POI用户模型的重构与优化
2019-10-08吉豪杰宋欣潮
吉豪杰 宋欣潮
摘 要: Apache POI中的用户模型是目前用于处理Excel数据的最为广泛的应用技术,但用户模型存在许多明显的弊端。本文将以一个学生档案管理系统为例,对用户模型中存在的问题以及产生问题的原因进行分析,并针对这些问题,借用面向过程的设计思想对用户模型进行优化和改进。使用不同规模的数据量对改进前后的用户模型进行测试,并对测试结果进行比较和分析,最终在一定程度上解决了用户模型的弊端,提升了用户模型的性能。
关键词: 用户模型;生产者消费者模型;POI技术;数据优化;内存溢出;设计模式;java多线程
中图分类号: TP315 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.05.038
本文著录格式:吉豪杰,宋欣潮. POI用户模型的重构与优化[J]. 软件,2019,40(5):193199
【Abstract】: The UserModel in Apache POI is the most widely used technology for processing Excel data at present, but the user model has many obvious disadvantages.This paper will take a student file management system as an example to analyze the problems existing in the UserModel and the causes of the problems. In view of these problems, the UserModel will be optimized and improved by using the process-oriented design idea.The data volumes of different scales were used to test the UserModel before and after the improvement, and the test results were compared and analyzed. Finally, the disadvantages of the UserModel were solved to some extent, and the performance of the UserModel was improved.
【Key words】: UserModel; Producer consumer model; POI; Data optimization; Out of memoryerror; Design mode; Java multithreading
0 引言
在当前的软件开发中,越来越多的需求涉及到对MicroSoft Office文档的处理,其中对Excel数据文档的处理尤为普遍。因此,关于对Excel文件处理的讨论与研究也愈演愈烈。到目前为止,已经出现了许多关于处理Excel文件的技术和开源项目,例如Java Excel Api(jxl),Apache POI[1],Alibaba EasyExcel等。这些开源项目各有特色,都能够适用于不同的开发场景,满足了大多数不同的开发需求,但也存在诸多问题,其中对Apache POI相关技术所存在问题的研究是本文讨论的重点。本文的创新点在于将面向过程的生产者消费者模型[2]的设计思想应用到传统的用户模型当中,以及采用多线程[3-9]的方式实现用户模型,对传统的用户模型处理Excel数据的程序进行重构,使用户模型在程序结构上逻辑更加清晰、功能更加明确,在数据处理能力上更加高效。
1 POI用户模型
1.1 用户模型简介
POI是由Apache组织提供的用java编写的免费开源的跨平台的 Java API,Apache POI提供API给Java程序对MicroSoft office格式档案读和写的功 能[1]。POI中关于Excel数据处理的部分主要包括User API、Event API和Streaming UserModel API。本文将重点讨论User API中的UserModel。
所謂的UserModel实际上就是基于Dom方式的解析,Dom解析就是将文件全部读入内存,对文件内部的结构进行建模,形成一颗Dom树的过程,如图1用户模型的Dom树结构。
从图1中可以看出,用户模型提供封装好的Workbook、Sheet、Row、Cell等实例来完成对excel数据的读写。
1.2 用户模型的应用
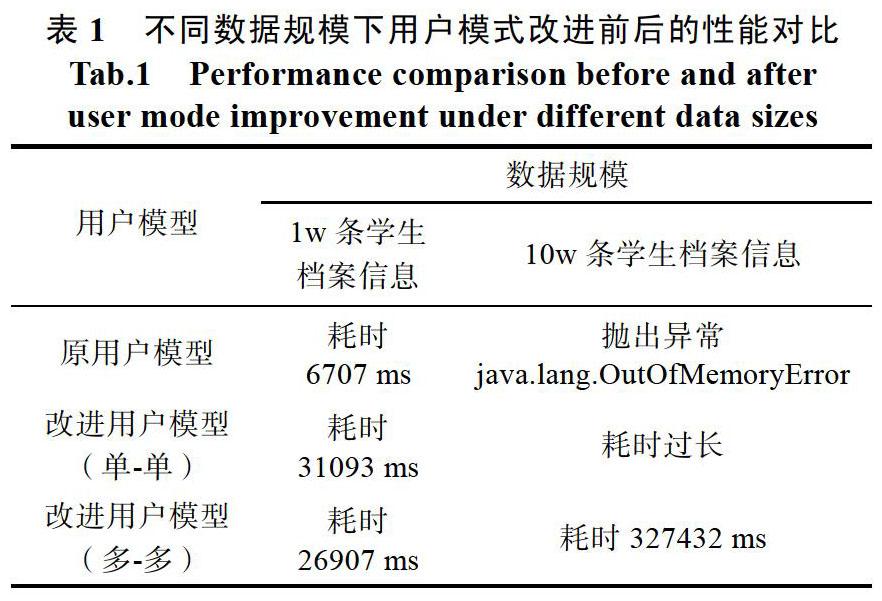
经过对用户模型的简单介绍,现在以文献[4]中提到的学生档案管理系统为例,对用户模型的Excel数据解析功能进行实现。该功能的业务处理过程为:①以流的方式接受excel文件;②根据接受的文件生成WorkBook对象;③根据Dom结构,遍历每个Sheet的每一个Row,将每一个Row中的Cell的值读取出来,存放到list集合中;④对list中的数据进行类型转换,并封装到领域对象Student中,生成存放Student对象的集合;⑤利用数据库的批量添加操作,将Student集合持久化到数据库中(涉及到多表操作)。
用户模型代码:
Student类:
public class Student {
private BigInteger stuId;//学号
private Archive archive;//档案
private Profession pro;//专业
private Department department;//院系
private String stuName;//姓名
private String stuSex;//性别
private String stuSendnum;//派遣证号
private String stuClass;//班级
private String stuLocation;//生源地
//省略部分属性和set、get方法
}
用户模型解析excel方法:
public static List
List
Workbook wb=getWorkBook(in,fileName); //获取WorkBook对象
if (wb!=null){
Sheet sheet=null;
Row row=null;
Cell cell=null;
list=new ArrayList
for (int i=0;i sheet=wb.getSheetAt(i); if (sheet==null){continue;} //遍历每一行 for (int j=sheet.getFirstRowNum(); j<=sheet.getLastRowNum();j++){ row=sheet.getRow(j); Integer columns= (int)row. getLastCellNum(); //遍歷每一列 List for (int m=0;m cell=row.getCell(m); if (cell!=null) { rowData.add (getCellValue(cell));//数据类型转换 }else{ rowData.add(""); } } //将每一行的数据放到list中 list.add(rowData); } } } return list; } 业务逻辑方法: public boolean uploadExcel(InputStream in, MultipartFile file) { //获取数据源 List //数据源封装成业务对象Student,存放到studentList中 //调用dao层的数据库操作方法,批量添加Student对象 //添加成功返回true,否则返回false } 1.3 用户模型的缺陷及原因分析 采用用户模型的方式读写Excel文件,由于这种方式容易理解,操作也较简单,所以成为了开发人员最常用的方式。但是这种方式也存在很明显的弊端:因为该方式是基于Dom内存解析的,所以对系统内存的依赖也就比较严重。也就是说,WorkBook对象是将整个文件流缓冲到系统内存当中,使用用户模型处理数据就要求系统有足够的内存空间去容纳以WorkBook对象为根的Dom结构。 在1.2的代码中可以看出,系统不仅会为WorkBook对象分配内存,而且还会为封转的Student对象集合分配大量空间。当数据量逐渐增大,对系统内存和cpu的开销也随之增大,直到系统没有足够的内存去处理数据时,就会造成内存溢出,导致数据处理失败。 以学生档案管理系统为例,对用户模型的系统资源使用情况进行分析。如图2数据量为1w时系统内存使用情况。 从图2中有上下两条曲线,上方曲线表示堆空间的最大值,下方曲线表示当前程序已经占用的空间。当有1万条excel数据时,系统会在一定时间内对这些数据分配内存并处理,占用内存大小大约60M,处理完数据后,立即释放空间。对于1万数据所占用的内存,系统完全有能力分配,所以不会造成内存溢出的情况。 如图3数据量为10w时系统内存使用情况。 由图3可知,当数据量增加到10万时,系统内存占用空间从100M迅速增加到700M以上并且呈缓慢上升的趋势。系统的堆空间也逐渐扩容到最大值,无法继续扩大,系统的可用内存资源迅速减少,直到系统没有足够的内存空间时,抛出内存溢出异常,此时10w条数据添加到数据库失败。 内存占用空间迅速增加是因为生成了基于Dom结构的WorkBook对象,呈缓慢上升趋势是因为系统在不断生成Student对象。 正是因为WorkBook对象和不断生成的Student对象,才造成了系统内存溢出。 虽然目前已经有很多方法可以替代用户模型去完成大数据量的Excel数据解析功能,比如POI中的基于事件驱动的事件模型和基于流式解析的流用户模型、基于xml的excel数据解析方式[7]等,但是对于用户模型本身的缺陷还未能够解决。解决用户模型的内存溢出问题,主要从两方面入手:一是减少WorkBook对象占用的内存空间,另一个是优化不断生成的Student对象的存储结构,本文将重点从后者入手来解决内存溢出问题。 2 生产者消费者模型 2.1 介绍 生产者消费者模型[2]是面向过程编程中的一种高效设计模式[8],该模型包括三种角色:生产者、消费者、数据仓库。其中生产者负责获取数据、数据类型转换等数据准备过程,消费者负责处理生产者准备好的数据,该模型通过一个数据仓库来实现生产者与消费者的解耦,降低生产者与消费者之间的依赖关系,并且支持并发、忙闲不均等情况的处理。如图4生产者消费者模型的工作原理。 2.2 应用 通常,处理Excel数据的过程为:①通过文件流来获取数据源,②根据具体的业务逻辑对数据源中的数据进行封装,③对封装好的数据进行相应的业务处理。这样的数据处理过程与生产者消费者模型的工作原理非常相似,过程①和②可以通过生产者来完成,数据存储可以通过数据仓库来完成,过程③可以用消费者来实现。 数据仓库通过维持一个恒定大小的缓冲区域来保证系统的内存消耗,可以有效解决内存溢出问题。由于生产者消费者模型支持并发,所以可以利用多线程的方式来高效率实现数据解析过程,充分利用cpu资源,达到提升系统性能的目的。通过对生产者消费者模型的利用,让数据解析过程的逻辑更加清晰,各部分分工明确,便于后期的系统维护和更改。 3 重构用户模型 3.1 利用生产者消费者模型改进用户模型 通过1.2对用户模型的实现和1.3用户模型的缺陷中可知,用户模型虽然易于理解,抽象层次高,但对系统性能的开销非常大,并且1.2中的业务逻辑方法既要获取数據又要执行数据库操作,不符合高内聚低耦合的程序设计原则。为解决用户模型对系统资源的依赖,且使得代码充分解耦,利用生产者消费者对用户模型进行改进: 首先将业务逻辑的处理分为数据准备、数据存储、数据持久化三个过程; 生产者负责数据准备过程,主要完成获取数据,数据封装操作;数据仓库负责临时存储数据;消费者负责数据持久化过程; 生产者和消费者以多线程的方式对数据进行并发处理。 对用户模型的改进,这里主要使用两种方式来实现:一种是单生产者-单消费者方式,一种是多生产者-多消费者方式。其中单生产者-单消费者方式在数据准备过程中,对于所有的数据都通过一个生产者来负责,虽然通过数据仓库可以保证系统中产生的Student对象不会占用过多的内存空间,但这样的执行效率显然不高。所以使用多生产者方式来实现,即多个生产者并行生产数据,比如10w条数据,若使用10个生产者,那么每个生产者平均负责生产1W条数据,忽略线程等待的时间,10w条数据生产完的时间相当于10个生产者都生产完1w条数据的时间。也就是说,将原来一个生产者生产10w条数据的任务交个10个生产者去完成,这样的执行效率会有显著提升。如图5改进后的用户模型业务处理流程。 实现代码如下: 数据仓库: public class DataWarehouse { private static int MAX_SIZE=5;//仓库大小 public static boolean isFinish=false;//生产过程是否结束 private BlockingQueue //生产者生产数据 public synchronized void addDatas(List while(dw.size()>=MAX_SIZE){ try { this.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } dw.add(datas); this.notifyAll();//唤醒所有等待的线程,主要唤醒消费者,防止死锁 } //消费者消费数据 public synchronized List consumeDatas(){ while(dw.size()<=0){ if(isFinish){//表示生产过程结束,且缓冲区为空,此时结束消费过程 this.notifyAll(); return null; } try { this.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } List this.notifyAll();//唤醒所有在等待的线程,主要唤醒生产者 return list; } public BlockingQueue return dw; } } 生产者(单生产者方式): public class Producter extends Thread{ private DataWarehouse dataWarehouse;//数据仓库 private InputStream inputStream;//输入流 private String fileName;//文件名 private TransDataUtil transDataUtil;//数据封装类,将excel数据封装成业务对象 public void run() { //遍历数据源,获取数据单元,数据单元的大小不宜过大也不宜过小,过大会占用内存空间,过小会增加与数据库交互的次数和频率,根据实验和研究,这里将单元大小设置成1000 if(list.size()>=1000){ dataWarehouse.addDatas(new ArrayList<>(list));//通过数据仓库生产数据 list.clear(); } DataWarehouse.isFinish=true;//表示生产数据结束 } } 生产者(多生产者方式): public class Producter extends Thread{ private DataWarehouse dataWarehouse; private Sheet sheet; private int start;//開始行 private int size;//数据源大小 private TransDataUtil transDataUtil; public void run() { Row row=null; Cell cell=null; List for (int i=this.start;i row=sheet.getRow(i); Integer columns= (int)row.getLastCellNum(); List for (int m=0;m cell=row.getCell(m); if (cell!=null) { rowData.add(ExcelUtil. getCellValue(cell)); }else{ rowData.add(""); } } //将rowData转化成对象Student放到list中 Student t=transDataUtil.transData(rowData); list.add(t); if(list.size()>=1000){//设置一个数据单元大小为1000 dataWarehouse.addDatas(new ArrayList<>(list)); list.clear(); } } if (list.size()>0) { dataWarehouse.addDatas(list); } list=null; DataWarehouse.isFinish=true; } } 消费者: public class Consumer extends Thread{ private DataWarehouse dataWarehouse; private StudentService studentService;//业务逻辑类,负责业务逻辑的处理 public void run() { while(true){ List if (studentList==null) { break; }else if (studentList.size()>0) { studentService.addStudentBatch(studentList); studentList=null; System.gc(); } } } } 業务逻辑方法:(单生产者-单消费者): public boolean uploadExcelByPC(InputStream in, MultipartFile file){ DataWarehouse.isFinish=false; producter.setFileName(file.getOriginalFilename()); producter.setInputStream(in); new Thread(producter,"producter").start(); new Thread(consumer,"consumer").start(); return true; } 业务逻辑方法:(多生产者-多消费者): public boolean uploadExcelByPC(InputStream in, MultipartFile file){ DataWarehouse.isFinish=false; List try { Workbook wb = ExcelUtil.getWorkBook(in, file.getOriginalFilename()); if (wb!=null) { Sheet sheet = null; Row row = null; Cell cell = null; for (int i=0;i sheet=wb.getSheetAt(i); if (sheet==null){ continue;} producter.setSheet(sheet); int size=sheet.getLastRowNum(); int pSize=5000;//表示一个生产者负责生产5000条数据 int start=0; int index=0; while(size>=pSize && size>0){ producter.setSize(pSize); producter.setStart(start); start+=pSize; size-=pSize; threadList.add(new Thread(producter,"producter-"+index)); index++; } if (size>0){ producter2.setSize(size); producter2.setStart(start); threadList.add(new Thread(producter,"producter-"+index)); } } } for (Thread t:threadList) {t.start();} new Thread(consumer,"consumer1").start(); new Thread(consumer,"consumer2").start(); } catch (Exception e) { e.printStackTrace(); } return true; } 3.2 性能分析 执行3.1中的实现代码,并监控jvm的内存使用情况,如下图为改进后的用户模型处理不同数据量时系统内存的使用情况。 从图7中可以看出,系统将文件流缓冲到WorkBook对象中后,系统占用内存从150M左右增加到700M以上,之后便维持在700M左右呈峰式不断变化,这是因为数据仓库的作用,对系统中封装的Student对象的内存占用情况进行了良好的控制,又因为多生产者与多消费者的并发操作,系统中不断产生的Student对象使用后被及时回收,系统吞吐量也有了显著提升。相比于图3中呈缓慢上升式的曲线而言,改进后的用户模型更能适用于一定数据量的处理任务。 如表1不同数据规模下用户模式改进前后的性能对比。 从上表中可以看出,生产者消费者模式对用户模型性能的影响,改进后的用户模型不仅保持了原来的高度抽象、易于理解和实现的优点,还解决了内存溢出的问题,在一定程度上对用户模型进行了优化,扩展了用户模型的应用场景。 但是使用用户模型,系统的时间消耗受到极大影响,就比如表1中处理10万条数据要花费327432ms,这样的执行效率是不可观的。影响时间的因素涉及到多方面,比如:多线程对资源的竞争、数据库的多表处理、SQL优化问题、程序代码的时间复杂度、I/O流的优化[5]等,由于文章篇幅有限且时间消耗问题不是本文讨论的重点,所以不再详细分析。 4 结论 经过对用户模型在实际应用中的弊端以及产生原因的充分分析,展示了在不同數据规模下的系统性能消耗,利用生产者消费者模式的思想,对用户模式进行重构,使得用户模型中各个角色的职能分离、交互协作,并通过多线程并发编程的实现方式,解决了在一定数据量条件下的excel数据读取问题,节省了系统的部分内存消耗,提升了业务处理效率。让用户模型在原有的高度抽象、易于理解等特性的基础上,减轻了对系统资源的依赖,扩展了用户模型的应用场景。虽然还不能完全解决用户模型对 系统资源的依赖,但对用户模型的内存占用做出了一定程度的优化,关于用户模型的缺陷仍然在不断研究。 参考文献 [1] Apache POI docs[EB/OL]. [2019-4-16]. http://poi.apache. org/components/spreadsheet/index. html. [2] 李腾. 批量数据优化处理框架的设计和实现[D]. 山东大学, 2015. [3] 路勇. Java多线程同步问题分析[J]. 软件, 2012, 33(4): 31-33 [4] 吉豪杰. 大数据时代下基于SSM框架的高校毕业生档案管理系统的研发设计[J]. 软件, 2018, 39(11): 151-158. [5] 马凯航, 高永明, 吴止锾等. 大数据时代数据管理技术研究综述[J]. 软件, 2015, 36(10): 46-49 [6] 左大鹏, 徐薇. 基于Hadoop 处理小文件的优化策略[J]. 软件, 2015, 36(2): 107-111 [7] 朝格. 浅谈EXCEL与XML的数据交换[J]. 软件, 2012, 33(5): 48-50 [8] 张强. 创建型模式在题型库设计中的应用[J]. 软件, 2012, 33(3): 69-71 [9] 胡泳霞. 基于内存模型的Java并发编程[J]. 电子测试, 2016(13): 89-90. [10] 张志强, 王伟钧, 施达. 一种大容量数据文件抽取算法的优化研究[J]. 成都大学学报(自然科学版), 2019(01): 52-55. [11] 劳加庆, 叶飞跃, 张国平. 多线程技术对批量数据处理的优化[J]. 微型机与应用, 2001(04): 11-12.