基于向量表示的代码搜索方法
2019-09-17慕江林刘克剑
慕江林,刘克剑*,林 晗
(1.西华大学计算机与软件工程学院, 四川 成都 610039;2.成都理工大学管理科学学院, 四川 成都 610059)
软件开发者基于Github、SourceForge等开源代码仓库上的可复用的基础软件包再次开发,可降低开发的时间和成本。开发者如果使用某些未在接口的使用方法中声明的方法,需要在代码搜索引擎搜索相关代码片段。如何有效地帮助开发者从代码库中搜索与任务相关的代码,成为代码搜索[1-3]的研究方向之一。
用户将少量关键词输入到代码搜索引擎中,搜索引擎搜索相关代码片段按照与关键词的匹配度返回给用户。基于开发者的开发经验,搜索的关键词为 “iterate a java hashmap”,搜索引擎应该返回java有关于hashmap迭代的示例,如图1所示。

已有的代码搜索引擎,如Ohlh Code[4]、 Krugle[5]等,将用户输入关键词当作纯文本,通过关键词检索类似的代码片段。使用该方法搜索到的结果中只包含单一的关键词,搜索结果与用户期望相差较大。
近期的一些代码搜索方法开始对代码结构和代码语义分析。PARSEWeb将代码抽象为方法调用序列,对方法调用序列聚类排序,查找相似使用模式的代码片段[6],是一种基于结构的代码搜索,准确率不高。PRIME将代码片段作为输入,从结构上对代码片段进行分析,寻找代码片段的相似之处[7],它忽略了代码语义,在搜索结果上表现不佳。SWIM算法通过词袋模型将自然语言查询语句翻译成API,再通过API生成代码片段[8]。虽然该方法有效地利用了查询的语义,但是基于词袋模型的语义匹配结果不太理想,基于API生成的代码片段,考虑了代码结构特性,忽略了代码之间的语言特性。QECK 算法是一种利用群体知识来扩充查询的方法,其中群体知识是指Stack Overflow的问答信息[9],该方法虽然扩展了查询文本,丰富了查询的语义,但是忽略了代码之间的语义,在代码相似度比较上不足。本文提出了一种基于向量表示的代码搜索方法——VRCS算法 (vector representation based code search),它充分利用了代码搜索关键词—代码之间语义和代码—代码之间的语义,在一定程度上提升了搜索的准确率。
1 基于向量表示的代码搜索方法
基于向量表示的代码搜索方法能够有效地利用搜索关键词的语义实现相关代码搜索。具体流程是:1)抽取代码片段库的代码,形成以单个方法为单位的代码片段,分割代码片段为单个代码词和代码符号,使用one-hot编码分解得到的代码词和代码符号,将编码后的向量输入到skip-gram模型中,得到向量组表示的代码库和一个训练好的skip-gram模型,其中,代码库的每段代码片段都是由代码词向量组成的向量组;2)对搜索文本进行预处理,去掉搜索文本中的修饰词汇,如介词、冠词等,将预处理后的搜索文本关键词作为代码关键词,利用第1步训练完成的skip-gram模型生成搜索关键词上下文代码片段向量组,其中向量组的每一个向量是搜索关键词上下文代码片段中的代码词的向量表示;3)将搜索关键词上下文代码片段向量组和待匹配代码片段向量组分别输入到编码器中编码,生成搜索关键词上下文代码片段隐向量和待匹配代码片段的隐向量;4)利用余弦相似度计算搜索关键词上下文代码片段隐向量和待匹配代码片段的隐向量的相似度,排序生成搜索结果,如图2所示。
2 代码词嵌入表示
2.1 代码片段词嵌入表示
自然语言的词嵌入表示有2大优势:能够获取单词的上下文语境;有助于句子的编码表示。由于程序语言具有与自然语言相似的语义特性[10],以词嵌入方式表示程序代码,以便代码关键词的语义扩充和从语义上对代码相似程度的计算。
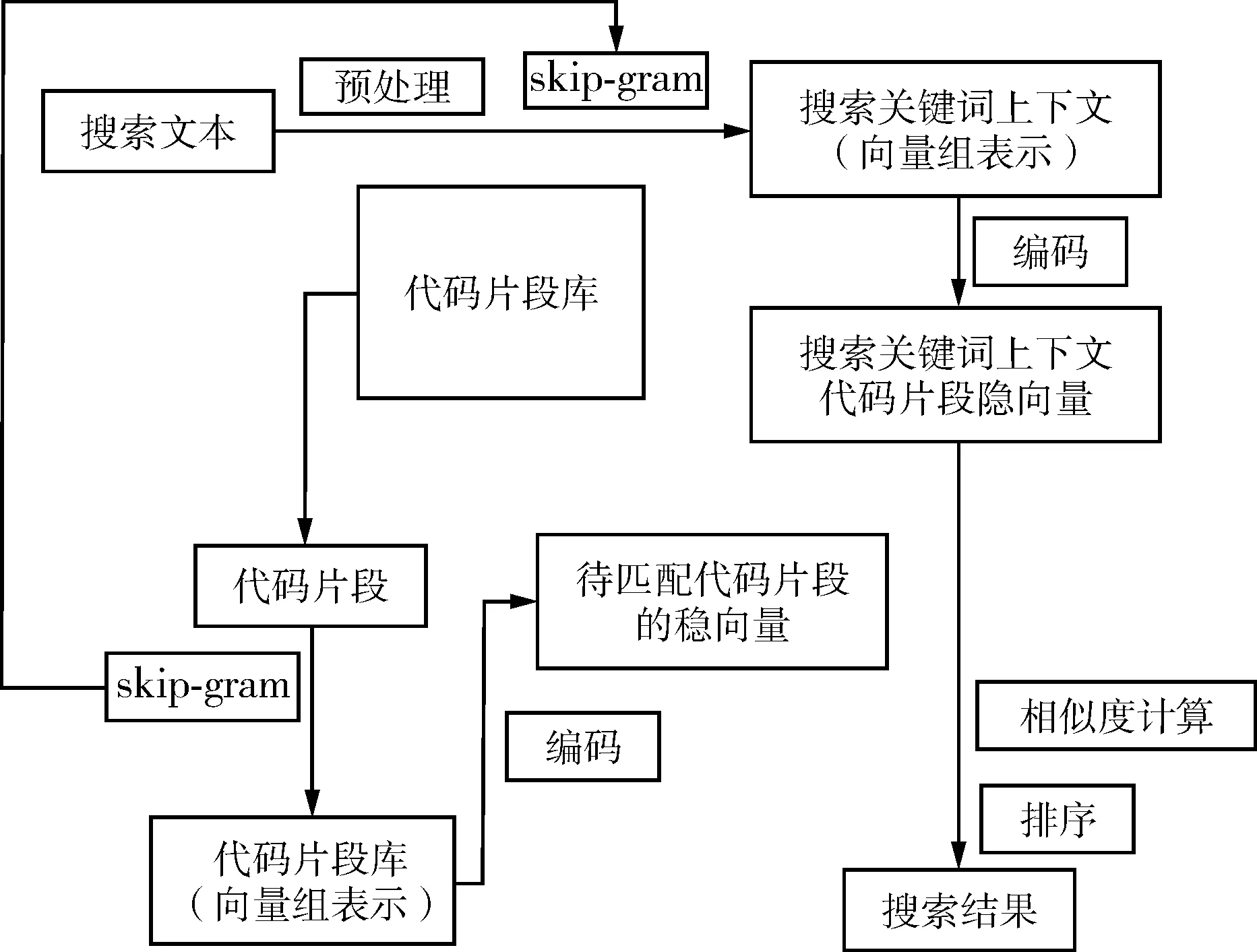
图2 基于向量表示的代码搜索方法概述
自然语言中符号常常被视为无用信息,代码数据集中的代码片段包含很多有助于代码理解的符号信息,如图1代码片段,其中“+”表示拼接字符串,“?”表示方法调用,“:”表示对集合的遍历等。为保存代码中的符号对代码片段语义的影响,将代码中的符号按照词进行编码。
为获取skip-gram模型的输入向量,抽取代码片段库的代码,形成以单个方法为单位的代码片段,分割代码片段为单个代码词和代码符号,使用one-hot编码分解得到的代码词和代码符号,将编码后的向量输入到skip-gram模型中。
通过训练skip-gram模型[11],可以得到代码词的唯一编码,skip-gram模型的结构如图3所示。
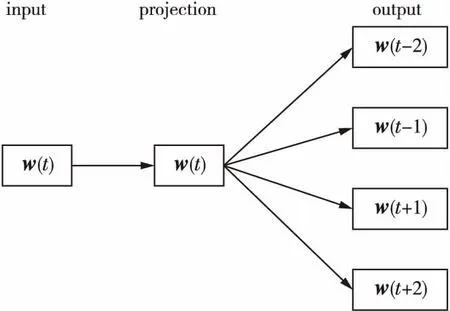
图3 skip-gram模型
w(t)是一个向量,表示代码词或代码符号的one-hot编码,w(t-1)和w(t+1)分别表示代码词或代码符号w(t)的上一个代码词或代码符号的one-hot编码和w(t)的下一个代码词或代码符号的one-hot编码。 采用无监督学习训练skip-gram模型,目标函数是最大化式(1)之和。
(1)
式中:c是滑动窗口的大小;T是单词序列的长度;p(wt+j|wt)用softmax函数定义条件概率,为
(2)

Vc={v1,v2,…,vkc}=

2.2 关键词语义扩展
用户输入的搜索文本中包含部分介词等修饰词汇,对代码的匹配不具有重要意义,将此类词汇去掉,得到纯净的语义相关的搜索关键词。为了对关键词的语义更好地补充,将上述清理后的关键词视为代码关键词,使用上述训练的skip-gram模型生成搜索关键词上下文代码片段向量组,其中每一个向量是代码关键词的向量表示。例如,搜索的关键词为 “iterate a java hashmap”,将其中的“a”去掉,留下“iterate java hashmap”,通过skip-gram模型扩充得到的代码片段,如图4所示。

搜索关键词上下文代码片段向量组为Vs,ks为代码词的个数,Vs表示为
3 基于代码片段的隐向量相似度计算
深度语义结构模型[12](deep sematic structured model, DSSM)是文档匹配[13]中的常用模型。深度语义模型将单词向量映射为句子隐表示,以便计算句子之间的相似度。为了计算搜索关键词上下文代码片段向量组和待匹配代码片段向量组的语义相似度,使用改进的DSSM模型进行相似度计算,如图5所示。
在图5中,Q对应搜索关键词上下文代码片段向量组,Ci对应代码片段词向量组。

图5 代码片段的编码和相似度计算

i∈{Q,C1,C2,…,Cn}
(3)


(4)
(5)
hi(3)为第3层第i个节点的隐向量表示,当i=Q时,是代码片段Q经过网络的编码计算得到代码的隐向量表示,当i=Ci时,是代码片段Ci经过网络的编码计算得到代码的隐向量表示。Wj为神经网络的权重参数;bj为偏置向量;式(4)中的激活函数f(·)表示为
(6)
R(Q,Ci)表示搜索关键词上下文代码片段隐向量hQ和待匹配代码片段的隐向量hCi的余弦相似度,计算式为
(7)
通过计算hQ和hCi的相似度,可得出搜索文本和待匹配代码片段的相似度,将相似度排序,得出的搜索列表作为最终的搜索列表。例如,与搜索的关键词 “iterate a java hashmap”匹配的代码片段,如图6所示。

代码片段匹配度Map
图6 关键词为“iterate a java hashmap”的相关代码匹配度
4 代码相似度计算模型训练
代码相似度计算模型训练的目标是使搜索文本与目标代码片段在语义上尽可能的相似,等价于搜索关键词上下文代码片段隐向量和待匹配代码片段的隐向量相似。为训练本模型,采用类似于深度语义模型DSSM的训练方式训练[12],对于实践中很难收集到的用户搜索文本和期望代码对,使用Stack Overflow开发者问答数据集和收集的Github数据集作为训练数据,从中抽取搜索文本和匹配代码片段作为正例,选择其他代码片段作为负例。其目标函数为
(8)
其中
(9)


Map

图7 回答被赞同数最多的答案(正例)
图8 无关回答(负例)
5 实验分析
5.1 数据收集
为了缓解小量数据导致的实验结果偏差,收集Github[14]上stars最高的500个项目中的代码和Stack Overflow开源数据[15]的Posts表作为训练数据集,这2份数据集的代码行数规模都超过了数10亿。Stack Overflow数据集中Posts表中的问题贴和回答贴总数量超过4 300万条。问题贴中包含用户提出问题。与问题贴对应的回答贴中包含其他用户对该问题的回答代码和提问者的满意回答贴。Github上收集项目包含大量类和类方法代码片段。
5.2 代码库的获取
为训练代码片段的隐向量相似度计算模型,将从Github数据集[14]和Stack Overflow数据集[15]中构建2个向量表示的代码库,Github代码库和Stack Overflow代码库,作为训练的训练集和测试集。
构建方式:第1步,分别抽取数据集中的代码片段和代码片段文本描述,将代码片段切割成以方法为基础的代码片段,并分割基础代码片段为代码词输入到skip-gram模型中,并采用负采样[12]优化概率值,获得skip-gram模型中的参数,同时,将代码片段中的基础代码片段表示成向量组的形式,将得到的代码文本描述和对应的代码片段向量表示放入数据库中;第2步,将第1步抽取的代码片段文本描述预处理,即当从Stack Overflow数据集中抽取代码片段文本描述时,抽取提问贴中的语义关键词,如 “iterate a java hashmap”,抽取的语义关键代码词为 “iterate java hashmap”作为代码片段文本描述关键词,当从Github数据集中抽取代码片段文本描述时,按照驼峰、下划线或其他类名命名方式分割类名和方法名,如,ThreadDumpEndpoint AutoConfiguration类中的方法dumpEndpoint,抽取成语义关键词“Thread Dump Endpoint Auto Configuration dump Endpoint” 作为代码片段文本描述关键词,利用第1步训练的skip-gram模型进行扩充,形成代码描述关键词上下文的向量表示;第3步,将第2步得到的代码描述关键词上下文向量表示,替换第1步代码文本描述——代码片段向量表示库中的代码文本描述,即可得到代码描述关键词上下文—代码片段库,如图9所示。

图9 代码库的获取
5.3 代码相似度计算实验流程
对于代码相似度匹配模型的训练,选取5.2节构建的代码库中一份数据作为训练集,另一份数据作为测试集。随机选取代码描述关键词上下文—代码片段库中的1组数据,将其中的代码描述关键词上下文向量组作为搜索输入,将其中的代码片段作为训练的正例,随机选择其他的代码片段作为训练的负例。
采用mini-batch SGD算法训练模型,首先将模型中的l1,l2层元素取为300,参数随机初始化,每一次mini-batch取1 024个训练数据,在整个数据集上迭代20次后,神经网络收敛。
5.4 评估方法
为了评估代码搜索方法的有效性,将从准确率、召回率、F值3方面对搜索结果进行评价。在Q个搜索中,使用符号NQK表示搜索结果为正确结果的数量,NQS表示搜索结果中总搜索次数,NQW表示搜索结果中的非最佳匹配结果被视为最佳匹配结果的数量。搜索结果准确率Pk是满意搜索结果所占总的搜索结果的比例,定义为
(10)
搜索结果的召回率Precall是所有搜索结果中的正确结果数占正确搜索结果数和被错误识别的正确结果数的比例,定义为
(11)
搜索结果的F值 (F-Measure) 表示准确率Pk和召回率Precall的加权调和平均, 用于评价模型的好坏,定义为
(12)
5.5 对比分析
为了评价本文所提出的算法的有效性,将VRCS方法与QECK和SWIM方法对比,并使用5.2节所构建的Github代码库和Stack Overflow代码库作为训练集和测试集。当Github代码库作为训练集,在Stack Overflow代码库做测试时,其准确率、召回率和F值如表1—3所示。

表1 Stack Overflow数据集下的准确率

表2 Stack Overflow数据集下的召回率
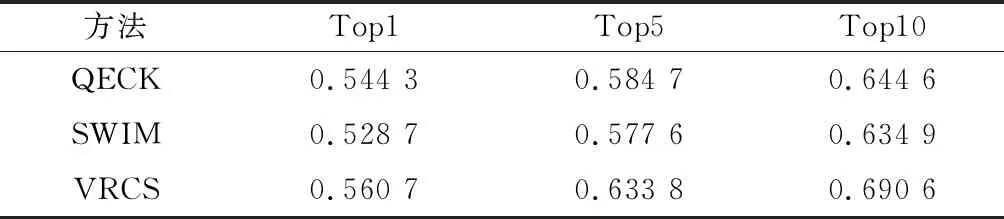
表3 Stack Overflow数据集下的F值
可以看出:VRCS 算法中58%的搜索能在第1个搜索结果找到正确答案,相对于QECK算法和SWIM算法,其准确率、召回率和F值有1%~3%的提升;65%的搜索能在前5个答案中找到正确答案,相对于QECK算法和SWIM算法,其准确率、召回率和F值有1%~7%的提升;72%的搜索能在前10个答案中找到正确答案,相对于QECK算法和SWIM算法,其准确率、召回率和F值有1%~5%的提升。
当Stack Overflow代码库作为训练集, Github代码库做测试时,其准确率、召回率和F值如表4—6所示。
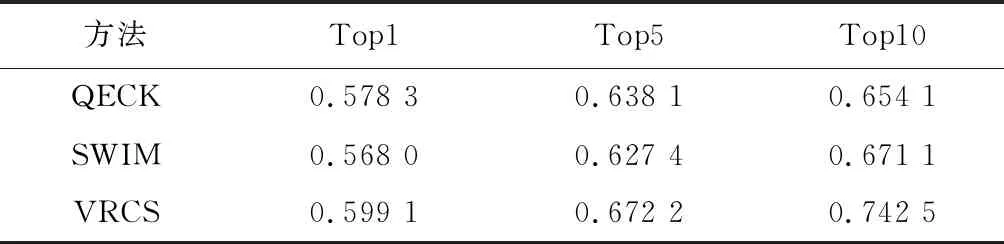
表4 Github数据集下的准确率
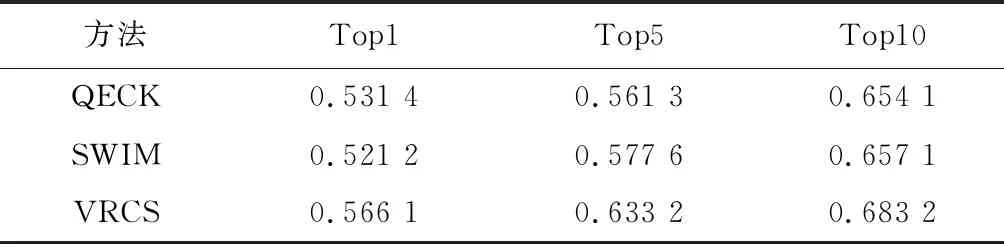
表5 Github数据集下的召回率

表6 Github数据集下的F值
可以看出:VRCS算法中59%的搜索能在第1个搜索结果找到正确答案,相对于QECK算法和SWIM算法,准确率、召回率和F值有2%~4%的提升;67%的搜索能在前5个答案中找到正确答案,相对于QECK算法和SWIM算法,准确率、召回率和F值有3%~7%的提升;74%的搜索能在前10个答案中找到正确答案,相对于QECK算法和SWIM算法,准确率、召回率和F值有2%~8%的提升。
通过将VRCS应用于上述2份数据集的测试对比发现,VRCS方法在准确率、召回率以及F值上有所提高。同时,VRCS算法在搜索结果的准确率平均高于召回率的3%,这是因为在大量数据的测试下,搜索准确率得到提高,导致了召回率变低。从数据集上看,使用Github数据集作为测试的搜索结果优于Stack Overflow数据集的搜索结果,因为从Github数据集上抽取的关键词更加具体,也更加能够表示代码片段。综上所述,对于基于大量数据的代码搜索,本文提出的VRCS算法充分利用了代码搜索关键词—代码之间语义和代码—代码之间的语义,在一定程度上提升了搜索的准确率。
6 总结
本文提出一种基于向量的代码搜索方法,该方法通过Github和Stack Overflow数据集中的代码片段训练一个skip-gram模型,并利用这个模型扩充从搜索文本提取的关键词,得到搜索关键词上下文代码片段向量组,最后计算搜索关键词上下文向量组和待匹配向量组的语义相似度,排序完成搜索。该方法有效地降低了因关键词语义模糊导致的搜索结果偏差。同时,应用神经网络学习代码片段的隐表示,从语义上匹配有更高的精确度。实验表明,本文提出的方法优于已有的代码搜索方法。在未来的研究中,可结合语义和代码结构,提高代码搜索结果的精确度。
