基于Mahout的图书推荐系统研究
2019-09-18杨云李文如
杨云 李文如
(陕西科技大学电子信息与人工智能学院, 西安 710021)
随着计算机与网络信息技术的快速发展,纸质图书明显具有向电子化方向发展的趋势,电子图书逐渐流行。在这种情况下,如何便于大部分用户在图书资源中快速查找图书,成为对图书检索能力的巨大挑战[1-2]。为了使检索系统更具便捷性和智能化,避免图书资源的浪费,提高借阅管理效率,建议进行用户个性化推荐设计。本次设计的图书检索推荐系统,将图书检索推荐系统总体功能分为图书检索排序模块和图书智能推荐模块,能够根据读者的借阅习惯进行图书推荐,满足不同读者的借阅需求。
1 系统设计
1.1 系统功能总体设计
本系统中设计了智能图书推荐模块,可根据搜索信息分别提供图书推荐。根据读者检索内容,向读者推荐相关图书,或根据读者借阅历史推荐图书。该系统的整体功能结构如图1所示。
用户在图书检索界面输入关键词进行检索。如果检索到的图书数量大于1,则启动智能排序算法,对图书进行排序,并根据检索结果调用图书推荐模块,将排序推荐结果反馈给用户。若用户输入检索结果为0,则启动图书智能推荐模块,根据用户借阅历史推荐相关图书,将结果列表反馈给用户[3-4]。系统的总体流程如图2所示。

图1 系统整体功能结构
1.2 建立系统数据库
1.2.1 数据的预处理
图书智能检索系统的设计中运用了2种算法,即多维度评分算法和检索结果优化算法。这2种算法中都需要以数据库信息系统中的借阅记录为基础,进行数据挖掘。借阅记录表中会存在一些无效数据,必须将其剔除,以保证算法执行结果的正确性[5]。此外,还需处理表中的噪声值,保存最新的借阅数据。例如,有用户在不同的时间借阅了同一本图书,所造成的数据重复即噪声,应将其剔除,并保存最新数据。
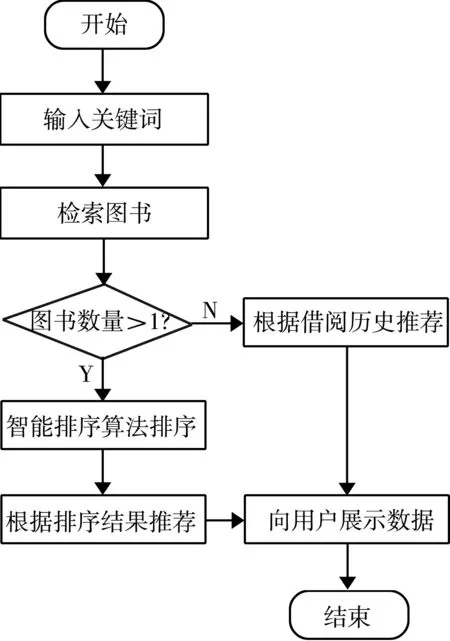
图2 系统总体流程
1.2.2 数据库设计
在图书智能检索信息系统中,与智能检索推荐模块和结果优化模块相关的数据库表有t_book(图书基础信息表)、t_bcatalog(图书副本信息表)、t_blend(图书借阅表)、t_reader(读者信息表)。图书基础信息表主要包括图书的简要介绍,以及用于排序的偏好系数。图书副本信息表主要包含图书馆中相关书籍副本的具体信息,图书借阅表主要包括书籍借阅的具体信息。读者信息表主要包含读者的基本信息资料。这几种数据库表的关系如图3所示。
1.3 系统检索结果的优化
检索结果优化算法,基于用户的累计借阅数量计算得出,因此,需先处理数据库中的借阅记录数据。然后,借助相应的算法计算出用户对相应图书的偏好系数。最后,将对用户检索图书的偏好系数进行排序,推荐图书,提高用户的检索效率[6-7]。优化算法的具体处理步骤如下:
(1) 对借阅数据进行预处理。对管理系统中的借阅记录数据进行预处理,去掉噪声数据,对不完整数据进行修正和补充。
(2) 对偏好系数进行计算。基于借阅历史数据,利用检索结果优化算法计算用户的偏好系数,将偏好系数存入偏好系数数据表中[8]。
(3) 对检索结果进行优化。用户检索图书列表时,系统会根据数据库中计算保存好的偏好系数对检索结果进行优化排序。
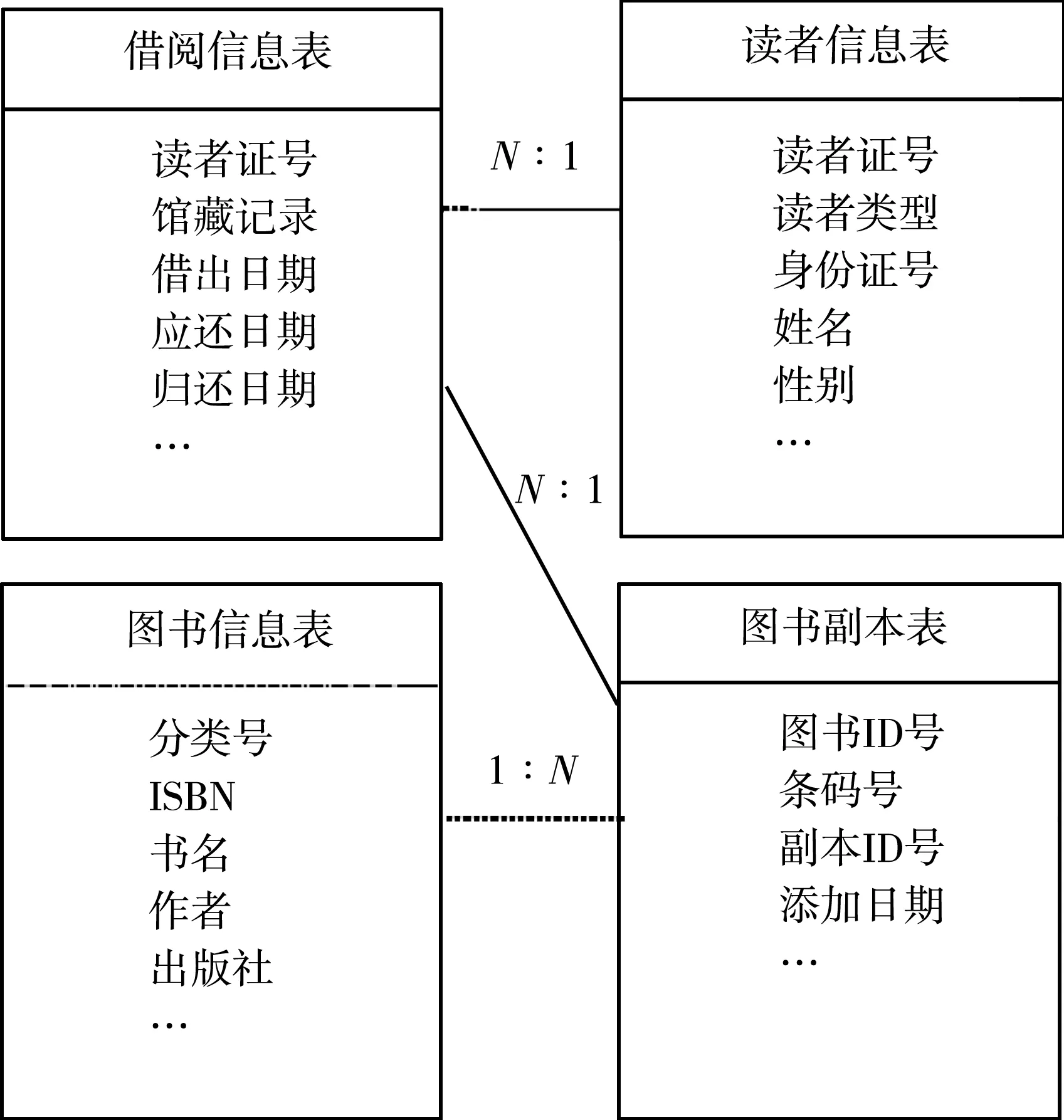
图3 数据库表的关系
2 图书推荐系统的实现
2.1 计算评分数据
借助多维度评分算法,汇总系统中的借阅记录评分数据,形成协同过滤推荐算法所需的基础数据。当前常用的协同过滤算法(Distributed Item-Based Collaborative Filtering)都是借助于用户评分数据来实现数据推荐的[9]。基于用户的协同过滤推荐算法的原始数据为
2.2 利用Mahout实现图书推荐
2.2.1 算法实现过程
在Mahout中,协同过滤算法的实现共包含以下过程:
(1) 求出用户矩阵。
(2) 求出项目矩阵。
(3) 求出项目矩阵的平方和。
(4) 根据项目矩阵平方和、项目矩阵计算得出项目相似度矩阵。
(5) 对项目相似度矩阵和用户矩阵进行整合,得到用户-项目相似度矩阵。
(6) 根据上一过程中得到的用户-项目相似度矩阵计算出用户推荐矩阵。
以上过程中用了7个Job任务来进行数据处理。其实,第一个Job任务是进行项目的数据格式转换,即将项目的编号由长整形转换为整形[10]。
2.2.2 数据量流程分析
(1) 用户矩阵。用户矩阵计算,就是对数据的抽取。针对用户-项目-评分原始数据,整合同一个用户评价过的所有项目。借助表2中的原始数据,通过数据抽取后得出用户矩阵(见表3)。

表2 用户-项目-评分原始数据表

表3 用户矩阵表
在表3所示的用户矩阵表中,itemID ∶prefValue表示向量,itemID是该向量的下标,prefValue是其取值。因此,对于用户1来说,其用户向量的实际表示应该是[5.0,3.0,2.5,0,0,0,0] ,从下标101开始,如果没有数据则标为0。Mahout中使用了一个Job任务来完成上面的数据处理,输出的KeyValue对的格式是
(2) 项目矩阵。选取不同的抽取规则,可以得到相应的项目矩阵。表4所示为可以抽取得到的项目矩阵。在Mahout中,使用了一个Job来完成,输出的KeyValue格式是

表4 项目矩阵表
(3) 项目矩阵平方和。针对上述的项目矩阵,在Mahout中使用另外的Job任务来对其进行处理,得到项目矩阵平方和[11-12],如表5所示。

表5 项目矩阵平方和表
其实项目矩阵平方和就是针对每个项目向量,求其所有项的平方和而已。比如,针对项目101,其项目向量为[5.0,2.0,2.5,4.0,5.0],然后求其平方和,得到其值为76.25。
(4) 项目相似度矩阵。在Mahout中,项目相似度矩阵式由2个Job任务共同处理完成的。第1个Job 是项目之间的相似度,按照升序对项目进行排列。首先针对项目101进行计算,紧接着对项目102进行计算,按照顺序往下类推[13]。由于在计算项目101时已经对101和102的相似度进行了计算,因此在计算102与其他项目的相似度时就不再考虑 101项目。第2个Job就是续接,即把没有计算的项目也加入到其他项目中。如,在项目101中有101和102的相似度,但项目102中并没有项目102和项目101的相似度;因此,可在102项目中续接101项目中的101与102相似度。按照此算法,最后输出的项目相似度矩阵如表6所示。
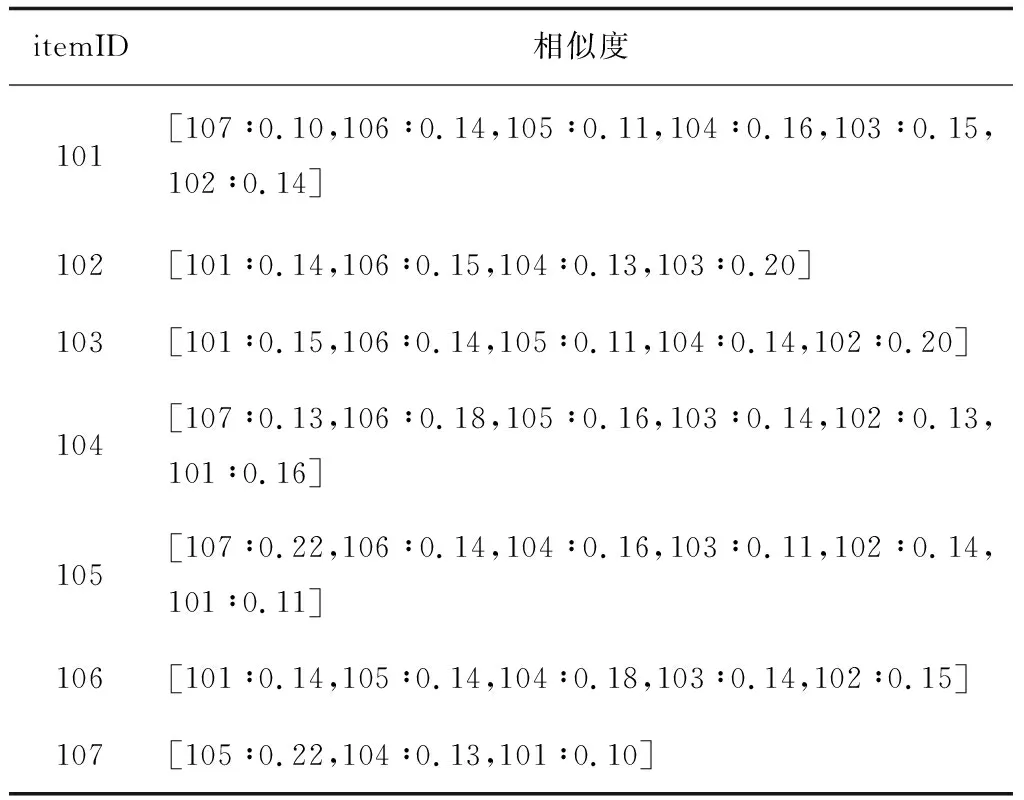
表6 项目相似度矩阵表
项目相似度的计算公式为(1)和(2):
(1)
(2)
式中:PuiI1表示用户ui对项目I1的评分;PuiI2表示用户ui对项目I2的评分;normsI1表示norms中与I1相对应的平方和。
假设有项目102和103,其中:
102矩阵=[5 ∶3.0,2 ∶2.5,1 ∶3.0]
103矩阵=[5 ∶2.0,4 ∶3.0,2 ∶5.0,1 ∶2.5]
可以得到dot102×103=26.00,norms102=24.25,norms103=44.25。带入式(2),可以得到simi102×103=0.20。由此可见,计算得到的项目相似度与表6中的数据相同。
(5) 用户-项目相似度矩阵。用户-项目相似度矩阵,即将用户和项目相似度矩阵进行拼接得到的矩阵[14-16]。在Mahout中使用了一个Job来处理,输出keyvalue对的格式〈VarlntWritabe,VectorAndPrefsWritable〉,即用户对应的输出格式是VarlntWritabe,用户-项目相似度矩阵的格式为VectorAndPrefsWritable,拼接后的用户相似度矩阵见表7(表中仅仅展示用户1)。
(6) 用户推荐矩阵。在Mahout中使用了一个Job任务根据上述用户-项目相似度矩阵来计算用户推荐矩阵,最后得到的结果如表8所示。

表7 用户-项目相似度矩阵表

表8 用户推荐矩阵表
表8中的矩阵数据是通过式(3)采用表7数据计算而得:
(3)
式中:simiIm是Ui针对Im的相似度矩阵,prefIm是Ui针对Im的评分。
对所有的用户而言,利用上面的公式,执行完毕后就可以得出相应用户的推荐矩阵数据。
3 结 语
在基于Mahout的图书智能检索系统中,图书检索排序算法和图书智能推荐功能,构成系统的关键构成部分。文中介绍了该系统的总体设计和工作流程,以及数据库的详细结构,重点阐述了图书检索排序算法及图书智能推荐的实现,以及Mahout中协同过滤算法的应用。图书检索排序算法和图书智能推荐的实现构成了图书智能检索中最关键的部分,为整个系统提供主要的功能支持。
