基于城市群的铁路白货物流需求集聚方法研究
2019-09-27陈诚
陈 诚
(中国铁道科学研究院集团有限公司 运输及经济研究所,北京 100081)
0 引言
随着供给侧结构性改革不断深化,我国运输结构与特征发生快速变化,电子消费品、日用消费品、快速消费品等零散高附加值白货物流需求增长迅速。随着国家运输结构调整和大气污染防治等相关政策的推进落实,更多的公路白货物流需求将转移至铁路。“白货”特指除煤、石油、焦炭、金属矿石、钢铁、非金属矿石、磷矿石等大宗货物之外的品类。从客户角度分析,白货品类具有企业个体物流需求小、运到时限要求高、价格敏感性强等需求特点。从铁路角度分析,白货物流需求具有总量需求大、单个城市需求小、运输方向不平衡等特点。由于城市点对点的白货物流需求一般无法满足铁路货车成列开行的要求,而通过编组站进行多次车流集结会造成白货全程运到时效慢、时限不可控,致使铁路在白货物流市场缺乏市场竞争力。
近年来,针对铁路白货物流需求的研究,主要集中在货源需求组织的策略和手段方面。郑平标等[1]提出对于高附加值货物应通过开发适应的运输产品、保障运输能力、完善客户管理、制定灵活的运价政策来加强货源组织;崔德伟等[2]针对铁路白货客户采用的自营、外包和综合3种物流模式,提出与生产企业加强合作、建立物流配送中心、加强无轨站建设等相应的白货运输对策建议;张玉召等[3]探讨由铁路货运营销中心、第三方物流企业、铁路和第三方物流企业形成联合体组织货源等3种模式;杨文曦[4]针对铁路白货班列产品在管理模式、组织方式、时效评价等方面的不足,提出班列运到时效精益管理的建议;鞠蓓[5]分析了铁路白货运输运到时限超时的原因,提出运输组织、合理中转、分接口接车能力等方面的建议;宁荣[6]提出基于聚类算法的区域运输网络分析理论,解决集装箱办理站区域运输网络布局不均的问题。目前,从铁路白货物流需求现状出发,有效解决城市铁路白货物流需求不足的研究较少。从铁路物流需求数据入手,通过物流需求集聚手段,整合分散的铁路白货客户需求,集零为整,以支撑区域间白货物流产品的开发和运营。
通过分析铁路白货物流需求分布可以看出,发送到达地区需求量差异明显,个别区域间的需求较大,这些条件为铁路白货物流需求集聚提供了货源基础。此外,中国国家铁路集团有限公司在全国规划了208个铁路一级、二级物流基地,其中一级物流基地33个,服务于国家级流通节点城市,二级物流基地175个,服务于区域级流通节点城市,物流基地基本覆盖周围区域的白货物流需求。截至2019年4月底,铁路物流基地已建成136个,其中一级29个、二级107个。物流基地的建成运营,为白货物流需求集聚提供了重要载体。铁路班列化的运输组织模式,同普通货车编组集结的模式相比,具有明显的时效优势,速度标尺160 km/h的班列干线旅速能达到100 km/h,速度标尺120 km/h的班列干线旅速能达到60 km/h,远远高于编组货物列车的平均旅速,与公路运输相比具有一定竞争力,能够进一步吸引公路货源。因此,以铁路物流基地作为两端物流需求的集聚载体,组织开行大节点间班列化的白货列车,能够有效压缩全程时效,保持稳定的时限,解决目前白货物流时限过长且不稳定的弊端,满足白货客户的物流需求,因而提出基于K-means算法的铁路白货物流需求集聚方法,为铁路白货列车班列化开行提供有效的理论支撑。
1 铁路白货物流需求集聚方法分析
1.1 K-means聚类算法基本原理
聚类是一种无监督学习的方法,其实质是依据某种距离度量,把相似的对象放入同一集聚群中,把不相似的对象放到不同的集聚群中。聚类与分类不同,聚类不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记。聚类是观察式学习而不是示例式学习,它是从数据集中寻找数据之间的关系,使得同一类数据之间尽可能的相似,不同类别的数据最大化可能的相异,从而发现数据之间隐藏的有规律的信息[7]。聚类分析算法有划分法、系统聚类法、密度法、网格法、模型法、孤立点法、模糊分析法等。在处理大量的非空间数据对象时,划分法中的K-means算法能够快速收敛,是最常用的方法。
K-means算法是一种基于划分的聚类算法,K代表集聚群个数,means代表集聚群内数据对象的均值,通过设置不同的K值,来聚集距离较近的集聚群。K-means算法以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,越有可能在同一个集聚群。数据对象间距离的计算有很多种,通常采用欧氏距离来计算数据对象间的距离。欧式距离的计算公式可表示为

式中:distance(xi,xj)为第i个对象和第j个对象两点之间的欧氏距离,xi,xj分别为第i个和第j个数据对象;D为数据对象的属性个数;xi,d,xj,d分别为第i个对象和第j个对象在属性d上的值。
K-means算法根据预先设定的k值将样本分为k个群,每个群的均值用μk来表示,这些均值被看作每个群的中心。K-means算法的目的是要找到k个群中心,使得每个样本离集聚中心的欧式距离的平方误差之和最小,可表示为

式中:J表示样本离集聚中心的欧式距离的平方误差之和;N表示样本总数;K表示集聚群的个数;rnk表示第n个样本是否在第k个集聚群内,若在则为1,反之为0;xn表示第n个样本点;μk表示第k个集聚群的中心;Ck表示第k个集聚群的样本集合表示第k个样本群中的第i个样本点。
K-means聚类算法是首先随机选取k个评价对象作为模型的初始聚类中心,然后依次计算每个对象与各聚类中心之间的空间距离,依据每个对象与各个聚类中心之间的距离,将所有对象分配给距离其最近的聚类中心。每个聚类中心及分配给其的聚类对象分别代表一个集聚群。当全部聚类对象都被分配完毕后,表示一次计算结束,每个聚类的聚类中心由已经聚类分配的现有对象被重新计算。重复迭代此过程,直到达到最大迭代次数,或者两次迭代的差值小于某一阈值时,迭代终止,得到最终聚类结果[8-9]。K-means算法聚类流程图如图1所示。

图1 K-means算法聚类流程图Fig.1 K-means clustering algorithm flow chart
1.2 铁路白货物流需求集聚模型
以K-means算法聚类为核心,搭建铁路白货物流需求集聚模型,模型搭建思路如下。①确定集聚的基本单元。铁路日常以铁路局集团公司、站段、车站为管理单位,货票上的货物始发终到位置信息体现为所属的站段和车站。如果以车站为基本单元进行物流需求聚类,由于办理白货业务的车站有2000多个,会形成2000多个发到站之间的需求OD矩阵,数据复杂,并且部分车站名称较为生僻,聚类结果直观性不强。因此,提出以城市为物流需求集聚的基本单元,有效简化了数据,同时提高结果的直观性。②利用聚类算法将相邻城市合并为一个城市群,合并城市需求,形成城市群之间的OD需求。③通过设定城市间距离和需求量,筛选出符合条件的城市群间的白货品类流动的主要方向。
铁路白货物流需求集聚的具体流程可以分为数据采集、数据转换、数据聚类和结果输出4个步骤,具体如下。
(1)数据采集。①采集铁路物流需求数据。从货票信息中选取了物流需求聚类需要的核心信息,得到每单货票的货物品类、发送吨数、发站、到站等信息。②采集城市的位置信息。通过调用网络上公开的经纬度查询接口来获取全国城市的经纬度。
(2)数据转换。①建立车站与城市的对应关系。通过查询车站信息,同时比对铁路货运站分布图,明确每个车站所在的省份和城市,将货票上基于车站的货物信息转化为基于城市的货物信息。②建立城市间的物流需求流向表。将同属于一个城市的多个车站需求数据汇总,得到城市的铁路物流需求。将货票运量信息按照发送城市、到达城市和品类汇总统计,使得同一个城市多个车站的物流需求数据合并,得到以城市为基本单元的物流需求信息,进而建立城市间的物流需求信息表。
(3)建立基于城市群的物流需求流向表。结合之前采集到的到的城市经纬度信息,可以得到城市间的距离。按照K-means聚类算法要求,设定k个聚类群,通过迭代计算,整合相邻城市的物流需求,将全国划分为k个城市群,形成k个城市群之间的铁路物流需求,总计条物流需求线路。
铁路白货物流需求集聚流程图如图2所示。
2 铁路白货物流需求集聚实例应用及分析
2.1 实例应用
在铁路白货货源集聚问题中,将城市的经纬度作为位置信息输入,选取2017年全路车站白货业务运量数据作为物流需求数据输入,设定城市群数量为50,应用SPSS数据分析软件嵌套的K-means聚类算法对货运数据进行自动化聚类分析。为了进一步得到有效的白货货源集聚的城市群对,增加筛选条件,发送城市群至到达城市群总吨数大于100万t且运输距离大于800 km,符合筛选条件的白货运输城市群如表1所示。发送主要集中在东北、内蒙、华北等区域,到达主要集中在东北、西南等区域。铁路可以考虑在这些方向上重点组织开发白货运输产品。
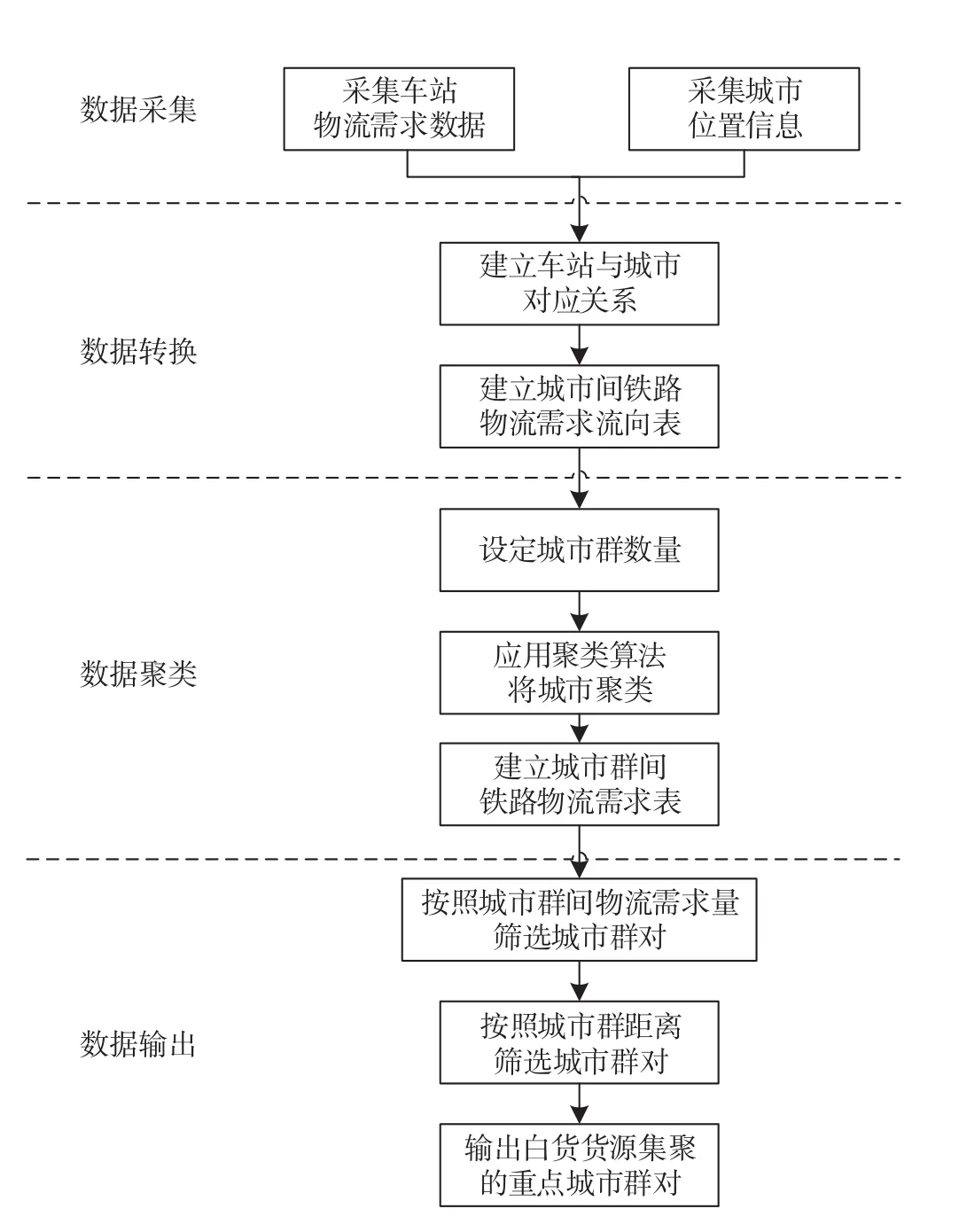
图2 铁路白货物流需求集聚流程图Fig.2 Flow chart of demand agglomeration of railway white goods logistics
2.2 结果分析
基于城市群的白货货源整列运输,有效压缩了干线运输时间。以黑龙江东部至辽宁西部线路为例,2个城市群中心城市距离约1200 km,120 km/h标尺快速列车平均时速60 km/h,铁路干线运输时间约20 h,两端群内城市对各自中心城市的最远距离取350 km,公路运输时间各约6 h,公路至铁路的短倒装卸作业时间取4 h,综合以上全程运输时间最大为40 h。采用普通货车运输方式,按铁路货物运输平均时速10 ~ 20 km/h计算,铁路运输需要60 ~ 120 h,加上两端短倒装卸各4 h,全程运输68 ~ 128 h。可见,采用货源集聚后,运到时限大幅缩短,同时通过班列化开行,时效稳定性得以保障。该线路班列开行,虽然增加了城市到中心城市货源集聚环节的费用,但通过集中分拨配送,能够有效降低短途运输成本,全程费用增加极为有限,且考虑到运到时限的大幅提高,抵消了费用增长带来的影响,运输综合质量明显提高。

表1 符合筛选条件的白货运输城市群Tab.1 White goods transportation city clusters meeting the screening conditions
2.3 保障措施
白货物流需求集聚后,为铁路长距离白货运输指明了线路方向和货源基础。要真正实现稳定的白货整列运输,还需要进一步考虑适合的品类和开行时段,选择适宜的装载车辆和物流基地,考虑客户对价格的承受能力,制订货源组织方案,为开发高质量白货班列提供保障。
(1)货源季节波动。部分白货的物流需求随季节变化比较明显,细致分析货源在不同时间段的发送运量分布,是合理制定、调整运输计划的基础,有利于保障货运列车的装载率。
(2)装载车辆要求。白货货源对装载车辆的要求各不相同,部分适用于集装箱运输,部分适用于棚车运输。由于目前120 km/h标尺的棚车和集装箱不能混编运行,因而需要对货源进行筛选,形成单一的快速棚车列车或快速集装箱列车。
(3)物流基地能力。根据中国国家铁路集团有限公司发展铁路物流基地的思路,物流基地主要承担白货的“运仓配”业务,因而白货货运班列两端发到主要依靠物流基地。在选中的城市群中,选择地理位置离主要货源地较近、具备整列开行能力、设施设备条件良好、集疏运便捷的物流基地作为发到两端的作业场所。
(4)全程物流质量比选。物流需求集聚在两端增加了集聚的作业环节,导致物流费用有所增加,因而需要全面权衡全程物流费用与时效的变化,按照客户的反馈筛选出对运输时效要求较高的货源,根据需求规模合理制定开行方案。同时考虑在开行初期对远距离集聚的货源进行补贴,鼓励客户选择班列化的货运产品。
(5)货源组织能力。货源统一集聚在物流基地,发到两端均增加了物流基地至企业仓库、转运中心的短驳运输环节。要加强与优质社会物流企业的合作,发挥公路灵活便捷的优势,通过公路运输提高货源集聚的效率,减少环节增加带来的影响。
3 结束语
随着国家产业布局优化、能源结构调整,煤炭为代表的大宗货物运输需求增长幅度有限,未来铁路增量将更多依赖提高铁路在白货物流市场的份额。通过K-means聚类算法实现基于城市群的铁路白货物流需求集聚,有利于铁路组织开行点对点开行白货班列,有效压缩全程运到时效,提高货运产品服务质量,进而提高产品的市场竞争力,吸引更多的公路物流需求转向铁路,由铁路主要负责大节点的干线运输,公路负责两端近距离的分拨和“最后一公里”的配送,充分发挥各种交通方式的优势,实现各种交通方式合理分工,促进各种交通方式的融合发展[10]。
