基于HOG特征的学生课堂状态检测研究
2019-09-18陈杰谢日敏
陈杰 谢日敏
(1. 福建商学院信息技术中心, 福州 350012; 2. 福建商学院信息工程系, 福州 350012)
物体检测是计算机视觉研究中的经典内容之一[1]。物体检测与图像分类,二者相辅相成。应用物体检测技术,可以从包含若干待测物体的图像中裁剪出这些物体。应用图像分类技术,可以对需裁剪的整张图像进行分类识别[2]。目前,物体检测与图像分类技术已应用于学生课堂状态评价。通过教室摄像头获取的图像,可检测出每个学生听课状态的子窗口;进而运用基于深度学习的神经网络算法,识别出每个学生的行为状态,如听课、看书、记笔记、交头接耳等。本次研究中,主要基于HOG特征,探讨学生课堂状态检测算法。
1 HOG特征提取
图像特征是物体检测的基础,计算机需要通过提取图像的某些特征对其进行识别。物体检测需提取的图像主要特征有多种,包括HOG特征、局部二值特征、Haar特征、尺度不变特征变换特征等[3-9]。上课过程中,人体大致上保持同一姿势,虽然存在细微的肢体动作,对检测结果影响不大。参照行人检测方法,在此以HOG特征作为检测特征。通过计算图像局部区域的方向梯度直方图来构建图像特征,在图像的几何和亮度变化过程中可保持较强的稳定性,图像局部目标及其表象、形状,能够通过梯度和边缘的方向密度分布来描述。HOG特征提取步骤如下:
(1) 对图像进行灰度化、标准化(归一化)处理。调节图像的对比度,减少图像局部的阴影和光照变化所造成的影响,同时抑制噪声的干扰。
(2) 计算图像中每个像素的梯度(包括大小和方向)。从图像像素梯度数据中获取轮廓信息,以进一步削弱光照的干扰作用。
(3) 将图像划分成同像素的若干个小单元。统计每个单元的梯度直方图,将梯度的方向离散为N个区间,利用梯度的大小加权投票产生N个条目的统计直方图,形成每个单元的特征。
(4) 将几个单元组成1个块。合并各单元直方图能量,在块中对每个单元进行标准化处理。通常单元可以在不同的块中出现,但对其标准化处理是在每个块中分别进行。这些块每滑动1个单元就生成1个新块,每个单元会在不同块中出现,其标准化后的特征值是不同的。同一个块内所有单元的特征串联起来便形成该块的HOG特征,如图1所示。
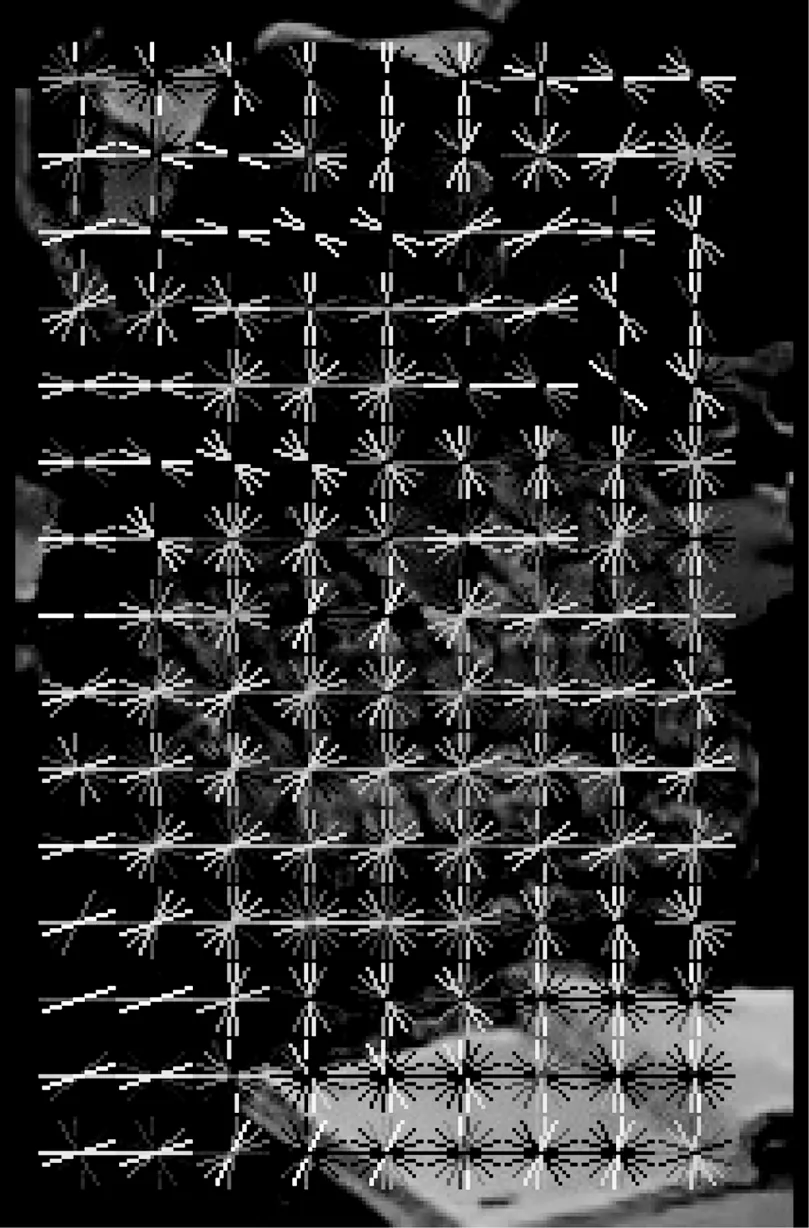
图1 图像中每个块的HOG特征
(5) 串联HOG特征,得到特征向量。将图像内所有块的HOG特征串联起来,就可以得到该图像的HOG特征。这个就是最终可供分类使用的特征向量了。
2 分类器训练
图像检测中常用分类器包括SVM支持向量机、神经网络、随机森林、Adaboost分类器等[10]。在此我们运用Adaboost分类算法进行数据训练。大量多尺度区域需要检测分类,并且不同区域的检测难度均不相同。在检测背景上,对非目标易进行判断,而针对实际目标附近区域与其他复杂区域的检测判断需谨慎。Adaboost算法在检测图像中具有天然优势,使得检测变得快速有效。在通过每个弱分类器后进行一次判断,面对简单背景通过几个弱分类器就可判断出非目标,而面对复杂区域则要通过多次判断后得出结论。
2.1 Adaboost算法
Adaboost算法是基于比较粗糙集的弱学习算法,通过改变训练数据的权值分布及迭代学习,组合这些弱分类器,最后构成一个强分类器。常见分类算法基本上都可以作为弱分类算法,通常以决策树为弱分类器进行分类检测。人物检测的Adaboost算法如下:
输入:训练数据集T={(x1,y1),(x2,y2),… ,(xN,yN)},yi∈{-1,1};弱学习算法。
输出:强分类器。
(1) 初始化权重D1=(w1,1,w1,2,…,w1,i,…,w1,N),w1,i=1N,i=1,2,…,N。
(2) form=1,2,…,Mdo
① 使用权值为Dm的训练数据集训练基本分类器Gm(x)。
② 计算Gm(x)的分类误差率:
em=P[Gm(xi≠yi)]
③ 计算Gm(x)的系数αm:
④ 更新训练数据集权值分布:
Dm+1=(wm+1,1,wm+1,2,…,wm+1,i,…,wm+1,N)
(3) 基本分类器组成强分类器:
其中,I[Gm(xi)≠yi],表示Gm(xi)≠yi时分类结果为1,否则为0。 正常情况下二分类基本分类器的分类误差率em≤12。 此时αm≥0,随着em增大和αm减小,分类误差率越大的基本分类器在最终的强分类器中的作用越小。在更新权值分布时,被基本分类器误分类样本的权值被放大,而正确分类样本的权值缩小,从而使误分类的训练样本在下一轮学习中起到更大作用。
2.2 评价标准
以准确率(Precision)和召回率(Recall)作为评价标准,并组成混淆矩阵(见表1)。

表1 混淆矩阵
其中Positive与Negative分别表示判定为正负样本的分类标记,True与False则分别表示预测正确与错误。
2.3 级联分类器设计
在图像识别中,检测目标的数量远远小于非目标的数量。尽量识别出多的目标图像,即提高召回率,但在提高召回率的同时准确率却又会下降。针对此矛盾,可以训练多个强分类器,级联这些分类器[11],其检测流程如图2所示。在每一级分类器中,将检测结果的正样本传入下一级,负样本直接丢弃。这样,在提高准确率的同时也保证了检测速度,明显的非目标在级联分类器的前几级强分类器检测中就被丢弃,而不会被传到后面更复杂的分类器。只要每级样本保持较高的召回率,最终的召回率也会比较高,准确率也将大幅提升。
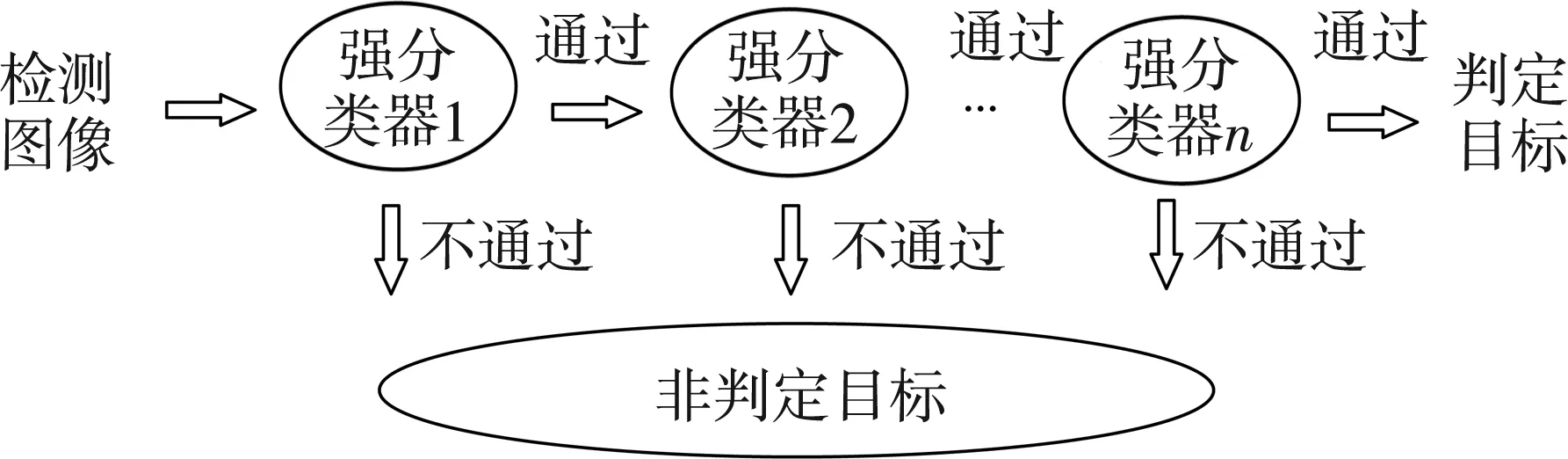
图2 级联分类器检测流程
在级联分类器的构建过程中,从某一个强分类器开始,若准确率和召回率还未达到预期值,即训练并添加一个强分类器。每级强分类器的训练样本,并不使用原始的正、负样本,而选择上一级强分类器通过判定的样本。其中,分类正确的作为正样本,分类错误的作为负样本,于是当前分类器将更加注重那些之前分类器不能区分的样本。
3 检测过程
3.1 图像金字塔滑动窗口检测
在得到分类器后,从待测图像中检测并定位出目标,需要对每个区域逐一进行识别。为了在检测中匹配物体大小的变化,在滑动窗口时,不能只用一个固定大小的窗口,窗口大小应可变,这种方法被称为分类器金字塔。如果窗口大小固定,而图像大小逐渐变换,则被称为图像金字塔。
3.2 后期处理
得到检测框时,如果检测框的大小和位置与实际物体不相匹配,我们可以对检测框进行微调,如收紧、扩大、移动等。这种变换被称作外边框回归(Bounding Box Regression)[12],该技术已经成为各种物体检测框架的默认组件。检测结果中,面对某一个物体可能会输出很多检测框,需使用非极大值抑制(NMS)进行后期处理,以消除重复检测框。
4 实验结果与分析
4.1 数据来源与预处理
通过架设在每间教室讲台上方的摄像头,可以获取学生课堂教学视频。从视频中提取图像,视频可以根据每帧的变化区分并排除背景区域,对人物进行粗略定位[13]。常用的算法有光流法、帧间差分法、背景消除法等。上课时学生运动较少,因此,根据帧变化进行定位检测的效果不够理想。在此,我们只重点考虑图像级数检测,而暂时不考虑对视频流的处理。
学生课堂状态检测分类器训练流程是:首先,从监控图像中手动选取固定大小的图像块,每个图像块对应一个学生的完整课堂状态,并标注为正样本,并从监控图像中选取不含学生的背景作为负样本;然后,针对图像进行特征提取,采用HOG特征进行训练。
取1 000张学生听课图像作为正样本,每张监控图像可以提取多张清晰图像。改变图像大小,统一调整为32px32px像素。从监控图像中选取无学生头像的背景图像,通过程序自动裁剪成固定大小作为负样本,一张背景图像可裁剪出多张负样本。
4.2 实验结果与分析
使用1 000张学生听课图像作为正样本,设置分类器级数为14级。学生课堂状态级联分类器检测结果如图3所示。从检测结果来看,剔除图中后三排学生图像,因其离摄像头太远以及与背景颜色相近无法检测。其余学生图像均可检测到,检测准确率也较高。另外,靠窗侧因距离摄像头较远以及图像角度等原因,有可能会将2个学生检测为同一个。对于这种情况,可以增加这些角度学生的训练样本,或提高图像分辨率。

图3 学生课堂状态级联分类器检测结果
截取了20张不同班级的学生上课图像。其中,剔除距离摄像头较远学生的图像后,检测到总的学生人数为529人,漏检人数为107人,错检人数为93人。召回率为79.77%,准确率为81.94%。
5 结 语
目前,图像物体识别检测、表情识别及深度学习等已成为计算机视觉技术研究热点。将计算机视觉和深度学习技术应用于课堂评价,有两方面优势:一方面,有效地挖掘了潜在的视频数据;另一方面,节省人力,且评价结果客观性较强。应用本次提出的基于HOG特征的学生课堂状态图像检测方法,可检出每个学生听课状态窗口,为后续行为状态识别提供基础数据。基于卷积神经网络的物体检测算法,是今后物体检测研究的发展方向,我们将在下一步探讨其对于课堂监控图像的检测识别。
