面向语义缺失场景的社交媒体中热门新闻识别方法研究
2019-10-06谢海涛肖倩
谢海涛 肖倩

摘 要:[目的/意义]对社交媒体中热门新闻的及时识别,有助于加速正面资讯的投送或抑制负面资讯的扩散。当前,基于自然语言处理的传统识别方法正面临社交媒体新生态的挑战:大量新闻内容以图片、音视频形式存在,缺乏用于语义及情感分析的文本。[方法/过程]对此,本文首先将社交网络划分为众多社群,并按其层次结构组织为贝叶斯网络。接着,面向社群构建基于卷积神经网络的热门新闻识别模型,模型综合考虑新闻传播的宏观统计规律及微观传播过程,以提取社群内热门新闻传播的特征。最后,利用贝叶斯推理并结合局部性的模型识别结果进行全局性热度预测。[结果/结论]实验表明,本方法在语义缺失场景下可有效识别热门新闻,其准确度强于基于语义信息的机器学习方法,模型具有良好的时效性、可扩展性和适用性。该研究有助于社交媒体的监管机构及时识别出各类不含语义信息且迅速扩散的热点内容。
关键词:社交媒体;舆情分析;热门新闻识别;卷积神经网络
DOI:10.3969/j.issn.1008-0821.2019.09.004
〔中图分类号〕G203 〔文献标识码〕A 〔文章编号〕1008-0821(2019)09-0028-13
Abstract:[Purpose/Significance]Recognition of hot news in social media is beneficial for interfering the dissemination of information.At present,the traditional recognition methods based on NLP are facing the new challenge,i.e.,many news are lack of texts for semantic and emotional analysis,such as pictures and videos.[Method/Process]To this end,this paper firstly divided social networks into communities and organized them as a Bayesian network according to their hierarchical structure.Then,a hot news recognition model based on convolutional neural network was constructed for each community.The model synthetically analysed the macro statistics and micro processes,so as to retrieve the features of hot news disseminations within the community.Finally,the global popularity prediction was carried out by Bayesian reasoning based on the local model recognition results.[Result/Conclusion]Experiments showed that our method could effectively recognize hot news without semantic data,and improve the speed and accuracy of hot news recognitions with certain extendibility.The research would help social media regulators identify hot topics that do not contain semantic information and spread rapidly.
Key words:social media;public opinion analysis;hot news recognition;convolutional neural network
近年來,国内外社交媒体(Social Media)产业发展迅猛。一方面,传统巨头(微博、微信、Twitter、Youtube等)深化着对大众信息分享习惯的影响;另一方面,新入局者(抖音、喜马拉雅FM、Instagram等)也在各自细分领域塑造着资讯传播的新模式。面对社交媒体中由用户生成的信息洪流,从中快速识别出热门新闻既有利于社交媒体提升运营质量,如发现优质内容后推荐给更多受众;也有助于政府机构及时获悉各类舆情预警并进行干预,如由政治事件[1]、经济震荡[2]、群体性事件[3]所引发的舆情波动。因此,热门新闻(Hot News)识别受到情报学、新闻传播学、计算机科学等领域的广泛关注并成为研究热点[4]。
热门新闻可定义为在一定范围的用户群体内,在单位时间中受众数量平均值较高的新闻。目前,针对社交媒体中热门新闻的识别问题已存在诸多方法[5]。其中,取得较好应用效果的方法大多需要语义信息的支撑,包括:1)基于概率统计及机器学习的方法,需根据历史数据对新闻关键词(主题词、敏感词)与其热度(点击量、评论数)之间的关联关系进行建模和学习,进而实现热门新闻识别;2)针对富含情感词的新闻文本、用户评论、表情符号等进行情感分析,根据新闻所引发公众情绪的正负性及其激烈程度来甄别热点。
虽然已有研究成果丰硕,但社交媒体与新闻传媒业态的飞速发展,正不断催生出更具挑战性的信息承载与传播生态,表现为:海量涌现的多媒体新闻内容夹杂着语义模糊的“流行语”,以图片、音视频等形式在社交媒体中迅速传播。由于从上述形态的新闻内容中抽取语义信息较为困难,因此基于自然语言处理技术(NLP)的热门新闻识别方法出现了较大局限性。本文力图摆脱对语义数据的依赖,将新闻的宏观传播态势与微观传播过程(社交网络节点间的信息传播时序)相结合,利用卷积神经网络(Convolutional Neural Network,CNN)抽取社群中热门新闻的多层次传播特征,并基于贝叶斯网络构建一种在社交媒体中识别热门新闻的方法。该方法在语义数据缺失场景下具有良好的识别准确度,也具有一定的时效性、可扩展性和适用性。
1 研究现状
针对热门新闻识别、热点话题发现(Topic Detection)、谣言监测(Rumor Spread Detection)等舆情分析问题已存在不少研究成果,其中应用效果较好的方法往往需要语义分析(Semantic Analysis)技术的支撑[6]。根据所选语义要素的不同,可将相关研究分为基于情感词和基于主题词的两类方法。
1)基于情感词的方法。该类方法基于情感词典对包含情感词汇的文本进行情感分析(Sentiment Analysis),以判断受众对新闻的情感状态[7-8]。在衡量受众情感的激烈程度上,主要从两个角度切入:第一,静态统计分析角度。将新闻给受众带来的情感变化与社会网络分析的已有研究结论相结合,得到新闻对整个社群情绪的正负性影响程度[9-10]。虽然该类方法在实践中取得了一定效果,例如首欢容等将其应用于谣言识别问题[11],但其只考虑了网络所展现的静态特性,未考虑信息的实际动态传播过程[12],存在缺陷;第二,传播动力学角度,如借鉴传染病模型(SIR)等,使用微分方程对社交网络中情绪传播的速率进行建模,从而预测新闻在网络中引发的情绪扩散态势[13]。相比于静态视角,动力学视角的方法可在时间维度上提供了更为精细化的预测。不过,网络情感词汇的表达具有相当的丰富性和多变性,因此以上方法对用户情感的判断往往不准确,很多研究缺乏对计算结果准确率和召回率的验证[4]。虽然也有研究者试图将支持向量机(SVM)与潜在语义分析(LSA)相结合,对情感词在高维度空间中进行分类,以期对用户的情感状态进行较为精确的判定,但社交媒体中的情感词过于灵活多变,模型的训练样本需要频繁更新,建模成本过高[14]。
2)基于主题词的方法。该类方法旨在挖掘新闻的主题特征与其热度之间的关联,根据历史数据训练出热门新闻识别模型。在抽取新闻的高维主题特征时,该类方法通常需要构建主题模型(Topic Model)。常用的主題模型包括概率潜在语义分析(pLSA)和隐含主题分析模型(LDA)等。在识别出新闻主题的基础上,利用无监督机器学习(Unsupervised Learning),如K-means聚类[5]、层次式聚类[15],对待判定对象及其它样本进行聚类,进而根据新闻所属类别来判断其是否热门。除无监督学习外,有监督学习(Supervised Learning)方法中的分类模型也被用来实现热点识别。例如,饶浩等用主成分分析法提取热门事件中的主要主题特征,再通过BP神经网络进行分类学习,实现热度分类模型[16]。随后,饶浩等还尝试将改进的支持向量机用于微博热门话题预测。该方法通过将高维特征空间中的内积运算转变为低维空间的函数运算,来拟合主题词词频与话题热度的关联,进而生成热门舆情预警模型[17]。相比于无监督方法,有监督方法具有更好的时效性,不需要在每次热门新闻的判定中都执行样本空间上的整体计算,但其也存在分类模型选择和模型复杂度设置方面的困难。
总之,以上两类方法均依赖于新闻包含的语义数据。然而,当前社交媒体上大量的热门新闻会以图片、音视频形式出现,缺乏判断其情感和主题的文本信息。因此,上述方法都不适用于此类语义缺失的识别场景。如若采用成本高昂的人工标记法对内容进行语义采集,也易造成监管的滞后性,无法满足舆情监测的实时性需求[18]。对此,杨小平、叶川等通过将用户评论作为新闻内容的补充来提取新闻的情感特征[19]与主题特征[20],曾金等通过识别图片的视觉特征来注释图片的语义[21],上述两种方法都存在数据噪音大、实用范围窄的问题;魏静、Liben-Nowell等依靠网络结构和节点相似性进行信息传播预测,虽然不再依赖文本信息,但却需要获知额外的用户属性[22-23],由于数据缺失是社交网络中的常见问题[24],以致该方法的应用受限。综上所述,本文旨在面向较为严苛的场景,在假设没有语义数据和用户属性信息的前提下,仅利用新闻传播的宏观统计量和微观传播时序信息,建立深度学习模型RHC以提取新闻多层次传播特征与其热度之间的关联。
2 社交网络中热门新闻的识别机制设计
2.1 基于社群划分的热门新闻分析框架
社交媒体中新闻的热度具有“时间与空间”上的动态变化性。一方面,新闻具有特定的生命周期,在其变成热门之前,会经过不同时间跨度的潜伏期;另一方面,社交网络用户基于兴趣和社会属性聚集成社群,特性主题的新闻通常仅在特定范围的人群中流行。因此,仅通过新闻传播的宏观统计量来判断其是否属于热门,会存在较大偏差。
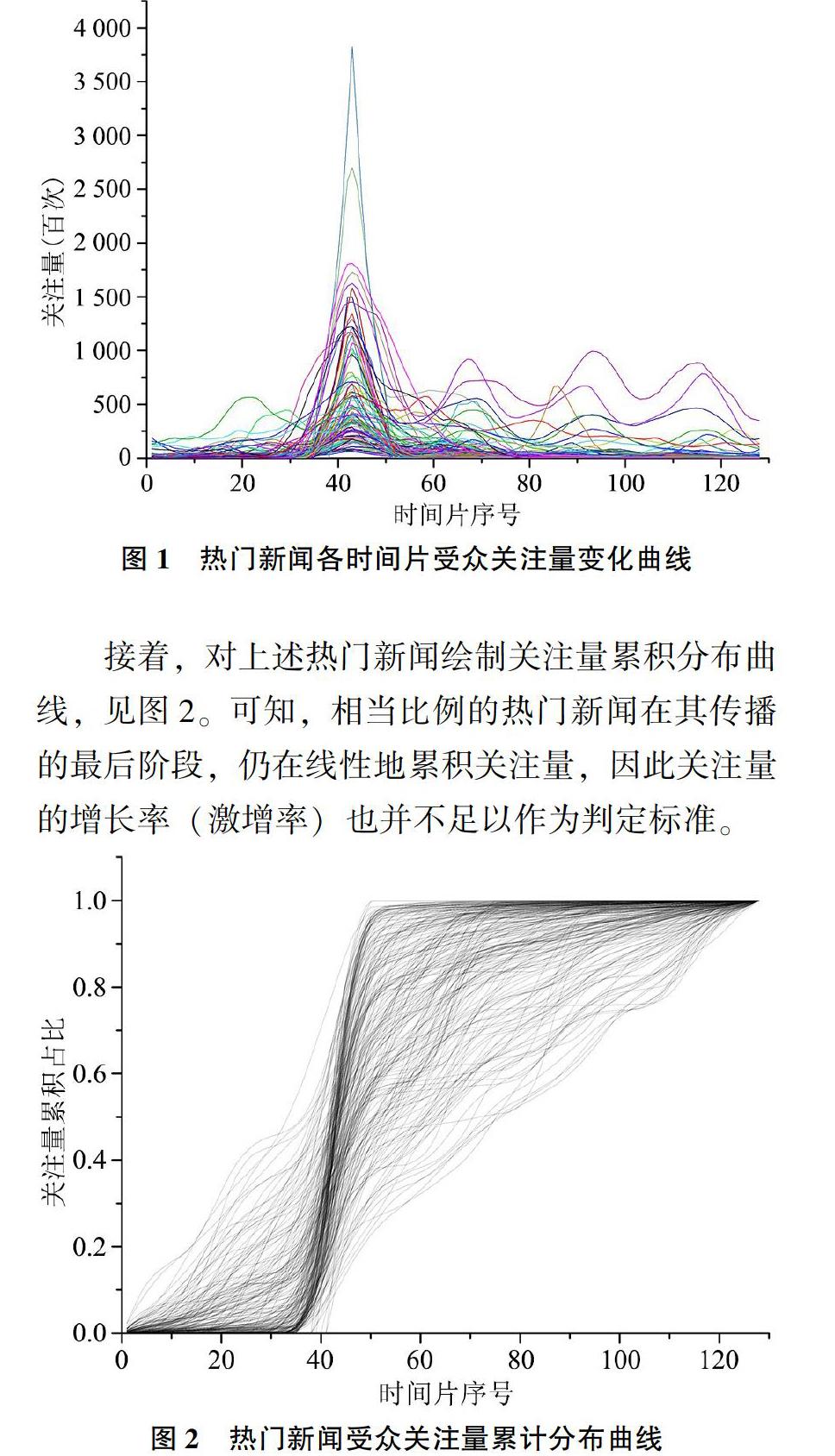
为验证上述结论,本文分析了社交媒体领域公认性高的公开数据集“斯坦福网络分析项目”(snap.stanford.edu),其选取Twitter中的局部社交网络,并对2008-2009年间的1 000条新闻进行了128个时次的受众跟踪,共涉及3千万个用户的转发(Retweet)行为。基于Stanford数据集,按新闻在单位时间片中的受众关注量均值排序,取排名前10%的热门新闻绘制128个时次的关注量变化曲线,见图1。可知,关注量曲线在波峰位置、波峰数量、峰值时刻等方面均存在显著差异,从曲线形态上无法直接区分热门新闻。
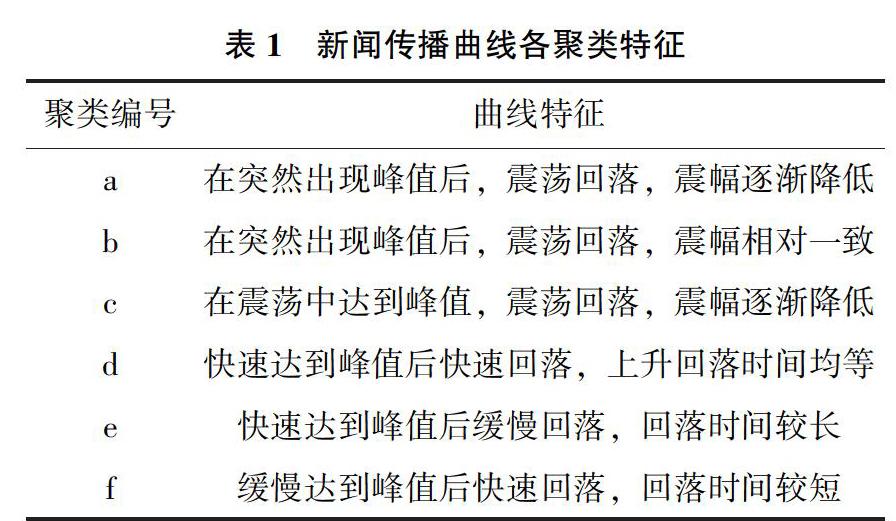
接着,对上述热门新闻绘制关注量累积分布曲线,见图2。可知,相当比例的热门新闻在其传播的最后阶段,仍在线性地累积关注量,因此关注量的增长率(激增率)也并不足以作为判定标准。
最后,按排序结果由高到低取5组新闻,每组100条。按分组分别绘制新闻在单个时次中出现的关注量峰值,见图3。可知,有相当比例的较冷门新闻的峰值也会高于较热门的新闻。若以峰值作为热门判定标准,误判率较高。
基于上述考虑,本文旨在将新闻传播的微观过程纳入考量,以弥补宏观统计量的不足。同时,借鉴“分治法”思想,将社交网络分割为层次化组织的社群,以应对热门新闻的局部性特点。分析框架见图4,基于卷积神经网络的热门新闻识别模型针对每个处于“叶子节点”位置的社群进行单独构建,以新闻的宏观统计和微观传播特征为输入,对受监控下的新闻给出是否属于热门的判定。将整个社交网络抽象并同构于贝叶斯网络,在叶子节点给出判定结果后,基于反向推理得到新闻在全局范围内的热度预测。
2.2 基于介数的层次式社群划分
对社交网络进行层次式社群划分,既有利于精确定位热门新闻的波及范围,也有助于保障深度学习模型在学习与监测中的计算可行性。整体上,采用分裂法进行划分直至社群满足终止条件,具体采用基于介数(Betweenness)的社群划分(Community Detection)方法。介数又称中介中心性,用以衡量边介于其他节点之间的程度。该方法是社群划分领域的经典算法,能割断处在不同社群之间的边,并将彼此连接较紧密的节点划分到同一社群,其划分结果符合“用户基于兴趣组成社群”的问题场景。另外,相比于基于节点聚类的方法,该方法具有更好的可计算性,适用于大规模社交网络。
基于上述操作,得到以s为源节点时的边介数。接下来需分别以所有节点为源节点进行轮询,最终将所有中间结果求和得到边的介数。在得到所有边的介数之后,基于GN算法进行社群划分[25],算法具体步骤不再赘述。GN算法的核心思想是按照边的介数由高到低进行剔除,剔除过程中会形成独立的社群,其终止条件是社群划分结果具有较高的模块度Q值(Modularity)。模块度用来衡量社群划分质量,是社群内部总边数与网络总边数的比值减去一个期望值,该期望值是假设网络为随机图时,在同样的社群划分下社群内部边数和网络边数的比值。计算公式如式(1),其中Avw为邻接矩阵中对应于节点v和w的元素,kv、kw是节点的度,m为网络中边的数量,θvw是指示函数,其值依赖于v、w是否在同一社群,若在则为1,否则为0最后,根据社交网络的结构特征并结合主观观察,通过设置合适的Q阈值,得到理想的社群划分结果。
2.3 新闻热度的贝叶斯推理
社交网络经划分会形成一棵“社群层次树”,其根节点代表整个网络,叶子节点代表最终划分后的社群,父节点(父群)会划分形成一组子节点(子群)。由于實际中的社交网络通常具有较大的用户规模,对所有叶子节点进行监控并无必要。因此通过对社群层次树进行剪枝来降低计算复杂度,剪枝方法为按特定比例删除父群下属的子群,删除的优先级反比于子群的规模。将剪枝后的社群层次树抽象为贝叶斯网络[26],并基于贝叶斯网络的参数学习与推理机制,能从历史数据中提取新闻在父群与子群中呈现出热门的条件概率,并在监测到子群出现热门新闻的情况下反向推理出该新闻在父群中属于热门的概率,具体如下:
最后,新闻热度推理机制按照固定的时间间隔,轮询叶子节点所对应模型的最新识别结果,并重新推理被监测新闻在上一层各父群范围内的热门概率,若概率超过阈值则认为新闻在父群中属于热门。依次类推,自底向上逐层推理出新闻的各层次判定结果。
3 基于卷积神经网络的热门新闻识别模型
3.1 面向传播统计量的宏观特征构建
新闻传播的宏观统计量是判断热门新闻的重要指标,如:点击量、转发量、评论数,但通过2.1节分析已知,简单的统计量难以有效刻画新闻传播的宏观特征。因此,本文采用了基于时间片的向量描述形式,如Stanford数据集中128个时次的关注量可用128维的向量描述,向量元素是单个时间片对应的关注量数值。相比于简单统计量,向量能刻画统计量的变化曲线,其可能隐含着新闻主题类别、新闻传播路径、新闻爆发形式等信息。
为验证本方法的合理性,再次针对Stanford数据集进行分析,随机选择一定数量的样本数据。考虑到新闻间的关注量差异较大,对样本集128个时次的关注量监测值xt按照式(4)进行归一化处理(Normalization)。对归一化后的关注量变化曲线进行K-means聚类,当聚类数量设置为6时,会形成聚类内部较一致、聚类之间较不同的结果,见图6。各类别均呈现相对特异的传播曲线,其主要特征总结见表1。
对于存在显著形态差异的曲线聚类背后的形成机制,本文假设聚类与新闻主题存在关联,即:不同主题的新闻会经过不同的传播路径,形成了差异性的关注量变化曲线。若该假设得到验证,则说明曲线形态确实蕴含着丰富的信息,向量描述形式更加合理。为验证该假设,本文对每条新闻进行类别标注,类别设置为10个,包括:政治、经济、社会、文化、体育、娱乐、教育、军事、健康、科技。新闻对类别的隶属关系使用10维向量表示,隶属度取值范围是[0,1],若干示例见表2所示。
对标注后的新闻进行K-means聚类,聚类数量设置为6,可得到基于主题的聚类结果。结合上文中的基于曲线形态的聚类结果,可得R×C列联表,见表3。对列联表按照式(5)进行R×C表卡方检验(独立性检验),其中A为实际观察频数,n为样本总数,nR、nC分别为各行、各列的合计,自由度为(R-1)×(C-1)。计算得到Fisher精确检验值121.623,P值<0.01,由此拒绝独立性假设,可知曲线形态与主题类别之间存在关联,可知向量描述形式能保留更多的知识。
3.2 面向传播时序过程的微观特征构建
3.2.1 基于节点中心性及权重的社交网络采样
由于对社群中所有节点进行传播过程监控的计算复杂度过高,因此需要进一步简化社群,简化方法是基于节点中心性(Centrality)对网络生成摘要。由于中心性较高的节点,其行为也较有代表性[27],因此新闻在该类节点上的传播时序,也更具挖掘价值。本文采用了3种主流的节点中心性(见表4)生成网络摘要,中心性越高的节点被保留的概率越大。另外,由于社交网络中节点属性及权重差异较大,高权重节点(意见领袖)对信息传播存在重要影响。因此网络采样中要优先保留高权重节点,要设置节点的保留概率正比于其权重。
3.2.2 微观传播特征的热力图表示
新闻传播的微观特征蕴含在受众参与传播的时序信息之中,如社交网络中用户转发某新闻的早晚顺序。若利用时序信息表征热门新闻的微观特征,需对两点加以验证:1)网络简化后的高中心性用户在参与热门和非热门新闻传播时,是否存在时间差异;2)热门新闻相对于非热门新闻的传播过程,是否存在更加显著的时序模式可供学习。
针对第一点,基于Stanford数据集展开分析。随机选取数据记录,将用户参与新闻转发的时间片、新闻热度、用户中心性绘制见图8。可知,高中心性的用户在高热度新闻传播中,呈现较早参与的趋势。
针对第二点,使用频繁序列模式(Frequent Sequential Pattern)来描述用户群体参与新闻传播
所展现出的显著时序模式。频繁序列模式常被用来描述海量的数据库事务中高频率存在的信息关联,如长度为3的模式“A→B→C”可表示如下规律在数据集中高频显现,即:“先出现A,再出现B,最后出现C”。本文使用PrefixSpan算法来进行频繁模式挖掘[28],模式的支持度(出现频率)阈值设置为0.1。对热门新闻与非热门新闻分别挖掘后,可得到两类新闻中不同长度的模式及其支持度。对两类别中相同长度模式的支持度进行方差分析,得到显著性数值(P值)见表5。从表5可知,热门新闻相比于非热门新闻存在更加显著的时序模式,时序模式也具有更高的支持度。
基于上述分析,可知使用时序模式来描述新闻传播的微观特征具备合理性。因此,本文构建了一种既能容纳时序信息,又能被卷积神经网络处理的热力图来描述新闻的传播过程,并基于热力图对特定社群中的新闻传播历史数据进行重新表述,以期从中挖掘到多层次的新闻传播规律。对于每条新闻传播数据,共构建3组热力图,分别对应于上述3种社会网络抽样。每组生成M张热力图,每张热力图由N个区域顺次排列组合而成,每个区域包含D×B个像素,D为生成的传播链条长度,B为宽度。具体生成流程见图9。
某社区中一则新闻传播的热力图,见图10。该热力图共有5个区域,生成的传播链长度为30,宽度为6。该图中的一个像素对应一个用户节点,像素颜色代表该用户参与该新闻传播的时间早晚,蓝色为较早、红色为较晚。可见,图10不但表征了参与传播的用户数量、增长率等特征,也涵盖了若干微观时序特征,如黑色小方框区域所展示的若干节点参与传播的相对时间顺序。
3.3 基于卷积神经网络构建热门新闻识别模型RHC
深度学习中的卷积神经网络(CNN)是一种机器学习模型,被广泛用于各类模式识别问题中,它通过有深度的卷积操作提取不同抽象层次的高维特征;通过池化技术(Pooling)有效控制学习规模,加速参数收敛,并使模型具有泛化能力;通过多层感知机部件灵活解决分类、回归等问题[29]。本文以热力图的形式重新表述新闻的传播过程,使所要解决的热门新闻识别问题适合用CNN来解决。基于CNN的RHC(Recognition of Hot News Based on CNN)模型结构,见图11。
RHC模型分为两部分:第一,新闻传播特征抽取,即从信息传播过程中抽取传播特征;第二,热门新闻识别,基于新闻传播特征,判断新闻是否热门。下面对两部分进行介绍。
第一部分,新闻传播特征抽取:
1)输入信号(Channel)是某条新闻传播过程的3组热力图,共3×M张。由于热力图可用二维矩阵表示,因此任何一个热力图均可表示为f(x,y),函数数值均归一化到[0,1]区间。
2)对输入信号进行C1、C2、S1、S2 4个过程的特征映射(Feature Map)。其中,C1、C2是卷积层,S1、S2是池化层。
卷积操作是将两个函数通过加权求和来进行叠加。若操作发生在二维平面上,输入特征f(x,y)与卷积核g(x,y)是如下映射函数R2→R,则卷积结果c(x,y)为:
在本文中,与一般情况不同的是卷积核要考虑输入特征的厚度,即热力图的层数3×M。因此,新闻的一系列热力图输入可表达为fz(x,y)函数,z∈{1,…,3×M}。输入特征需要与多个卷积核进行计算,卷积核均为gz(x,y)形式。卷积方法为按层对每个热力图同一区域分别进行二维卷积,最后按区域对各层二维卷积结果求和生成三维卷积结果。例如,I表示一系列热力图输入,厚度为2,两个热力图分别记为I1、I2。K与I相对应,为3×3×2(厚度)卷积核,则卷积结果为:((1×1)+(3×4))+((2×3)+(4×1))=23。池化操作用以进行特征采样。由于卷积后会生成大量特征,为提升模型泛化能力并降低计算量,故用池化操作保留概要特征。本文采用的是最大池化(Max Pooling)方法,保留采样范围内的最大值,例如,对4×4的特征矩阵,进行2×2面积的池化。
实际设计时,通常会将卷积结果再代入激活函数,对特征进行非线性映射,并压缩值域范围。本文采用的是ReLU(Rectified Linear Unit)激活函数,该函数将在下文介绍。
3)将经过上述特征映射后的结果进行光栅化,即将矩阵元素一字排开变成向量形式,并与基于时间片的宏观统计向量拼接成一个向量,称为新闻传播向量,该向量作为第二部分(热门新闻识别)的输入。
第二部分,热门新闻识别:
该部分由两个部件构成,前一个部件是全连接的多层感知机,后一个部件是热门新闻识别分类器。
1)多层感知机类似于神经网络,用以进行多个输入的累加与非线性映射,具体结构如下:
其中,Input=(Input1,…,Inputn)是输入向量,w=(w1,…,wn)是权重向量,b是偏置量,ReLU激活函数的表达式为f(x)=max(0,x)。该激活函数有两个优点:第一,梯度不饱和,在模型参数调优的反向传播(Back Propagation)中,减轻了梯度弥散的问题;第二,极大地加快了参数收敛的速度。以上从输入到输出的计算公式如下:
2)熱门新闻识别分类器用来做出最终判断。由于判断新闻是否热门属于分类问题,故此处采用Softmax多分类模型,损失函数(Loss Function)用均方误差法(Mean Squared Error,MSE)。它们的公式分别为:
為确定上述模型中的大量参数,本文采用神经网络、卷积神经网络常用的反向传播算法进行参数学习。该标准化算法较为成熟,具体实现可参见卷积神经网络相关文献,本文不再赘述。
综上,RHC模型将针对特定社群上的热门识别问题进行训练,训练数据为社群中非语义的新闻传播历史数据,其中的热门新闻为在全局范围内某统计量排序靠前的一定比例的新闻,训练后模型可对社群中的非语义新闻传播数据进行监控,从而发现热门新闻。
4 实验设计与结果分析
4.1 实验内容设计
实验针对上文所述的“斯坦福网络分析项目”(snap.stanford.edu)公开数据集展开,数据集对2008-2009年间Twitter局部网络中的1 000条新闻进行了128个时次的受众跟踪,涉及的社交网络有节点3千万个。本实验截取其中的子网络进行实验,涉及网络节点25 000个,边121 720条。将1 000条原始数据按照单位时间中的关注量均值由高到低排序,将排名前20%的个体标注为热门新闻。随机取其中80%作为训练集,剩余作为测试集,形成“热门新闻识别数据集”。
本文使用Keras(https://keras.io)实现卷积神经网络模型RHC。Keras是构建CNN的高层API,由Python实现,并基于Tensorflow等后端运行。本文采用适用于科学计算的Python发行版Anaconda。所用计算机内存16G、SSD硬盘256G、CPU为英特尔酷睿i7。RHC关键代码如下:
本文共设计4个实验来验证基于RHC模型的热门新闻识别机制(以下简称RHC)的工作情况:1)RHC有效性实验,看其在非语义场景中的热门新闻的识别率相比于基于语义信息的机器学习方法的优劣;2)RHC时效性实验,看其能否较早地识别出热门新闻;3)RHC可扩展性实验,看能否通过增加卷积神经网络复杂度来提升识别准确度;4)RHC适用性实验,用仿真实验设计各类新闻传播场景,看RHC方法的适应能力。
4.2 RHC方法的有效性与时效性实验
为了对比,本文实现了基于语义信息的逻辑回归方法LR。首先对1 000条新闻进行4.1节中的主题类别标注,语义标注由多人完成并进行了一致性验证。然后LR基于训练集的10维主题向量和热门与否的标签进行训练。最后LR基于10维主题向量对测试集进行二元分类。用RHC与LR方法分别进行识别,统计结果见表6。可知RHC在非语义场景中识别热门新闻上的表现强于基于语义的逻辑回归方法,热门新闻识别率良好。
由于每条新闻的传播数据都存在128个时次的“快照”,因此在实验中通过按时间早晚顺序复现传播过程让RHC执行128次识别,并记录正确识别出热门新闻时的用户关注量。将识别出的30条热门新闻按最终关注量由高到低分5组,统计其被正确识别为热门新闻时的用户关注量均值,结果见表7。可知,RHC方法能较早地识别出正在扩散的热门新闻,且新闻热度越高,相对识别速度越快。
4.3 RHC方法的可扩展性与适用性实验
为验证RHC方法的可扩展性,对卷积神经网络模型做两方面扩展:1)扩展模型的深度,深度体现为各类特征映射层、全连接层等的数量之和;2)提高训练集在数据集中的比例。对各情况下的RHC识别F值统计见图12。
随着样本数据集的扩大、模型复杂度的提升,虽然模型的学习时间延长,但其识别能力也随之上升,可见,模型有一定可扩展性。因此,在具有高性能计算环境的情况下,可在该模型中应用大规模数据集,从而提升模型的精度。
为验证RHC模型在不同场景中识别能力的适用性,本文实现了一种基于元胞自动机的社会网络中新闻传播仿真工具RHC-Sim[30]。在该工具中,用户节点分布在二维网络中,节点与4个相邻节点为邻居节点(若节点为黑色,则表示不存在此邻居)。红色表示已分享某条新闻的节点,绿色表示未分享该新闻的节点。在该工具中,主要配置项见表8,工具可直接输出仿真测试数据,其运行时的可视化结果见图13。为保证仿真贴近于真实情况,本文将模型所依据的新闻传播规律纳入了仿真工具的配置与编码中。
为验证RHC模型的适用性,使用仿真工具RHC-Sim创建不同结构特征的社交网络。在同一轮实验中,固定网络结构,用户被设置为不同的属性。每轮实验进行100次仿真,其中热度高的新闻占20%,普通新闻占80%。所生成数据80%用于训练集、20%用于测试集,在每次仿真中新闻的波及范围和传播源头数量均被设置为不同数值,见图14左图。针对得到的测试数据集,统计RHC识别精确度均值见图14右图。
可知,RHC模型在多种社交网络结构中,对多种传播模式的热门新闻都有较高识别精确度,且随着传播源头数量的增长、传播范围的增大,识别精度逐渐提高并最终稳定。精度的提高与传播源头多、传播范围广的热门新闻具有更多的传播时序信息和宏观统计特征可供模型学习存在相关性。
5 结论与展望
本文面向语义信息缺失的场景,提出了一种用于社交媒体的热门新闻识别方法。该方法将新闻传播过程用热力图重新表征,利用卷积神经网络从宏观统计特征及微观传播过程的时序信息中提取多层次特征,摆脱了对语义的依赖,识别精度强于基于语义信息的机器学习方法,且具有一定时效性、可扩展性和适用性。本研究有助于在社交网络的舆情监管、情报分析、个性化推荐、谣言探测、恶意传播等问题中,更有效地捕捉各类不含语义的新媒体热门内容,包括:数据、图片、音频、视频、链接、加密文件等。另外,由于深度学习模型的设计较依赖研究者的主观知识,因此如何将模型设计与传播学、情报学的传统分析方法有机融合以形成设计更加合理的模型,有待进一步探索。
参考文献
[1]Tumasjan A,Sprenger T O,Sandner PG,et al.Predicting Elections with Twitter:What 140 Characters Reveal About Political Sentiment[C]Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media.The AAAI Press,2010:178-185.
[2]Bollen J,Mao H,Zeng X.Twitter Mood Predicts the Stock Market[J].Journal of Computational Science,2011,2(1):1-8.
[3]安璐,欧孟花.突发公共卫生事件利益相关者的社会网络情感图谱研究[J].图书情报工作,2017,61(20):120-130.
[4]纪雪梅,王芳.SNA视角下的在线社交网络情感传播研究综述[J].情报理论与实践,2015,38(7):139-144.
[5]王晰巍,邢云菲,王楠,等.媒体环境下突发事件网络舆情信息传播及实证研究——以新浪微博“南海仲裁案”话题为例[J].情报理论与实践,2017,40(9):1-7.
[6]張艳丰,李贺,彭丽徽,等.基于语义隶属度模糊推理的网络舆情监测预警实证研究[J].情报理论与实践,2017,40(9):82-89.
[7]Bermingham A,Smeaton A F.Classifying Sentiment in Microblogs:Is Brevity an Advantage?[C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Management.ACM,2010:1833-1836.
[8]赵晓航.基于情感分析与主题分析的“后微博”时代突发事件政府信息公开研究——以新浪微博“天津爆炸”话题为例[J].图书情报工作,2016,60(20):104-111.
[9]Symeonidis P,Tiakas E,Manolopoulos Y.Transitive Node Similarity for Link Prediction in Social Networks with Positive and Negative Links[C]//Proceedings of the Fourth ACM Conference on Recommender Systems.ACM,2010:183-190.
[10]王丹,张海涛,刘雅姝,等.微博舆情关键节点情感倾向分析及思想引领研究[J].图书情报工作,2019,63(4):15-22.
[11]首欢容,邓淑卿,徐健.基于情感分析的网络谣言识别方法[J].数据分析与知识发现,2017,1(7):44-51.
[12]叶腾,韩丽川,邢春晓,等.基于复杂网络的虚拟社区创新知识传播机制研究[J].现代图书情报技术,2016,32(7-8):70-77.
[13]Cole W D.An Information Diffusion Approach for Detecting Emotional Contagion in Online Social Networks[D].Tempe,AZ:Arizona State University,2011.
[14]田世海,吕德丽.改进潜在语义分析和支持向量机算法用于突发安全事件舆情预警[J].数据分析与知识发现,2017,1(2):11-18.
[15]丁晟春,龚思兰,李红梅.基于突发主题词和凝聚式层次聚类的微博突发事件检测研究[J].现代图书情报技术,2016,32(7-8):12-20.
[16]饶浩,陈海媚.主成分分析与BP神经网络在微博舆情预判中的应用[J].现代情报,2016,36(7):58-62.
[17]饶浩,文海宁,林育曼,等.改进的支持向量机在微博热点话题预测中的应用[J].现代情报,2017,37(3):46-51.
[18]李真,丁晟春,王楠.网络舆情观点主题识别研究[J].数据分析与知识发现,2017,1(8):18-30.
[19]杨小平,马奇凤,余力,等.评论簇在网络舆论中的情感倾向代表性研究[J].现代图书情报技术,2016,32(7-8):51-59.
[20]叶川,马静.多媒体微博评论信息的主题发现算法研究[J].现代图书情报技术,2015,31(11):51-59.
[21]曾金,陆伟,丁恒,等.基于图像语义的用户兴趣建模[J].数据分析与知识发现,2017,1(4):76-83.
[22]魏静,朱恒民,宋瑞晓,等.个体视角下的网络舆情传递链路预测分析[J].现代图书情报技术,2016,32(1):55-64.
[23]Liben-Nowell D,Kleinberg J.The Link-Prediction Problem for Social Networks[J].Journal of the American Society for Information Science and Technology,2007,58(7):1019-1031.
[24]柯昊,李天,周悦,等.数据缺失时基于BP神经网络的作者重名辨识研究[J].情报学报,2018,37(6):600-609.
[25]Girvan M,Newman M E.Community Structure in Social and Biological Networks[J].Proceedings of the National Academy of Sciences of the United States of America,2002,99(12):7821-7826.
[26]Koller D,Friedman N.Probabilistic Graphical Models:Principles and Techniques-Adaptive Computation and Machine Learning[M].Probabilistic Graphical Models-Principles and Techniques,2009.
[27]张凌,罗曼曼,朱礼军.基于社交网络的信息扩散分析研究[J].数据分析与知识发现,2018,2(2):46-57.
[28]Pei J,Han J,Mortazaviasl B,et al.PrefixSpan:Mining Sequential Patterns Efficiently By Prefix-projected Pattern Growth[C]//International Conference on Data Engineering,2001:215-224.
[29]朱娜娜,景东,薛涵.基于深度神经网络的微博图书名识别研究[J].图书情报工作,2016,60(4):102-106.
[30]杨晶,罗守贵.基于元胞自动机的网络谣言传播仿真研究[J].现代情报,2017,37(6):86-90.
(责任编辑:孙国雷)
