基于深层神经网络的道路交通标志检测识别方法研究
2019-09-17王斯健李志鹏
王斯健 李志鹏

摘 要:交通标志在道路交通运行中扮演着不可或缺的角色。随着智能交通的不断发展,道路交通标志的自动检测识别日益受到研究者的关注。在实际交通环境下,由于运动模糊、天气条件、光线干扰及拍摄视角等因素,给图像中交通标志自动识别带来了困难。针对这一问题,该文提出了基于深层神经网络的快速交通标志识别的方法,实现了常见道路交通标志的检测识别,并通过实验进行测试,结果表明,该方法在图像中交通标志的检测率和识别率方面都达到了较好的效果。
关键词:道路交通标志 检测识别方法 深层神经网络
中图分类号:TP391.41;TP183 文献标识码:A 文章编号:1672-3791(2019)06(b)-0001-04
建立全要素实体地理信息数据库是我国新型基础测绘项目的重点任务。目前是通过车载激光扫描仪获取道路实体点云数据,同时搭载全景相机进行辅助拍摄获取全景照片,最后根据采集的数据进行数字化编辑、属性录入以及最终入库。其中道路交通标志的类别属性需要根据全景照片进行人工判读或者外业调绘来获取,这导致了巨大的工作量以及较高的误判率等问题。
近年来,随着深度学习的迅速发展,利用神经网络算法解决图像的问题逐渐受到研究者们的青睐。其中卷积神经网络是通过训练海量的样本进行学习得到先验知识,进而可以直接探测和识别目标图像。该文研究了深度学习的方法,利用卷积神经网络算法对全景图片进行道路交通标志的自动检测和识别,并通过实验评估了该方法的准确性和可行性。
1 基本原理
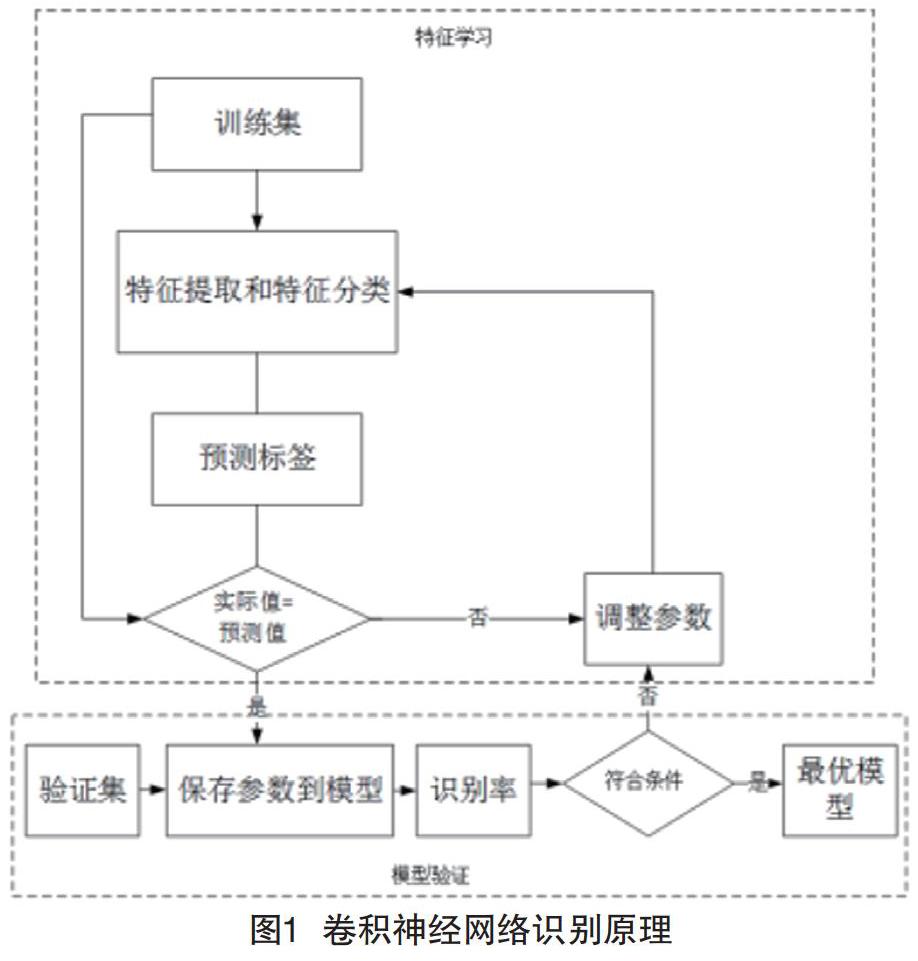
卷积神经网络(CNN)的核心结构包括两部分。其一为特征提取,每个神经元的输入与前一层的局部接受域相连,并提取该局部区域的特征,一旦该局部特征被提取后,与其他特征间的位置关系也随之确定下来;其二是分类,网络的每个计算层由多个特征映射组成,每个特征映射是一个二维平面,平面上所有神经元的权值共享,最终由全连接层作为分类层计算特征向量并输出分类结果。在监督学习和反馈机制调节下,CNN能够模拟人脑机制的认知过程逐步提高对不同物体的辨识能力[1]。
与传统分类器相比,CNN作为智能分类器不需要手动设计特征。在传统的模式识别中,需要通过人为设计特征从输入样本中收集图像信息再使用分类器进行分类。CNN是原始图像作为输入,从大量的样本数据中自主学习待识别目标的特征。与人为设计特征很难适应多种类物体的识别相比,自主学习特征能够提取到更适合目标分类的特征。从大量的数据中自主学习特征避免了由于特征复杂带来的提取特征困难,并且对于环境变化、遮挡等影响有较强的鲁棒性。概括来讲,CNN算法的训练过程可以分为两部分,即前向学习和反向验证。在前向学习过程中计算网络的损失(分类错误的程度)并利用反馈调节机制,使用梯度下降法调节网络参数以降低网络损失,输出网络模型。反向验证过程中使用验证集验证模型的分类能力是否满足要求。其具体过程如图1所示。
2 数据研究与方法
2.1 卷积神经网络架构
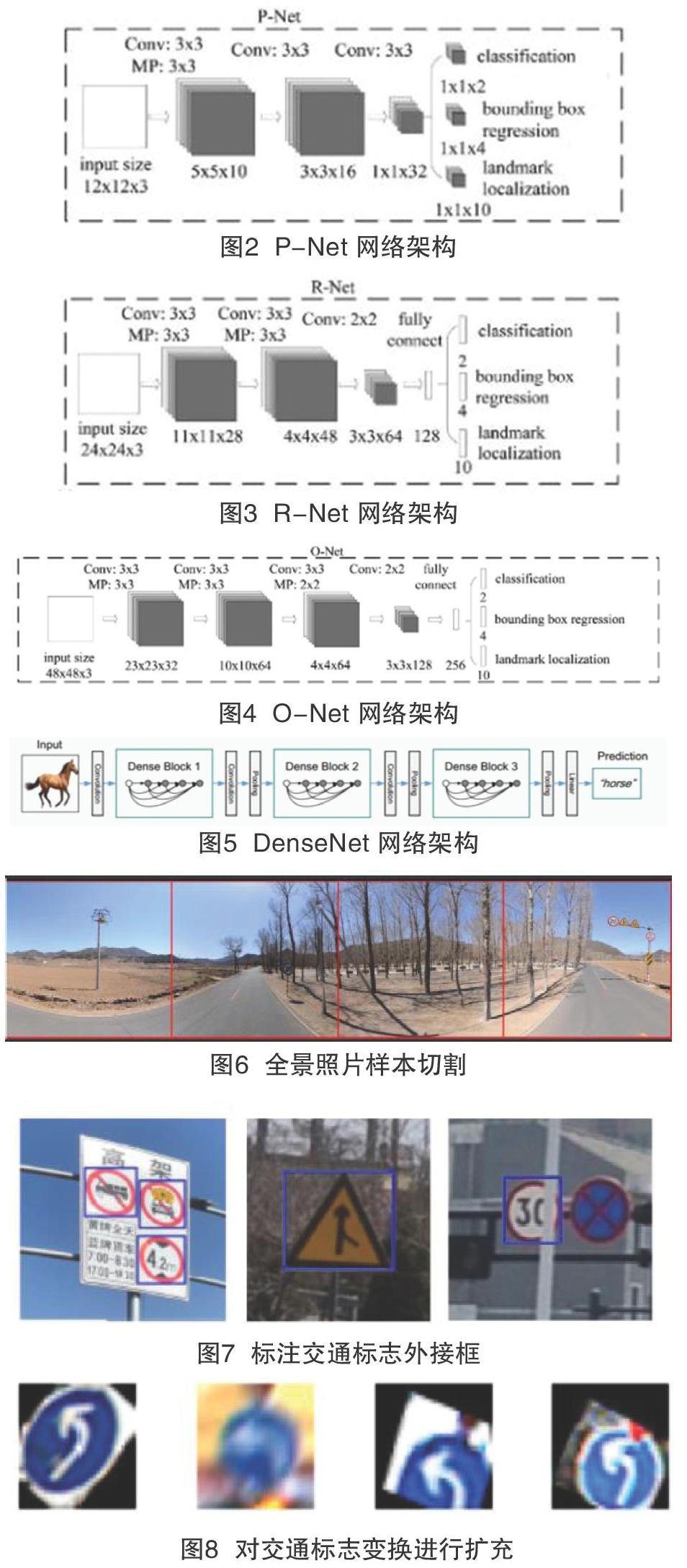
该文的程序网络架构主要分为两个部分,首先是利用了级联卷积神经网络探测交通标志的位置,建立最终的候选区域。第二部分是利用密集卷积网络对生成的含有交通标志的候选区域进行分类[2]。
第一部分利用级联卷积神经网络进行探测主要分为3个阶段。
第一步采用一个全卷积神经网络,称之为Proposal Net(P-Net)(见图2),去获得候选窗体和边界回归向量。同时,候选窗体根据边界框进行校准。然后,利用非极大值抑制(NMS)方法去除重叠窗体。
第二步Refine Network(R-Net)(见图3),将经过P-Net確定的包含候选窗体的图片在R-Net网络中训练,网络最后选用全连接的方式进行训练。利用边界框向量微调候选窗体,再利用NMS去除重叠窗体。
第三步Output network(O-Net) 比R-Net多一层卷积,功能与R-Net作用一样,只是在去除重叠候选窗口的同时,显示交通标志的关键点定位(见图4)。
选好候选区域后利用密集卷积网络(DenseNet)对选中的候选区域的照片进行分类。DenseNet是一种具有密集连接的卷积神经网络。在该网络中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。DenseNet的网络基本结构如图5所示,主要包含密集区块(Dense Block)和过渡层(transition layer)两个模块组成[3]。其中Dense Block为稠密连接的模块,transition layer为连接相邻2个Dense Block的模块。
2.2 样本数据训练
通常从网络上下载的交通标志图片都是理想化且不真实的。因此,为了模拟一个真实的道路场景,该文采用了在上海实地外业拍摄的照片以及腾讯街景全景影像作为样本数据集。其中,腾讯街景照片覆盖了全国300多个城市的道路场景,用了6个单反相机拍摄并拼合了起来,每间隔10m获取一张。其中包含了30000张有交通标志的影像,这些影像都是在不同的天气条件下拍摄以及都有一定的扭曲。
该文在下载的全景影像中选择了2000张带有交通标志的照片,其分布于5个不同的城市,并包含了市区与郊区。然后将影像上部25%(天空)和下部25%(地面)都裁切掉,留下中间的感兴趣区域,再垂直分割为4块[4],如图6所示。最终得到了影像数据集,样本影像的分辨率为2048×2048。实地拍摄的照片也类似切割成尺寸相同的影像。
根据交通标志的特征显著性,该文只标注了3种类型的交通标志:警告标志、禁令标志和指示标志。由于网络架构分为交通标志探测与识别两个方面,因此制作数据样本集也分为两步。
首先,在制作探测交通标志训练数据集的过程中,在样本影像数据集中每一张照片上的所有交通标志勾画出外接矩形边界框,其中包括了扭曲的以及被遮挡的标志等情况,并记录了其外接矩形左上角(x1,y1)与右下角(x2,y2)的坐标,保存在对应的文本中(见图7)。
然后在对交通标志进行分类时,根据其在样本数据集中的常见性,具体挑选出了42种常见的交通标志,将它们根据上一步勾画的外接矩形框裁切出来,尺寸皆重采样成48×48像素,最后对它们进行标注标签,具体交通标志及其标签如表1所示。
由于交通标志类型数量的不均匀性,该文把少于100个样例的交通标志也做了一个特殊的分类,以三大类型做划分,分别是指示标志的其他(io)、禁令标志的其他(po)以及警告标志的其他(wo);然后对100到1000个样例的分类进行扩充,增加到1000个样例。扩充是将原有的标志进行随机的旋转[-20°,20°],或者进行色彩增强[5],部分还做了模糊和透视变形,如图8所示;其他超过1000个样例的数量保持不变。最后将制作好的样本数据集进行训练得到训练模型。
3 实验测试数据
3.1 数据样本集中影像测试
实验选取了100张数据样本集中的照片进行测试。影像大小均为2048×2048,影像畸变较小。实验中对于像素过于小的交通标志检测效果不是特别突出,因此选择了剔除小于15×15像素的交通标志后,重新进行了统计。数据检测统计如表2所示。
3.2 实地拍摄全景影像测试
实验还选取了在上海市张江镇利用全景相机拍摄获取的100张带有交通标志的全景影像进行了测试。影像大小均为4096×2048,影像畸变较大。得到如表3所示的实验结果。
3.3 成果展示
具体情况见图9、图10。
4 结语
该文尝试利用人工智能深度学习算法对车载全景影像中的交通标志进行探测与识别分类,比以往的一些特定算法具有更好的可靠性。下阶段,将扩大交通标志的范围,训练更多不同种类的交通标志,能够识别出更复杂的交通标志,例如道路施工安全标志、旅游区标志以及辅助标志等带文字图画信息的交通标志。
此外,该研究需要进一步探索对识别后的交通标志进行测绘级别的空间定位,需要研究更多成熟的算法对全景图片与三维激光点云进行分析、综合,实现从车载采集的全景图片与点云数据中自动化解算出城市交通标志的类型和实际空间位置,从而智能化地生产地理信息数据。
参考文献
[1] 杨振杰.基于CNN的交通标志识别研究[D].天津工业大学,2017.
[2] Zhang K,Zhang Z,Li Z, et al. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J].IEEE Signal Processing Letters,2016, 23(10):1499-1503.
[3] Huang G, Liu Z, Maaten L V D, et al.Densely Connected Convolutional Networks[A].2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR)[C].IEEE Computer Society,2017.
[4] Zhu Z, Liang D, Zhang S, et al. Traffic-Sign Detection and Classification in the Wild[A]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)[C]. IEEE Computer Society,2016.
[5] 黃琳.基于深层神经网络的交通标志识别方法研究[D]. 江苏科技大学,2015.
[6] Charles R.Qi, Wei Liu, Chenxia Wu, et al. Frustum PointNets for 3D Object Detection from RGB-D Data[J].Computer Science Computer Vision and Pattern Recongnition,2017(12).
