,本文设计了3组试验进行对比,分别是基于时间序列NDVI数据的DTW法(简写为DTW(NDVI))、TWDTW法(简写为TWDTW(NDVI)),以及结合NDVI与PCA1的TWDTW法(简写为TWDTW(NDVI+PCA1))。并在TWDTW(NDVI)方案下对影像数据的选择进行试验设计,进一步探讨部分月份影像缺失对试验结果的影响,分析TWDTW方法对时间序列数据密集程度的依赖性。NDVI与PCA1的组合策略是将PCA1的值进行归一化,使两数据的数值保持在同一量级范围,分别计算待分像元在两类数据集下与各农作物样本的最小累计距离,将两距离相加得到TWDTW距离,通过对比得到最终的分类结果。
具体流程如图3所示,构建2016年Landsat时序数据集以及采集样本点数据,对Landsat数据集进行指数计算和主成分变换,生成时序NDVI和PCA1数据,选取样本点数据提取时序影像的值,生成标准序列,采用以上3种方案进行匹配计算,得到分类结果,并进行精度评价和分析。

图3 试验设计流程图
2.3 精度验证
混淆矩阵法是目前评价分类精度最常用的方法[27],该方法采用总体精度(Overall accuracy,OA)(式(9))、生产者精度(Producer accuracy,PA)(式(10))、用户精度(User accuracy,UA)(式(11))和Kappa系数(式(12))等评价指标从不同的侧面来反映图像的分类精度。


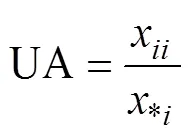

式(9)~(12)中,为验证样本的总数,x和x分别为分类结果中第类样本的总数和验证样本中第类样本的总数,x为混淆矩阵中的第行列中的数,代表第类样本中被正确分类的个数,为分类的类别数。总体精度表征分类的整体准确率,生产者精度和用户精度表征单一类别分类精度,Kappa系数则是评定生产者精度和用户精度的稳定性,可表征分类结果的可信度。
3 结果与分析
3.1 标准序列生成分析
受地域和气候因素的影响,相同作物在不同区域可能具有不同的物候特征[26]。如图4所示为基于样本点提取影像值生成标准NDVI时序曲线和PCA1时序曲线,由于铁门关地区的棉花(棉花2)比尉犁县棉花(棉花1)的种植时间早,从NDVI时序曲线中可以看出棉花2比棉花1的上升时间早,棉花2样本在6月1日的NDVI值为0.42,而棉花1还停留在0.18。棉花2的物候曲线与焉耆县的辣椒比较相似,采用TWDTW算法进行分类容易将两者误分。本文采用整体分类与局部专题提取相结合的方法,将铁门关地区的棉花单独作为一类,对它进行专题提取。在NDVI时序曲线中,由于小麦的种植时间最早,因此曲线的上升期比其他农作物出现的时间要早,在6月1日达到峰值,之后逐渐下降。香梨的生长季较长,NDVI曲线在4月22日之后一直保持在较高的水平,直到9月21日后曲线开始下降。
在PCA1时序曲线中每类农作物在节点值的整体离散度虽然比NDVI小,但是每类农作物的曲线特征也存在一定的区别,其中芦苇的PCA1曲线相比于其他作物一直处于较低的水平,棉花较高,香梨和辣椒处于中间,区分度较小,小麦在7月份已经收割完成,PCA1的值在7月22日升高,影像的亮度值增加。

图4 典型农作物NDVI与PCA1时序变化曲线
3.2 不同方法分类精度对比分析
通过上述分类过程,得到研究区内3种方案的农作物识别分类结果(图5)。将除训练样本外剩余的306个样本点作为验证样本点,分别对3种方案的分类结果进行精度验证(表2)。从表中可以看出基于时序NDVI与PC1特征量相结合的TWDTW分类方法精度最高,仅利用时序NDVI单一特征量的TWDTW方法次之,未考虑时间权重因子的DTW方法的分类精度最低。总体精度分别为85.29%、82.68%、65.69%,Kappa系数为0.823、0.791、0.585。从精度结果中可以说明DTW匹配算法引入时间权重因子后,对分类精度具有很大幅度的提高;加入PCA1特征后也比单一的NDVI特征具有更好的精度。

表2 分类精度
注:PA为生产者精度;UA为用户精度
Note: PA is Producer’s accuracy; UA is User’s accuracy
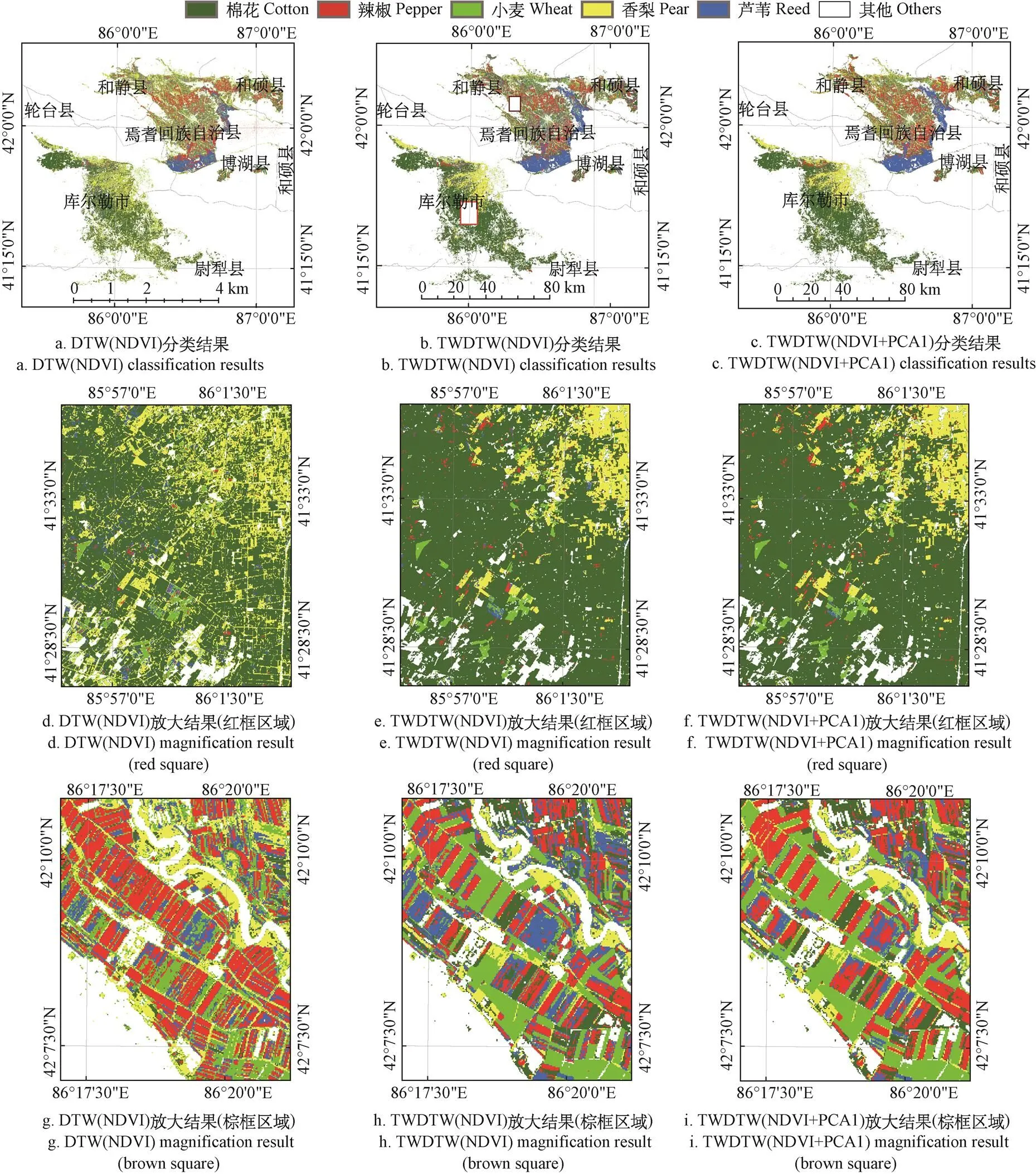
图5 不同方法的分类结果
基于NDVI特征量的TWDTW方法相比于DTW方法,除辣椒提取生产者精度提高较小外,其他类别的精度都大幅提高。其中小麦的生产者精度和用户精度提高最多,分别提高了37.03和32.41个百分点;香梨精度的上升幅度次之。除辣椒和小麦外,其他作物的生产者精度和用户精度都达到80%以上。结合PCA1与NDVI相比于只采用NDVI单一特征量的分类结果,加入PCA1后,辣椒的生产者精度和用户精度分别提高了8.06和9.27个百分点,在所有作物中精度上升幅度最大。香梨与小麦的分类精度基本不变,说明这两类作物对PCA1特征量的敏感度并不高。
为了更好地对比3种方案的分类结果,对局部区域进行放大,图5d-f为红色方框的局部放大图,图5g-i为棕色方框的局部放大图。从图5d中可以发现基于DTW算法的分类结果“椒盐”噪声明显,而且许多棉花样本被误分为香梨,图5e基于TWDTW算法的分类结果好于图5d,“椒盐”噪声有所改善,能够较好地对作物进行分类,加入PCA1后的对结果并没有太大影响(5f)。图5g-h与5d-e具有相似的结果,但图5h中有许多耕地被分为芦苇,这明显与实际情况不相符,图5i中通过加入PCA1特征,之前的芦苇地大部分转变成辣椒,结合野外收集到的样本点,证明了该转变的正确性。两图中小麦的分类结果基本不变,说明只采用NDVI特征能够较好地区分小麦与其他作物,而加入PCA1后,对小麦的分类结果的影响并不大。
3.3 不同影像组合分类精度对比分析
为了探索不同时期的影像缺失对分类精度的影响,本文基于TWDTW方法采用不同时相NDVI的影像组合方式对研究区内的农作物进行分类,分类精度如表3所示。由于小麦的种植时间在2月底,播种出苗后很长一段时间处在幼苗阶段,生长缓慢,去除2月26日和3月29日的影像进行试验,发现分类精度与全部影像参与分类的结果一致(表3试验2)。4月6日后,香梨和小麦开始生长,各曲线开始分化,在11月8日后大部分农作物都已收割完毕,NDVI值都处于较低水平,但是香梨地和部分棉花地的NDVI值要相对较高,在前面的试验的基础上再去除这两个时相的影像后,分类精度略有下降(表3试验4),但不明显,在后续所有试验的影像组合中该4景影像都不参与分类。对于生长季中的其他时相影像的缺失对分类精度的影响情况,逐一进行试验(表3试验5-12),发现5月16日与6月1日的影像缺失对分类精度的影响最大,精度从81.37%降至79.08%,从图4中也可看出农作物的NDVI值在这两时相差异最大。7月26日以后,除了小麦已经收割完以外,其他农作物都处于旺盛的生育期,NDVI值高,区分度较小,所以单景影像的缺失影响并不大,除9月21日影像缺失(试验12)导致分类精度在试验4的基础上下降0.35个百分点外,其余精度保持不变。
从上述试验中发现在影像分布较为均衡的情况下,单景影像的缺失对于分类整体精度的影响并不大。而较多影像的缺失对分类精度是否产生较大影响,通过选取研究区农作物生长季前期、中期和后期4个时相的影像进行试验(表3试验13-15),3组试验的分类精度分别为71.56%、76.47%和72.22%,精度下降明显,其中生长季中期的4景影像取得了最高的精度(试验14),说明研究区内农作物在4 -7月差异性最大,是农作物识别的关键时期。

表3 不同影像组合分类精度
注:√指参与分类的影像。
Note: √refers to images that need to be involved in classification.
4 讨 论
4.1 时间权重对分类结果的影响
时间节点和特征值是时间序列数据中最主要的两大特征,在序列相似性匹配计算中,DTW算法只专注于特征值在相似度距离中的计算,对所有的匹配点只计算它们的基距离,认为距离值越小则相似度越高,而忽略了匹配点的时间跨度对结果影响。时间权重这个物理量不仅考虑了节点特征值的大小,兼而考虑匹配点的连接情况,对于跨时间匹配的点实施惩罚机制,在保证特征值参与计算的基础上,同时考虑时间特征对相似性度量的影响。
在遥感专题信息提取方面,由于每种农作物都有其独特的物候特征,该特征是区别各种农作物的重要条件。本文基于时序NDVI数据,通过设置DTW和TWDTW 2 组对比试验探讨时间权重的加入对分类结果的影响。从表2中可以看出,时间权重的加入对该算法的分类精度具有显著的提升,分类总体精度也从65.69%上升到82.68%。根据野外考察的实际情况与农作物样本点的分布得知,除库尔勒东北部种有香梨外,库尔勒其余地区和尉犁县都是棉花的成片种植区,香梨与棉花的种植界限清晰,而从图6的DTW分类结果中发现有大量的棉花误分为香梨。从棉花的验证样本中选取被误分为香梨的样本点,在DTW算法下分别对比样本点与棉花序列、香梨序列的节点匹配情况和最佳匹配路径,如图6c所示,DTW算法通过跨时间匹配的方式得到样本点与香梨的DTW距离为4.56´10-2,两匹配节点时间跨度最大的为96 d,样本与棉花的DTW距离为6.57´10-2,与香梨的相似度大于棉花。虽然香梨与棉花的生长季存在较大差异,但是在没有时间权重约束的情况下,DTW的特质同样可以使两序列在节点值相近的情况下产生较高的相似度,造成农作物的误分。在引入时间权重后,该样本点与棉花、香梨的DTW距离分别为0.201´10-7、2.174´10-7,与棉花的相似度大于香梨,跨时间匹配的现象得到限制,该样本点被正确分类,其他作物的分类精度也得到了显著提高。

图6 节点匹配情况与最佳匹配路径
4.2 PCA1对分类结果的影响
各农作物随季节的变化不仅在NDVI时序曲线上表现出不同的生长特征,在PCA1时序曲线上也存在一定的差别。为了扩大作物间的区分度,本文在NDVI特征量的基础上加入了PCA1,采用TWDTW算法进行分类,将两时序数据计算的距离值相加得到最终的TWDTW距离,试验结果表明辣椒、棉花和芦苇的分类精度都有所提高,基于PCA1计算距离值的加入使得之前分类模糊度较大的像元被正确分类,总体分类精度从82.68%上升到85.29%,精度提高了2.61个百分点。笔者还试图加入PCA2特征量进行分类,但由于PCA2存在较大的噪声,且PCA2中各农作物的类内同质性较差,对分类精度并没有产生积极的作用。为了更好地提取不同作物,后续将继续研究引入其他更能反映作物差异的指数,进一步提高农作物种植信息的提取精度。
5 结 论
本文以覆盖研究区所有农作物生育期的Landst7 ETM+和Landsat8 OLI影像为数据源,对所有数据进行NDVI计算和主成分变换,生成时间序列的NDVI和PCA1数据集,采用动态时间规整(dynamic time warping, DTW)和时间加权的动态时间规整(time weighted dynamic time warping,TWDTW)方法对研究区内的农作物进行识别分类,结果表明:
1)基于NDVI时序数据,采用DTW和TWDTW方法对研究区内农作物分类的精度分别为65.69%和82.68%,引入了时间权重因子后,农作物的分类精度得到大幅提高。通过分析两算法在计算过程中节点的匹配情况发现,时间权重能够较好地限制DTW算法中存在的畸形匹配现象,增大不同类别间的距离值,提高作物分类精度。
2)在所有影像中选取部分影像组合进行分类,结果表明在农作物生长季开始初期和结束时所获取的影像在参与分类的过程中对分类精度的提高并没有太大的帮助。农作物生长季影像的大量缺失虽然会对分类的精度产生较大的影响,但是TWDTW算法只利用有限的影像也能取得较好的分类精度。
3)在时序NDVI数据的基础上加入PCA1特征量,采用TWDTW算法进行农作物分类,总体精度从82.68%上升到85.29%,被误分为芦苇的像元明显减少,说明时序PCA1对部分农作物的识别有所帮助。在今后的研究中还可探索其他特征量的加入对分类结果的影响。
[1] 许青云,杨贵军,龙慧灵. 基于MODISNDVI多年时序数据的农作物种植识别[J]. 农业工程学报,2014,30(11): 134-144. Xu Qingyun, Yang Guijun, Long Huiling. Crop information identification based on MODIS NDVI time-series data[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2014, 30(11): 134-144. (in Chinese with English abstract)
[2] Qiu Bingwen, Li Weijiao, Tang Zhenghong, et al. Mapping paddy rice areas based on vegetation phenology and surface moisture conditions[J]. Ecological Indicators, 2015, 56(1): 79-86.
[3] 杨闫君,占玉林,田庆久. 基于GF_1_WFVNDVI时间序列数据的作物分类[J]. 农业工程学报,2015, 31(24): 155-161. Yang Yanjun, Zhan Yulin, Tian Qingjiu. Crop classification based on GF-1/WFV NDVI time series[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2015, 31(24): 155-161. (in Chinese with English abstract)
[4] 高晓岚,汪小钦. 多源遥感数据在植被识别和提取中的应用[J]. 资源科学,2008, 30(1): 153-158. Gao Xiaolan, Wang Xiaoqin. An application of multi-source remote sensing data in identification and extraction of vegetation information[J]. Resources Science, 2008, 30(1): 153-158. (in Chinese with English abstract)
[5] Ajay Mathur. Crop classification by support vector machine with intelligently selected training data for an operational application[J]. International Journal of Remote Sensing, 2008, 29(8): 2227-2240.
[6] Yang Chenghai. Evaluating high resolution SPOT 5 satellite imagery for crop identification[J]. Computers And Electronics in Agriculture, 2011, 75(1): 347-354.
[7] 胡琼,吴文斌,茜宋. 农作物种植结构遥感提取研究进展[J]. 中国农业科学,2015, 48(10): 1900-1914. Hu Qiong, Wu Wenbin, Qian Song. Recent progresses in research of crop patterns mapping by using Remote Sensing[J]. Scientia Agricultura Sinica, 2015, 48(10): 1900-1914. (in Chinese with English abstract)
[8] 平跃鹏,臧淑英. 基于MODIS时间序列及物候特征的农作物分类[J]. 自然资源学报,2016, 31(3): 503-514. Ping Yuepeng, Zang Shuying. Crop identification based on MODIS NDVI time-series dataand phenological characteristics[J]. Journal of Natural Resources, 2016, 31(3): 503-514. (in Chinese with English abstract)
[9] 郭昱杉,刘庆生,刘高焕,等. 基于MODIS时序NDVI主要农作物种植信息提取研究[J]. 自然资源学报,2017, 32(10): 1808-1818. Guo Yushan, Liu Qingsheng, Liu Gaohuan, et al. Extraction of main crops in Yellow River Delta based on MODIS NDVI time series[J]. Journal of Natural Resources, 2017, 32(10): 1808-1818. (in Chinese with English abstract)
[10] Kong Fanjie, Li Xiaobing, Wang Hong, et al. Land cover classification based on fused data from GF-1 and MODIS NDVI time series[J]. Remote Sensing, 2016, 8(9): 741-761.
[11] 张焕雪,曹新,李强子,等. 基于多时相环境星NDVI时间序列的农作物分类研究[J]. 遥感技术与应用,2015, 30(2): 304-311. Zhang Huanxue, Cao Xin, Li Qiangzi, et al. Research on crop identification using multi-temporal ndvi hj images[J]. Remote Sensing Technology and Application, 2015, 30(2): 304-311. (in Chinese with English abstract)
[12] 杨闫君,占玉林,田庆久,等. 利用时序数据构建冬小麦识别矢量分析模型[J]. 遥感信息,2016, 31(5): 53-59. Yang Yanjun, Zhan Yulin, Tian Qingjiu, et al. Crop classification based on GF-1/WFV NDVI time series[J]. Remote Sensing Information, 2016, 31(5): 53-59. (in Chinese with English abstract)
[13] Sakoe Hiroaki, Chiba Seibi. Dynamic programming algorithm optimization for spoken word recognition [J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1978, 26(1): 43-50.
[14] Keogh Eamonn. Exact indexing of dynamic time warping[J]. Knowledge and Information Systems, 2005, 7(3): 386-758.
[15] Hamooni Hossein. Phoneme sequence recognition via DTW-based classification[J]. Knowl Inf Syst, 2016, 48(2): 253-275.
[16] 管续栋,黄翀,刘高焕. 基于DTW距离的时序相似性方法提取水稻遥感信息_以泰国为例[J]. 资源科学,2014, 36(2): 267-272. Guan Xudong, Huang Chong, Liu Gaohuan. Extraction of paddy rice area using a DTW distance based similarity measure[J]. Resources Science, 2014, 36(2): 267-272. (in Chinese with English abstract)
[17] Maus Victor, cˆamara Gilberto, Appel Marius. Dtwsat: time-weighted dynamic time warping for satellite image time series analysis in R[J]. Journal of Statistical Software, 2017, 80(1): 1-30.
[18] Guan Xudong, Huang Chong, Liu Gaohuan. Mapping rice cropping systems in vietnam using an NDVI-based time-series similarity measurement based on DTW distance[J]. Remote Sensing, 2016, 8(19): 3390-3415.
[19] 杨辽. 基于多光谱数据的库尔勒香梨种植面积提取研究[D]. 乌鲁木齐: 新疆大学,2015. Yang Liao. Based on Muitispectral Data of Kuerle Fragrant Pear Planting Area Extraction Research[D]. Urumqi: Xinjiang University, 2015. (in Chinese with English abstract)
[20] 叶燕清,杨克巍,姜江,等. 基于加权动态时间弯曲的多元时间序列相似性匹配方法[J]. 模式识别与人工智能,2017, 30(4): 314-327. Ye Yanqing, Yang Kewei, Jiang Jiang, et al. Multivariate time series similarity matching method based on weighted dynamic time warping algorithm[J]. Pattern Recognition and Artificial Intelligence, 2017, 30(4): 314-327. (in Chinese with English abstract)
[21] 宋盼盼,鑫杜,吴良才. 基于光谱时间序列拟合的中国南方水稻遥感识别方法研究[J]. 地球信息科学学报,2017,19(1): 117-124. Song Panpan, Xin Du, Wu Liangcai. Research on the method of rice remote sensing identification based on spectral time-series fitting in southern China[J]. Journal of Geo-information Science, 2017, 19(1): 117-124. (in Chinese with English abstract)
[22] Araya Sofanit, Ostendorf Bertram, Lyle Gregory, et al. Cropphenology: An R package for extracting crop phenology from time series remotely sensed vegetation index imagery[J]. Ecological Informatics, 2018, 46(5): 45-56.
[23] 沈静逸. 基于DTW和LMNN的多维时间序列相似性分析方法[D]. 杭州: 浙江大学,2017. Shen Jingyi. A Novel Similarity Measure Model for Multivariate Time Series Based on LMNN and DTW[D]. Hangzhou: Zhejiang University, 2017. (in Chinese with English abstract)
[24] 张浩,刘志镜. 加权DTW距离的自动步态识别[J]. 中国图象图形学报,2010, 15(5): 830-836. Zhang Hao, Liu Zhijing. Automated gait recognition using weighted DTW distance[J]. Journal of Image And Graphics, 2010, 15(5): 830-836. (in Chinese with English abstract)
[25] 翟涌光,屈忠义. 基于非线性降维时序遥感影像的作物分类[J]. 农业工程学报,2018, 19(34): 177-183. Zhai Yongguang, Qu Zhongyi. Crop classification based on nonlinear dimensionality reduction using time series remote sensing images[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 19(34): 177-183. (in Chinese with English abstract)
[26] Belgiu Mariana. Sentinel-2 cropland mapping using pixel-based and object-based timeweighted dynamic time warping analysis[J]. Remote Sensing of Environment, 2018, 204(1): 509-523.
[27] Russell G. Congalton, Kass Green. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices, Second Edition (Mapping Science)[M]. Florida: Lewis Publishers, 1999.
Crops identification in Kaikong River Basin of Xinjiang based on time series Landsat remote sensing images
Wang Xiaoqin, Qiu Pengxun, Li Yali, Cha Mingxing
(1.350108,2.350108,; 3.350108,)
The crops information of area and planting distribution has a great influence on the production management and policy making of the agricultural sector. Obtaining this information timely and accurately is not only the main content of agricultural remote sensing, but also the important reference for adjusting planting and estimating crop yield.At present, crop classification based on time series data mainly adopts medium and low spatial resolution images with long time series, while there are a large number of mixed pixels in low and medium spatial resolution images, which limits the classification accuracy of crops. The Normalized vegetation Index (NDVI) is mainly used in the selection of features of crop classification, while the application of other features selection is relatively few. With the rapid development of remote sensing technology, medium and high spatial resolution remote sensing data is becoming more and more abundant.How to make full use of medium and high spatial resolution images for crop classification has great research significance. This paper uses the Landsat7 ETM+ and Landsat8 OLI time series datasets of 2016 to extract crops from Kaikong River agricultural area of Xinjiang based on time-weighted dynamic time warping.It mainly includes pear, wheat, pepper, cotton and so on. According to the sample points collected in the field investigation, the sample database was established, and the NDVI values and PCA1 values of all kinds of samples were extracted at different time phases, that the standard NDVI sequences and PCA1 sequences were generated. In this paper, three classification schemes were designed and compared to explore the effect of DTW method on the recognition ability of different crops by using medium and high spatial resolution time series images, and to evaluate the time weight factor and the influence of NDVI combined with the first principal component (PCA1) on the classification results of crops. The principle of DTW algorithm classification was to calculate the distance value between the pixel sequence to be divided and the standard sequence of each crop. The smaller the distance value is, the higher the similarity between the sequences is. The crop type of the pixel to be divided was determined by comparing the distance value. However, because of its flexibility, the algorithm is prone to abnormal matching, and the introduction of time weight can limit this phenomenon very well. In this paper, DTW and TWDTW algorithms were used to classify crops based on NDVI data, and the classification accuracy of the two methods were 65.69% and 82.68%, respectively. It showed that the addition of time weight factor could effectively avoid the abnormal matching phenomenon of DTW algorithm and improve the ability of the algorithm to identify different crops. With the combination of NDVI and PCA1, the classification accuracy of TWDTW had increased by 2.61 percentage points, and the phenomenon of the misclassification had significantly reduced. It explained that PCA1 could further expand the difference between crops and improve the classification accuracy. The experimental results showed that the TWDTW algorithm could obtain a satisfactory classification result in the case of less high spatial resolution data. It proved that the TWDTW algorithm has great application potential in the time of more and more high- spatial resolution images, and provides a reference for fine identification of crops based on time series data.
remote sensing; crops; classification; time weighted dynamic time warping; time series; normalized vegetation index; principal component analysis
2018-12-27
2019-07-16
国家重点研发计划课题(No. 2017YFB0504203);中央引导地方发展专项(No. 2017L3012)
汪小钦,博士,研究员,主要从事资源环境遥感应用方面的研究。Email:wangxq@fzu.edu.cn
10.11975/j.issn.1002-6819.2019.16.020
S127
A
1002-6819(2019)-16-0180-09
汪小钦,邱鹏勋,李娅丽,茶明星.基于时序Landsat遥感数据的新疆开孔河流域农作物类型识别[J]. 农业工程学报,2019,35(16):180-188. doi:10.11975/j.issn.1002-6819.2019.16.020 http://www.tcsae.org
Wang Xiaoqin, Qiu Pengxun, Li Yali, Cha Mingxing.Crops identification in Kaikong River Basin of Xinjiang based on time series Landsat remote sensing images[J].Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(16): 180-188. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2019.16.020 http://www.tcsae.org
