基于Avro的异构信息源转换传输中间件设计*
2019-09-18宋铭涛吴文江
宋铭涛,吴文江,胡 毅
(1.中国科学院大学,北京 100049;2.中国科学院沈阳计算技术研究所,沈阳 110168;3.沈阳高精数控智能技术股份有限公司,沈阳 110168)
0 引言
数字化车间是“工业4.0”发展和中国“2025 智能制造”实现的基石,其中对数字化车间信息采集和集成是建立数字化车间的重要基石。数字化车间的各种设备信息的采集主要有两种采集方式,一是直接采集设备信息,二是对控制设备的相关信息进行采集从而间接获得要采集设备的信息。通过对所采信息进行汇总处理从而实现设备的掌管控制。由于车间设备种类繁多,通信方式多样,故采集出来的信息多种多样,存在不同的数据格式,进而导致数据处理阶段复杂度高、扩展度低等问题。数字化车间中异构信息源的异构主要体现在数据,而数据的异构性主要体现在:
(1)系统异构:数据源所依赖的设备系统、所使用的数据库系统、操作系统以及所操作的文件系统之间不同。
(2)结构异构:不同的厂商提供的设备中所提供的接口不同,导致数据产生的格式结构不同。为了兼容之前旧设备和扩展新功能,会导致数据在设备更新之前之后不尽相同。
(3)来源异构:同一数据属性来源于不同的设备提供者。
针对异构信息源的转换传输问题,传统的方式是采用数据库解决,近些年来,常用的解决方式有:基于微软的COM/DCOM技术、基于CORBA体系架构、基于设备所依赖的协议或者基于知识的信息集成。但这些处理方式大都要求特定的语言、特定的平台或者特定的系统架构。从数字化车间发展的趋势以及在当前大数据时代背景下,信息源无论是数据量级或形态都在不断地变化、增长,现有的这些解决方式呈现出难以增加新种类数据源和满足可扩展性、可跨平台等要求的缺陷。
通过对现有的数字化车间异构信息源采集、传输和集成等相关技术的研究,从信息源数据入手,提出了一种基于Avro的异构信息源转换传输中间件架构,并根据该架构,采用IDL定义了语言传输规则,采用设计模式思想构建实现了基于Avro的异构信息源转换传输中间件,该中间件可实现将不同类型数据转化成统一的二进数据进行传输,在传输之后又可以从二进制数据中快速恢复传输的原始数据。并且,由实验结果表明基于Avro实现的异构信息源转换传输中间件可跨平台、可跨语言、可集成、可高效的描述和无损转换传递信息,进而获得可靠的解析结果,可以有效地解决数字化车间异构信息源的转换传输问题。
1 关于Avro技术
Avro全称为Apache Avro,是一个数据序列化反序列化系统框架。Avro拥有丰富的数据结构和属性。Avro依赖模式(Schema)实现数据结构定义。模式可类比为Java或者C#中的类,它定义了转换传输的信息结构。类比可根据类产生任意多个实例对象,Avro将传输转换的信息包装成信息实例进行必要的操作。此外,信息实例在序列化和反序列化操作时必须需要知道它的基本结构,在这里,信息实例是根据模式产生的信息对象,因此,每次序列化或者反序列化时都需要知道当前信息所使用模式的具体结构。
Avro以动态类型、无标记数据以及当数据模式发生变化,处理数据时总是同时提供新旧模式来做差异分析,无须手动处理的显著特点。
1.1 Avro RPC
Avro RPC(Avro Remote Procedure Call)是Avro功能特性和RPC(Remote Procedure Call)远程过程调用结合的产物,两者优良特性强强联合,在通讯程序之间携带信息数据的方式、特性使得Avro在分布式等诸多领域应用广泛。同时,数字化车间未来的发展趋势是云制造,智能制造,到时将面临海量数据的异构问题,而Avro技术诞生之初就是为了解决大量数据的问题,因此会有很好的契合。Avro RPC抽象数据流传输在C/S软件框架下如图1所示。
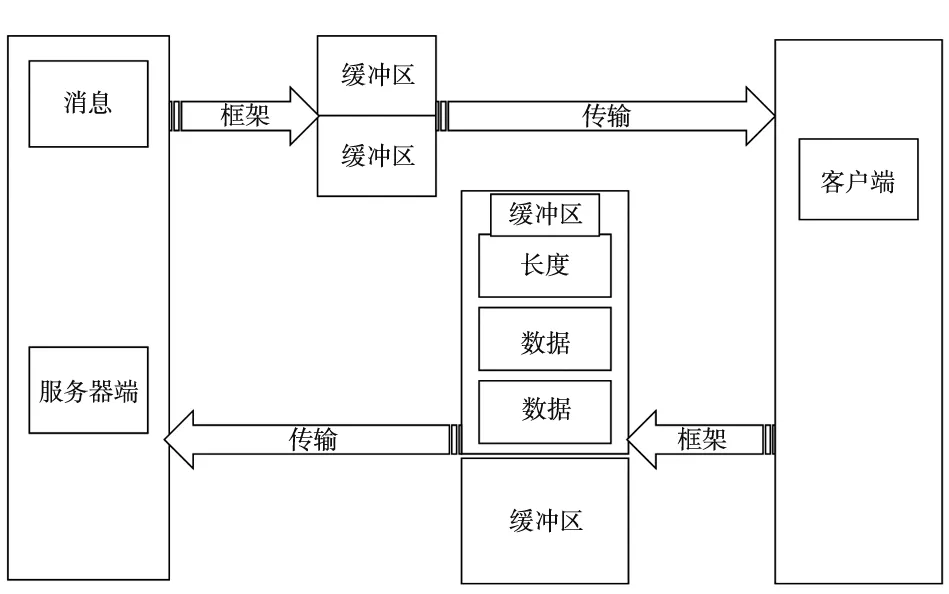
图1 Avro RPC抽象数据流程
1.2 Avro的应用原理
本着约定大于配置,可大量减少配置相关工作的原则,Avro在应用时必要的工作流程如图2所示。
其工作流程可总结描述为:
(1)设计所需要的服务。
(2)根据设计的服务,编写Avro IDL服务描述文件,即模式。
(3)根据编写Avro IDL服务描述文件使用Avro提供的代码生成工具生成所需的服务代码。
(4)根据完成服务的业务逻辑编写完整的服务代码。
(5)运行服务。
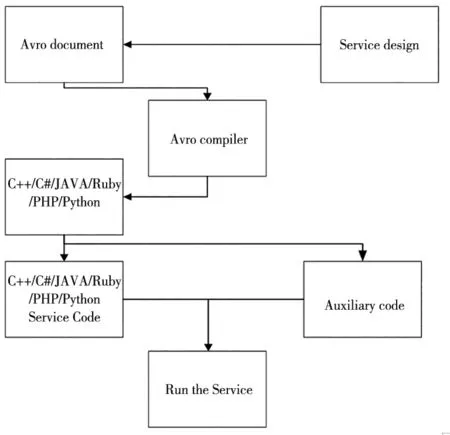
图2 使用Avro的工作流程
2 基于Avro异构信息源转换传输中间件架构设计
该中间件架构按照异构信息源中数据流的输入、处理、流出,可分为异构数据流接入层、序列化编码层、反序列化译码层、数据交互输出层等,如图3所示。

图3 数据流下中间件架构图
异构数据流接入层负责与数据采集端或者其他提供数据的接口进行交互,其主要工作是根据要传输的信息定义模式,为序列化编码层做必要的准备工作;序列化编码层负责将要转换传输的数据按照模式的结构进行组织,并进行序列化编码;反序列化译码层负责从序列化的数据流中恢复原始数据信息;数据交互输出层负责将恢复的信息进行交互输出或者和其他处理模块进行对接。
3 中间件组件的详细设计
该中间件转换传输数据的流程为:根据要转换传输的信息定义模式,通过序列化编码层将要传输转换的数据序列化为二进制数据或者JSON数据流进行传输,转换后的数据传输到需要的模块,经过反序列化译码层和数据输出层从二进制流或者JSON数据流中恢复原始的数据信息。
根据该中间件架构设计以及采用C/S软件架构实现的基于Avro的异构信息源转换传输中间件主要包含两个模块4个层,一个是Server端,包含异构数据源接入层和序列化编码层;另一个模块是Client端,包含反序列译码层和数据交互输出层。
3.1 异构数据流接入层
数据接入层主要任务是定义模式,以传输数控机床设备信息为例。
模式定义为:
@namespace("CNC_machine.DTO")
protocol CNCProtocol {
import idl "ProjectDTO.avdl";
record CNC_machine_Item {
string index;//索引编号
string attributeType;//属性类型
string attributeName; //属性名称
string accessLevel;//访问权限
double value;//属性值
int state;//状态位
}
}
由于数据在序列化之后是以二进制数据流或者JSON数据流进行传输的,必须保证数据结构的统一,因此在数据接入层进行预处理校验。基于事实分析和依据所校验数据的最终结果状态呈现有限性,故采用基于有限状态机的方式对接入的异构数据信息进行检测过滤,包含对数据的有效性和完整性进行决策判断,数据接入层的异构数据流状态如图4所示。
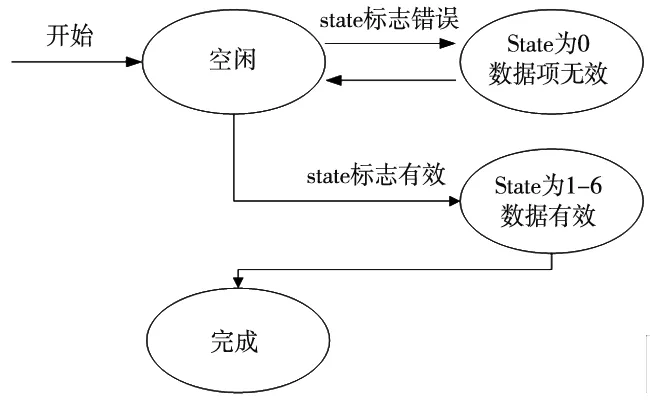
图4 异构数据流接入层状态图
3.2 序列化编码层
序列化编码层是中间件的核心部分之一,在编码之前首先判断数据内容是否合法,能否统一被模式所表示至关重要,虽然数据已经在接入层预校验过,但为了在序列化操作之前,数据项中数据有一个良好的组织方式,所以在软件设计实现过程中,采用静态工厂的设计模式,设计通用的数据组织方式接口,默认实现采用的是XML文件配置方式。采用具有自描述性和具备强可扩展的XML配置文档进行功能封装,可跟随要序列化传输的数据项的变化而稍作修改,同时数据的有效性、完整性等也可通过此种方式进行二次校验。
中间件详细的组件设计如图5所示。
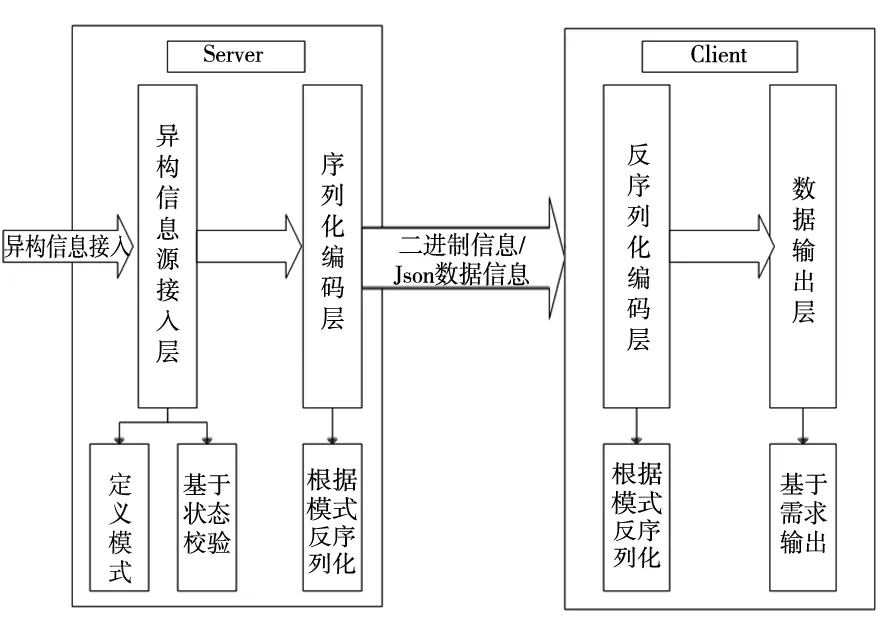
图5 中间件架构
XML的设计使用。通常情况下描述组织传递的信息,一般采用硬编码的方式严格定义信息结构,此种方式下编写的代码实现信息传输不具有广泛适用性,不便于扩展,而基于XML配置文件的方式可描述数据中字段属性等抽象化信息,可以定义统一的数据传输格式,使得信息的结构组织方式随着接入层中模式定义的改变而改变,扩展性强,当接入层模式改变,只修改XML文档中元素的属性值即可。此种方式,在相关领域软件的解析中应用较多。
当传输转换数据的模式定义完成以及数据的组织方式确定之后,以数字化车间中采集到的数控机床信息为例,序列化过程核心伪代码如下:
Serialize(T thisObj)
ms <- new MemoryStream
enc <- new BinaryEncoder(ms)
//Schema即是数据接入层中定义的模式
writer <- new SpecificDefault
Writer(thisObj.Schema)
writer.Write(thisObj, enc)
return ms.ToArray()
3.3 反序列化译码层
反序列化译码层其主要功能可总结为对上层进行序列化编码的数据执行逆操作,以得到传递的真实数据信息。基于Avro封装的功能核心伪代码如下:
Deserialize(byte[] bytes)
dec <- new BinaryDecoder(ms);
regenObj <- new T();
reader<-new Specific
DefaultReader(regenObj.Schema,
regenObj.Schema);
reader.Read(regenObj, dec);
return regenObj;
3.4 数据交互输出层
数据交互输出层主要功能是在反序列化译码层得到的真实信息数据之后,以这些数据为基础,根据需求进行格式化输出,以便与下一个数据流程模块进行对接。需求取决于使用场景,具体参考下一章。在异构信息数据流接入层中,使用模式定义的数据结构可以简化数据在序列化编码层的相关操作。而在数据交互输出层则侧重于将反序列化译码取得真实数据根据下层需要设计相应的数据输出格式。当输出对接的是网络访问时,输出JSON格式的数据是较好的选择,而当无具体要求时,可根据模式以XML格式或者文本格式生成反序列化译码所得到的真实数据。
4 中间件的使用和使用场景
中间件在设计上采用C/S设计模式,中间件的Server端对应异构数据接入层和序列化操作编码层;Client端对应反序列化编码和交互数据输出层。根据设计使用时所依赖的设备类型和设备的开放程度,中间件可分为两种类型,内置式和外置式。
内置式需要输出数据源设备的底层源码支持,故应用场景有限,而外置式更接近中间件的本质,只要设置好工作环境,即可承担起本身的主要功能。在数字化车间实际使用场景中可以根据需求,选用其中一种或者两种类型组合使用。
内置式将数字化车间设备的信息根据定义的传输模式直接进行序列化传输,但它依赖于数字化车间中设备的底层源码支持,通过设备提供的内置调用接口获得数据信息,之后依据模式组织与传输数据。架构图如图6所示。
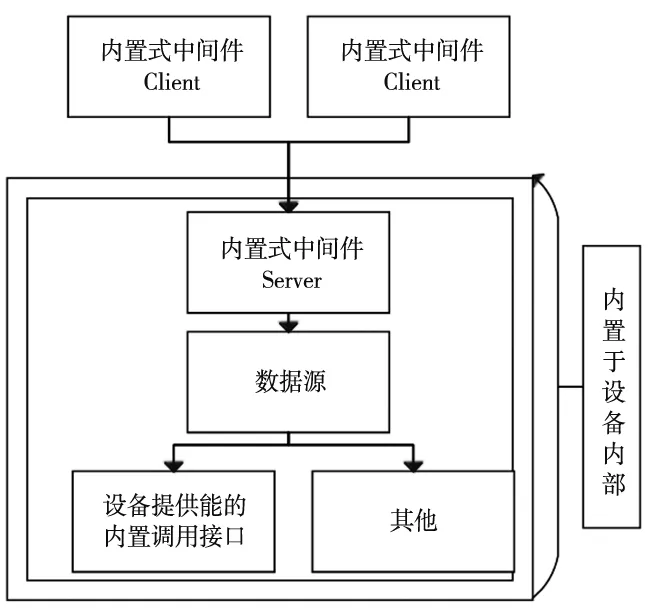
图6 嵌入内置式架构图
外置式相对来说比较灵活,它相当于一个接口,对外可对接多种数据来源。如图7所示。

图7 外置式架构图
数据可来源上述两种中间件类型中的任何一种类型的Server端或者Client端,也可以来自于其他类型采集服务器,如PLC、OPC DA、OPC UA或者MTConnext,甚至是私有协议,只要得到数据信息,并且知悉其根据要传输转换信息数据的组成所定义的模式即可。
内置式和外置式中间件架构中的Server端和Client端可认为是原子类型,可通过组合使用的方式满足各种各样的异构数据转换和传输的需求。
5 实验结果
实验环境以数字化车间中的主要设备-数控机床为数据源,以蓝天数控系统组成工作集群,模拟异构数据从传输到转换的整个流程,以测试不同数量级的数据转换传输所需的时间。
在实验环境下,为了测试跨语言属性,实验环境中间件Server端是基于C#语言设计实现的,而客户端实现有两种,一种基于C#实现,另一种是基于JAVA语言实现。
表1是实验环境中转换传输时间和所对应数据量级的实验记录表,从实验中得到的数据观察,该中间件在处理转换传输数据时所需求的时间未表现出随数据量的增加同比上升的情况。

表1 数据转换传输时间记录表
通过将表1中记录的数据转换成散点图并绘制实验数据曲线,其中X轴对应表中转换传输的数量级(单位:条),Y轴代表完成传输转换当前数量级信息所需的时间(单位:ms)。并且通过拟合实验数据得到了实验数据对应的对数拟合曲线,如图8所示。由观察可知,数据转换传输所需的时间随数据量成对数增长。

图8 实验数据和实验数据拟合的对数趋势图
6 结束语
该异构信息转换传输中间件使用C/S架构和分层的体系架构,层次关系清晰,灵活,根据所要转换传输的异构信息源信息的特点,生成相应的模式文件,通过添加或删除属性,实现对现有数据的动态描述,充分体现了设计时考虑的高效性和可扩展性。通过实验表明,此中间件可靠性强,数据转换效率高,能够对异构信息源中的数据格式和映射关系灵活定制,可有效解决数字化车间中异构数据转换和传输的问题。
