基于特征和项目近邻的混合推荐算法研究
2019-09-28苏晓云祝永志
苏晓云,祝永志
(曲阜师范大学 信息科学与工程学院,山东 日照 276826)
0 引 言
在互联网和信息技术飞速发展的背景下,网络中的数据呈现爆炸性增长的趋势,同时也存在大量冗余,如何从这些过量数据中高效准确地提取出所需信息成为当前亟待解决的难题。推荐系统正是解决这一难题的重要手段。
推荐系统[1]旨在为用户提供个性化的产品或服务推荐,通过处理日益增多的过载信息来改善当前难以从大量冗杂数据中检索有效信息的状况,从而提供个性化服务。早期研究人员就开始关注明确依赖评级结构的推荐问题[2],基于项目间或项目与用户间交互的相关信息来对用户兴趣进行预测,进而向特定的用户推荐最适合的项目,以生成个性化推荐。
1 相关研究
推荐算法是推荐系统的核心,协同过滤[3]是推荐算法中最流行的方法,它从用户行为中收集大量的数据来进行预测,依赖于用户和项目之间的关系;混合推荐算法是指综合不同推荐算法的优势从而提高推荐算法准确性的一种推荐方法。
近年来,国内外研究人员对推荐算法的研究呈现出多样化的趋势。如文献[4]在传统矩阵分解模型SVD的基础上提出了最小二乘ALS算法;文献[5]将协同过滤应用到Spark平台上,实现了算法并行化;文献[6]基于用户相似度定义了一种社交网络中的属性相似度,改进了协同过滤算法;文献[7]提出了一种基于用户行为特征的动态加权混合推荐算法,有效降低了推荐的误差,提高了推荐精度。
文中将基于项目的协同过滤推荐算法(ItemBase CF)与基于矩阵分解的最小二乘法(ALS)进行动态加权混合,并将该混合算法在Spark平台上进行实现,以提高算法的并行性和扩展性,以及推荐准确性。
2 协同过滤推荐算法
2.1 ItemBase协同过滤推荐算法
2.1.1 相似度计算
ItemBase CF根据项目间的相似性,对于给定的某个用户根据其历史行为信息,将相似度最高的物品推荐给用户[8]。计算物品之间相似度的方法[9]主要有:
(1)余弦相似度。
(1)
(2)修正的余弦相似度。
(2)
(3)Pearson相关性相似度。
(3)
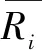
2.1.2 评分预测
在ItemBase CF中采用基于项目均值的加权平均值来计算预测评分[10],公式如下:
(4)
ItemBase CF通过计算项目间的相似度,将相似度较高的前k个项目作为该项目的近邻集合[11],通过调整k值的大小可以改善推荐结果的精确度。
2.2 基于ALS的协同过滤推荐算法
基于矩阵分解的ALS协同过滤推荐算法[12]的原理是通过最小化Frobenius损失函数找到两个低秩矩阵U、V来最大程度逼近原矩阵R,即:
(5)
其中,Rm×n为原始评分矩阵;Um×d为用户特征矩阵;Vd×n为项目特征矩阵,d≪min(m,n)。
Frobenius损失函数如下:
(6)
为防止过拟合问题,加入正则化参数,如下:
(7)
在求解过程中,通过交替迭代的方法,先固定V,将L(U,V)对ui求偏导,得到:
ui=(VTV+λI)-1VTri
(8)
同理,对vj求偏导得到:
vj=(UTU+λI)-1UTrj
(9)
式8、式9中,ri表示由用户i的评分组成的向量;rj表示由项目j组成的评分向量;I表示d×d的单位矩阵。
在上述过程中不断迭代,直到RMSE值最小或达到最大迭代次数[13]为止,将迭代产生的特征向量相乘得到R'=UVT。
3 混合协同过滤推荐算法IACF
3.1 由单机转向Spark分布式平台
传统的单机环境目前已不能满足大数据日益增长的需求,在运行具有较高复杂性的推荐算法时,实际效率是差强人意的。利用分布式平台将规模较大较复杂的作业分配给不同的节点,能够充分利用其存储和计算性能。
Spark分布式平台是基于内存的通用并行大数据计算引擎,在迭代速度上优于MapReduce[14],通过弹性分布式数据集(RDD)进行数据操作,将算法流程中的任何一个点映射到集群节点的内存中,后续过程不必反复从磁盘中读取数据,适用于多次迭代算法[15]。
Spark的工作原理如图1所示。
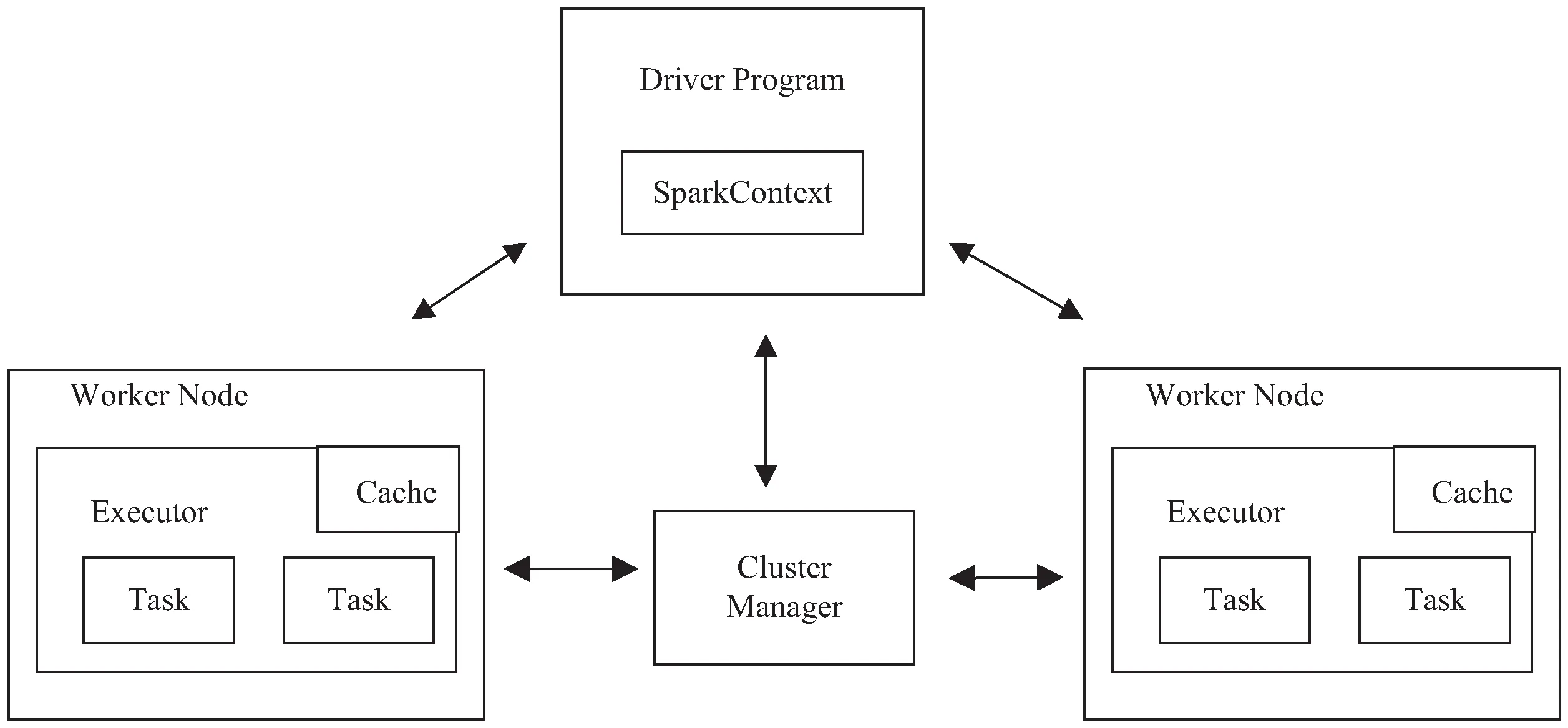
图1 Spark工作原理
3.2 混合推荐原理
基于项目的协同过滤算法与基于矩阵分解的ALS算法各有其优势,文中采用动态加权的方式将两种算法的预测结果进行混合,得到混合协同过滤推荐算法IACF(ItemBase_ALS collaborative filter)。该算法的主要原理是根据加权公式将ItemBase CF的评分Iui和ALS算法的评分Aui进行混合,得到最终预测评分Rui,加权公式如下:
Rui=λIui+(1-λ)Aui
(10)
其中,λ是加权因子,其取值会影响最终混合结果的精确性。
基于项目的协同过滤算法与项目近邻的选取有关;ALS算法与迭代次数、隐含特征因子的个数及正则项系数lambda有关。通过多次实验验证得知,隐含特征因子对算法准确性影响较大,因此文中选择隐含特征因子作为关键影响因素,固定迭代次数和lambda。在混合算法中,通过调整项目近邻n和隐藏特征因子r的取值来确定λ,如下:
(11)
(12)
3.3 算法描述
ItemBase CF和ALS混合协同过滤推荐算法(IACF)描述如下:
输入:用户-项目评分矩阵;
输出:预测结果评分。
(1)利用修正的余弦相似度公式(式2)计算项目间相似度;
(2)根据步骤1中的结果选择相似度最高的k个项目作为项目近邻,通过评分预测公式(式4)进行预测,得出预测结果Iui;
(3)调整隐藏特征r的个数,选择ALS算法进行预测,得出预测结果Aui;
(4)根据式11确定λ;
(5)根据加权公式(式10)将步骤2、3的结果进行混合,得出最终预测结果。
4 实验及结果分析
4.1 实验数据与环境
采用Grouplens提供的MovieLens数据集中约700位用户对9 000部电影的最新评分数据集,约10万条,评分范围为1~5分,分值越高表示用户对该电影的喜好程度越高。评分数据集格式如表1所示。

表1 评分数据表格式
实验环境是在VirtureBox虚拟机上架设的三个节点的Hadoop集群,系统为Ubuntu16.04,Spark为2.1.0版本运行在Hadoop集群上,其依赖于Yarn,HDFS作为存储平台,采用Python语言进行实验编程。
4.2 评价指标
预测评分的精准度主要通过均方根误差(RMSE)和平均绝对误差(MAE)两种指标体现,两者的值越小,表示预测准确度越高。若pui表示预测评分,rui表示实际评分,N表示测试集中评分个数,有如下定义:
(13)
(14)
4.3 实验设计与结果分析
实验首先将评分数据集按照8∶2的比例划分为训练集和测试集,将训练集用于预测评分,测试集中的数据作为参考来评估算法预测的准确性。
设置两组实验,涉及到ALS算法时按经验选取迭代次数为20进行迭代直到收敛,lambda=0.01。
第一组实验比较传统的ItemBase CF与混合协同过滤算法IACF,固定ALS算法的隐藏特征数r,改变项目近邻数n分别进行实验,结果如图2和图3所示。
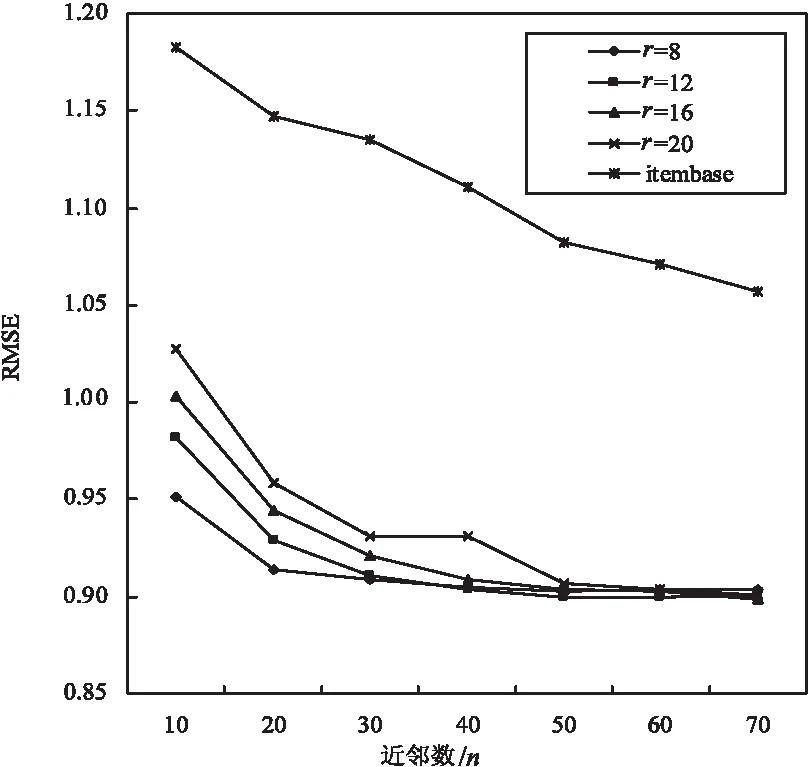
图2 Itembase CF与IACF算法的RMSE变化趋势
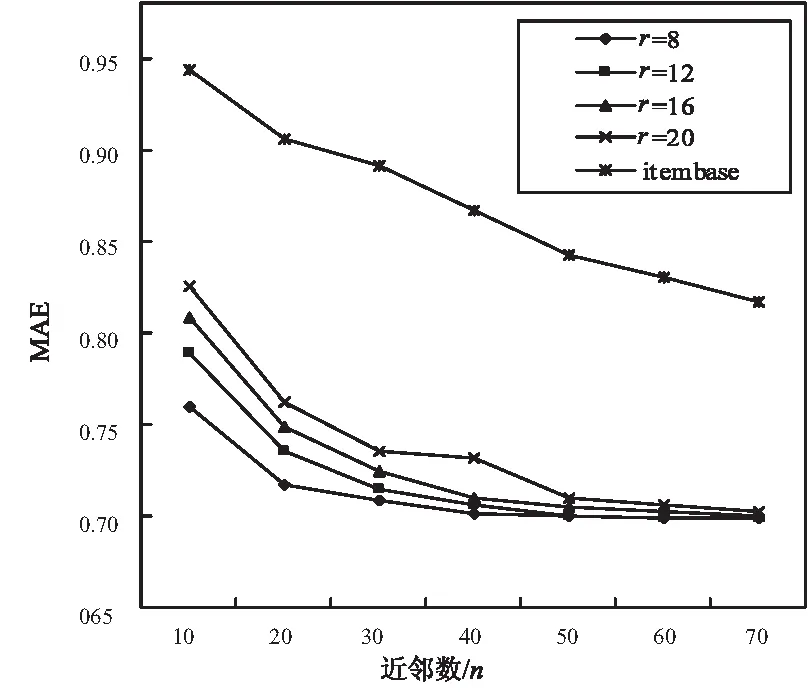
图3 Itembase CF与IACF算法的MAE变化趋势
从图中可以看出,传统ItemBase的RMSE最小值为1.053 7,MAE最小值为0.816 6,其变化趋势大致相同,都随近邻数n的增大而减小;而混合算法IACF的RMSE最小值为0.899 0,MAE最小值为0.698 2,二者均大幅度下降,推荐准确度明显提高,且与传统ItemBase算法的变化规律基本相同,随近邻数n的增加而减小,即λ的值越大,其RMSE和MAE越小,达到一定程度时趋于平稳。
第二组实验比较ALS协同过滤算法与混合协同过滤算法IACF,通过确定的项目近邻数n,调整隐藏特征因子r来分别进行实验,实验结果如图4和图5所示。
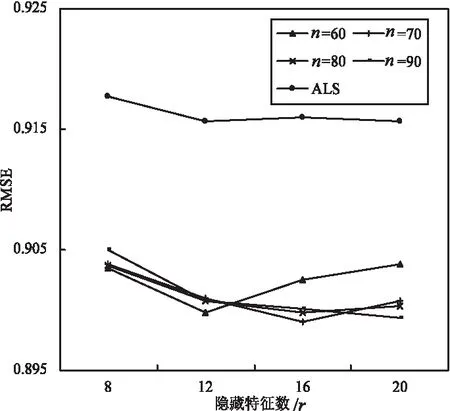
图4 ALS与IACF算法的RMSE变化趋势
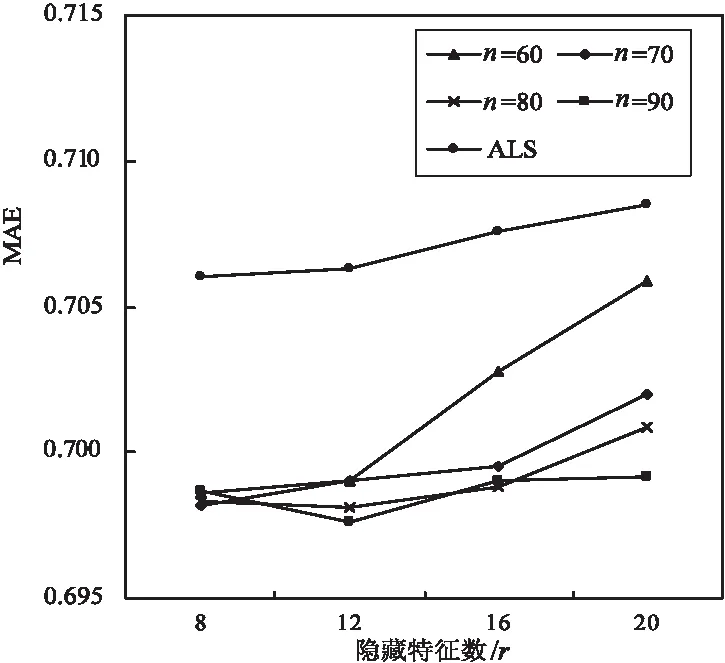
图5 ALS与IACF算法的MAE变化趋势
从图中可以看出,r=12时,传统ALS算法RMSE最小值为0.915 6,r=8时,MAE最小值为0.706;融合了ItemBase的IACF算法,其RMSE和MAE值均有所减小,RMSE范围在0.899 0~0.905 0之间,MAE值保持在0.697 6~0.705 9间,推荐准确度明显提高。
综合两组实验结果,混合协同过滤算法IACF在Spark上的实现保证了算法的可扩展性,动态加权混合提高了算法推荐的准确性。
5 结束语
文中实现了由单机环境到分布式平台的转变,并提出了一种混合协同过滤推荐算法IACF。该算法将ItemBase CF和ALS算法根据各自特点选取不同特征组合构造加权公式进行融合,通过调节不同参数来动态改变不同维度的权重,从而突出某一算法的特性,使得改进后的IACF能够满足不同需求。实验结果表明,IACF算法在分布式平台Spark上的实现提高了算法的并行性与可扩展性,同时在评分预测及推荐精度上也有所改善。
